


在AI编码工具快速普及的当下,效率提升的光环背后隐藏着代码质量与生产安全的隐忧。越来越多企业在享受AI编码速度红利的同时,也面临着bug激增、生产中断频发的问题。但这些问题究竟有多严重?AI更易引发哪些类型的bug?又该如何有效规避?
AI编码与人类编码的bug差异
为厘清AI编码的真实问题,国外有研究团队扫描了470个开源GitHub仓库,通过commit信息、IDE配置文件等信号,区分AI协同编写与人类独立编写的PullRequest(PR),最终得出了一组量化且极具参考价值的对比数据,AI编码并非全知全能,其在bug生成、问题严重性上,与人类编码存在显著差异。(文末附下载)
1.AI问题代码数量是人类的1.7倍
从整体数据来看,AI生成代码的bug总数是人类的1.7倍,且更易引发高风险问题。
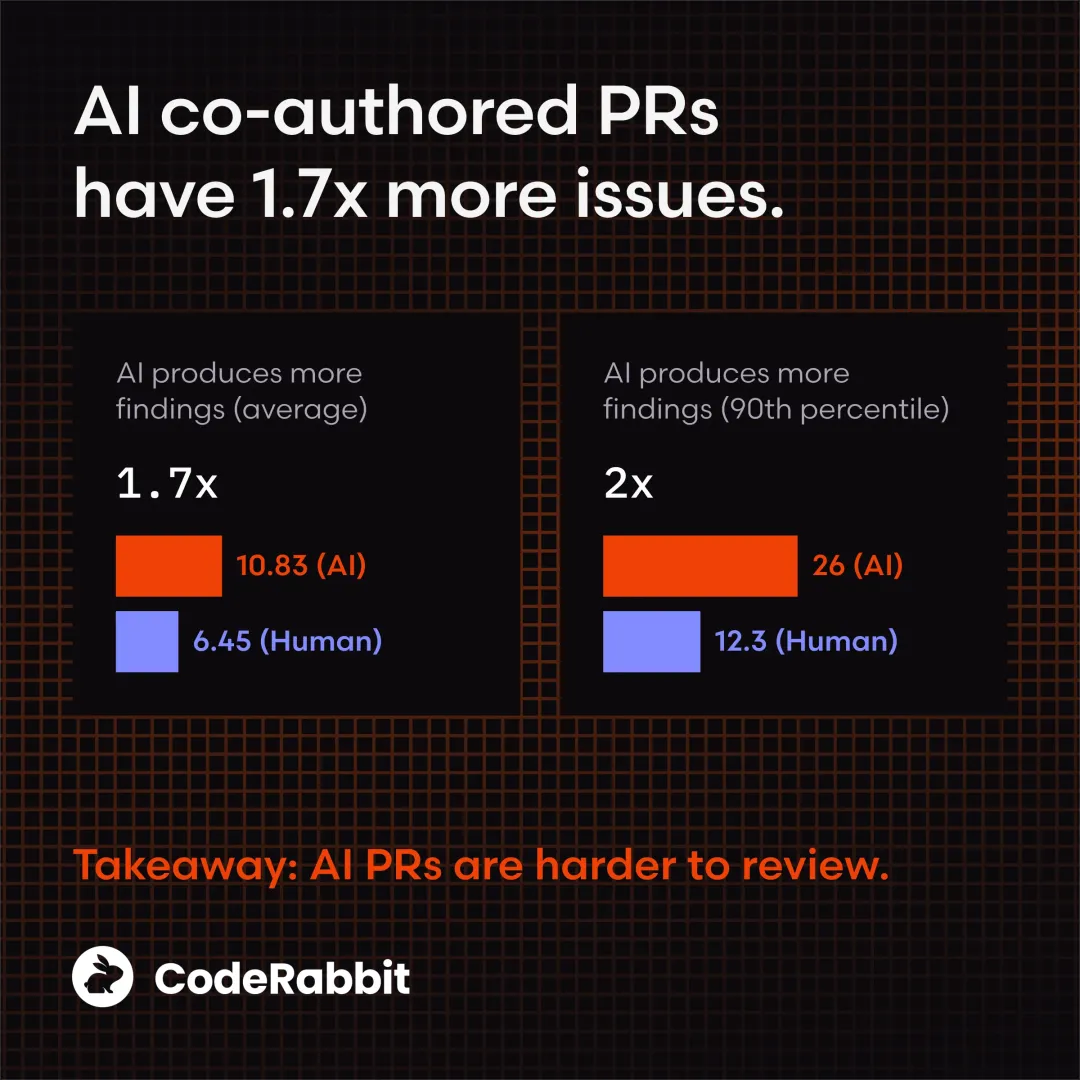
AI创建的重大问题代码数量是人类的1.4-1.7倍。这意味着,AI编码虽然能快速产出代码,但问题代码的比例更高,且可能直接威胁生产环境稳定。这类问题一旦流入生产,往往会导致服务中断、功能失效等情况。

