Anthropic最新研究报告:AI已能自主工作45分钟,普通人的"躺赢"机会就在这里
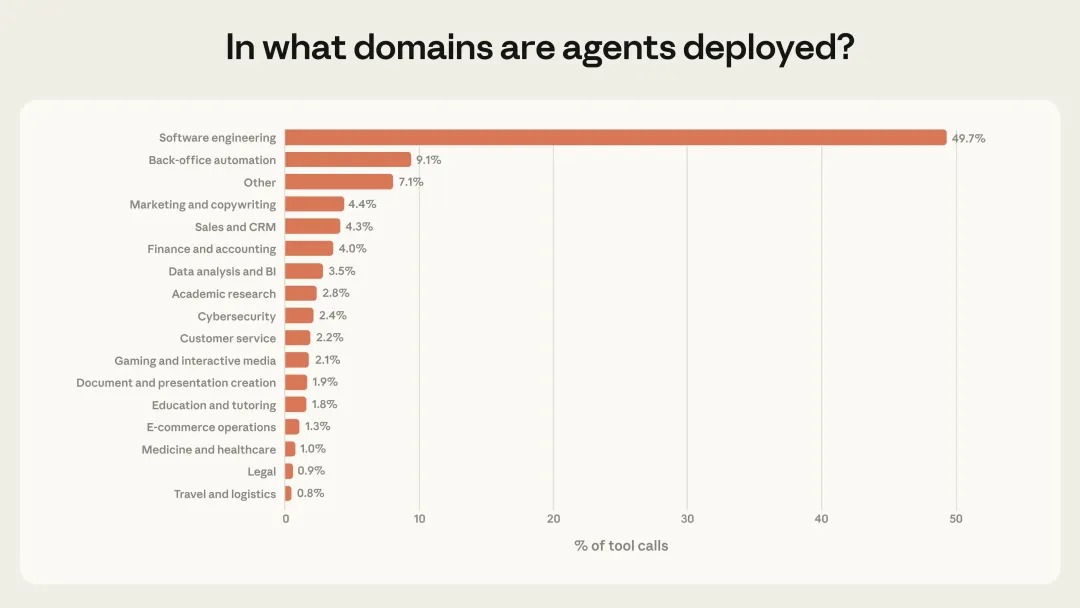
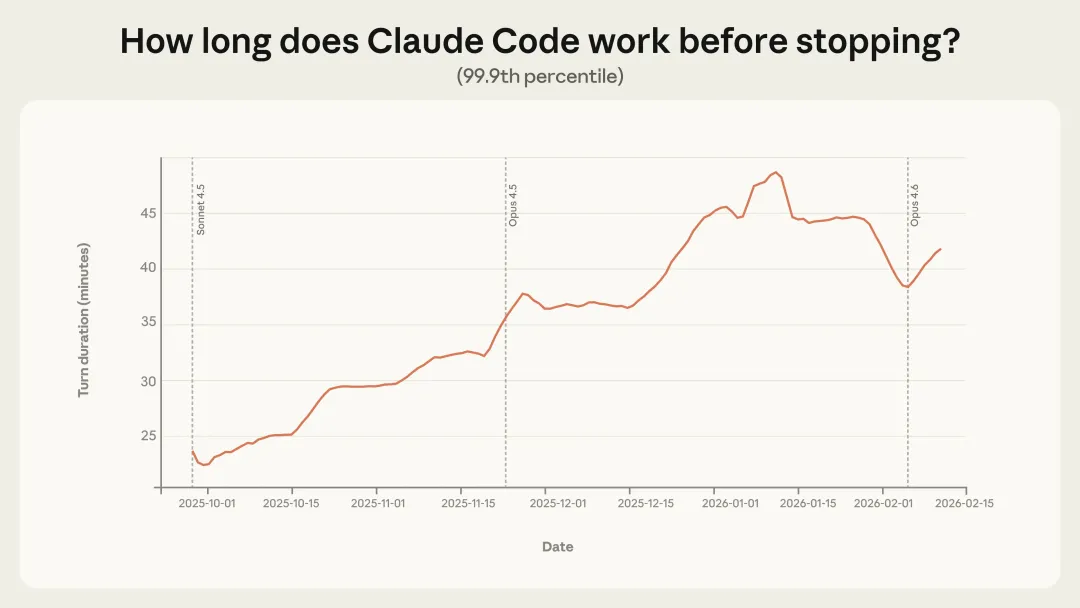
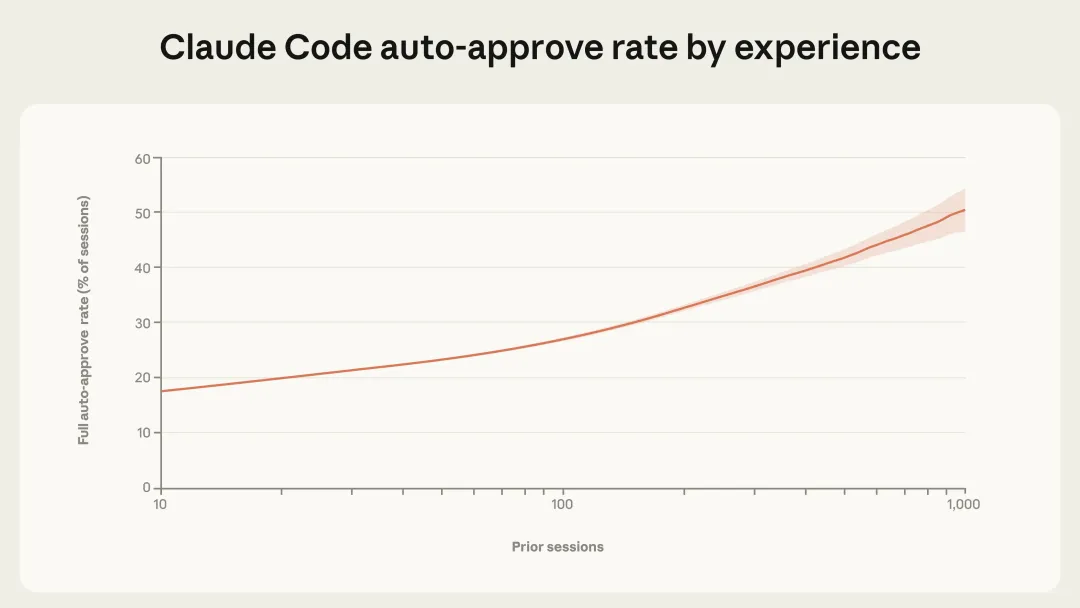
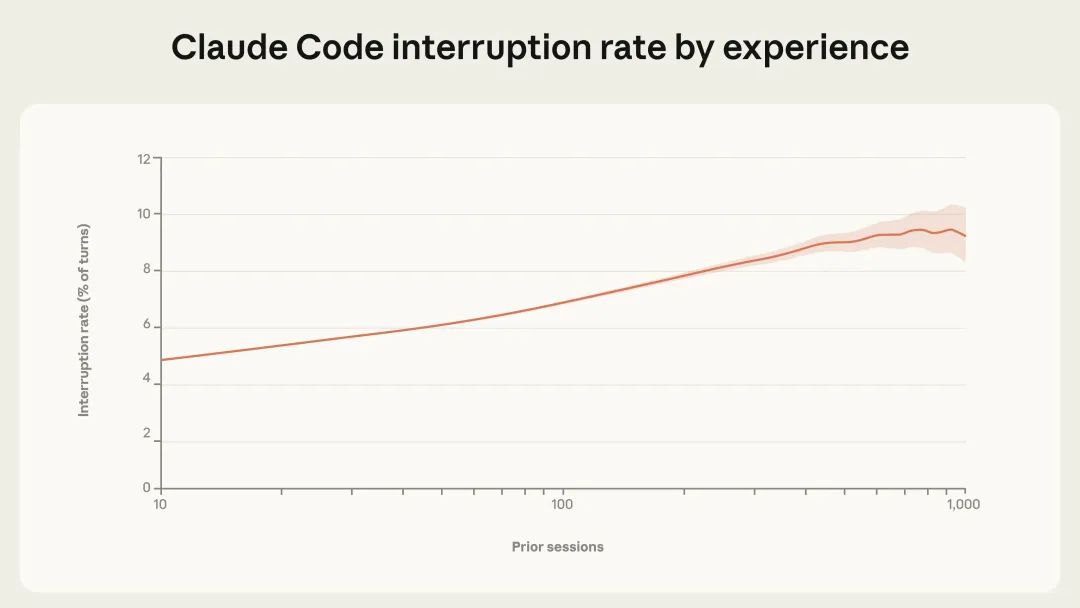
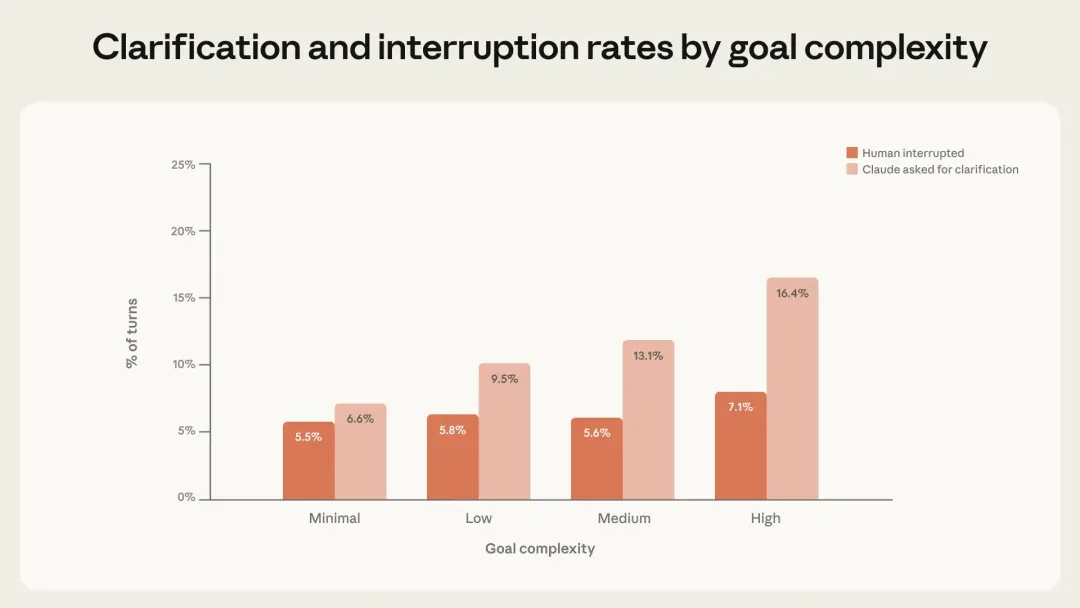
读完这篇报告,我后背发凉, 因为现在是自主工作45分钟,几个月后可能就是450分钟,even更长。上周五深夜,我把Anthropic最新发布的这篇研究报告从头到尾读了两遍。不是因为恐惧。而是因为一种很具体的、落地的感觉涌上来——那扇窗户,现在还开着。但它正在慢慢关上。这篇报告不是PR稿,不是产品发布会,是Anthropic的研究团队用真实数据分析了数百万次人类和AI Agent(AI智能体)之间的交互之后,写出来的。里面有几个数据,我觉得每个人都应该看到:AI Agent自主工作的时间,三个月内翻倍了,从25分钟到超过45分钟越有经验的用户,越少"逐步审批"AI的每个动作,越多地直接放手让AI跑目前AI Agent的使用,将近50%集中在软件工程领域,但医疗、金融、网络安全正在快速涌入这意味着什么?意味着我们正处在一个极其罕见的窗口期:AI的能力已经远超大多数人给它的权限——它能做的,比人们敢让它做的多得多。下面,我把这篇报告完整翻译给你看。翻译完之后,我会告诉你,我们这些"非技术人",具体应该怎么做。AI智能体已经到来。它们正在被部署到各种各样的场景中——从邮件分类到网络间谍活动,风险跨度极大。理解这个光谱对于安全部署AI至关重要,但我们对人们在现实世界中如何使用智能体,其实知之甚少。我们通过隐私保护工具,分析了Claude Code和公开API中数百万次人类与智能体的交互,试图回答:人们给了智能体多大的自主权?随着经验积累,这种授权会如何变化?智能体在哪些领域运作?