



锋行链盟推荐阅读
来源:中国信通院
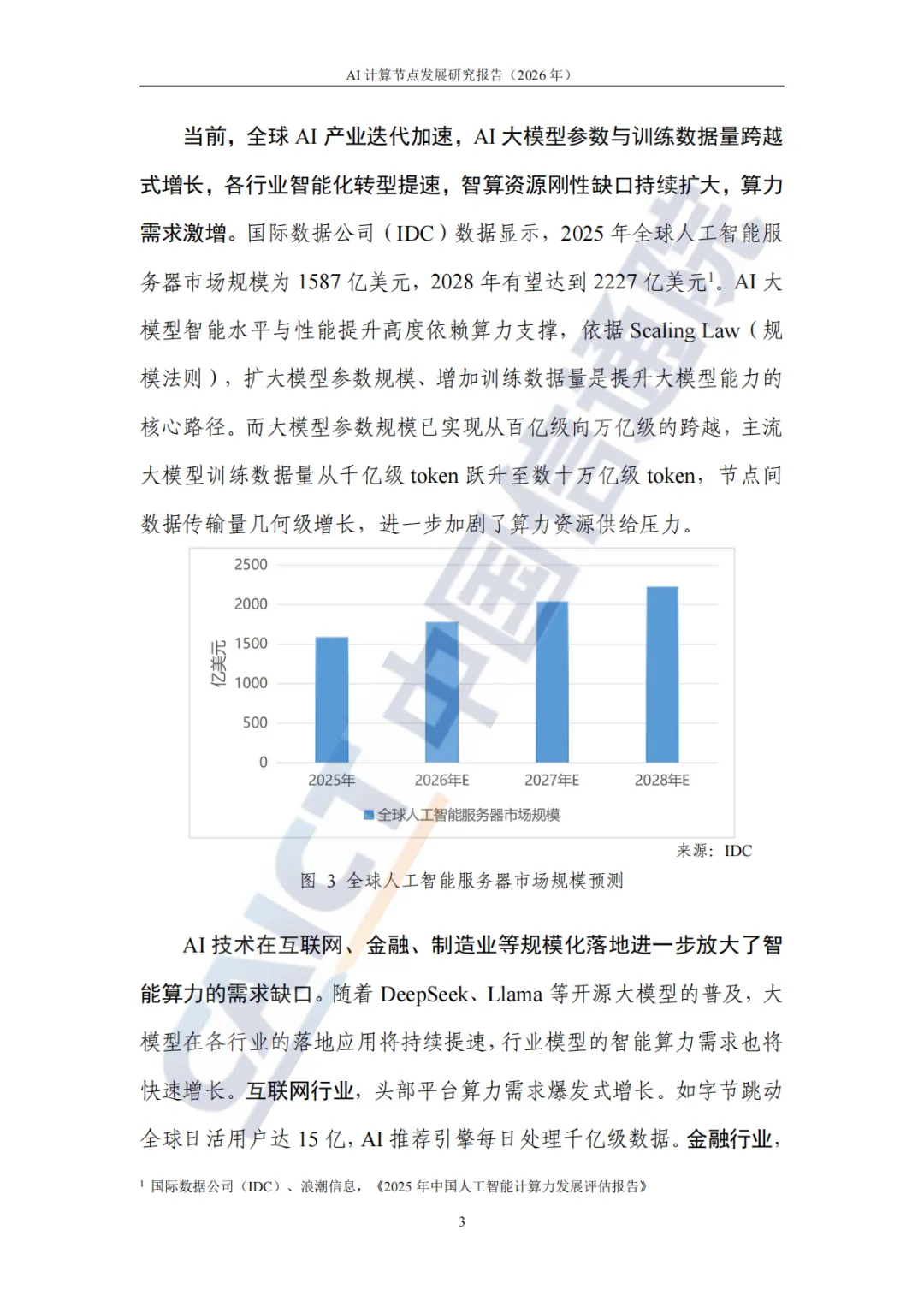
以下是内容详情
前 言
当前,全球人工智能(AI)加速发展,伴随着大模型参数规模与训练数据大幅增长,AI产业发展推动全球AI算力市场规模持续扩大,互联网、金融、制造等重点行业智能化转型进一步放大算力需求。同时,传统算力架构面临单机性能受限、集群扩展瓶颈、资源利用率偏低等多重挑战,新型架构探索成为突围算力瓶颈的关键路径。AI计算节点作为构建超大规模智能算力集群的核心,依托高速互联技术融合多算力芯片形成规模化计算单元,有效破解AI大模型训练中的算力协同与效率难题。
在此背景下,智能算力作为支撑人工智能高质量发展的重要基础,已成为国家战略支点,多国加大政策支持与投资力度,我国也通过多项政策部署,推动AI计算节点技术突破与工程落地。同时,我国智能算力正处于从规模化扩张向高效化提升的关键期,AI计算节点凭借高密集约、高速超宽、高效灵活、高稳可靠的核心特征,通过节点架构重构、超低时延网络、CXL内存、智能算力调度、绿色低碳供能等核心技术创新,在大模型训练、高并发推理及金融、工业、能源等行业场景应用中发挥着关键支撑作用。
立足新发展阶段,本报告系统分析AI计算节点发展概况、核心技术、应用场景、产业生态及未来趋势,为政策制定、技术研发与产业应用提供参考,助力构建先进易用、绿色高效的算力基础设施,推动AI与实体经济深度融合,夯实数字经济发展基础。
一、 核心定义与出现动因:应对大模型时代的算力“系统级”瓶颈
报告开宗明义,指出AI计算节点的诞生是AI产业,特别是大模型发展进入深水区的必然产物。其核心定义是:一个通过超高速互联技术(如NVLink),将多颗AI算力芯片(GPU等)紧密集成,形成的一个逻辑上统一的、可横向扩展的“超级计算单元”。
其出现的深层动因源于三重压力:
需求爆炸:大模型参数与数据量从百亿/千亿级向万亿/数十万亿级跨越,形成“通信密集型”场景,对算力协同和数据传输效率提出极致要求。
传统架构瓶颈:传统以CPU为中心、通过外部网络(如以太网、InfiniBand)堆叠服务器的“Scale-Out”模式,在扩展至万卡规模时,遭遇网络延迟和带宽瓶颈,导致有效算力无法线性增长,出现“算力黑洞”(利用率低于30%)。
国家战略与产业竞争:全球主要经济体(美、英、欧、中)均将智能算力基础设施上升为国家战略,进行大规模投资和政策引导(如美国“创世纪计划”,中国“人工智能+”行动),推动底层算力架构创新以争夺制高点。
因此,AI计算节点的本质是从“堆叠独立的算力盒子”转向“构建一体化的算力模块”,旨在从系统架构层面解决单点芯片性能之外的、更根本的集群级协同效率问题。
二、 技术架构解析:从“计算单元”到“算力系统”的五大支柱
报告将AI计算节点的核心技术解构为六个方面,构成了其支撑万卡级智算集群的完整技术栈:
架构重构(核心突破点):这是最根本的变革。从“以CPU和外部网络为中心”转向 “以GPU间高速直连为中心” 。通过NVLink等技术在节点内构建非阻塞的全互联网络,将数十上百张加速卡整合为一个内存统一寻址、算力无缝调用的紧耦合单元,极大降低了张量并行等紧耦合任务中的通信延迟。节点本身再通过InfiniBand/RoCE网络进行Scale-Out扩展,实现“节点内极致性能”与“节点间线性扩展”的统一。
