


在巨大的变革中快速emo又快速复活了。来翻一翻别人家夸张的广告?。总体就解决了一个问题,让SD报告和SEND基本同时完成,效率一小步,技术革新一大堆。为什么觉得夸张,因为下面这个案例:
“CRO提供的病理学实验室LIMS数据,需完成向 SEND 标准转换后方可使用,而该转换工作在最终版 PDF 研究报告生成后许久才完成。这导致申办方毒理学家无法将病理学检查结果与发病率统计数据,同试验期数据及临床病理学检查结果进行交叉比对分析。
PointCross 解决方案:PointCross 在收到 PDF 报告初稿后的 7 个工作日内,提取所有受试动物及其器官、组织的数字化数据,并将该数据导入申办方客户在 Xbiom 通用数据模型与存储库中的专属站点。此举使申办方的病理学家与毒理学家能够结合试验期数据,对受试队列的发病率统计数据开展分析与观测。节省了4至6周的工作时间;同时避免了向 CRO 支付8000至10000美元的 LIMS 数字化病理学数据服务费”。
毒理学家能理解病理PDF报告以及LIMS 数据不就不用浪费7个工作日了吗?。


原文实在很难看懂,Ai重构了一下结构和内容,感兴趣可以去官网看~
https://pointcrosslifesciences.com/three-steps-to-transforming-cro-productivity-time-cost-and-quality-in-nonclinical-study-reporting/

公司背景
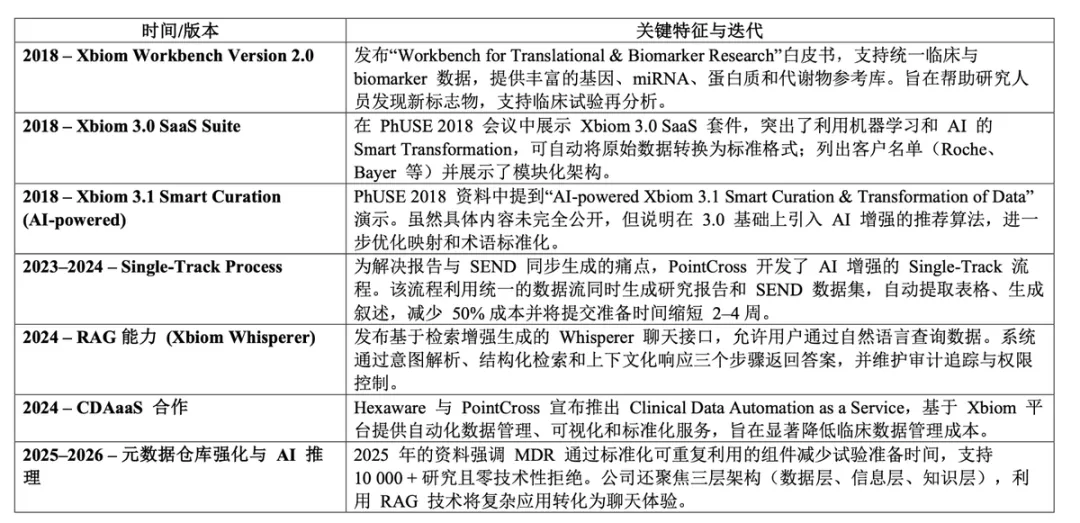
Xbiom 是 PointCross Life Sciences 提供的一个模块化数据管理和分析平台,用于从临床、转化医学和非临床研究中自动采集、转化和分析多源数据。平台利用统一数据模型(UDM)和元数据驱动的智能映射技术,实现临床试验数据、非临床 SEND 数据、泛实验室数据以及生物标志物数据的自动标准化和汇聚,并提供交互式可视分析、统计分析、法规提交和自然语言查询等功能。其技术定位不只是传统的电子数据采集(EDC)或临床试验管理系统(CTMS),而是统一的生物分析数据基础设施,支持药物研发从研究到监管的端到端数据流程。
Xbiom 的模块化架构包括:安全数据交换层 (VDR)、元数据仓库和智能转换器 (MDR & Smart Transformer)、统一数据模型 (UDM) 仓库、法规提交模块、沉浸式图形对象 (IGO)、非临床与临床洞察模块、eDataValidator 以及支持“Single‑Track”同时生成研究报告和 SEND/SDTM 的 AI 工作流。平台既可作为 SaaS 部署,也可在客户防火墙内私有部署,满足制药公司对数据安全和合规性的要求。
产品版本演进与发展路线

