




核心结论

投资要点:
◾ 以光电融合共封装,实现密度、性能、能效、架构全面跃升:
CPO作为下一代数据中心互连的核心技术,通过光电芯片的封装级深度融合,全面突破铜互连与可插拔光模块的物理边界,在密度、性能、能效与系统架构四个维度实现代际跃升。相较铜缆,其以光代电,彻底打破高速传输的距离与带宽瓶颈;相较可插拔光模块,CPO将端口带宽密度提升一个数量级,为224G+ SerDes与太比特级交换架构提供底层支撑,同时系统级功耗下降可达50%以上。通过缩短电通道、统一热管理及简化光布线,CPO进一步提升系统可靠性并优化整体 TCO,正在重塑高端算力互连的技术范式。
◾ 海外巨头技术演进全面提速,产业化进程有望较27年前移:
全球算力龙头正同步加速CPO技术路线落地。NVIDIA已明确2025–2026年“双代递进”商用节奏,从强调可维护性的准共封装快速演进至深度共封装形态,直接服务超大规模AI集群互连需求。Broadcom持续推动CPO平台向更高交换带宽(102.4T)与先进封装体系(FOWLP、COUPE)演进,并以开放生态模式带动产业链成熟。Intel则从先进封装与光电耦合基础能力切入,分阶段夯实规模制造条件。三大巨头分别从系统牵引、制造平台与底层技术三端形成合力,标志着CPO正由技术验证期迈向工程化部署阶段,大规模应用窗口有望早于此前市场预期。
◾ Scale-up增量厚积薄发,激活全产业链共同向上:
CPO的真正增长引擎来自Scale-up高带宽互连的刚性需求,而非传统Scale-out网络的成本替代逻辑。以NVIDIA Blackwell架构为例,其NVLink单GPU互连带宽已达7.2Tbps,约为800G以太网方案的9倍,传统可插拔光模块在功耗与带宽密度上已逼近物理极限。CPO凭借极短电通道与高集成光引擎,成为当前能够同时满足超高速率、低功耗与高端口密度的系统级方案,确立其在Scale-up领域的战略卡位。这一架构升级正推动产业链价值重构:上游硅光芯片与高性能激光器价值量显著提升,中游先进封装与光电协同制造成为核心壁垒,下游AI系统与液冷散热需求同步扩张。CPO不再只是单点器件创新,而是正在成为驱动新一代算力基础设施升级的核心技术底座。
◾ 关注标的
如需获取完整报告,欢迎联系国投证券电子团队或对口销售
◾ 风险提示:
新技术发展不及预期;市场竞争加剧;AI发展及投资不及预期。
分析师:
马良: S1450518060001
常思远: S1450525120001

报告正文

01光电融合革命:CPO技术如何重塑下一代算力基础设施
共封装光学CPO(Co-Packaged Optics) 是一种将光引擎与交换ASIC芯片通过高密度互连集成于同一封装载体内的先进架构。该技术通过将光引擎紧邻ASIC封装,显著缩短高速电接口(如SerDes)的传输距离,实现芯片间(D2D)及设备间(M2M)的短距光互连。CPO方案省去了传统架构中复杂的射频走线及 Redriver/Retimer 等中继器件,从而显著降低功耗与系统成本,实现更高的集成度与带宽密度。在该架构下,光引擎取代传统光模块,成为光电转换的核心单元,被视为下一代低功耗、高集成度封装技术的主要发展方向。
CPO正成为突破算力扩展瓶颈的关键技术,其价值将在Scale-Up与Scale-Out两大路径中充分体现。在Scale-Up层面,CPO旨在解决节点内GPU互联的物理限制。传统铜缆在200Gbps/lane及以上速率时,传输距离最多只有两米且功耗高。CPO通过光电深度融合,将能效提升至接近大规模商用临界点(当前Nvidia方案已达5.6pJ/bit,逼近铜缆5pJ/bit替代阈值),从而打破机箱边界,实现跨机柜的低延迟统一内存访问,为构建超大规模计算单体铺平道路。在Scale-Out层面,CPO通过光引擎与交换ASIC的共封装,将助力突破51.2T+交换机的带宽与能效瓶颈。它大幅提升了叶脊网络的互联密度,有效支撑AI Fabric的大规模节点间通信,是实现分布式集群高效横向扩展的核心引擎。
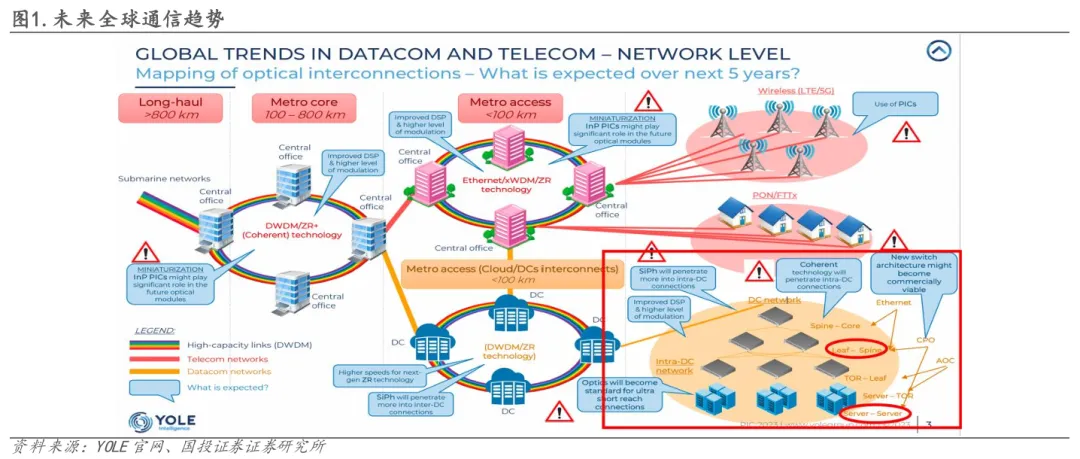
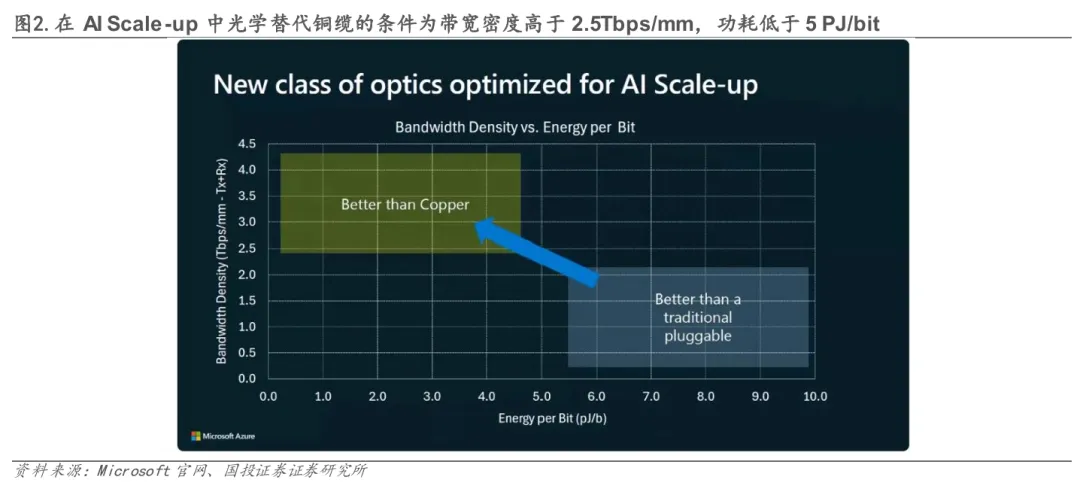
02CPO核心优势:光电融合驱动的架构革新
光模块的演进历程,本质上是一场持续向交换芯片ASIC靠拢、不断缩短电光转换距离的技术革命。纵观发展历程,可插拔光模块(Pluggable)→板载光学(OBO)→近封装光学(NPO)→共封装光学(CPO)→裸片级CPO封装内光学(OIO),这一过程的核心驱动力,始终围绕互连距离的缩短、带宽密度与能效比的提升,以及光电融合的不断深化。在这一演进路径中,CPO相较于目前广泛使用的可插拔架构,展现出高密度、高能效、高性能与架构简化等多重优势;而未来的 OIO 将进一步把光I/O直接集成至计算/存储芯片,取代传统电I/O变为光信号,在带宽与延迟方面实现更深层次优化。
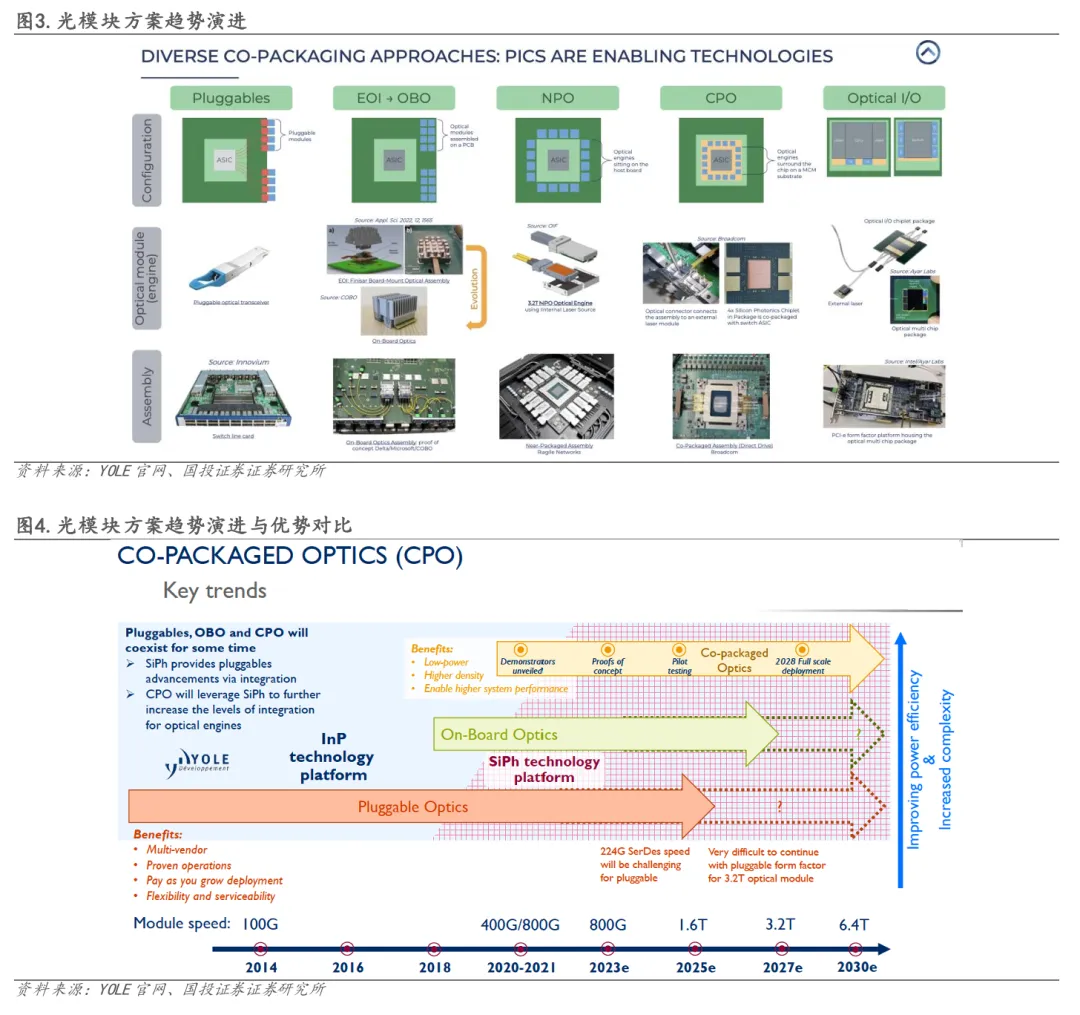
2.1 高密度集成:突破物理空间限制,提升单位面积算力
在CPO架构下,系统集成密度实现数量级提升,显著增强单位面积的计算与通信能力。在相同交换机前面板面积条件下,CPO可支持的光通信端口数量可以突破传统可插拔模块限制。传统可插拔光模块作为独立单元,需配套外壳、连接器及高速SerDes接口,端口密度受限于模块体积与PCB布线资源。相比之下,CPO利用硅光平台与先进封装技术(如CoWoS、微凸块互连),将光引擎以裸芯片形式与交换芯片集成于同一基板,实现百微米级光电互连。从带宽密度来看,传统可插拔光模块通常仅能达到约5–40 Gbps/mm,而共封装光学(CPO)架构可提升至50-200Gbps/mm级别,实现约一个数量级的提升。