高效互联(生命线):报告构建了“节点内-节点间-集群间”三级高速网络体系。
节点内:依赖NVLink等私有协议或开放标准(如UEC、ODCC的ETH-X),实现卡间超低时延、高带宽直连。
节点间:依赖InfiniBand或优化后的RoCE构建无损集群网络。
集群间:利用高速光传输、广域RDMA等技术,实现跨地域算力协同。报告特别提到了国内在开放互联(如腾讯等推动的ETH-X)和国际标准(如UEC、UALink)方面的生态建设努力。
存储与内存突破(弹药库):为突破“内存墙”,采用“Chiplet(芯粒)+ HBM(高带宽内存)”的先进封装,在物理上缩短数据路径。同时,利用CXL协议实现节点间的内存池化,为千亿参数模型提供远超单机物理内存的弹性共享资源,是支撑大模型训练的关键。
异构计算与高密集成(密度与效率):采用“CPU+GPU+NPU/TPU”的异构架构,各司其职。通过高密度服务器设计(如单机柜64卡甚至640卡),结合液冷(从“可选项”变为“刚需”),实现算力密度的数量级提升和能耗效率的优化。
智能调度与绿色供能(大脑与心脏):软件定义的智能调度平台,实现训练与推理任务的混合部署、异构芯片的统一调度,旨在将集群利用率从不足30%提升至90%以上。液冷技术是保障高密度算力稳定运行、降低PUE的核心。
三、 应用场景:从通用能力到行业纵深的价值落地
报告展示了AI计算节点如何从技术概念转化为实际生产力:
大模型训练:这是AI计算节点的“主战场”。其价值在于通过前述技术,解决万亿参数模型训练中通信同步、内存不足和长周期运行稳定性三大难题。国内厂商(如新华三、浪潮、华为、中科曙光)已在2025年密集推出单机柜64卡至640卡的产品,竞争白热化。
高并发推理:面对ChatGPT类服务的百万级并发需求,AI计算节点通过高速缓存、算子拆分、共享显存池、弹性伸缩等技术,实现低延迟、高吞吐、低成本推理。报告以昆仑芯优化DeepSeek-V3推理为例,说明了其价值。
行业智能化(未来增长点):报告重点剖析了金融、工业、能源三大行业,表明其应用正从互联网科技公司向传统行业核心业务系统渗透。
金融风控:实现毫秒级欺诈交易拦截,并将模型训练周期从数周缩短至数小时。
工业质检:支持上百路高清视频流毫秒级分析,实现微米级缺陷检测。
能源调度:融合气象与电网数据,实现新能源功率的精准预测和多时空尺度优化调度。国家电网、中国太保、吉利汽车等案例显示了明确的行业需求。
四、 产业生态:国际垄断与国内“系统创新+开放协同”的双轨竞争
报告对国内外生态的对比分析极具洞察力:
国际生态:呈现 “技术引领与生态开放并行” 的特点。
生产侧:英伟达是绝对主导者,凭借其全栈(GPU、NVLink、NVSwitch、CUDA)构建了封闭但强大的“护城河”。AMD、博通等在特定领域竞争。同时,由谷歌、微软、AMD等巨头推动的UALink、UEC等开放联盟,正试图打破垄断,构建开放的互联标准。
应用侧:由云巨头(AWS, Azure, GCP)和科技巨头(Meta, Google)主导,他们既是最大买家,也通过自研芯片(如TPU, Trainium)和参与标准制定,反向影响硬件发展路径。