2.核心问题类型
逻辑与正确性问题:AI代码在这类错误上比人工代码高出75%,平均每百个PR中出现194处此类问题,包括逻辑错误、依赖配置错误和控制流问题。这类错误往往看起来代码结构完整、语法无误,但在实际执行中会触发隐藏漏洞,它们在代码审查中极易被忽略,审查者需要逐行梳理逻辑才能发现问题,而非简单检查语法或格式。

安全漏洞:AI代码引入安全问题的概率是人工的1.5-2倍,典型问题包括密码处理不当和不安全的对象引用。这源于AI训练数据中包含大量未经过安全审计的开源代码,且AI在生成代码时更关注功能实现,而非安全合规。

性能问题:虽然AI编码的性能bug总量不多,但杀伤力极强。研究发现,AI生成的代码中,过度I/O操作问题的发生率是人类的8倍,这类问题会直接导致系统资源占用过高、响应延迟增加,在高并发场景下可能引发服务雪崩。

并发与依赖问题:AI在处理复杂场景时,对时序和依赖关系的把控明显不足。在并发原语误用(如锁竞争、线程安全问题)、依赖包版本冲突、代码执行顺序错误等问题上,AI的出错概率是人类的2倍,这类问题会导致代码在多线程环境下出现数据不一致、服务不稳定等情况。