2.2 高能效表现:重构光电转换路径,大幅降低系统功耗
2.2.1 架构重构实现能效跃升
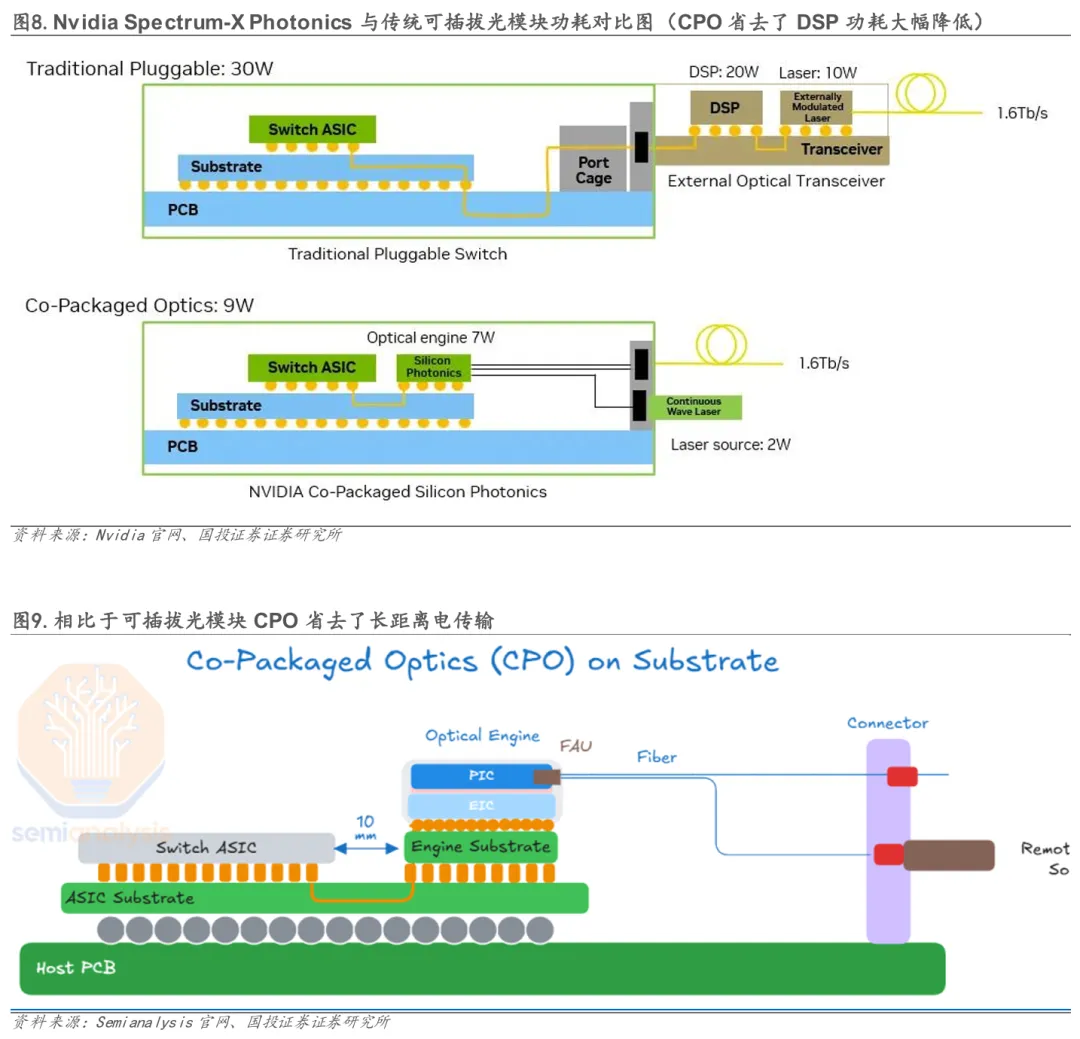
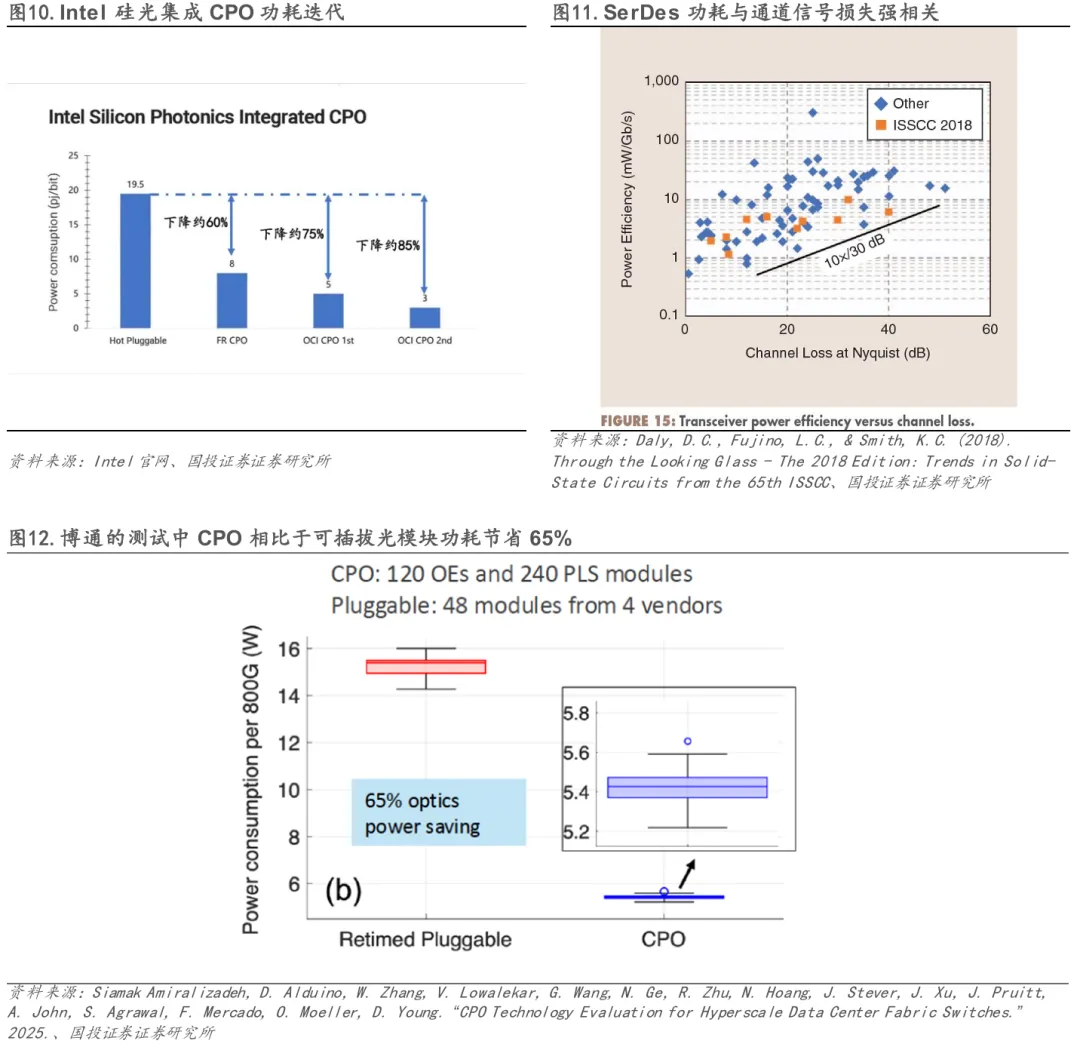
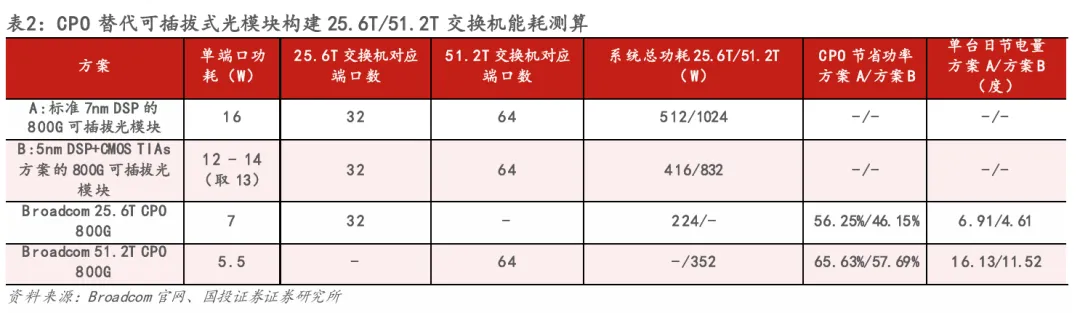
CPO技术最突出的优势在于其卓越的能效表现,能够将光通信系统整体功耗显著降低50%以上。这一突破性成果源自对传统架构中“电-光转换”环节的根本性重构。CPO架构的核心优势源于极短的电互连:1)物理长度的急剧缩短直接降低了驱动功耗与阻抗损耗;2)由此带来的优质信号完整性,降低了对高功耗DSP进行复杂信号补偿的依赖;3)光电协同设计消除了冗余的信号调理链路。实际数据印证了这一优势:以Nvidia Spectrum-X Photonics为例,其1.6Tb/s CPO方案总功耗仅为9W(光引擎7W,激光器2W),而传统可插拔光模块总功耗高达30W(仅DSP就达20W,激光器10W),CPO方案实现了约3.5x的能效提升。博通在 ECOC 2025公布的测试结果显示,在同等800G带宽下,传统800G 2×FR4可插拔光模块功耗约15W,而采用CPO交换芯片时,其光引擎与外置激光源合计功耗约5.4W,对应约65%的功耗下降。在Nvidia的大规模AI集群测算中,CPO的优势进一步放大。以GB300 NVL72架构、三层网络为例,传统DSP光模块仅光收发器即消耗17MW电力;切换至CPO后,光互连相关功耗可下降约84%,即便考虑交换机侧新增光引擎与外置激光源,整体网络功耗仍可降低约23%。若结合CPO高端口密度带来的网络扁平化(由三层向两层演进),总网络功耗降幅可扩大至约48%。
2.2.2 规模部署带来显著节能收益
CPO的节能效益随交换机容量提升而呈指数级放大。在25.6T系统中,CPO相较于可插拔方案节能约46%-56%,单台日节电量约为4.6-6.9度。而当容量升级至51.2T时,其节能幅度进一步提升至58%-66%,单台日节电量大幅增至11.5-16.1度。在大规模数据中心部署下,万台51.2T交换机规模的数据中心每年能够因此省下约4205-5887万度电。这不仅直接转化为巨额电费节省,大幅降低OPEX,更极大地缓解了数据中心的供电和散热压力,降低了碳排放,符合“双碳”战略目标。因此,CPO是未来超大规模数据中心实现高速互联与绿色发展的关键技术路径。
2.3 高性能突破:解决信号完整性瓶颈,支撑高速率与低时延性能
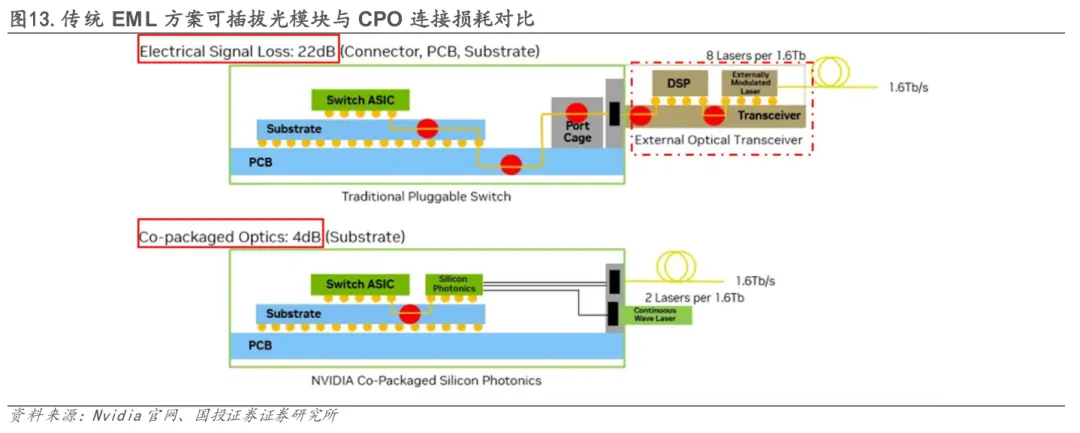
CPO技术从传输速率、信号质量、降低延迟三方面突破了可插拔光模块的性能瓶颈。在传输速率方面,CPO将电互联距离从厘米级缩短至百微米级,这一关键突破大幅降低了信号在传输过程中的衰减、反射和串扰,使得224G及以上SerDes的信号完整性问题得到根本性解决,为稳定实现3.2T及更高速率铺平了道路。在信号质量方面,CPO通过极短距离的电互联,在200Gbps通道,将传统EML方案高达22dB的连接损耗大幅降至仅4dB。更重要的是,虽然光速是有限的,但CPO架构通过两个关键机制实现了纳秒级的延迟降低:1)电信号传输距离的缩短,直接减少了信号传播时间;2)由于传输路径大幅缩短,信号质量显著提升,这使得原本用于信号修复的复杂数字信号处理(DSP)得以简化甚至移除,消除了DSP处理带来的主要延迟。这种纳秒级的延迟降低对于需要极低延迟通信的高性能(HPC)计算和AI训练集群具有重要意义。
2.4 架构简化:降低系统复杂性和总拥有成本
相较于传统可插拔光模块,CPO通过架构层面的深度集成,从根本上降低了系统的整体复杂性与总拥有成本。其核心优势体现在三大关键路径上:
简化信号路径,降低电气复杂度与材料成本:CPO将光引擎与计算/交换芯片在封装内紧密集成,极大地缩短了高速电信号的传输距离。这不仅显著缓解了对PCB材料、布线工艺和信号完整性的极致要求,更直接降低了高速板材的使用与主板设计的复杂度,从而在源头上压缩了硬件成本。
统一热管理,提升散热效率与能源效益:CPO将光学器件纳入主芯片的统一散热体系中,构建了更短、更高效的热管理路径。这种集成化散热方案降低了对复杂独立光模块进行冷却的能耗,提升了整体散热效率,有助于直接降低数据中心的冷却功耗,实现运行成本的节约。
优化物理布局,提升密度与可靠性:CPO采用光纤阵列直接出光,彻底避免了设备内部大量的光纤跳线。这不仅解决了机柜内布线混乱、空间占用多的问题,使得设备布局更加紧凑可控,也减少了因连接器松动和线缆弯折导致的故障点,提升了系统可靠性与可维护性。
总而言之,CPO通过信号路径的简化、热管理的统一与物理布局的优化,实现了系统架构的代际升级,不仅降低了前期的硬件与材料成本,更通过减少空间占用、降低冷却能耗和提升。

