


四平商圈的蜜饯、古早味怀旧餐厅的灯光、近40位科技大佬齐聚,黄仁勋站在椅子上高举酒杯,宣告2026将是AI产业“极度吃紧”却又“非常好”的一年。
台北四平商圈的夜市依旧热闹,黄仁勋不久前在这里采购蜜饯时说:“水果干、各类花生糖和其他零食都非常棒,是我儿时的味道。”几小时后,他在台北砖窑古早味怀旧餐厅举办了一场被称为“兆元宴”的晚宴。
现场,黄仁勋站在椅子上向近40位科技界领袖致辞,他们来自台积电、联发科、广达、鸿海等公司。

这位英伟达CEO直言:“AI要有智慧,就一定要有记忆体。”他预测2026年对高带宽内存与LPDDR的需求将大幅爆发。
01 兆元盛宴
科技巨头的聚会,黄仁勋在“兆元宴”上的开场白与众不同——他站上了椅子。近40位台湾科技企业的掌门人围坐一堂,这是AI时代供应链最高级别的聚会。
宴会的第一排坐着华硕创始人施崇棠、联发科执行长蔡力行、台积电董事长魏哲家等重量级人物。鸿海董事长刘扬伟、和硕董事长童子贤等业界大佬也齐聚一堂。
黄仁勋回顾了与供应链伙伴共同克服的挑战:“2025年是非常充满挑战的一年,因为我们开始生产Grace Blackwell。”他坦言Grace Blackwell相比前代产品Hopper要复杂得多。
02 供需矛盾
黄仁勋对2026年AI产业的预测令人瞩目。他认为2026年将是AI产业“极度吃紧的一年”,整个供应链将面临前所未有的压力。
半导体供给过去每年以约一倍速度成长,但AI需求的增长速度更快。从芯片、封装到存储的每个环节都极度紧张,特别是对高带宽内存与LPDDR的需求将大幅爆发。
与童子贤对2026年产业前景的高度乐观相呼应,黄仁勋也表示今年将迎来“非常好的一年”。
03 战略转型
面对外界对ASIC专用芯片可能取代GPU的担忧,黄仁勋态度强硬地表示:“不合理也不现实。”他的理由是英伟达早已不是单一的芯片供应商。
英伟达正在打造整个AI基础架构,涵盖CPU、GPU、网络芯片、交换器与资料处理系统。英伟达与几乎所有大型AI企业合作,包括Google、OpenAI、Anthropic与xAI。
这种全栈生态整合的战略转型,使得英伟达能够提供从硬件到软件的全套解决方案。黄仁勋透露,英伟达目前每年研发预算已达200亿美元,未来仍将以每年约50%的速度成长。
04 台湾供应链
黄仁勋对台湾供应链给予了高度评价:“NVIDIA没有台湾就不可能存在。”他盛赞台湾企业的技术实力与工程文化。
他特别强调台积电在先进制程上的关键地位,预期未来十年台积电产能将“远超过倍数成长”。黄仁勋形容这不仅是服务于英伟达的需求,更是“整个人类史上最大规模的科技基础建设扩张之一”。
英伟达与联发科的合作也在深化,双方将携手打造“低功耗但极高效能”的SoC,锁定新世代AI PC与AI运算装置市场。
05 竞争格局
黄仁勋对ASIC竞争格局的回应值得深思:“要做到比英伟达产品更好的ASIC,要有比英伟达更好的研发人员。”他直言许多公司正在尝试,但英伟达仍走在前面。
英伟达的全栈生态战略正是应对竞争的关键。从Hopper到Blackwell,再到正在研发的Rubin平台,技术难度已从“困难”变成“不可能”。
黄仁勋还透露,英伟达将参与OpenAI下一轮募资,且金额可能是英伟达史上最大的一笔战略投资。
06 未来展望
从黄仁勋的谈话中,可以看出英伟达对未来有着清晰的规划。Vera Rubin平台已经启动,它由“六颗全球最先近芯片组成”,制程与整合复杂度极高。
黄仁勋认为,我们正处于新一轮AI基建的起点,这个过程还需要大约10年时间。AI需要遍布全球的计算设施,需要在中国台湾建造,也需要在美国、欧洲、日本、东南亚建造。
“有三类工厂正在建成,一是晶圆厂,二是计算机组装厂,第三类则是AI工厂。”黄仁勋描绘了AI基础设施建设的完整蓝图。
“2026年是非常关键的一年,供应链会工作得很辛苦。”黄仁勋在“兆元宴”尾声再次向供应链伙伴致谢。
他站在椅子上说的那句“This year is going to be very big”,不仅是对供应链伙伴的鼓励,也是对整个AI产业发出的信号。