这些行动有多大风险?1. Claude Code自主运行时间越来越长。 在运行时间最长的那批任务中,Claude Code在停下来之前自主工作的时长,三个月内几乎翻倍——从不到25分钟增长到超过45分钟。这个增长在多次模型发布之间是平滑的,说明并非纯粹是模型能力提升导致的,而是现有模型在实际使用中发挥的自主性,远低于它们真实能达到的水平。2. 有经验的Claude Code用户更频繁地开启"自动审批",但也更频繁地主动打断。 随着用户积累使用经验,他们倾向于停止逐一审查每个操作,转而让Claude自主运行,只在必要时介入。新用户中约有20%的会话使用完全自动审批,有经验的用户这一比例超过40%。3. Claude Code主动暂停寻求澄清的次数,多于人类打断它的次数。 除了人类主动暂停,智能体自身主动暂停也是部署系统中重要的监督形式。在最复杂的任务中,Claude Code寻求澄清的频率是人类主动打断的两倍以上。4. 智能体在高风险领域使用,但尚未大规模铺开。 公开API上的大多数智能体行为风险较低且可逆。软件工程占了近50%的智能体活动,但医疗、金融和网络安全领域的使用正在兴起。我们的核心结论是:有效监督智能体,需要新的部署后监控基础设施,以及帮助人类和AI共同管理自主性与风险的全新交互范式。智能体很难进行实证研究。首先,对于什么是智能体,目前没有公认的定义。其次,智能体正在快速演进。去年,许多最复杂的智能体(包括Claude Code)都只涉及单一对话线程,而今天,已经出现了可以自主运行数小时的多智能体系统。此外,模型提供商对客户智能体架构的了解非常有限——我们没有可靠的方法把对API的独立请求关联成连贯的"智能体会话"。我们将智能体定义为:配备了工具、能够采取行动的AI系统——比如运行代码、调用外部API、向其他智能体发送消息。研究这些工具的使用情况,能让我们了解智能体在真实世界中的行为。公开API:让我们能广泛了解数千个客户的智能体部署情况。我们在单次工具调用层面进行分析,虽然无法重建完整的会话行为序列,但能做出有依据、一致的现实世界观察。