


写在前面
面对 NVIDIA 从 A100 到 B300 的数十款产品,加上各种"特供版"和出口管制政策,要做出正确决策并不容易。本文系统梳理了 NVIDIA 全系列 GPU 的技术参数、市场定位和合规现状,为面临类似选择的人提供参考。
一、产品线全景:五大架构代际
NVIDIA 的 GPU 架构演进可以用一条清晰的时间线来概括:

| Volta | ||||
| Turing | ||||
| Ampere | ||||
| Ada Lovelace | ||||
| Hopper | ||||
| Blackwell | ||||
| Blackwell Ultra | ||||
| Rubin |
架构的演进不只是制程的缩小,更是针对 AI 计算场景的深度优化。Hopper 架构引入的 Transformer Engine 让大模型训练效率提升了数倍,而 Blackwell 的 FP4 精度支持则进一步压缩了推理成本。
二、数据中心级 GPU 深度解析
2.1 旗舰型号参数对比
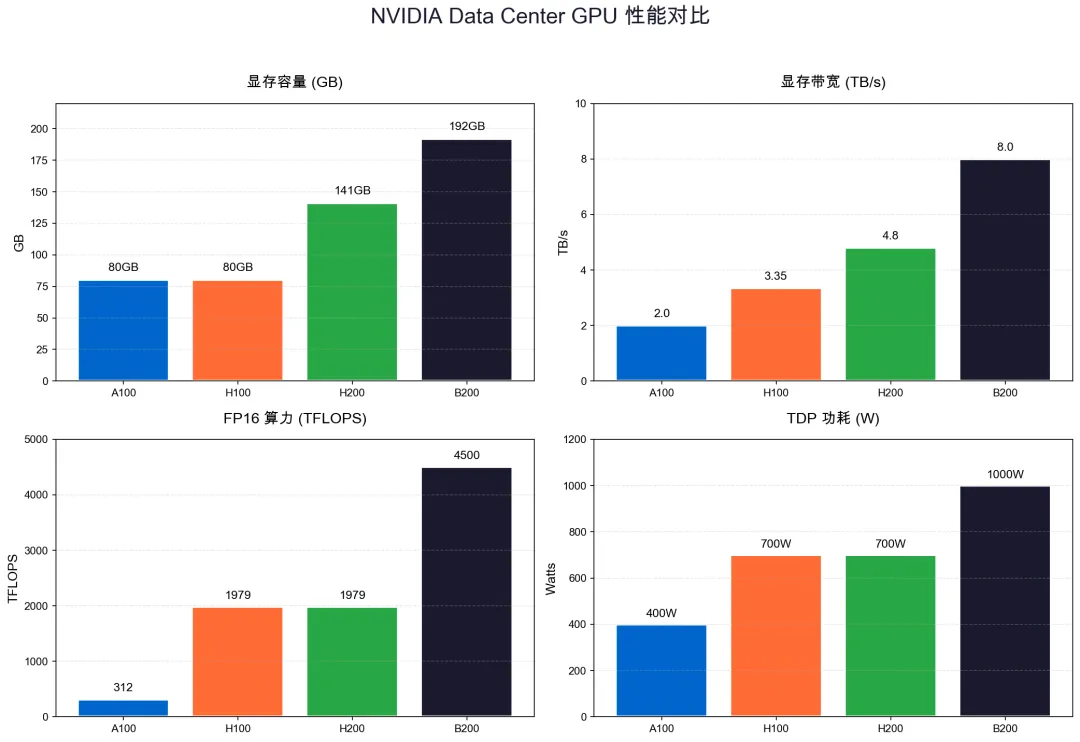
数据中心 GPU 是 NVIDIA 的营收主力,也是技术创新的最前沿。以下是当前主流型号的详细规格:
| 架构 | |||||
| 制程 | |||||
| 晶体管数 | |||||
| CUDA 核心 | |||||
| Tensor Core | |||||
| 显存类型 | |||||
| 显存容量 | 288GB | ||||
| 显存带宽 | 8.0 TB/s | ||||
| TDP 功耗 | 1400W | ||||
| NVLink 带宽 | |||||
| FP64 (TFLOPS) | |||||
| FP32 (TFLOPS) | |||||
| FP16 (TFLOPS) | |||||
| FP8 (TFLOPS) | |||||
| FP4 (TFLOPS) | 30,000-38,900 | ||||
| 参考价格 | |||||
| 发布时间 |
*注:B200/B300 部分性能参数为预估值;B300显存采用12层HBM3e堆叠技术
从这张表可以看出几个关键趋势:
显存容量和带宽的跃升:从 A100 的 80GB HBM2e 到 B200 的 192GB HBM3e,显存容量翻了 2.4 倍,带宽翻了 4 倍。这对于大模型训练至关重要——显存决定了能加载多大的模型,带宽决定了数据喂给计算单元的速度。