03 CPO的核心挑战:架构变革下的四大难题
未来数据中心与智算中心的光互联架构将从单一路线走向“OCS、CPO、可插拔光模块”三路线并存的格局,并形成分层明确、协同发展的技术体系。
OCS依托其超大交换容量与系统级扩展能力,率先在Spine层和大型Scale-up集群中规模落地,已成为万卡级GPU/TPU互联的核心基础设施。目前,谷歌 Apollo 项目在数据中心网络架构中引入全光 OCS方案,逐步替代传统 Clos 架构下的电交换模式,并已在 Spine 层实现规模化部署。
CPO在功耗与带宽密度方面具备结构性优势,是面向高带宽互联的中长期技术路径。但短期仍受良率、返修难度、测试复杂度、异质集成热管理及生态灵活性不足等因素制约。现阶段CPO率先落地于Scale-out交换层面,主要因当前共封装良率仍处爬坡期,失效对系统影响相对可控,更适合作为产业链工艺与系统协同能力的验证场景;而可插拔光模块凭借灵活性、互操作性与成熟供应链,仍将长期主导Leaf层以下机柜内、机架间及中长距离互联市场。
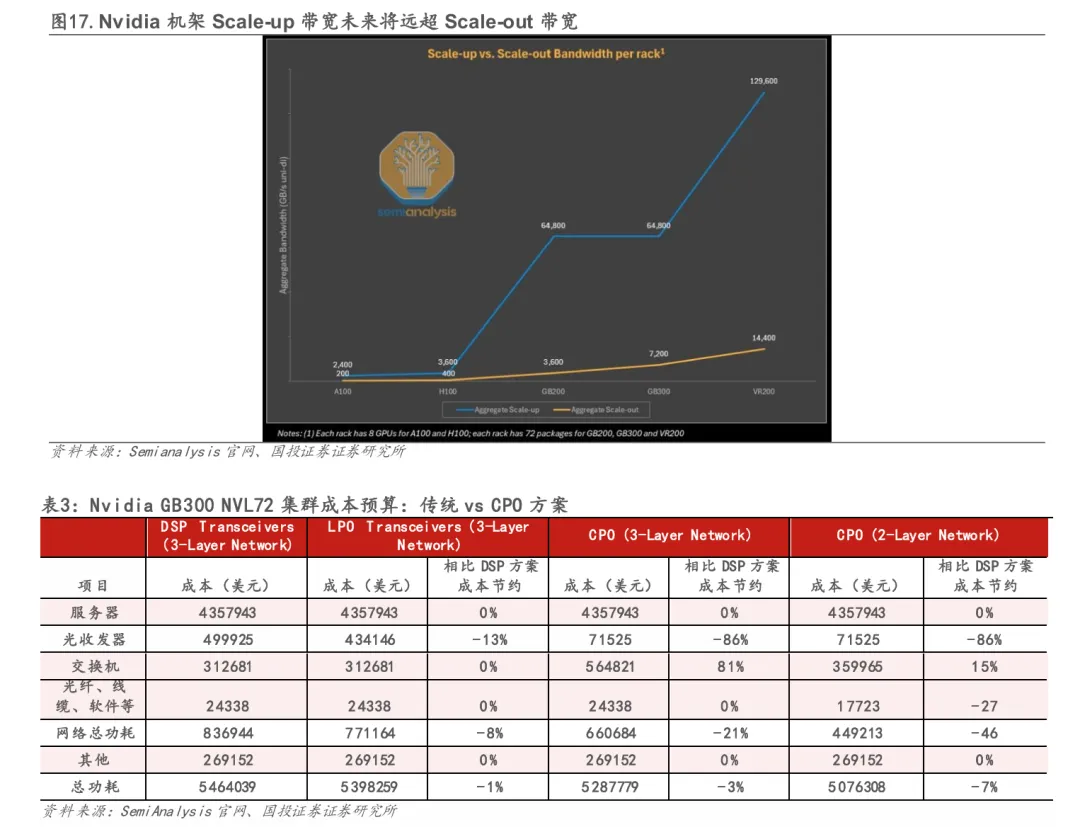
当前CPO在Scale-out中的部署更具“验证属性”,成本优势尚未充分释放。以NVIDIA的CPO交换机方案为例,CPO在TCO层面的改善整体仍较有限。在1.6T交换平台中,传统可插拔方案需配置约72个1.6T光模块,对应光模块成本约7万美元量级;CPO方案采用约36个3.2T光引擎,光学物料成本约3.5–4.0万美元,物料层面具备一定优势。但在系统交付过程中,光引擎、FAU、ELS及配套光纤仍叠加较高系统级毛利,使终端CPO方案的光学相关成本与可插拔方案接近,成本优势并不显著。在三层网络架构下,尽管CPO可显著减少光模块采购数量(降幅约80%以上),但新增封装复杂度与系统集成成本抬升交换机整体成本,最终网络侧TCO降幅约30%;考虑到服务器仍占集群TCO主导,整集群层面的总成本改善仅为个位数。即便网络由三层向两层扁平化演进,CPO对整体TCO的改善幅度也主要体现在中高个位数水平。
CPO的长期主要增量来自于Scale-up互联。 相较Scale-out网络,GPU Scale-up对带宽密度与时延要求呈数量级提升。以 NVIDIA Blackwell 为例,第五代NVLink单GPU单向带宽达900GB/s(7.2Tbps),约为800G以太网Scale-out方案的9倍,推动GPU SerDes速率持续演进,也使传统可插拔光模块在功耗与带宽密度上逐步逼近物理极限。CPO将光电转换前移至封装层,可显著降低互连功耗并提升系统带宽密度与时延表现,更契合Scale-up架构的演进方向。随着Scale-up域规模与互联速率持续提升,其互连TAM增速有望显著快于Scale-out网络,CPO核心市场空间预计最终由Scale-up应用主导。
整体来看,行业正从传统“可插拔”模式迈向“OCS+CPO +可插拔”的立体演进结构,并在不同网络层级基于性能、成本与灵活性需求形成最优技术配置,为新一代高效算力网络奠定基础。根据LightCounting预测,未来五年可插拔光模块仍是市场主导形态;在800G/1.6T端口需求中, CPO端口份额预计将在2026–2028年提升至30%以上。
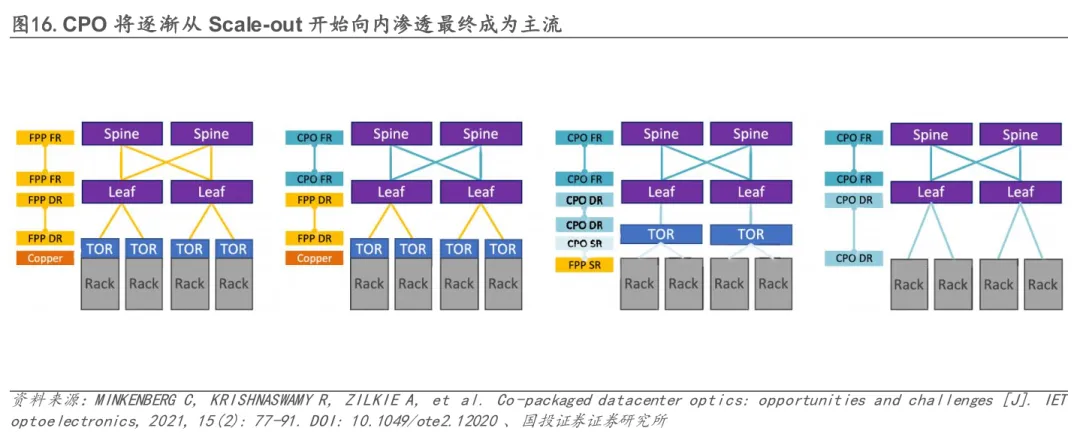
3.1 灵活性缺失与生态锁定
CPO技术的规模化应用,正面临着灵活性缺失、运维成本高昂与供应链生态锁定三大根本性制约。在架构设计上,光引擎与交换芯片 ASIC 的深度集成削弱了系统灵活性,光学接口难以独立升级或现场更换,与数据中心长期采用的模块化、可维护设计理念存在一定冲突;在运维层面,光学与高价值交换芯片的强耦合显著放大单点故障代价,任何光学或芯片层面的异常均可能导致整板甚至整机更换,抬升维护复杂度与隐性TCO。
在产业生态方面,CPO 尚未建立起类似可插拔光模块的成熟认证与标准体系。传统光模块已形成由 IEEE 802.3(PMD 物理层标准)、OIF(电接口与 SerDes 规范) 以及多源协议(MSA,如 QSFP、OSFP 体系) 共同支撑的高度互操作生态,不同厂商产品可实现真正的即插即用,并通过长期的兼容性与可靠性认证。相比之下,CPO在机械形态、光纤接口、外置激光方案及系统级可靠性认证等关键环节仍缺乏统一规范,目前仅有 OIF 针对高密度互连(如 CPX)等方向的探索性推进,整体仍处于标准化早期阶段。部分厂商选择以系统级专有方案推进,易将客户锁定于单一设备供应商;在交换芯片市场已高度集中的背景下(CR5>90%),这一趋势或进一步削弱客户议价能力,并加剧光模块厂商、OSAT 与晶圆代工厂之间的边界模糊与协作不确定性。
3.2 异质集成热管理难问题
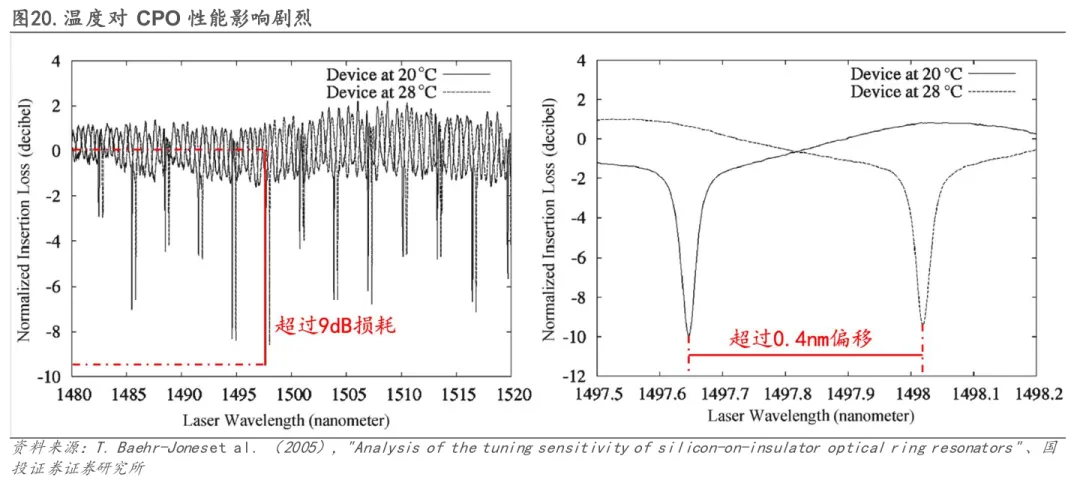
CPO技术在热管理方面面临严峻挑战,其核心矛盾在于将两个热行为截然不同的核心部件——高功耗的交换机芯片与对温度极度敏感的光子集成电路(PIC)——紧密集成在同一封装内。一方面,交换机芯片运行时产生大量热量,会通过热串扰直接传导至相邻的光引擎,导致PIC中微环谐振器等关键光学元件发生波长漂移与性能劣化。根据T. Baehr-Jones et al(2005),温度仅从20°C升至28°C,就可能导致微环传输谱发生0.4nm偏移,插入损耗变化高达9dB,严重影响传输稳定性。另一方面,这种异质集成对散热设计提出了极高要求:高集成导致热密度高达500W/cm2,系统不仅需要高效导出交换机芯片的集中热量,还需为光引擎——尤其是当激光器也集成在PIC近旁时——维持一个局部的、稳定的低温环境。这往往要求为不同元件设计独立且热隔离的散热路径,在材料、结构与工艺上极大增加了封装复杂性与整体成本。
3.3 测试困境与良率瓶颈
CPO技术的测试与良率困境,根植于其系统级集成的架构。与传统可插拔光模块可独立测试筛选的模式不同,CPO在封装前无法有效模拟其真实工作环境。如Tian M. et al(2023)在《Co-packaged optics (CPO): status, challenges, and solutions》所述,其光引擎在与交换芯片进行系统级封装前,无法通过仿真有效模拟真实工作环境——由于光、电、热信号频率的巨大差异(THz、GHz、kHz),进行高精度协同仿真极其低效,导致热耦合、信号完整性等关键性能在封装前实同“黑盒”。系统集成更会指数级放大良率损失。以一个集成1颗交换芯片和10个光引擎的CPO模组为例,假设交换芯片良率为98%,光引擎为99.5%,其系统总良率将骤降至约93%(0.98*0.995^10=0.93)。而基础元件良率本就承压,例如行业领先的台积电,其硅光晶圆的生产良率据业界评估也仅在65%左右。任一元件的失效都将导致整个昂贵模组的报废。这直接转化为高昂的成本,目前1.6T CPO端口成本高达2800美元,远高于可插拔方案的1200美元,组件简化带来的成本优势被低良率完全吞噬。
3.4 技术迭代周期错配
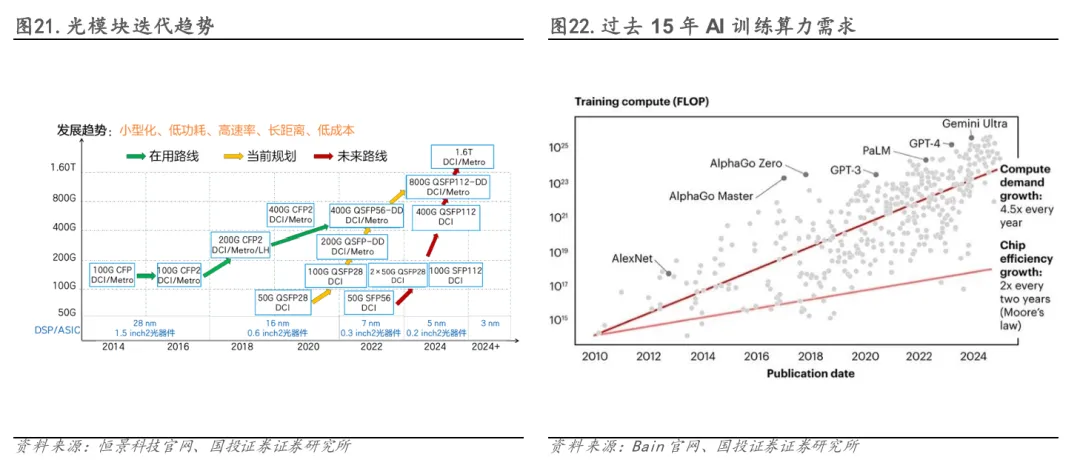
CPO技术面临因光、电技术迭代周期错配而引发的升级灵活性困境。其将光引擎与交换芯片深度集成的架构,在提升性能的同时,也永久锁定了光接口的速率与功能。相比之下,可插拔方案允许用户在光技术演进后,仅更换光模块即可实现低成本升级。而CPO方案一旦部署,若新一代光引擎技术问世,用户将无法单独升级光学部分,只能继续使用落后技术或更换整个交换机系统,显著推高了技术迭代成本与系统生命周期内的TCO。值得注意的是,光模块的迭代速度正在不断加快:在云计算时代,其速率升级周期约为3-4年,而进入AI时代后,由于AI训练算力需求年增长4.5倍,芯片能效每2年需要实现翻倍,驱动光模块迭代周期进一步缩短至约2年。
04海外巨头技术演进全面提速,CPO产业节奏有望较27年预期提前
从海外主要厂商的技术推进节奏来看,CPO正由早期验证阶段加速迈向工程化落地,整体产业化进程有望早于此前普遍预期的2027年时间点。以NVIDIA和Broadcom为代表的交换芯片与网络系统厂商,已在高带宽交换平台中实质性导入光引擎方案,并在新一代产品中持续提升单芯片带宽与光电集成深度,显示CPO正从概念验证走向可规模部署的系统形态。与此同时,Intel则从封装与I/O基础能力切入,逐步推进光引擎直连、可插拔式光封装接口及3D光子集成,夯实底层技术平台。不同路径的并行推进共同指向一个趋势:随着高速电互连瓶颈日益凸显,CPO在下一代高带宽计算与网络架构中的应用窗口正在前移,产业落地节奏具备提前的现实基础。
4.1 英伟达:Scale-out产品率先落地,技术升级指向带宽密度与深度封装
在GTC 2025上,NVIDIA首次系统性发布其基于CPO的Scale-out交换机产品路线,标志着公司在数据中心光互连架构上由传统可插拔光模块正式迈向共封装阶段。从节奏上看,英伟达的CPO发展呈现出清晰的代际演进路径:2025 年下半年实现首代产品商用落地,2026 年推进第二代高带宽深度集成方案,技术形态由“可维护优先”逐步过渡至“高集成度优先”。
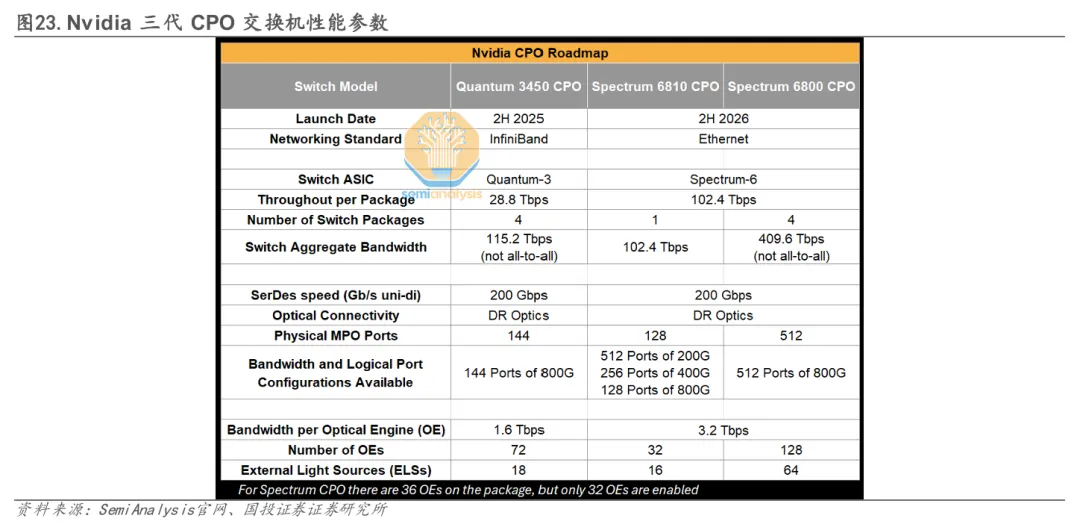
第一代CPO架构对应Quantum-X Photonics平台,代表产品为Quantum X800-Q3450交换机,总交换带宽达到 115.2Tbps。该系统采用 4 颗 28.8T Quantum-X ASIC 组成多平面(multi-plane)架构,每个物理端口同时连接至四颗交换芯片,通过多路200G电通道并行传输,实现高radix与高扩展能力。在光学侧,每颗 ASIC 周围配置6个可拆卸光学子组件,每个子组件集成3个光引擎,即单ASIC对应18个光引擎、整机共72个光引擎。单颗光引擎带宽 1.6T,由8路200G PAM4电通道驱动8个200G PAM4微环调制器(MRM)光通道,体现出 200G MRM在量产系统中的实际应用能力。在封装层面,光引擎内部 PIC(N65工艺)与 EIC(N6工艺)通过TSMC COUPE平台进行混合键合,实现光电芯片的高带宽短距互连。由于光引擎仍以可拆卸子组件形式存在,该代产品在形态上更接近NPO,但已实现电通道显著缩短这一CPO的核心目标,同时兼顾一定可维护性。

