


全球电力工业正经历从“垂直一体化”向“竞争性市场化”的深刻转型。在现代市场环境下,发电商、售电公司及虚拟电厂(VPP)等主体失去了确定性的供需信息保障,转而进入一个高度波动的博弈环境。
不确定性来源的爆发式增长
供给侧: 可再生能源(RES)的大规模接入引入了强随机性,能源出力由“计划控”转为“天气控”。
需求侧: 随着产消者(Prosumer)和电动汽车(EV)的普及,负荷曲线呈现出高度的非线性与时空耦合。
市场侧: 节点边际电价(LMP)受到燃料成本、网络阻塞及竞争对手策略的复杂影响,表现出明显的均值回归与价格尖峰特征。
传统确定性优化(Deterministic Optimization)因缺乏对极端场景和尾部风险的捕捉能力,已难以满足现代交易需求。因此构建多维度的不确定性建模体系已成为制定稳健交易策略的核心基石。
一、随机规划(SP):基于场景演化的经典框架
随机规划是处理概率信息已知情形下的标准方法。其核心逻辑是将连续的概率分布离散化为一系列“情景(Scenarios)”。
1. 两阶段决策机制:该框架将决策流分为两个时序阶段:
1.1 第一阶段(预决): 在不确定性揭示前做出(如日前投标量、机组组合)。
1.2 第二阶段(追补): 在不确定性实现后进行的调整(如实时调度、平衡溢价支付)。
数学目标函数通常表示为:
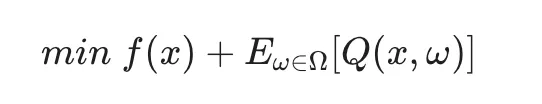
2. 场景生成与削减的前沿技术
Time-GANs: 相比传统蒙特卡洛模拟,生成对抗网络(GAN)能够自动捕获可再生能源出力在时间序列上的长程相关性,无需预设分布形式。
快速前向选择(FFS): 针对场景爆炸问题,利用 Kantorovich 距离 进行概率测度压缩,在保留统计特征的前提下大幅提升计算效率。
二、鲁棒优化(RO):针对“最坏情况”的免疫策略
当概率分布难以获取或不可靠时,鲁棒优化提供了一种极端风险对冲手段。它不关注平均收益,而关注在给定的不确定性集合(Uncertainty Set)内的生存能力。
1. 三层优化架构(Min-Max-Min)
内层: 最优运行调整。
中层: “自然界”寻找使系统成本最大的最坏场景。
外层: 交易者寻找在最坏场景下损失最小的策略。
2. 保守性与经济性的平衡
通过引入不确定性预算(Budget of Uncertainty),决策者可以调节策略的保守程度。例如,限制24小时内发生剧烈波动的时段总数,从而避免因过度防范极低概率事件而导致的经济性大幅下滑。
三、分布鲁棒优化(DRO):数据驱动的融合路径
DRO是近年来的学术热点,旨在弥合SP(过于依赖分布假设)与RO(过于保守)之间的鸿沟。
模糊集(Ambiguity Set): DRO构建一个包含所有可能分布的“分布集合”。
Wasserstein 距离: 通过历史数据构建经验分布球体。随着数据量的增加,模糊集半径收缩,模型从鲁棒性向统计最优性平滑过渡。这种方法有效规避了模型设定偏误(Model Mis-specification)风险。
四、信息间隙决策理论(IGDT):非概率的容错边界分析
在某些极端不确定环境(如政策剧变)中,决策者可能连波动范围都无法确定。IGDT 转换了建模视角:
鲁棒性函数(α-Robustness): 在满足最低利润底线的前提下,系统能承受的最大波动范围是多少?
机会函数(β-Opportunity): 为了获得超额“暴利”,市场需要具备多大的有利波动潜力?
IGDT 为管理层提供了一个直观的“利润-风险”权衡曲线,而非单一的最优解。
五、机会约束与风险度量(CVaR)
为了在模型中量化“厌恶风险”的程度,通常引入 条件在险价值(CVaR):
VaR 仅关注特定概率下的损失阈值,而 CVaR 关注超过阈值后的损失期望(尾部风险)。
在交易模型中,通过将目标函数设为Maximize(1-λ)E[Profit] +λCVaR,交易员可以灵活定制其风险偏好。
六、深度强化学习(DRL):高频交易与博弈进化
针对实时交易和多主体博弈,基于数学规划的方法面临计算瓶颈。
无模型学习: DRL智能体通过与市场环境不断交互,学习最优报价策略(如 PPO, SAC 算法)。
多智能体(MADRL): 能够模拟多个市场主体之间的纳什均衡演化,捕捉“经济持留”等策略性行为,尤其适用于高频调频市场。
下表归纳了不同建模路径的特征:
| 建模方法 | 核心逻辑 | 典型应用场景 | 主要优缺点 |
| 随机规划 (SP) | 期望价值最大化 | 日前市场、中长期合同 | 易于理解,但对概率分布准确性要求高 |
| 鲁棒优化 (RO) | 最小化最大损失 | 电网安全校核、极端风险防控 | 计算稳健,但策略倾向于保守 |
| 分布鲁棒 (DRO) | 概率分布的鲁棒性 | 虚拟电厂竞价、套利交易 | 兼顾数据与稳健性,数学求解难度较高 |
| IGDT | 容错能力最大化 | 政策波动风险分析 | 无需概率分布,提供直观的决策边界 |
| DRL | 行为演化与交互 | 实时市场、多主体自动交易 | 响应极快,但模型可解释性弱 |