可读性与维护性问题:AI代码的技术债隐患更突出。AI生成代码的可读性问题是人类的3倍,具体表现为格式混乱、命名不规范、注释缺失或冗余。虽然这类问题不会直接导致服务中断,但会大幅增加后续调试、迭代的成本。当代码库中AI生成的难读代码积累到一定程度,会让维护者难以理解逻辑,进而延长故障排查时间,甚至因误改代码引入新问题。
值得注意的是,AI编码也并非全是劣势,在拼写错误、难以测试的代码生成上,AI的表现优于人类。
AI编码为何易出bug?
AI编码Agent的bug问题,并非单纯源于模型能力不足,而是技术原理限制与人类使用方式共同作用的结果。
1.技术原理局限:上下文缺失与预测式生成的先天短板
当前主流AI编码工具的核心是大语言模型(LLM),其训练逻辑是基于海量数据预测下一个token,这一原理决定了它的先天局限:
缺乏专属上下文:LLM的训练数据多来自公开开源代码,而非企业内部的代码库。这意味着,AI无法精准理解企业特有的代码规范、业务逻辑、依赖关系,生成的代码可能与现有系统水土不服,比如误用内部封装的工具类、违背团队约定的接口设计规则。
上下文窗口的遗忘效应:为适配长文本处理,LLM会采用上下文窗口压缩或滑动窗口策略。当任务链条较长(如生成代码→审查→修改→验证)时,AI会逐渐丢失前期的任务信息,比如忘记某个函数的设计目标、忽略某个参数的约束条件,最终导致代码偏离需求。
2.使用方式误区:自主化与规模化放大风险
随着AI Agent技术的发展,越来越多团队让AI自主运行(无需人工干预),甚至长时间批量处理任务。这种使用方式会让小错误不断叠加,最终酿成大问题:
错误复利效应:AI在自主执行过程中,若某一步出现幻觉(生成不存在的逻辑)或上下文偏差,后续步骤会基于这个错误继续生成代码,导致错误滚雪球。比如,AI误判某个接口的返回格式后,后续依赖该接口的代码都会出现解析错误,且这些错误会隐藏在大量代码中,难以定位。
快而不精的陷阱:AI能在分钟级生成数百行代码,不少团队因此追求多窗口并行开发,同时推进多个功能模块。但这种速度优先的模式,会忽略对代码逻辑的实时校验,也会让后续审查时因代码量过大而难以全面覆盖,最终让隐患流入生产。
如何降低AI编码的风险?
AI编码的效率价值不可否认,但必须通过科学的使用方法,平衡速度与质量。从任务启动到代码落地,每个环节都有可优化的空间。
1.预先规划
在启动AI编码前,必须先梳理清晰的需求与上下文,避免AI无的放矢。先制定详细的技术规格文档(包括功能目标、接口设计、边界条件、错误处理规则),将模糊的需求转化为AI可理解的结构化信息。这能帮AI锁定核心目标,减少因需求理解偏差导致的逻辑错误。还需补充专属上下文,将团队的代码风格指南、内部库文档、现有系统的依赖关系等,作为前置信息提供给AI,让生成的代码更贴合企业实际场景,减少水土不服的问题。
2.选对LLM
不同LLM的训练侧重不同,并非最新最贵就最适合。要避免一刀切选择,比如某模型擅长生成简单业务逻辑代码,但在处理并发、安全相关场景时表现不佳;另一模型可能在代码可读性上更优,但生成效率较低。需通过内部测试或参考行业测评数据,为不同任务选择适配的LLM。例如,生成安全敏感代码(如认证逻辑)时,选择在安全合规性上表现更好的模型;生成工具类代码时,选择效率更高的模型。同时,避免频繁切换LLM,防止因模型对prompt的理解差异,导致代码风格混乱或逻辑偏差。
3.拆解任务
将大任务拆分为最小可执行单元,是降低AI错误的关键。比如,将开发用户登录模块拆分为设计登录接口→实现密码加密→编写登录校验逻辑→添加异常处理4个小任务,每个任务仅让AI生成10-50行代码。小任务的上下文更清晰,AI不易遗忘,生成的代码也更易审查。同时控制Agent运行时长,避免让AI自主运行数小时批量生成代码,而是每完成一个小任务就人工介入校验,确认逻辑无误后再启动下一个任务。这能及时发现错误,避免错误复利效应。
4.差异化审查
AI代码的审查不能沿用人类代码的标准,必须针对其高风险点重点盯防、明确审查重点。面对AI生成的PR,优先检查逻辑正确性(逐行梳理业务逻辑、验证边界条件)、安全合规性(检查密码处理、权限控制、输入校验)、依赖与并发(确认依赖包版本、排查线程安全问题)。遵循小PR优先原则,若AI生成的PR代码量超过100行,需拆分后审查;同时,避免因代码量大、看起来复杂就放松审查,必须确保每个关键逻辑都被覆盖。可采用多人交叉审查,减少单人审查的遗漏风险。
5.借助工具
仅靠人工审查难以应对AI编码的规模化风险,必须借助工具构建多层防御体系:第一,强化自动化校验:完善单元测试、集成测试用例,确保AI生成的代码能通过自动化测试;引入静态代码分析工具,实时检测安全漏洞、性能隐患(如过度I/O)、代码规范问题。第二,用AI反制AI:利用AI辅助审查工具,对AI生成的代码进行二次校验。这类工具能基于历史bug数据,快速定位AI常见的逻辑错误、安全问题,减少人工审查的盲区。第三,完善QA流程:制定针对AI代码的QA校验(包括逻辑、安全、性能、可读性等维度),确保每个环节都有明确的校验标准;同时,加强生产环境的可观测性(如日志监控、性能告警),及时发现AI代码引发的潜在问题。
小结
2025年,多家科技巨头曾以AI生成代码占比作为效率标杆,但事实证明,代码行数从未是衡量软件价值的有效指标。AI编码的真正价值,不应是更快产出代码,而是在保证质量的前提下提升效率。随着行业对AI编码风险的认知加深,2026年正在成为AI编码质量年,科学使用AI、平衡速度与质量将成为行业共识。
究模智后台对话框回复20260224即可下载!
原文链接:
https://www.coderabbit.ai/blog/state-of-ai-vs-human-code-generation-report
