


文末有惊喜,记得看到最后~
最近项目组为了搞“智能投研助手”已经连加了三个周的班,但效果总是差点意思:明明原文是1.2亿营收,模型推理出来变成12亿。想用参数规模更大的满血版DeepSeek R1,老板又不批预算买H20卡。看着测试用例里时不时出现的胡说八道反馈,真上线了,研究员一天能给我们打八百个电话。
周末得空在家刷了会儿Arxiv,看到一篇新论文《Bridging the Arithmetic Gap: The Cognitive Complexity Benchmark and Financial-PoT for Robust Financial Reasoning》,创作团队的观点十分扎心:大模型在金融定量推理任务上就如同文科生遇到理科试卷,别指望它能完美推理!

但这篇论文提出的 Financial-PoT(金融思维程序) 架构,让我看到了在低算力、低预算下解决这个问题的希望。说人话就是:既然大模型算术差,那就让它只负责写Python代码,计算的事交给CPU去干。
PoT将分析任务分为语义提取和数学计算两部分,数学计算部分由实时生成的独立的python计算程序完成,从而提升大模型任务性能和准确率。
DeepSeek 这种推理模型虽然强,但在处理 A股年报这种“数据源+映射难度+结果单位”三维复杂的场景时,依然会发生论文里说的“认知崩溃”。
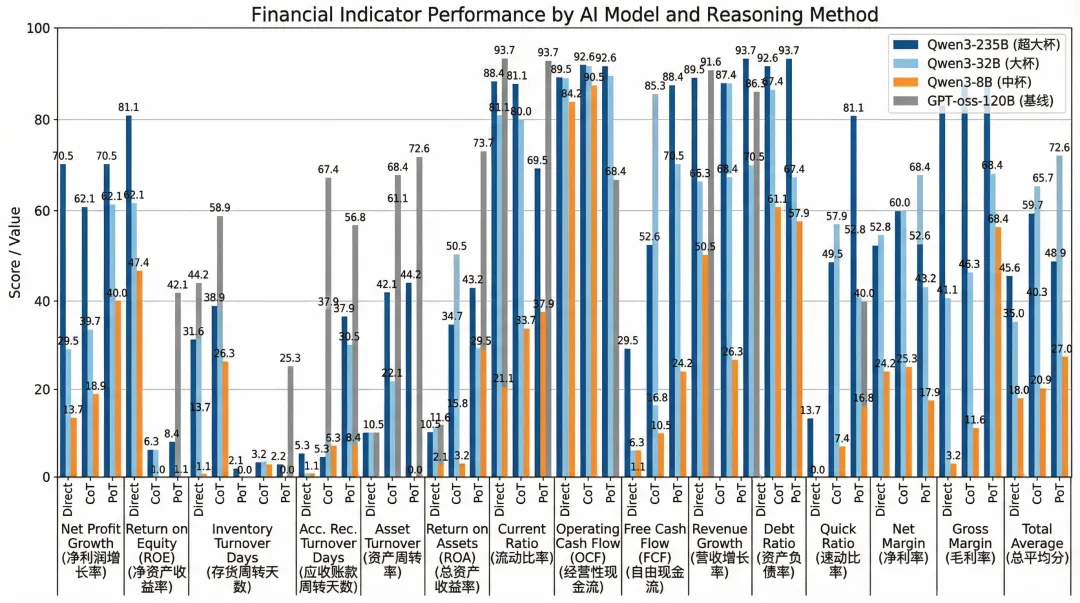
图片为论文table 5数据重绘
简单总结这篇论文给我的 3 个落地启发:
1、降本增效:30B模型能打 235B
论文实测证明,在研报分析这种复杂推理任务场景下,用“模型生成代码+外部工具执行”的模式,小参数模型的效果能超越单纯依靠“大力出奇迹”的大参数模型。 这意味着我们不用去考虑H800买不到的问题了!用本地部署的 30B/35B 模型配合代码解释器,就能达到甚至超过昂贵大模型的准确率。
2、安全合规:从“有概率失败”到“可排查到底哪里失败了”