精度支持的演进:Hopper 引入 FP8,Blackwell 引入 FP4,每一代新精度都能带来约 2 倍的吞吐提升。对于推理场景,FP4 意味着同样的硬件能服务更多的并发请求。
功耗的持续攀升:单卡 TDP 从 A100 的 400W 涨到 B200 的 1000W,这对数据中心的散热和供电提出了更高要求。液冷正在从可选项变成必选项。
2.2 推理专用 GPU
并非所有场景都需要旗舰卡的算力。NVIDIA 也提供了面向推理优化的产品线:
| 架构 | |||
| 显存 | |||
| TDP | |||
| 定位 | |||
| 参考价格 | |||
| 适用场景 |
T4 和 L4 的低功耗设计(70W 左右)使其适合大规模部署在边缘节点。L40S 则是 A100 停产后,国内能买到的最接近训练卡的产品,但 GDDR6 显存的带宽远低于 HBM,大模型训练时容易成为瓶颈。
三、中国市场特供版:合规与限制
3.1 特供版芯片清单
受美国出口管制(ECCN 3A090 等规则)影响,NVIDIA 为中国市场推出了多款"降规版"芯片:
| A800 | ||||
| H800 | ||||
| H20 | ||||
| RTX 4090D | ||||
| RTX 5090D |
3.2 H20 与 H100 的详细对比
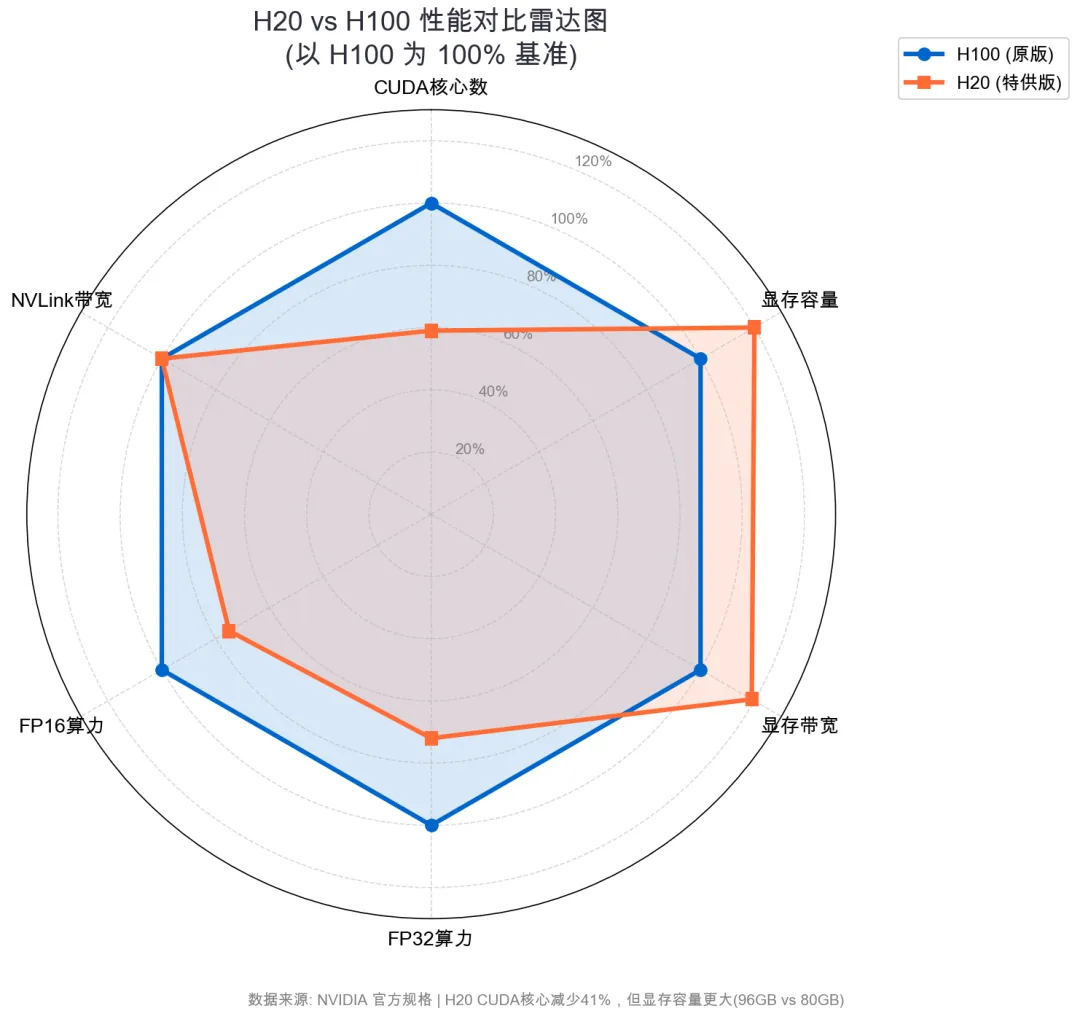
H20 是目前中国市场能买到的最强 NVIDIA AI 芯片,了解它与 H100 的差距对选型至关重要:
| CUDA 核心数 | |||
| 显存容量 | |||
| 显存带宽 | |||
| NVLink 带宽 | |||
| FP32 算力 | |||
| FP16 算力 | |||
| 互联方式 |
一个有趣的细节:H20 的显存容量(96GB)反而比 H100 基础版(80GB)更大,显存带宽也略高。这意味着在显存受限的场景(如大模型推理),H20 可能表现优于预期。但在计算密集型任务(如训练)中,CUDA 核心的削减会直接导致性能下降约 28%。
3.3 出口管制现状(截至 2026 年 3 月)
根据公开报道和政策文件,目前的管制态势如下:
已明确禁售的产品:
• A100、A800、H100、H800 • L40、L40S • RTX 4090(原版) • B200、B300、GB300(最新Blackwell架构全系列受限)
需要许可证的产品:
• H20(2025年4月16日起,英伟达宣布需"无限期"申请许可,2026年政策仍在持续) • H200(虽获出口许可,但据报道对华销量为零,2026财年确认无中国收入)
目前可购买的产品:
• RTX 4090D、RTX 5090D • RTX 6000 Ada / RTX PRO 6000 Blackwell(专业卡) • RTX PRO 4000/2000 Blackwell(小型工作站卡) • L4、T4
2026年最新动态:
• 英伟达2026财年Q4(2025年11月-2026年1月)财报确认,H200对华销售"数量为零" • GB300 NVL72系统已在2026财年贡献110亿美元收入,但全部来自非中国市场 • 英伟达正在开发新的中国特供版芯片以符合出口管制要求
风险提示:出口管制政策变化频繁。2025年4月的 H20 禁令就让许多正在部署的企业措手不及。建议企业在采购前确认最新政策,并考虑备用方案。
3.4 采购路径建议
对于中国企业,目前的采购选择可以分为几个梯队:
第一梯队(合规但性能受限):
• H20(如能获得许可) • RTX 4090D/5090D(消费级,适合小规模训练/推理)
第二梯队(灰色地带,风险较高):
• 通过第三国转口的 H100/H200 • 二手市场的 A100
第三梯队(国产替代):
• 华为昇腾 910B/910C • 寒武纪 MLU370/590 • 海光 DCU
需要指出的是,国产芯片在软件生态(CUDA vs. CANN)上仍有差距,但在特定场景(如华为昇腾对 Transformer 模型的优化)已具备可用性。
四、消费级与专业级 GPU
4.1 GeForce RTX 系列(游戏/创作)
RTX 4090/5090 虽然定位为游戏卡,但其 24GB/32GB 显存和强大的 FP16 算力,使其成为小规模 AI 训练的热门选择。4090D 相比原版削减了约 11% 的 CUDA 核心,但在大多数场景下差距不明显。
4.2 RTX Pro 专业卡系列
专业卡的优势在于驱动认证(ISV 认证)、更大的显存和更稳定的供货。对于需要长期运行的生产环境,专业卡的可靠性值得考虑。
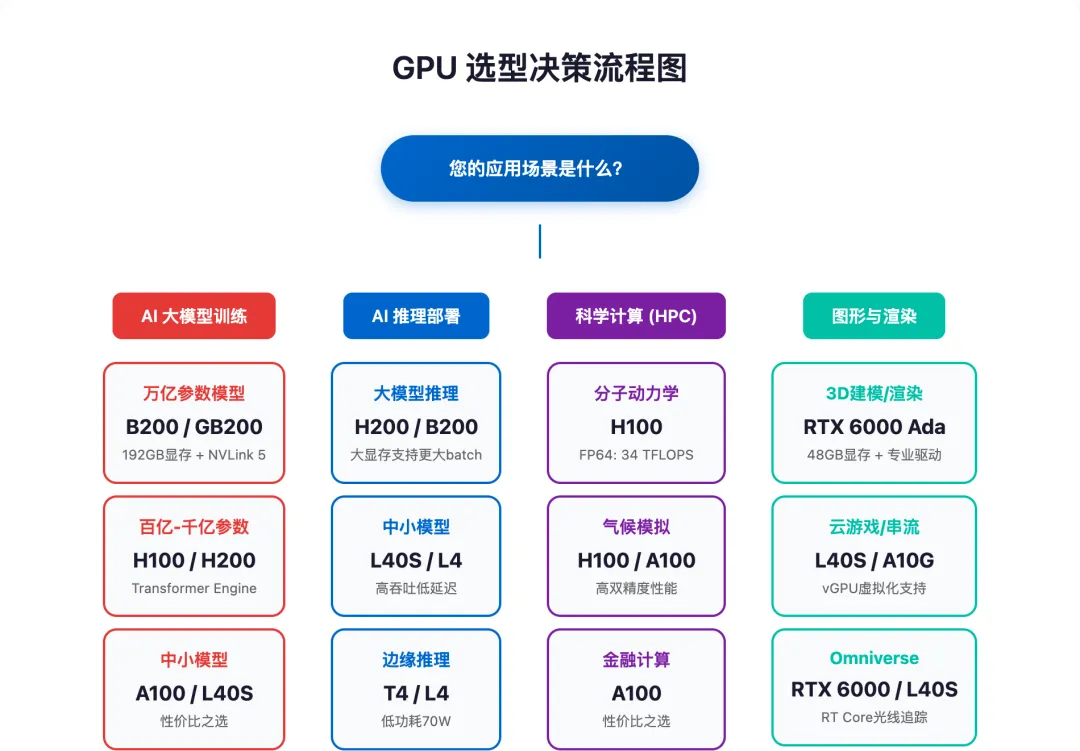