Claude Code:作为我们自己的产品,我们可以跨会话关联请求,完整了解从头到尾的智能体工作流。这使Claude Code特别适合研究自主性——比如智能体运行多久不需要人类介入、什么触发了中断、用户随经验积累如何调整监督方式。但它只是单一产品,主要用于软件工程。通过结合两个数据源,我们能回答单独靠任何一个都无法回答的问题。在Claude Code中,我们可以直接测量:从Claude开始工作到停下来(无论是完成任务、提问,还是被用户打断),中间经过了多长时间。大多数Claude Code的"回合"(turn)时间很短,中位数约45秒,过去几个月基本稳定在40到55秒之间。对于一个正在快速增长的产品来说,这是可以预期的:新用户加入后,因为经验较少,不太可能给Claude充分的自主权。真正有说服力的信号在尾部。 最长的那些回合,揭示了Claude Code最雄心勃勃的使用方式,也指向了自主性的发展方向。从2025年10月到2026年1月,第99.9百分位的回合时长几乎翻倍,从不到25分钟增长到超过45分钟(见下图)。值得注意的是,这个增长跨越了多次模型发布,是平滑的。如果自主性纯粹是模型能力的函数,我们会期待在每次新版本发布时看到跳跃式的增长。这种相对平稳的趋势,反而说明了另一些因素在起作用:资深用户随着时间积累对工具的信任、尝试更有雄心的任务、以及产品本身的持续改进。我们还分析了Anthropic内部的Claude Code使用情况。从8月到12月,Claude Code在内部用户最具挑战性任务上的成功率翻倍,同时每次会话中人类干预的平均次数从5.4次降至3.3次——用户在给予Claude更多自主权的同时,也在取得更好的结果。这两组数据都指向一个重要现象:"能力溢出"(deployment overhang)——模型实际能处理的自主性,远超其在现实中被允许发挥的程度。顺便比较一下:外部机构METR估计,Claude Opus 4.5能以50%的成功率完成需要人类工作近5小时的任务。而Claude Code中第99.9百分位的回合时长只有约42分钟。