第二代 CPO 架构则对应2026年推出的 Spectrum-X Photonics 平台,面向以太网AI网络。与第一代相比,其核心变化在于带宽密度与封装集成度的显著提升。交换芯片从单片ASIC演进为MCM结构:中央为102.4T交换 ASIC,外围环绕8颗224G SerDes I/O Chiplet,大幅提升SerDes接口总带宽与版图利用效率。在光学侧,每个交换封装集成36个第二代光引擎(其中 32 个工作、4 个冗余),单颗光引擎带宽提升至3.2T,包含16路200G光通道。与首代可拆卸光学子组件不同,第二代光引擎直接焊接在基板上,不具备现场更换能力,因此通过冗余设计提升系统可靠性。这一变化标志着英伟达CPO架构由“准共封装”向“深度共封装”迈进,工程思路从可维护性优先转向规模化量产与系统级集成优先。
整体来看,英伟达已形成“两代递进”的 CPO 技术路线:第一代实现架构落地与系统级验证,解决电互连距离与功耗瓶颈;第二代在更高带宽平台上提升光电集成深度,并引入冗余与 MCM设计以适配大规模部署需求,显示出CPO正从前沿技术探索阶段进入面向超大规模AI网络的工程化演进阶段。
4.2 博通:先发卡位并主动拥抱技术迭代,关键架构升级推动平台迈向高带宽规模化部署
作为最早推进CPO系统落地的厂商之一,Broadcom在CPO交换机领域具备先发优势。其产品路线呈现出:从混合电光验证架构→全光I/O规模化架构→面向AI高带宽平台深化演进的清晰技术递进。
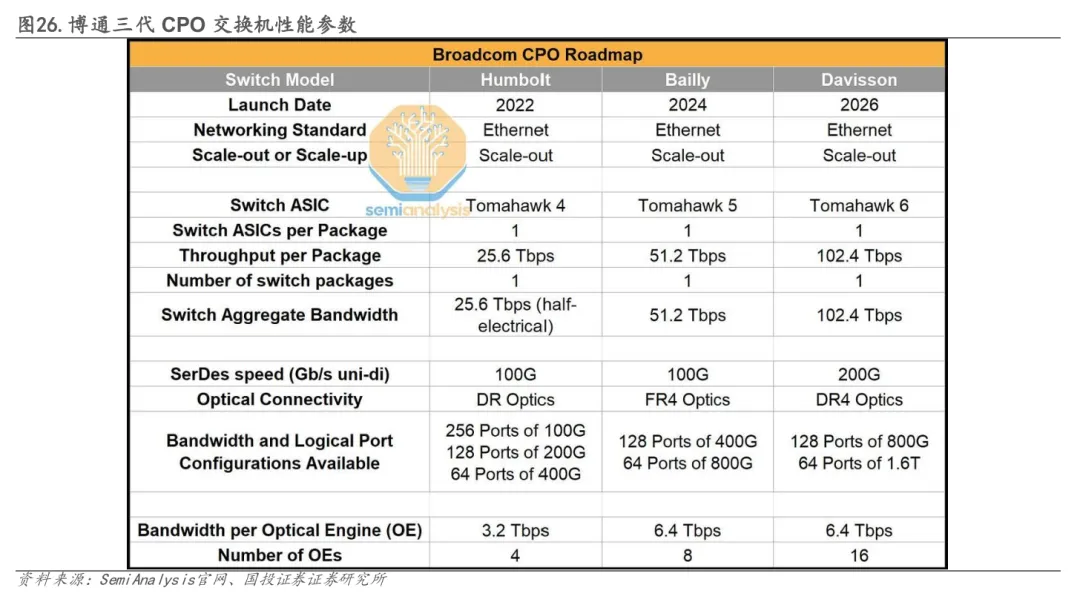
博通第一代CPO设备“Humboldt”(TH4-Humboldt)主要承担概念验证角色,是一款25.6Tbit/s以太网交换机,采用电接口与光接口各占一半带宽的混合架构。其中12.8Tbit/s 光带宽由4个3.2Tbit/s光引擎提供,每个光引擎包含32条100G光通道。该设计强调分层网络中的差异化互连需求:在机架顶部(ToR)场景,电接口用于近距离铜缆连接服务器,光接口负责向上级交换层的远距离互连;在汇聚层场景,电接口用于机架内交换机互连,光接口则承担跨层级光链路。这一代产品在光电集成方面采用SiGe EIC,为后续工艺演进奠定基础。