五、应用场景选型指南
5.1 AI 大模型训练
万亿参数模型(GPT-4 级别):
• 首选:B300 / GB300 NVL72(2025-2026年最新) • 次选:B200 / GB200 NVL72 • 理由:B300配备288GB HBM3e显存(比B200提升50%),TDP 1400W,FP4精度下算力高达30-38.9 PFLOPS • 价格参考:B300单卡预计350-400万;B200单卡约$30,000-40,000(已受限)
百亿到千亿参数模型:
• 首选:H100 / H200 • 备选:H20(如预算有限且能获得许可) • 理由:Transformer Engine 对 LLM 训练有显著加速 • 价格参考:H100 ~27,000(约¥19万);H20 ¥11万/颗(中国市场)
中小模型(<100B 参数):
• 首选:A100(如仍有库存)/ L40S • 消费级备选:RTX 4090D 多卡并联
5.2 AI 推理部署
大模型推理(Llama 3 70B 级别):
• 首选:H200 / B200 • 理由:大显存可支持更大 batch size,高带宽降低延迟
中小模型推理:
• 首选:L40S / L4 • 理由:L40S 的 48GB 显存可部署 70B 级模型 INT4 量化版本
边缘推理:
• 首选:T4 / L4 • 理由:低功耗(70W),可大规模部署
5.3 科学计算(HPC)
分子动力学、气候模拟等场景对 FP64(双精度)性能敏感:
注意:消费级 RTX 卡的 FP64 性能被大幅削减,不适合科学计算。
5.4 图形与渲染
3D 建模/渲染:
• 首选:RTX 6000 Ada / RTX 5000 Ada • 理由:大显存可加载复杂场景,专业驱动稳定性更好
云游戏/串流:
• 首选:L40S / A10G • 理由:支持虚拟化(vGPU),可多用户共享
Omniverse/数字孪生:
• 首选:RTX 6000 Ada / L40S • 理由:需要 RT Core 加速光线追踪
六、未来趋势与风险提示
6.1 技术演进方向
从 Blackwell 到 Blackwell Ultra 的演进,可以看出 NVIDIA 的技术路线:
显存持续扩容:B300配备288GB HBM3e显存(采用12层堆叠技术),相比B200的192GB提升50%。预计2026年Rubin架构将进一步突破显存容量限制。