两者并不直接可比——METR的评估是在没有人类交互的理想化环境下进行的,而我们的数据反映的是现实中Claude会暂停寻求反馈、用户会主动打断的真实情况。这进一步说明:在实践中授予模型的自主权,远远落后于它们真实能处理的水平。我们发现,随着用户积累Claude Code的使用经验,他们会给予Claude更多自主权(见图2)。新用户(少于50次会话)在约20%的会话中使用完全自动审批,到750次会话时,这一比例增长到超过40%。这种转变是渐进的,反映了信任的稳步积累。值得注意的是,Claude Code默认要求用户手动审批每个操作,所以部分转变也可能是用户随着对Claude能力的熟悉,主动调整了产品设置。审批每个操作只是监督Claude Code的方式之一。用户也可以在Claude运行时主动打断,提供反馈。我们发现,打断率也随着经验增加而上升:新用户(约10次会话)在5%的回合中打断Claude,而有经验的用户打断率约为9%(见下图)。打断增加和自动审批增加同时发生——这看起来像是矛盾,但其实反映了用户监督策略的转变:新用户:更倾向于在每个动作执行前逐一审批,因此很少需要中途打断有经验的用户:更倾向于让Claude自主工作,在出问题或需要调整方向时再介入;更高的打断率也可能反映他们对何时需要介入有了更敏锐的直觉这个发现很重要:有经验的用户并非放弃了监督,而是换了一种更主动的监督方式。 有效的监督并不要求审批每一个动作,而是要在关键时刻处于能够干预的位置。四、Claude Code主动求问,比人类打断更多当然,人类不是塑造自主性的唯一力量。Claude本身也是主动参与者——当它不确定如何进行时,会自行停下来寻求澄清。我们发现,随着任务复杂度增加,Claude Code寻求澄清的频率也在增加——而且比人类主动打断的频率更高(见下图)。在最复杂的任务中,Claude Code寻求澄清的频率是最简单任务的两倍以上,说明Claude对自身不确定性有一定的校准能力。以下是Claude Code停止的常见原因,以及人类打断Claude的常见原因对比:这些发现表明,智能体主动停止是部署系统中一种重要的监督形式。