第二代产品“Bailly”则标志着博通CPO架构由验证阶段迈向全面光化阶段。该平台为51.2Tbit/s以太网交换机,全部I/O均通过光接口实现,集成8个6.4Tbit/s光引擎,每个光引擎提供64条100G光通道,通道数较第一代翻倍。关键变化在于EIC由SiGe升级为7nm CMOS工艺,更高的集成度支持更复杂控制逻辑,从而推动单光引擎通道数从32条提升至64条。同时,封装工艺由TSV转向FOWLP,EIC通过TMV向PIC布线并以铜柱凸点连接基板。FOWLP在移动终端领域已大规模应用,具备成熟OSAT生态(如ASE/SPIL),使该代产品更具规模化可制造性。

在更高带宽方向上,博通持续推进CPO与先进封装深度结合。在Hot Chips 2024披露的实验设计中,公司提出将6.4T光引擎与逻辑芯片、HBM堆栈和SerDes tile集成于同一封装,通过从CoWoS-S升级至CoWoS-L扩大基板尺寸(单边超100mm),可容纳更多光引擎,理论上支持51.2Tbit/s级光带宽的高集成系统形态。这一方向体现出CPO与先进多芯片封装、存储堆栈协同集成的趋势。
进入最新一代,博通推出基Tomahawk 6的Davisson CPO交换机,单封装带宽达到102.4Tbit/s,集成16个6.4T光引擎,交换ASIC采用TSMC N3工艺制造。系统整机由代工厂商完成组装,同时部分客户直接采购TH6裸片并搭配自研光引擎构建系统,显示出该平台在生态层面的开放性。
从技术路线看,博通后续CPO光端点将逐步向TSMC COUPE平台迁移。相较以往采用的边缘耦合与MZM方案,COUPE更适配光栅耦合与MRM路径,代表着光调制与耦合技术路线的明显转向。虽然博通在CPO领域经验深厚,但这一代际变化意味着其在部分关键技术环节需要重新优化设计,封装与工艺协同能力的重要性进一步提升。
总体来看,博通的CPO发展呈现出三阶段演进特征:第一代验证电光混合可行性,第二代实现全光I/O规模化与封装成熟化,最新一代则在102.4T级平台上推动高带宽与先进封装深度融合,显示CPO正从早期示范形态向面向AI高带宽网络的工程化主流方案演进。
4.3 英特尔:四阶段分步推进,从封装级电互联过渡至3D光子集成
相较于直接推出高带宽CPO交换系统,英特尔在CPO领域采取了更为渐进式、基础设施先行的发展路径。其技术演进呈现出:由封装级高速电互连→光引擎直接耦合→可插拔光封装接口→3D垂直光互连逐步推进的四阶段路线。
第一阶段(2023):封装级高速电I/O奠基
英特尔在2023年首先提出先进封装间电互连方案,核心在于实现封装到封装(package-to-package)的短距高带宽电连接,绕过传统PCB走线,以支持多芯片系统之间更高带宽、更低损耗的数据交换。这一步并非直接引入光互连,而是为未来光子集成建立封装级I/O基础架构,为后续在同一封装环境中引入光通道预留物理与系统接口条件。
第二阶段(2024):首代CPO直连光纤方案验证
2024年,英特尔展示了其首代CPO原型系统,采用光引擎芯粒与光纤直接耦合的方式,无需外部光连接器,从而简化链路结构。在OFC 2024上,公司展示了一款4Tbit/s(双向)光计算互连(OCI)芯粒,与概念版Xeon CPU共封装运行,实现64条32Gbit/s通道的无误码传输,并达到约5pJ/bit的能效水平。这一阶段的重点在于验证光I/O在封装内的可行性与能效优势,但仍以固定光纤尾纤为主,维护与模块化能力有限。
第三阶段(2025):可插拔式光封装接口过渡
第二代CPO方案开始引入可拆卸光学封装连接器,替代此前永久连接的光纤尾纤结构。英特尔开发了带有嵌入式3D波导的玻璃光桥,可插入封装侧边,实现封装内光子器件与标准光纤连接器之间的对接。这种设计提升了系统的模块化与可维护性,使CPO形态从“实验验证型”向“可服务化工程形态”过渡。
第四阶段(2027):迈向3D垂直集成光子架构
英特尔规划在2027年前后推进第三代CPO形态,即3D垂直光子集成。该方案通过垂直扩展光束耦合技术,实现不同芯片层之间的垂直光信号传输,例如在光子中介层与逻辑芯片之间构建短距离自由空间或玻璃内部光路。通过将光I/O引入垂直方向,英特尔希望进一步削弱高速电互连瓶颈,为未来超高带宽chiplet互连架构提供新的封装级解决方案。
总体来看,英特尔的CPO发展路径强调封装平台能力先行、逐步引入光互连形态,从基础电互连架构建设出发,经过光引擎直连验证与连接器模块化过渡,最终走向高度集成的3D光子封装形态,体现出其在先进封装与光子技术深度融合方向上的长期布局思路。

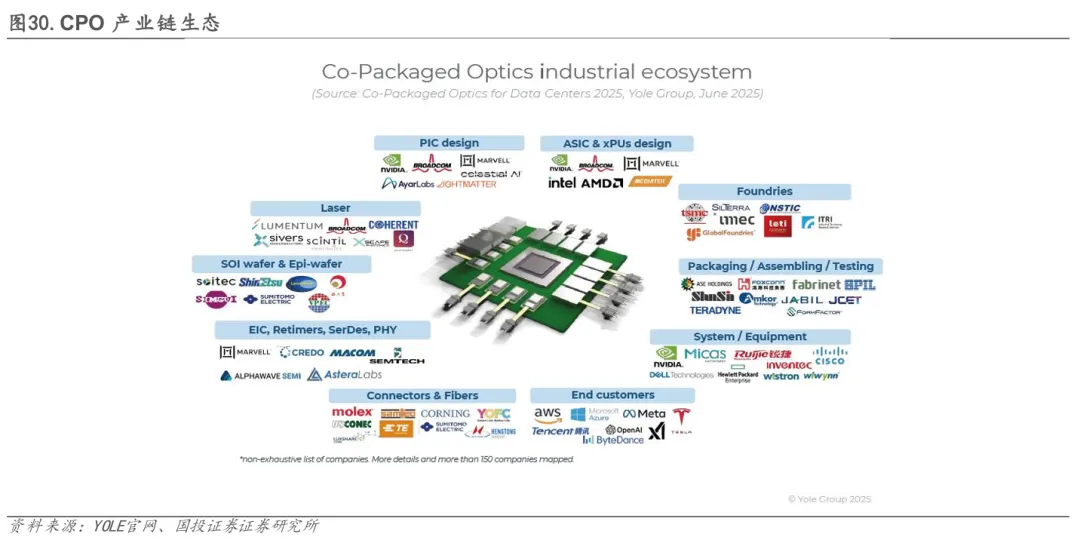
05CPO产业链:AI驱动下的紧耦合生态与垂直整合趋势
CPO(Co-Packaged Optics)产业链主要包括上游芯片及光器件、中游封装制造与测试、以及下游系统与终端应用等环节。上游核心环节如 ASIC 芯片、光引擎(PIC/EIC)及高端光源目前仍以 海外厂商占据主导地位,代表企业包括博通、英伟达、迈威尔、Credo 等,技术成熟度和产业生态优势较为明显;国内厂商如天孚通信、光迅科技等正处于持续投入和验证阶段。中游封装、制造、测试及散热环节对工艺协同与工程能力要求较高,国内企业在该环节具备一定基础,以中际旭创、新易盛、天孚通信为代表,相关能力有望随CPO方案推进逐步释放。下游主要为 Nvidia、Cisco、锐捷网络等设备厂商,终端需求集中于北美云CSP云服务商及国内头部互联网客户。整体来看,CPO产业仍处于技术与商业化路径逐步明晰阶段,上游核心技术突破节奏及下游规模化落地进展仍有待持续观察。

