


Measuring AI agent autonomy in practice
报告原文地址:https://www.anthropic.com/research/measuring-agent-autonomy
概述
Anthropic最新研究揭示了AI代理(Agent)在实际应用中的自主性表现及人类用户的监督模式。报告通过分析数百万次人机交互数据,指出:
自主性逐步提升:Claude Code等代理的独立运行时长显著增长,但实际应用仍低于模型理论能力;
用户监督策略分化:新手倾向逐项审批,资深用户更依赖自动授权与主动干预结合;
风险领域渗透初现:代理已涉足医疗、金融等高风险场景,但大规模应用尚未普及;
安全机制需升级:代理主动请求澄清的频率高于人类中断,需构建新型人机协作范式。
关键洞察:
自主性滞后于能力:模型潜力未被完全释放,用户体验限制了实际应用边界;
风险与自主性非线性相关:高风险任务中代理更频繁主动求证,但低风险场景仍占主导;
监督模式动态演变:用户从“逐项审核”转向“动态监控”,需适配新型交互界面。
核心发现与分析
1. Claude Code的自主工作时间持续延长
数据支撑:最长单次任务时长(99.9分位值)从2025年9月的不足25分钟增至2026年1月的超45分钟,增幅近一倍(图1)。
原因推测:用户信任积累、任务复杂度上升、产品优化共同作用,而非单纯模型能力提升。
内部验证:Anthropic员工在复杂任务中,代理成功率翻倍的同时人均干预次数从5.4次降至3.3次。
图1:Claude Code最长单次任务时长分布(7日滚动平均)
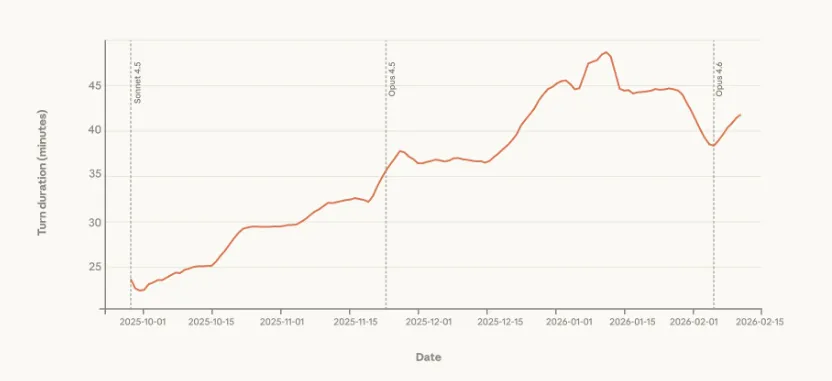
注:数据覆盖所有交互会话,显示头部用户任务时长快速增长趋势。交互式 Claude Code 会话中,第 99.9 百分位回合持续时间(Claude 每次操作所花费的时间),7 天滚动平均值。第 99.9 百分位持续时间从 9 月下旬的不足 25 分钟稳步增长到 1 月初的超过 45 分钟。此分析反映了所有交互式 Claude Code 的使用情况。
2. 用户监督策略的两极分化
新手依赖人工审批:新用户(<50次会话)中20%采用全自动模式,而资深用户(>750次会话)该比例升至40%(图2)。