一、现状:三个"隐形杀手"
⏱️ 杀手一:时间黑洞
当前行业惯例是顺序流程:
研究团队先写报告(4-5周)
SEND团队再上手(再4-5周)
总周期:8-10周
明明可以并行,非要排队等。
? 杀手二:重复造轮子
同样的数据,要整合两次:
方案元数据提取 → 做两遍
LIMS+非LIMS数据整合 → 做两遍
研究报告元数据重新提取 → 再做一遍
⚠️ 杀手三:QA成本爆炸
两个团队、两套流程,必然产生结构性偏差:
机械核对占SEND成本的30%以上
仅报告数字化就占20%
如果附录数据不在LIMS里,核对成本逼近40%
更糟的是,80%的协调成本都花在"把个体数据重新整合成汇总数据"这种本不该存在的环节上。

二、什么是"单轨流程"?
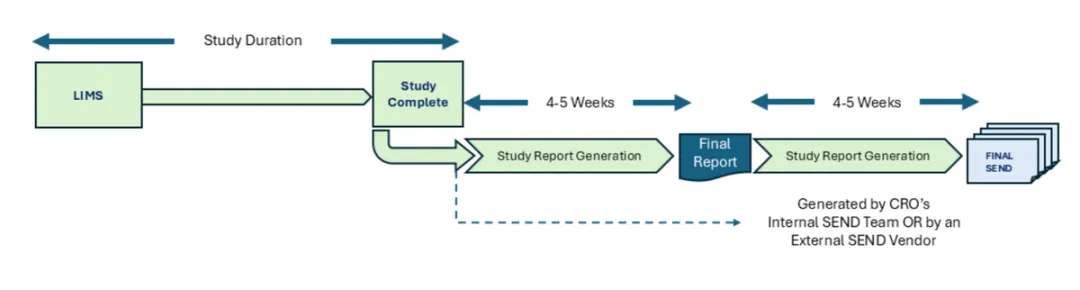
CRO 非临床研究的当前顺序流程
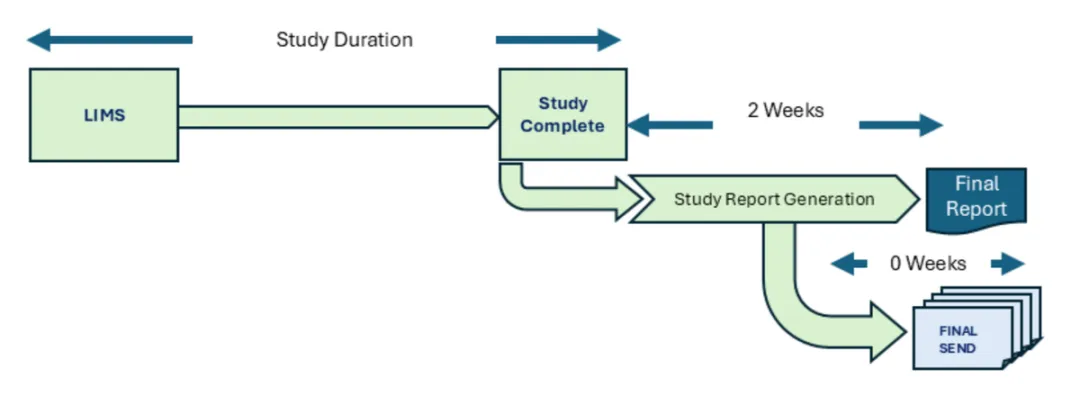
CRO 非临床研究的单轨流程
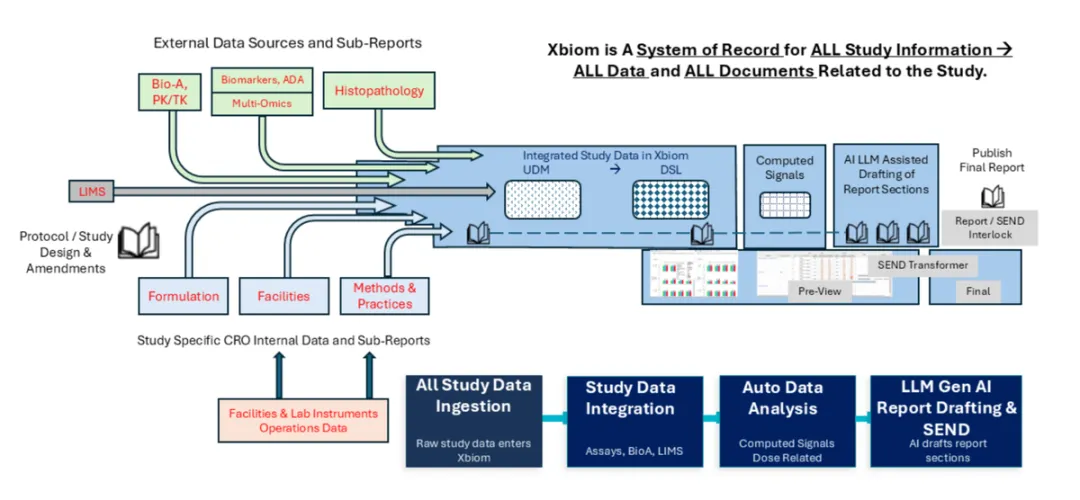 单轨 Xbiom™ 研究信息管理系统
单轨 Xbiom™ 研究信息管理系统
一个数据集,两个交付成果,同时生成。
研究报告和SEND不再是一前一后,而是基于统一数据模型并行开发。当研究主任点下"定稿"的那一刻,SEND包已经准备好了。
关键承诺:不增加跨职能依赖。研究主任不用学SDTM,SEND团队不用等排期——集成发生在数据层,而非组织层。