5.1 ASIC:系统性能的决策核心
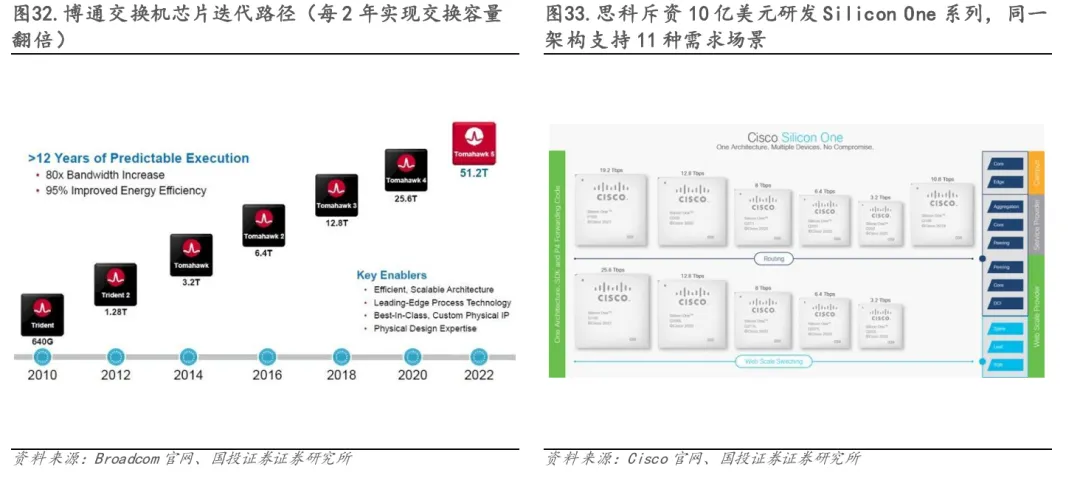
在CPO架构中,ASIC主要指用于高带宽数据交换的交换机芯片(Switch ASIC),是整个系统的性能上限所在。当前主流方案集中在Broadcom Tomahawk、Cisco Silicon One 等超大规模交换ASIC,这类芯片通常提供51.2T/25.6T级别的交换容量,并集成112G/224G SerDes以支撑高密度光电互联。CPO对ASIC的核心要求包括:更高的 SerDes 速率、更严格的 I/O 能耗指标(pJ/bit 级)、以及对光学接口的原生友好性(如光邻近布局、短距耦合能力)。因此,CPO驱动ASIC演进的方向正从传统的“前面板可插拔 I/O”转向“极短通道的共封装高速接口”,促使厂商在PHY架构、散热设计、电源完整性以及芯片面积利用上重新优化。总体来看,CPO所需的ASIC是更高速、更低功耗、并且具备光电协同封装能力的下一代高端交换芯片。
5.2 光引擎:光电转换的集成枢纽
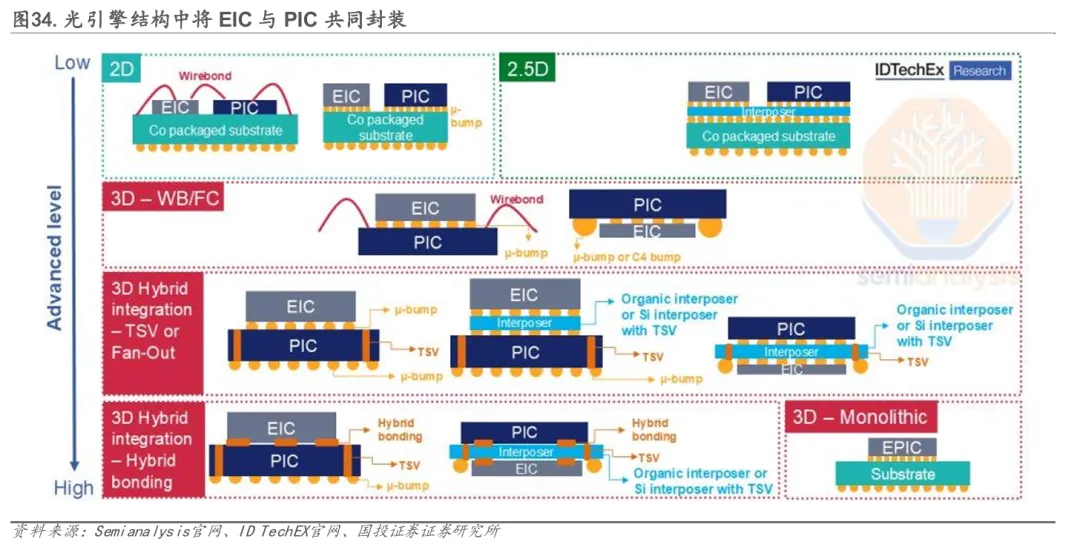
光引擎作为核心的光电转换单元,承担着连接ASIC与光纤网络的关键桥梁作用。其通常由 PIC(硅光调制器、波导等光学器件)与EIC(驱动器、跨阻放大器等电接口芯片)协同构成,实现电信号与光信号之间的高效转换。其中,硅光芯片主要承担光路集成与调制功能,依托 CMOS兼容工艺实现高密度波导与调制器集成;磷化铟相关器件则多用于提供高性能激光光源或增益功能,以弥补硅材料在发光能力上的不足;电接口芯片负责完成与ASIC之间的高速信号驱动、放大与匹配。相较于传统可插拔光模块,CPO通过将光引擎与交换ASIC进行共封装,显著缩短高速电通道距离,从而降低信号损耗与功耗水平,在系统能效方面具备进一步优化空间。总体来看,光引擎不仅是CPO实现光电转换的核心功能单元,也是推动带宽密度提升与系统能效改善的重要技术基础。
目前主流技术路线包括硅光(SiPh)和VCSEL短距方案。比较硅光与VCSEL两大技术路线,硅光代表着面向未来的系统级解决方案,而VCSEL则是在特定优势领域实现关键突破的差异化路径。硅光技术基于CMOS工艺在硅芯片上集成光路,其核心优势在于高集成度、出色的可扩展性以及未来的降本潜力,是追求高性能和规模化部署的主流方向;但其发展受限于片上光源集成、波导损耗等关键技术挑战。与之相对,VCSEL技术通过先进封装集成激光器,最大优势在于极致的低功耗(可低于5 pJ/bit)和短距应用下的成本效益;然而,它在向更高速率演进时面临可靠性挑战,且高精度封装工艺要求苛刻,因此主要专注于数据中心机架内等短距互联场景。
从集成方式看,当前光引擎的技术路径主要包括单片集成与异构集成两类。单片集成指在同一晶圆或工艺平台上同时实现 PIC与EIC 的制造,其在互连距离、寄生参数和系统简洁性方面具备一定理论优势,但受限于硅光工艺制程难以持续向先进节点演进,对高速电接口性能和未来扩展能力形成制约。相比之下,异构集成通过分别在硅光工艺与先进CMOS工艺上制造PIC与EIC,并借助先进封装实现高密度集成,在兼顾光学性能的同时释放电接口的制程红利,更有利于支持更高带宽与更低功耗需求,因而正逐步成为主流技术方向。其中,3D 集成等先进封装方案通过进一步缩短PIC与EIC之间的互连距离,有助于降低寄生效应、改善信号完整性,为 CPO 性能提升提供重要支撑。
国内外企业在光引擎产业化中正沿不同技术路径布局:国外依靠技术与生态积累领先,国内则凭借产业链协同、封装制造和本土化供给提升竞争力。随着技术方案趋于成熟并经受规模化验证,未来的全球竞争与合作格局将加速演变。国外领先企业在高端光引擎与先进封装技术上具有一定先发优势。以Ayar Labs为代表的海外创新企业在硅光与异构集成方案上率先实现设计与工程验证;传统光芯片与高速互连厂商如Broadcom、MACOM、Credo等依托成熟ASIC、PIC与电接口能力,在高带宽密度与低能耗方案上持续投入;Lumentum、Coherent等公司在光源器件与光学元件领域具备深厚积累,为整体光引擎模块化提供基础支撑。此外,主要代工与封装服务供应商(如 GlobalFoundries、Tower、AMF 等)通过提供硅光工艺与高级封装能力参与生态构建。国内企业在光引擎及相关集成技术上也加速布局并逐步形成协同能力。在硅光器件与光引擎模块化方面,天孚通信、光迅科技等公司加大在设计、工艺验证与封装能力方面的投入,推动从光组件向光引擎集成方案的延伸。