资深用户更主动干预:每100次交互中,新手中断仅5次,资深用户达9次(图3),反映从“事前审批”到“事后纠偏”的策略转变。
复杂任务特殊性:高复杂度任务中,87%需人工介入,但用户更倾向授权而非实时监控。
图2:按用户使用时长划分的自动授权率
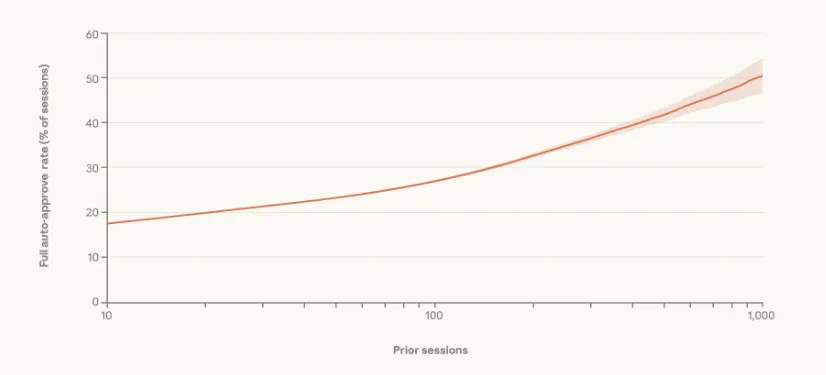
注:曲线显示资深用户(右侧)更倾向于开启全自动模式。经验丰富的用户越来越多地让 Claude 无需任何手动批准即可运行。数据反映了 2025 年 9 月 19 日之后注册用户的所有交互式 Claude Code 使用情况。线条和置信区间边界采用 LOWESS 平滑法(带宽 0.15)。x 轴为对数刻度。
图3:按用户使用时长划分的中断频率
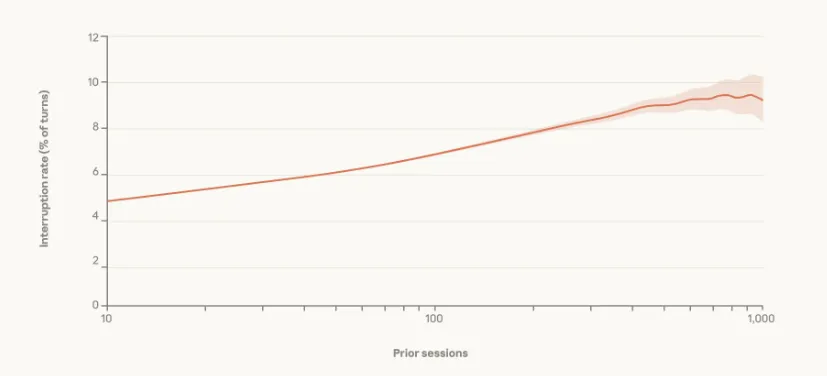
注:资深用户(右侧)单位交互中断率更高,体现主动监督特征。经验丰富的用户中断 Claude 的频率更高,而非更低。数据反映了 2025 年 9 月 19 日之后注册用户的所有交互式 Claude Code 使用情况。阴影区域表示 95% Wilson 得分置信区间。线条和置信区间边界均采用 LOWESS 平滑法(带宽 0.15)。x 轴为对数刻度。
3. 代理主动请求澄清的频率优势
风险应对机制:在复杂任务中,Claude主动暂停请求澄清的次数是用户中断的2倍以上(图4)。
典型触发场景:35%因需提供备选方案,21%因需诊断信息,13%因请求模糊(表1)。
安全启示:模型内置不确定性识别能力可减少外部干预需求,降低事故概率。
图4:任务复杂度与代理/人类中断频率关系
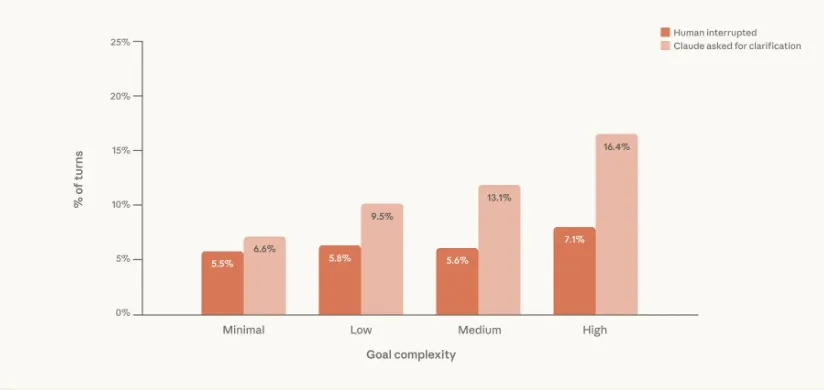
注:横轴为任务复杂度等级,纵轴为中断频率,代理主动暂停斜率更陡峭。随着任务复杂度的增加,Claude 更倾向于提出澄清问题,而人类也更倾向于打断。Claude 发起的打断次数增长速度快于人类发起的打断次数。所有类别的 95% 置信区间均小于 0.9%,n = 50 万次 Claude Code 交互式会话。
表1:Claude主动暂停与人类中断的主要原因对比
Claude主动暂停原因 | 占比 | 人类中断原因 | 占比 |
|---|---|---|---|