训练模型识别并主动向人类报告自身不确定性,是一种重要的安全特性,与权限系统、人类监督等外部保障互为补充。我们让Claude对公开API中的单次工具调用,在1到10的量表上估计其相对风险和自主性:整体而言,公开API上80%的工具调用来自具有至少一种保障措施的智能体,73%看起来有某种形式的人类介入,只有0.8%的操作是不可逆的(如向客户发送电子邮件)。从领域分布来看,软件工程占了近50%的工具调用。除此之外,商业智能、客服、销售、金融和电子商务都有所涉及,但每个领域占比都不超过几个百分点。这些模式表明,我们正处于智能体采用的早期阶段。软件工程师是最先大规模构建和使用智能体工具的群体;其他行业正开始进行实验性探索。随着智能体扩展到这些风险更高的领域,风险和自主性的边界将进一步扩展。我们只能分析来自Anthropic单一模型提供商的流量,其他模型构建的智能体可能呈现不同的模式公开API流量让我们只能分析单个工具调用,无法重建完整的智能体会话;Claude Code提供了完整会话数据,但只限于一款以软件工程为主的产品我们的分类由Claude自动生成,无法因隐私约束而进行人工检查底层数据这项分析反映的是特定时间窗口(2025年底至2026年初),智能体格局正在快速变化我们正处于智能体采用的早期,但自主性在增加,高风险部署正在涌现,尤其是随着Cowork等产品让智能体更加普及。我们提出以下建议:模型和产品开发者应投资于部署后监控。 部署前评估只能测试受控环境下的能力,许多发现在部署前测试中根本看不到。我们必须理解人们在实践中如何与智能体交互。模型开发者应训练模型识别自身不确定性。 让模型主动向人类报告不确定性,是与权限系统、人类审批流程互补的重要安全属性。产品开发者应为用户监督而设计。 有效的智能体监督不止是在审批链上放一个人。随着用户积累经验,他们倾向于从审批每个动作转变为监控整体行为,在需要时介入。产品开发者应投资于让用户可信地了解智能体行为的工具,以及简单的干预机制。现在不应强制规定特定交互模式。 我们的发现表明,有经验的用户会转向监控和必要时介入的方式,而非审批每个动作。要求人类批准每个动作的规定,会制造摩擦,却不一定带来安全效益。