5.2.1 调制器:技术路线三足鼎立,厂商因地制宜
调制器技术路线呈现“三足鼎立”之势:MZM代表高性能与高成熟度,MRM代表高密度与未来扩展性,EAM则提供卓越的热稳健性。技术选择已超越单纯的性能比较,成为厂商根据自身封装能力、系统架构战略(特别是对WDM的依赖程度)和热设计边界所做出的核心战略抉择。未来,随着CPO向更高带宽与更复杂集成演进,MRM与先进WDM的结合,以及EAM在chiplet异构集成中的潜力,预计将成为产业创新的主要焦点。
5.2.1.1 马赫-曾德尔调制器(MZM):技术成熟的高性能路径
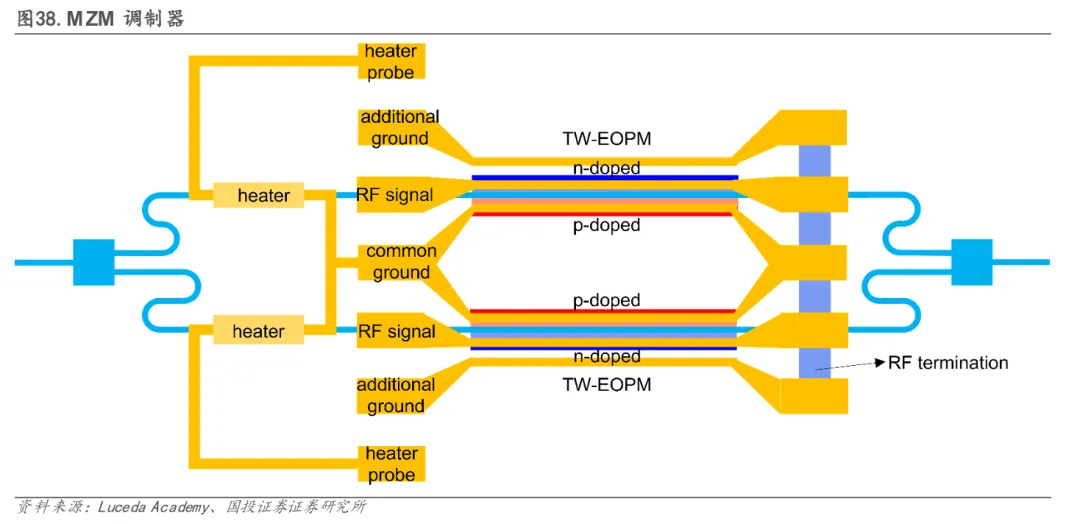
MZM采用干涉原理调制,是当前最易实现且热敏性低的方案。其核心优势在于支持高阶调制格式(如PAM4及相干QAM),并具备清晰的向200Gbaud以上高波特率演进的路径,是实现单通道400G+ 带宽的关键技术。然而,MZM的物理尺寸巨大(典型面积约12,000 µm²),导致其调制器密度低,严重限制了单芯片可集成的通道数量,且在功耗方面不具优势。因此,MZM主要适用于对线性度与传输距离有较高要求、但对集成密度相对宽松的场景。
5.2.1.2 微环调制器(MRM):高密度集成的代表,受产业龙头青睐
MRM利用微环共振原理工作,其最大优势在于极致的紧凑性,尺寸仅为25-225 µm²,比MZM小两个数量级,可实现极高的调制器与波长通道集成密度,天然适合与波分复用(WDM)技术结合。此外,MRM驱动电压低,有助于降低系统功耗。然而,其致命弱点是热敏感性极高(温度漂移达70-90 pm/°C),需要复杂且精准的温控系统,对设计与制造工艺提出了极大挑战。正因为攻克这一挑战能构建极深的护城河,英伟达(NVIDIA) 等行业巨头明确选择并大力投入MRM路线,将其视为实现超高带宽密度的关键。
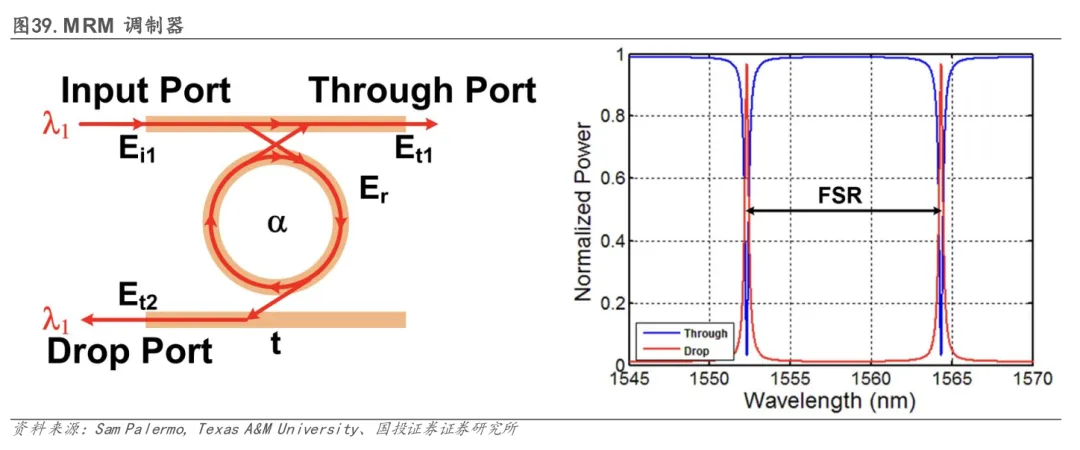
5.2.1.3 电吸收调制器(EAM):在热稳定性与集成度间寻求平衡
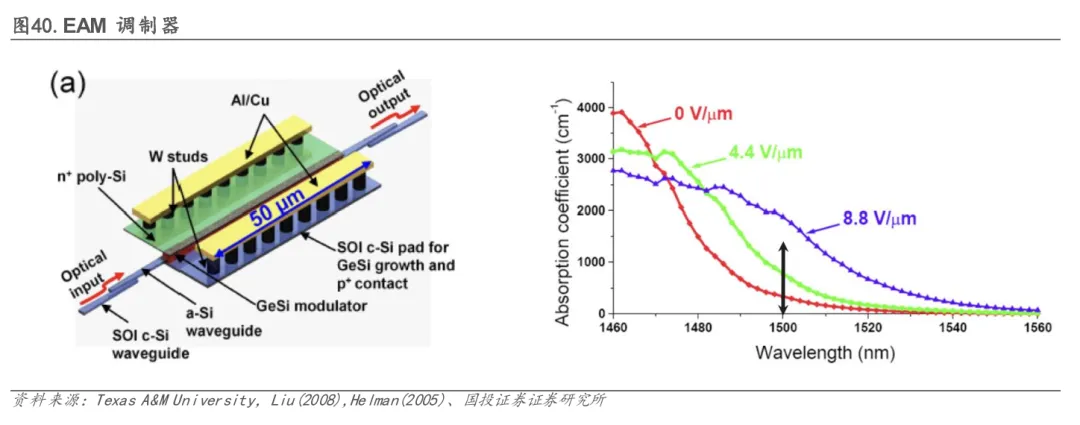
EAM基于Franz-Keldysh效应,通过电压改变材料吸光性来调制信号。其核心优势在于出色的热稳定性(可耐受高达35°C的瞬时温度波动),非常适合放置在发热量大的计算芯片附近。在尺寸(约250 µm²)和功耗上也优于MZM。但其主要局限在于:硅基锗(GeSi)EAM的工作波段通常限于C波段,与数据中心主流的O波段生态系统兼容性差;同时,其可靠性感知和插入损耗略高于其他方案。目前,Celestial AI等公司是该路线的积极推动者,旨在解决近计算封装环境下的特定热管理难题。
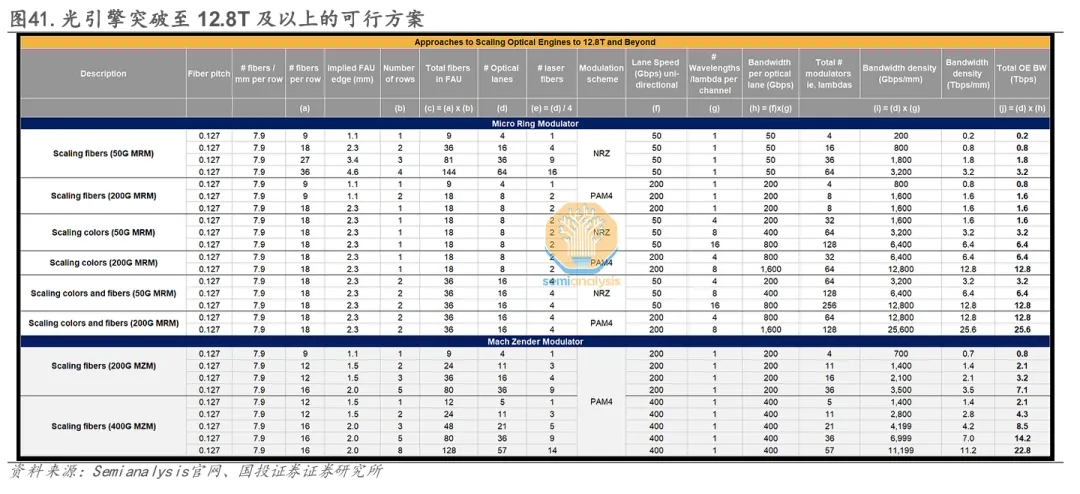
5.2.2 光引擎技术演进路线:围绕“系统集成优化”与“多维带宽扩容”展开突破
在光引擎技术演进路径上,产业正围绕“系统集成优化”与“多维带宽扩容”展开突破,目前行业主流产品带宽普遍集中于1.6T-3.2T区间。尽管已有厂商展示6.4T方案,但由于物理尺寸通常达到现有方案的2-3倍,且需依赖双光纤阵列单元(FAU),其实际带宽密度尚未形成对可插拔方案的压倒性优势,制约了规模化导入的动力。
为构建具有代际优势的竞争力,行业正从电气接口与光学链路两个维度进行系统性升级:
在电气接口方面,产业正探索三条技术路径:一是延续短距SerDes,以兼容现有可插拔生态;二是采用UCIe等宽I/O接口,结合56G NRZ等较低信号速率以降低封装难度;三是采用宽I/O结合高速光链路,通过PAM4调制及波分复用(WDM)提升单纤效率。
在光学链路扩容方面,业界围绕“快而窄”(高单通道速率)与“慢而宽”(多光纤并行)两大理念同步推进:
1)提升光纤密度:当前光纤最小间距为127μm(约8纤/毫米),产业正朝80μm间距迈进,并探索多芯光纤技术。目前已实现的最大规模光纤阵列为2D FAU的36纤方案。
2)提高单通道速率:波特率正从100Gbaud向200Gbaud推进,调制方式则从PAM4向PAM6/PAM8乃至相干调制(如DP-16QAM)演进。
3)扩展波分复用通道:当前主流商用DWDM系统支持8-16个波长,而业界前沿研究正推动波长数向32λ乃至64λ迈进,相关激光器与调制器技术已进入原型验证阶段。
综合来看,下一代12.8T及以上光引擎的实现,必须依赖电气接口架构、光纤集成工艺、调制技术与激光器阵列等多个维度的协同突破。只有在带宽密度、能效与成本上同时形成代际优势,CPO技术才能真正从演示验证走向规模化商用。
5.3 光路系统:信号生成与精准传输的生命线
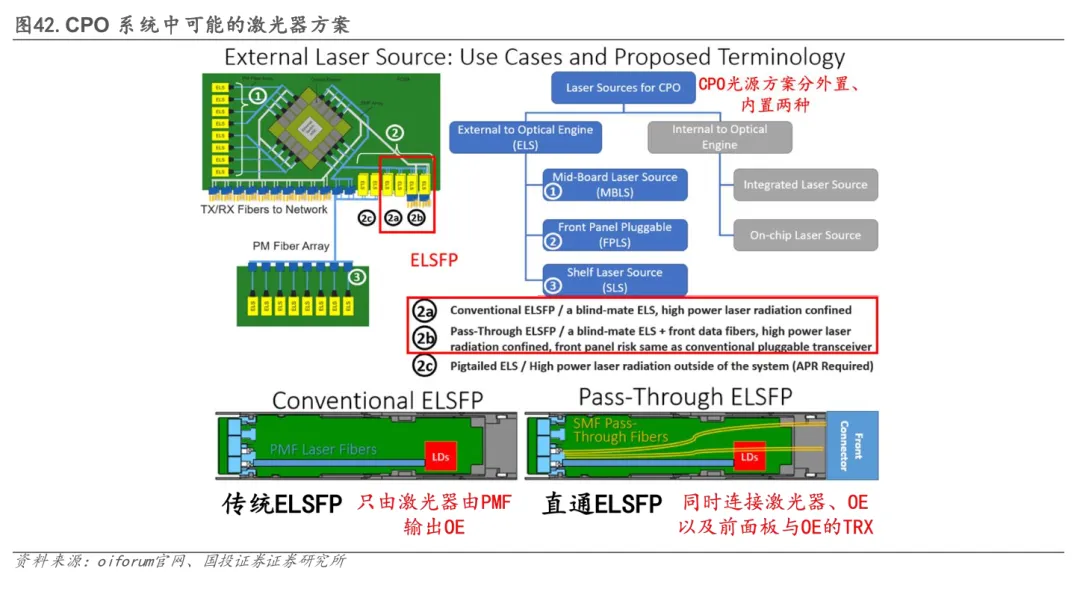
5.3.1 内置/外置光源:ELS破解热管理与可靠性瓶颈成为主流方案
CPO的光源集成主要分为内置光源(On-Chip Laser)与外置光源(External Light Source, ELS)两大技术路线。内置光源通过将激光器(通常基于III‑V族材料)直接键合集成在硅光芯片上,在理论上具备最高的集成度与最低的互连损耗,是实现终极功耗和尺寸优化的理想路径。然而,该方案面临三重核心挑战:(1)激光器本身是系统中可靠性相对薄弱的环节,其失效可能导致整个光引擎芯片报废,故障影响范围大;(2)激光器对温度极为敏感,而将其与发热量巨大的主机计算芯片(如GPU/XPU)共封装,会加剧热管理难度,影响性能和寿命;(3)片上激光器通常难以提供足够高的输出光功率,限制了链路预算。因此,内置光源方案虽前景广阔,但受制于可靠性、热管理和功率输出等瓶颈,短期内难以实现规模化商用落地。
相比之下,将激光器独立为外部可插拔模块的外置光源(ELS)方案已成为当前产业界的主流共识和CPO交换机的实际部署选择。该方案显著降低了共封装体的热管理复杂度与封装工艺难度,并使得激光器可以像传统光模块一样进行独立维护和更换,大幅提升了系统的可维护性与可靠性。其核心代价在于,光信号从外部激光模块通过光纤耦合进入光引擎的过程中,会经历连接器损耗、光纤耦合损耗及调制器效率等多重衰减,因此需要配备输出功率更高(例如要求达到24.5 dBm级别)的激光器来进行补偿,这会带来更高的功耗和散热需求。目前,行业正通过推动ELSFP等标准化形态来完成外置光源的落地。ELSFP采用OSFP封装外形与高密度MPO光纤连接,可分为仅提供光源的“传统型”与能同时集成光源和部分收发功能的“直通型”。后者能进一步提高面板端口密度,但设计与实现难度也更大。为驱动光引擎中的多个并行光通道,ELS方案普遍采用高功率连续波(CW)激光器结合“一拖多”分光结构,为阵列化调制器提供稳定光源,构成了当前CPO产业化推进中最主流的激光技术路径。目前,国内的CW光源领域主要由源杰科技与长光华芯等企业重点布局,而国际市场则由博通、Lumentum与Coherent等领先厂商主导技术发展与生态构建。
5.3.2 光纤阵列单元(FAU):高精度设计需求带来高价值量与高壁垒
在共封装光学(CPO)技术加速落地的进程中,光纤阵列单元(FAU)作为实现芯片与光纤间高效光耦合的核心组件,其设计与制造水平直接影响系统的带宽和能效。尤其在台积电COUPE等先进硅光封装平台上,FAU需与光路结构深度协同,以确保从硅透镜到光纤的低损耗光耦合。尽管I/O通道数提升会增加工艺复杂度,但行业若能推动接口标准化,将显著缩短开发周期并降低整体成本,促进CPO规模化商用。
市场空间方面,根据QY Research数据,2025年全球光纤阵列市场销售额达到了6.98亿元,预计2032年将达到10.35亿元,年复合增长率(CAGR)为5.9%(2026-2032)。在技术附加值更高的硅光CPO领域,由于对耦合精度、插损控制及偏振保持能力的要求远高于传统光模块,FAU的单体价值量将持续提升。
从产业格局看,FAU市场目前由Corning、Kohoku Kogyo、博创科技等企业主导,具备精密加工与光学设计能力的厂商占据领先地位。而在CPO技术路径迭代中,行业正从早期基于扇出型晶圆级封装(FOWLP)的方案,全面转向以台积电COUPE为代表的硅中介层集成平台。以博通(Broadcom)为例,其已明确将COUPE作为下一代交换芯片与加速器的CPO解决方案,替代此前采用的FOWLP路径,核心原因在于FOWLP结构中信号经模塑通孔(TMV)传输至电芯片时寄生电容过高,限制了每通道速率超越100Gbps,而COUPE平台凭借高密度互连与优异信号完整性,可支持单光引擎向12.8Tbps及以上带宽演进。
5.3.3 高密度无源器件:随端口密度与CPO渗透率的同步放大打开增量区间
CPO架构从根本上重构了数据中心内部的光互连形态,也同步拉动了无源光器件体系的系统性升级。相较于传统可插拔光模块方案,CPO 在显著降低功耗与链路损耗的同时,引入了外置激光源(ELS)、高密度板级出纤以及复杂光纤重排需求,使光链路从“模块级连接”演进为“系统级光互连”。在这一过程中,TRX、保偏光纤(PMF)、多类型高密度跳线以及 MPO / MXC 等连接器不再是简单的配套部件,而是直接参与光功率预算、信号完整性和系统可靠性设计,构成确定性较强、随端口密度与 CPO 渗透率同步放大的重要增量市场,为上游高端无源光器件厂商打开了新的价值空间。
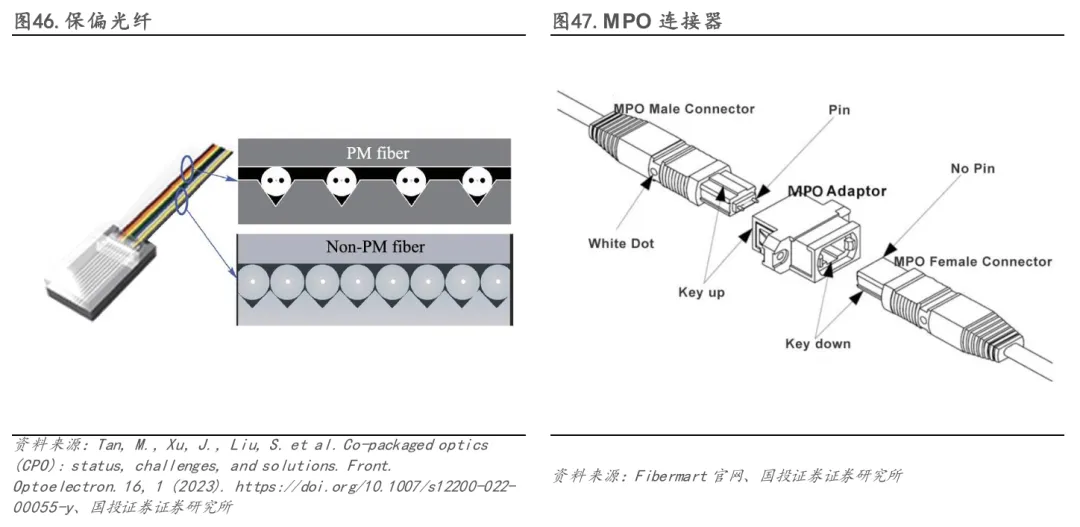
保偏光纤(PMF)是保障高性能光互联的核心基础元件,其性能直接决定了CPO光链路的信号完整性、能效与整体可靠性。其主要作用在于将外部激光器发出的线偏振光以高纯度偏振态(维持高偏振消光比,PER)高效、稳定地传输至光子集成电路(PIC)芯片,并精确对准其特定偏振模式,从而确保调制与探测效率。为适应CPO设备内部严苛的紧凑空间,PMF需具备卓越的弯曲不敏感特性,以同时抑制因弯曲导致的插入损耗(IL)增加与偏振态劣化,满足系统严格的光功率预算。此外,PMF通常以带纤形式进行布设与管理,以确保在整个部署链路中偏振方位的一致性与可控性。鉴于其通常承载数百毫瓦级的高光功率,PMF的设计与封装还需重点考虑高功率下的长期可靠性,防止功率泄漏引发连接器或涂层损伤,保障系统稳定运行。
MPO 连接器承担着高密度光纤集中接入与板级光互连外延的关键作用。由于 CPO 将光引擎直接封装在交换 ASIC 周边,系统对光纤出入板(fiber break-out)的数量、密度和一致性提出了极高要求,MPO以“一插多芯”的形式成为事实上的主流接口方案。以英伟达为例,其 Quantum 3450 CPO 交换机提供144个Physical MPO端口,Spectrum 6810 提供128个,而 Spectrum 6800 更是达到512个MPO端口,充分体现了在超大规模AI交换系统中,MPO 对支撑高带宽、低功耗和高集成度光互连的核心价值。
Shuffle Box通常位于光引擎(O/E)与设备前面板之间,作为光纤重排、汇流与物理保护的关键中间节点。它将来自多个O/E的高密度光纤通道进行标准化整理与重新分组,实现从非标准引擎侧光纤排布到前面板标准接口(如 MPO、LC、SN 等)的平滑过渡。通过在 Shuffle Box 内完成光纤的固定、分层管理与应力释放,不仅可显著降低微弯/宏弯带来的损耗风险,还能提升系统的可维护性与模块级可更换性。在超高端口数、空间极度受限的CPO交换机中,Shuffle Box是实现高可靠性、高一致性和可规模化部署的重要结构组件。