功耗与性能同步提升:B300 TDP达到1400W,GB300 NVL72系统在2026财年已贡献110亿美元收入,成为数据中心主力产品。
更低精度计算:FP4已在Blackwell系列成熟应用,推理成本较FP8再降50%。未来可能看到FP2甚至更低精度的支持。
Chiplet与多芯片封装:B200/B300采用MCM设计,Rubin架构(2026年预告)将进一步推进模块化设计,采用3nm制程。
CPU-GPU融合深化:GB300延续Grace+Blackwell组合,显存带宽达16TB/s,FP4算力30-38.9 PFLOPS。
6.2 地缘政治风险
对于中国企业,采购 NVIDIA 芯片面临的不确定性在增加:
断供风险:H20 的许可证要求表明,即使是"合规版"芯片也可能随时受限。企业应建立至少 6 个月的库存缓冲。
技术代差:B300/GB300已确认无法进入中国市场,Rubin架构(2026年)预计也将受限。中国企业与国际先进水平的差距可能进一步拉大。
国产替代进展:华为昇腾 910C 据称性能接近 H100,寒武纪、海光等也在快速迭代。软件生态(CUDA 兼容性)仍是最大短板。
6.3 采购决策建议
基于以上分析,对不同企业的建议:
大型云厂商:
• 继续争取 H20 进口许可 • 同步测试华为昇腾等国产方案,做好双栈准备 • 关注软件生态迁移成本
中小 AI 企业:
• RTX 4090D/5090D 仍是性价比之选 • 考虑云服务(如阿里云、腾讯云)的 GPU 实例,转移硬件风险
科研机构:
• 利用高校/研究所的进口渠道优势 • 关注国家超算中心的资源申请
附录:关键术语解释
| CUDA Core | |
| Tensor Core | |
| RT Core | |
| HBM | |
| NVLink | |
| TDP | |
| Transformer Engine | |
| FP8/FP4 | |
| ECCN 3A090 |
参考资料
1. NVIDIA 官方技术文档 (2024-2025) 2. 美国商务部出口管制条例 (EAR) 3. 各芯片规格数据来自厂商公开资料 4. 出口管制相关报道(2024-2025年)
本文技术参数截至 2026 年 3 月,出口管制政策变化频繁,采购前请确认最新法规。