国内生态:走的是 “多主体协同与自主生态构建” 的路径。
核心策略:在单芯片(如昇腾、寒武纪、海光、沐曦)性能短期难以匹敌的情况下,通过系统级架构创新(如高速互联拓扑、液冷集群设计)和软硬件协同优化,弥补单点差距,提升整体集群效率。
发展模式:强调“自主核心+开放兼容”。一方面自主研发关键技术(如腾讯的EthLink,阿里的ALink),另一方面积极融入国际开放标准(如参与UEC、ODCC合作),避免被孤立。形成运营商、云厂商、硬件企业、科研机构(如中国电信、百度、华为、鹏城实验室)深度协同的格局,共同推动解决方案在政务、工业、金融等场景落地。
五、 未来趋势:从技术创新到生态融合与全域渗透
报告展望了四个关键趋势:
政策层面:聚焦自主创新与产业链协同。政策将从鼓励单纯建集群,转向支持芯片互联、架构设计等“系统级”关键技术攻关,并通过产业联盟推动标准制定和规模化应用。
技术层面:持续追求高效互联与高密集成。未来将探索全光互联、更先进的封装(Chiplet)、训推一体架构以及AI驱动的动态资源调度,目标是进一步提升效能、降低功耗。
产业层面:格局呈现头部引领与多方协同。具备全栈能力的巨头(云厂商、电信运营商)将主导生态。商业模式从卖硬件转向提供“算力即服务”、“模型即服务”的一体化方案。构建开放、解耦、标准化的产业生态成为共识,以降低适配成本,汇聚产业力量。
应用层面:从试点示范向全域渗透。将从大模型训练/推理,深度下沉到金融风控、药物研发、智能制造等各行各业的核心业务系统,出现更多深度定制化的“行业AI计算节点”解决方案,成为支撑产业智能化的通用底座。
总结而言,这份报告清晰地描绘了AI计算节点作为下一代智算基础设施核心的完整图景:它是在大模型时代需求驱动下,为突破系统级算力瓶颈而产生的新型集成化算力模块。其竞争已超越单纯的硬件性能比拼,进入以架构设计、互联协议、软件生态和产业协同为焦点的系统性能力竞赛阶段。国际上面临封闭生态与开放路线的博弈,国内则依托庞大的应用市场和系统级创新,走一条多主体协同、自主开放的特色发展路径。未来,AI计算节点将从技术高地向千行百业渗透,成为驱动数字经济与实体经济深度融合的关键力量。

















【锋行链盟】

锋行链盟一站式企业全周期赋能平台
已累计服务付费会员超 5000+,构建起高粘性、高价值的企业服务生态。依托由研究院、上市公司高管、创始人、投资人、券商投行、高校及政府机构组成的高端会员生态,为企业提供资源共享、专业人才对接、项目合作及港股 / 纳斯达克上市等全链条服务。
资源共享
汇聚企业、投资机构、政府部门、科研院所等核心资源,实现信息、渠道与机会互通。
项目合作与产业协同
提供产业链上下游匹配、技术合作、政企合作、园区落地、项目路演等合作机会。
专业化上市服务
由资深投行背景团队提供全流程上市辅导,助力企业登陆资本市场:
上市前期筹备
企业上市资质诊断、合规性梳理、财务规范指导、股权架构设计;
上市路径规划
结合企业实际情况,纳斯达克、香港联交所等多板块上市路径分析与选择建议;
中介机构对接
精准对接头部券商、知名律所、会计师事务所、保荐机构,降低沟通成本;
资本运作支持
涵盖上市融资、并购重组、再融资等全流程财务顾问服务,保障上市进程顺畅。