5.4 CPO产业化落地驱动产业链价值重构,核心组件与先进封装成受益焦节点
CPO技术的规模化应用正深刻重塑光互联产业格局,触发一场从上游组件到下游系统的价值链迁移。尽管可插拔光模块在相当长时间内仍将保有应用场景,但为满足未来算力基础设施对更高带宽密度与更低功耗的极致追求,产业链向CPO等高端技术的演进已成为确定性的长期趋势。这一进程正推动产业格局呈现“结构分化、价值上移”的鲜明特征:具备技术壁垒的核心组件如硅光引擎、高端ASIC、激光器与高密度光纤连接器,以及提供先进封装与液冷散热方案的厂商,将持续受益于CPO带来的高集成与高性能需求;而传统可插拔光模块、分立元件及常规散热方案的市场空间则面临渐进但不可逆的替代压力。整体而言,产业链价值正加速向光电协同设计与系统级集成能力集中,推动行业竞争从模块制造向底层芯片技术与平台级解决方案纵深演进。
5.4.1 受益环节:CPO核心组件、先进封装引领价值增长
从产业链角度看,CPO量产首先带来新增互联需求的释放,受益环节可分为上游组件、中游封装制造与散热方案、以及下游系统厂商三个方向:
上游:CPO核心组件供应商率先受益。随着光引擎与交换芯片深度协同,上游关键器件需求显著提升。包括 ASIC、硅光光引擎(OE)、激光器、耦合器件、光纤连接器等核心部件厂商,将直接受益于 CPO 带来的高带宽、高集成升级。由于CPO对芯片-光学对接精度要求更高,上游关键器件的技术含量与ASP均明显提升,预计率先获得增量。
中游:封装、散热与制造测试厂商同步受益。CPO采用光电协同封装,对2.5D/3D封装、微光学对准、TFE技术提出更高要求,中游具备光电混合集成能力的OSAT厂商将迎来量价齐升。同时,散热环节直接受益:CPO将高速SerDes与光引擎放置在同一封装内,热密度显著上升,对液冷板、VC均热板、先进导热材料、热仿真服务提出更高需求。预计具备平台级散热设计能力的厂商(如冷板、D2D散热方案提供商)将伴随CPO渗透率提升而获得实质增量。
下游:设备厂商依托新技术性能红利增强竞争力。CPO带来的高带宽密度与更低能耗,使AI交换机与AI服务器的系统性能显著提升,同时降低机房布线与整体TCO。下游头部厂商通过采用CPO实现整机算力密度提升,进而增强AI集群和数据中心的产品竞争力,预计新技术带来的性能红利率先在系统厂商端体现。
5.4.2 承压环节:传统模块与分立元件或面临结构性替代
随着CPO技术迈向规模化产业化,其高度集成的架构正推动光互联产业链价值重构,传统环节面临显著结构性压力。上游领域,传统分立元件供应商如OSA、独立Driver/TIA等因功能被集成至硅光芯片或光引擎中,需求量与价格双双承压;同时,可插拔光模块所依赖的精密连接器与电缆组装需求也将因CPO内部连接形态的根本性变化而萎缩。中游环节,传统可插拔光模块制造商成为受冲击最直接的群体,行业领先企业如中际旭创、光迅科技等已积极向上游核心光组件与硅光芯片领域布局,力图突破被“部件化”的风险;未能及时转型的厂商则可能面临市场空间与利润率的双重挤压。此外,CPO的高热密度结构推动散热方案向液冷等高端技术升级,传统风冷市场逐步萎缩。下游系统与数据中心在初期则需应对设备重构成本与供应链绑定加深的挑战。整体来看,CPO产业化进程正加速价值链向硅光芯片、集成光引擎与先进散热方案集中,传统光模块制造与分立器件厂商成为主要承压方。
06关注CPO相关投资机会
在当前光模块技术快速迭代的背景下,CPO虽被业界普遍视为下一代重要方向,但其产业化节奏仍面临热管理、耦合精度、标准缺失与成本高企等多重挑战,具体规模商用时间存在不确定性;因此当前阶段的投资重心应侧重于把握其带来的主题性机会,重点关注在硅光芯片、CW激光器、光纤阵列等关键技术环节已有扎实布局,且具备跨代技术参与能力的核心企业,以在不确定性中捕捉具备高确定性的产业链价值环节。


■ 团队介绍
马良:国投证券电子首席,上海交通大学工科硕士,产业工作三年半,2015年入行,曾任职于东北证券,2018年加入国投证券。擅长全产业链研究。新财富团队核心成员,多次接受CCTV2、彭博社、新浪财经、iFind等财经媒体的采访。
朱思:北京邮电大学本硕,产业工作十年,2021年加入国投证券,主要覆盖功率半导体、PCB、LED以及部分消费电子领域。
常思远:约翰霍普金大学硕士,曾先后就职于中银证券、太平基金,2025年加入国投证券,在科技领域有较为全面的研究,主要负责消费电子、AI算力、AI端侧等相关领域。
周赵羽彤:多伦多大学工程硕士,主要覆盖半导体材料、零部件、设备、晶圆制造、封测等领域。
董雯丹,新加坡国立大学金融数学硕士,2025年加入国投证券,主要覆盖半导体芯片设计、部分PCB上游领域,曾任职于山西证券
王寓捷:本科毕业于厦门大学,硕士毕业于新加坡南洋理工大学,曾就职于太平基金,主要覆盖消费电子、AI产业链。

证券研究报告:《光通信系列报告二:光电共封装重构算力互连架构,CPO开启高密度高能效新时代》
对外发布时间:2026年2月13日
报告发布机构:国投证券股份有限公司(已获得中国证监会许可的证券投资咨询业务资格)

■ 分析师声明
本报告署名分析师声明,本人具有中国证券业协会授予的证券投资咨询执业资格,勤勉尽责、诚实守信。本人对本报告的内容和观点负责,保证信息来源合法合规、研究方法专业审慎、研究观点独立公正、分析结论具有合理依据,特此声明。
■ 本公司具备证券投资咨询业务资格的说明
国投证券股份有限公司(以下简称“本公司”)经中国证券监督管理委员会核准,取得证券投资咨询业务许可。本公司及其投资咨询人员可以为证券投资人或客户提供证券投资分析、预测或者建议等直接或间接的有偿咨询服务。发布证券研究报告,是证券投资咨询业务的一种基本形式,本公司可以对证券及证券相关产品的价值、市场走势或者相关影响因素进行分析,形成证券估值、投资评级等投资分析意见,制作证券研究报告,并向本公司的客户发布。
■ 免责声明
本订阅号为国投证券电子团队的个人订阅号。本订阅号推送内容仅供专业投资者参考。为避免订阅号推送内容的风险等级与您的风险承受能力不匹配,若您并非专业投资者,请勿使用本信息。本信息作者所在单位不会因为任何机构或个人订阅本订阅号或者收到、阅读本订阅号推送内容而视为公司的当然客户。
本订阅号推送内容仅供参考,不构成对任何人的投资建议,接收人应独立决策并自行承担风险。在任何情况下,本信息作者及其所在团队、所在单位不对任何人因使用本订阅号中的任何内容所引致的任何损失负任何责任。
本订阅号推送内容仅供国投证券股份有限公司(以下简称 “本公司”)的客户使用。本公司不会因为任何机构或个人接收到本订阅号推送内容而视其为本公司的当然客户。
本订阅号推送内容基于已公开的资料或信息撰写,但本公司不保证该等信息及资料的完整性、准确性。本订阅号推送内容所载的信息、资料、建议及推测仅反映本公司于本订阅号推送内容发布当日的判断,本订阅号推送内容中的证券或投资标的价格、价值及投资带来的收入可能会波动。在不同时期,本公司可能撰写并发布与本订阅号推送内容所载资料、建议及推测不一致的内容。本公司不保证本订阅号推送内容所含信息及资料保持在最新状态,本公司将随时补充、更新和修订有关信息及资料,但不保证及时公开发布。同时,本公司有权对本订阅号推送内容所含信息在不发出通知的情形下做出修改,投资者应当自行关注相应的更新或修改。任何有关本订阅号推送内容的摘要或节选都不代表本订阅号推送内容正式完整的观点,一切须以本公司向客户发布的本订阅号推送内容完整版本为准,如有需要,客户可以向本公司投资顾问进一步咨询。
在法律许可的情况下,本公司及所属关联机构可能会持有内容中提到的公司所发行的证券或期权并进行证券或期权交易,也可能为这些公司提供或者争取提供投资银行、财务顾问或者金融产品等相关服务,提请客户充分注意。客户不应将本订阅号推送内容作为作出其投资决策的惟一参考因素,亦不应认为本订阅号推送内容可以取代客户自身的投资判断与决策。在任何情况下,本订阅号推送内容中的信息或所表述的意见均不构成对任何人的投资建议,无论是否已经明示或暗示,本订阅号推送内容不能作为道义的、责任的和法律的依据或者凭证。在任何情况下,本公司亦不对任何人因使用本订阅号推送内容中的任何内容所引致的任何损失负任何责任。
本订阅号推送内容版权仅为本公司所有,未经事先书面许可,任何机构和个人不得以任何形式翻版、复制、发表、转发或引用本订阅号推送内容的任何部分。如征得本公司同意进行引用、刊发的,需在允许的范围内使用,并注明出处为 “国投证券股份有限公司证券研究所”,且不得对本订阅号推送内容进行任何有悖原意的引用、删节和修改。
本订阅号推送内容的估值结果和分析结论是基于所预定的假设,并采用适当的估值方法和模型得出的,由于假设、估值方法和模型均存在一定的局限性,估值结果和分析结论也存在局限性,请谨慎使用。
国投证券股份有限公司对本声明条款具有惟一修改权和最终解释权。