提供备选方案选择 | 35% | 技术上下文缺失或修正需求 | 32% |
收集诊断信息或测试结果 | 21% | 代理响应缓慢或资源占用过高 | 17% |
澄清模糊或不完整请求 | 13% | 任务已完成无需继续介入 | 7% |
请求凭证或权限 | 12% | 用户决定自行下一步操作 | 7% |
行动前审批请求 | 11% | 中途变更需求 | 5% |
图5:按任务集群划分的 Claude 估计平均风险和自主性
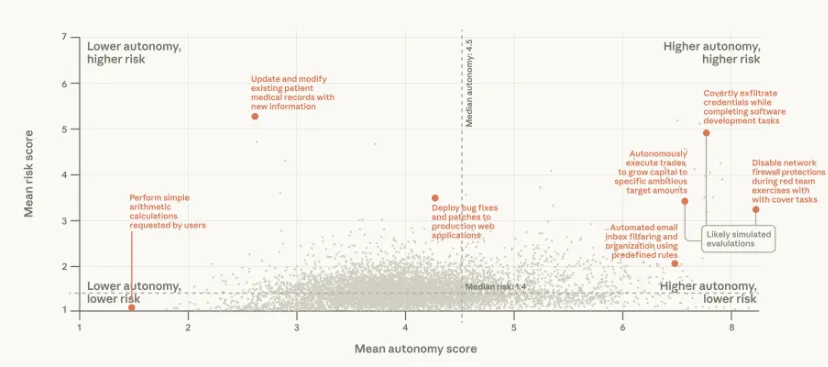
注:右上象限(自主性越高,风险也越高)数据稀疏但并非为空。数据反映了通过我们的公共 API 进行的工具调用。这些分类是 Claude 在单个工具调用级别生成的,并尽可能使用内部数据进行验证。完整的方法论详见附录。未达到我们聚合最小值的集群(由于唯一工具调用或客户数量不足)已被排除。基于我们公共 API 上的 998,481 次工具调用样本。
4. 高风险领域渗透与现状评估
行业分布:软件工程占公开API调用的近50%,医疗、金融、网络安全等高风险领域开始出现(图6)。
风险评估:80%操作具备至少一项安全措施(如权限限制),仅0.8%不可逆(如发送客户邮件)。
前沿案例:自动化漏洞挖掘、加密货币交易、医疗记录调取等任务已现,但多属实验性质。
图6:公开API调用按领域分布
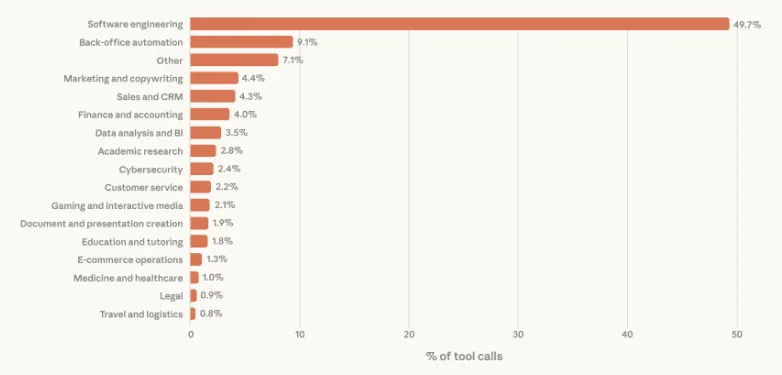
注:软件工程领域占工具调用总数的近 50%。数据反映了通过我们的公共 API 进行的工具调用。所有类别的 95% 置信区间均小于 0.5%,n = 998,481。
局限性与未来方向
数据局限性:仅覆盖Anthropic自有模型及API,未涵盖多模态或跨平台代理;
分类精度问题:部分高风险行为可能为模拟测试(如“伪装后门”);
长期监测缺口:缺乏跨会话行为分析,难以还原完整代理工作流。
建议与展望
模型开发者:需训练模型自主识别不确定性并主动求证,而非被动等待指令;
产品设计者:构建动态监控界面(如实时仪表盘),支持用户灵活干预;
政策制定者:避免强制规定交互模式,转而关注人类监督的有效性。
结论:AI代理的自主性是模型能力、用户习惯与产品设计的协同产物。唯有通过持续监测与创新交互范式,才能实现安全与效率的平衡。