完整报告(含附录)见:https://www.anthropic.com/research/measuring-agent-autonomy它实际上能自主完成需要人类工作5小时的任务,但大多数人只敢让它工作45分钟。它能处理高度复杂的事务,但50%的人只用它来写代码。它能独立做决策,但大多数人还在逐一审批它的每一步操作。第一条路:成为"AI × 你所在行业"的早期探索者报告里说得很清楚:医疗、金融、网络安全、客服、电商——这些领域正在开始实验AI Agent,但距离规模化还早得很。你在哪个行业工作?你最了解哪个领域的工作流程?你有没有可能,成为第一批把AI Agent真正用到那个领域里的人?不需要你会编程。你需要的是:对你的行业足够熟悉,熟悉到知道哪些工作流程可以被自动化。第二条路:学习"如何有效监督AI",而不是"如何替代AI"报告里最有趣的发现之一是:有经验的用户不是"把所有事情都丢给AI",而是发展出了更高效的监督策略——他们知道什么时候放手,什么时候打断。这种能力,不是软技能,是硬本领。未来所有知识工作者,都需要学会如何做一个高效的"AI监督者"。而现在学,成本最低。你可以今天就开始:打开Claude Code或者任何一个AI Agent工具,不要只是用它回答问题,而是给它一个任务,然后观察它怎么工作,什么时候它会卡住,你需要怎么介入。这个过程本身,就是在积累宝贵的经验。AI能做的事会越来越多,但AI不能替代一件事——你亲身踩坑的经验,和你基于这些经验形成的判断力。今天,关于"如何在某个具体领域用好AI Agent"的知识,极度稀缺。如果你愿意尝试、愿意记录、愿意分享,你就有机会成为那个领域的早期意见领袖。这不是鼓励你去做网红。这是说:当一个新技术浪潮来临,最早认真学习并记录探索过程的人,往往会在浪潮中站得最稳。这篇报告的结论其实很清醒,也很温和:我们还在早期,没有人能完全预测接下来会发生什么。但有一件事是确定的:那条从"AI被严重低估使用"到"AI被充分发挥"的路,需要有人去走。如果这篇文章对你有帮助,欢迎分享给你觉得应该看到的人。
我们下篇见。