1️⃣ 研究报告撰写:AI辅助,数据驱动
数据导入后,通过通用数据模型(UDM)和数据服务层(DSL)生成统一视图
系统自动计算剂量-时间相关信号、统计检验
AI根据元数据注册表中的目标目录,逐节生成报告草稿
研究主任可AI润色或手动编辑,系统自动比对确保不偏离数据
定稿即锁定,全程符合21 CFR Part 11
2️⃣ SEND元数据:前置捕获,持续同步
研究开始前:方案参数直接录入SEND域编辑器,提前生成TE/TA/TX/EX域
研究进行中:LIMS数据自动填充DM域,方法/工具决策自动写入元数据注册表
零手动提取:告别"研究结束后再重新录入一遍"的噩梦
3️⃣ SEND质控与提交:一键出包
数据导入完成后,SEND团队随时预览、测试导出
验证报告和注释自动汇总到nSDRG
Define.XML自动生成
研究报告一定稿,SEND提交包立即就绪(数据集+nSDRG+Define.XML+验证报告)

单轨不是"拼凑工具",而是集成平台。以下组件缺一不可:

安全边界:LLM绝不触碰源数据,绝不自主决策,所有生成内容可追溯验证——符合FDA/EMA最新AI指导原则。

自动化成熟流程(主路径)
数据自动"闯关":原始数据 → 准备 → 分析 → 信号生成,关键节点需人工签批。
关联式事件驱动工作流(并行)
数据交换爬虫、申办方通知、报告审核等,非关键路径但大幅降低管理开销。
两种自动化,明确边界




顺序提交模式的存在,更多是因为惯性,而非合理性。在紧张的报告周期后再加4-5周SEND工作,是整个行业的隐性成本。
单轨流程的核心逻辑很简单:从同一个锁定的数据模型,同时生成两份交付成果。
研究主任签字的那一刻,就是提交包完成的那一刻——无需数周等待,无需反复核对,无需担心不一致。
技术组件已验证,挑战只在集成与运营投入。