大家做金融项目最怕什么?怕大模型幻觉。大模型直接吐出一个数字,你根本不知道它是怎么算出来的,业务追究出问题原因时总是会汗流浃背。 但在 PoT 模式下,模型输出的是一段 Python 代码。
算对了,那是逻辑对。
算错了,看代码就知道是公式引错了还是数据提错了。 这种“可追溯、可审计”的特性,才是敢上线的前提。
3、 别迷信“全能”,相信“分工”
之前我做行情抓取时也踩过坑,死磕 Prompt 让模型算同比增长率,结果始终无法平衡响应速度和解析准确度。后来把任务拆解:大模型只负责提取“今年营收”和“去年营收”两个变量,计算交给 Python 脚本,准确率瞬间从 65% 飙到 85%。这篇论文用学术严谨的数据(基于95份A股年报的CCB基准测试)验证了这条路的正确性。
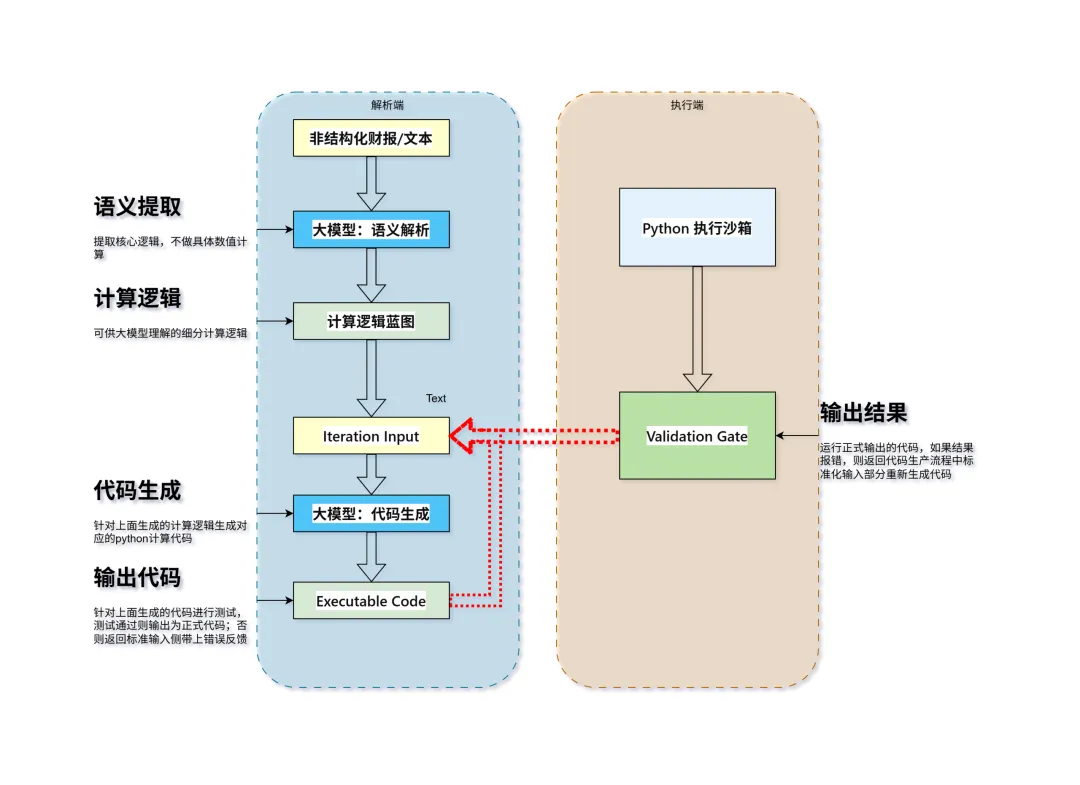
图片为论文PoT架构图数据重绘
但也必须得泼盆冷水,这篇论文虽然给了新思路,但在实际落地中,这3个“深坑”不解决,上线必炸 ⚠️:
限于篇幅,更多关于论文的细节解析和思考我整理到下面的资料中,欢迎领取:
- 【细节深挖】我针对论文更多细节的独家解析(是我整个论文研究解析过程中的完整思考分析)。
- 【逻辑全景】我提炼的高清思维导图,一眼看懂原文全篇脉络。
- 【原文直达】官方下载通道(论文原文有大量细节和图表可帮助读者进一步深入研究,有兴趣的朋友建议阅读一下原文)

参考资料
- 论文标题:Bridging the Arithmetic Gap The Cognitive Complexity Benchmark and Financial-PoT for Robust Financial Reasoning
- 原作者:Boxiang Zhao, Qince Li, Zhonghao Wang, Yi Wang, Peng Cheng, Bo Lin
- 声明:
本文仅对论文观点进行技术解读与金融应用前景探讨,版权归原作者所有。