附专业科普:ASIC与GPU,谁将主导AI计算的未来?
在黄仁勋的台北晚宴上,他直言“ASIC取代GPU不现实”,这一表态背后是两种不同芯片技术路线的竞争。要理解这场技术之争,我们需要先弄清楚ASIC和GPU到底是什么。
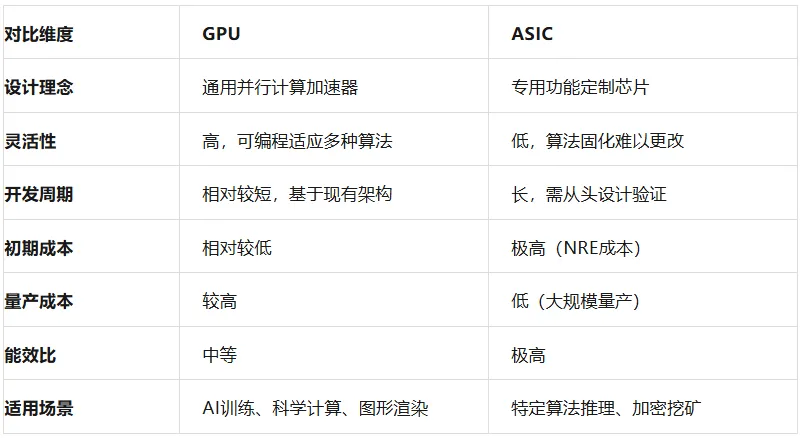
一、GPU:通用计算的并行加速器
图形处理器(GPU) 最初是为图形渲染而设计的专用处理器,但它的并行计算架构意外地成为了人工智能计算的“利器”。
GPU的核心优势在于它拥有成千上万个小型计算核心,能够同时处理大量相似的计算任务。这种“并行计算”能力恰好契合了AI算法的需求。
架构特点:GPU采用SIMD(单指令多数据)架构,一条指令可以同时操作多个数据
计算精度:支持从FP64到FP8多种精度计算,适应不同AI任务需求
内存带宽:配备高带宽内存(HBM),能快速传输海量数据
编程友好:拥有成熟的CUDA/OpenCL生态系统,开发者工具链完善
在AI训练中,GPU能够同时处理神经网络中数百万个参数的梯度计算,这是CPU难以企及的。黄仁勋强调的“全栈AI架构”正是建立在GPU的强大并行计算能力之上。
二、ASIC:专用定制的效率王者
专用集成电路(ASIC) 是为特定应用量身定制的芯片,如比特币矿机中的SHA-256芯片、手机中的基带芯片等。
ASIC的设计理念是“用专用硬件实现特定功能”,它的优势在于极致的效率和功耗比:
极致效率:针对特定算法优化,执行速度可比通用芯片快数十倍
低功耗:去除了不必要的电路,功耗大幅降低
高集成度:将完整系统集成在单一芯片上
成本优势:量产后的单位成本较低
谷歌的TPU(张量处理器)就是典型的AI ASIC,专为神经网络推理设计,在搜索、翻译等场景中表现出色。
三、技术对比:通用灵活vs专用高效
四、AI计算的选择:为什么GPU难以被取代?
黄仁勋认为“ASIC取代GPU不现实”的技术逻辑在于:
1. AI算法快速演进:神经网络架构几乎每年都有突破性进展。ASIC一旦流片,算法就固化了,而GPU的可编程性能快速适应新算法。
2. 训练与推理的不同需求:AI训练需要高度灵活性,因为研究人员不断尝试新架构;推理阶段算法相对稳定,适合ASIC优化。英伟达的全栈战略覆盖了从训练到推理的全过程。
3. 生态系统壁垒:英伟达花费数十年建立的CUDA生态系统形成了“软硬件协同护城河”。超过400万开发者依赖这一平台,迁移成本极高。
4. 规模经济效应:GPU的大规模量产降低了单位成本,而ASIC需要足够大的特定市场才能分摊高昂的初期研发成本。
5. 内存瓶颈:无论是GPU还是ASIC,AI计算都受限于内存带宽。黄仁勋强调的“高带宽内存需求”对两者都是挑战,但英伟达在HBM领域已有深厚布局。
五、未来趋势:异构计算与融合架构
实际上,AI计算的未来可能不是“非此即彼”的选择:
1. 数据中心异构化:大型云服务商正构建同时包含GPU和ASIC的混合计算集群,根据工作负载动态分配任务。
2. 芯片内融合:新一代GPU正在集成更多专用加速单元,如英伟达Hopper架构中的Transformer引擎,在通用架构中融入专用优化。
3. 可重构计算:FPGA(现场可编程门阵列)和CGRA(粗粒度可重构架构)试图在灵活性与效率间寻找平衡点。
4. 软件定义硬件:通过高级编程框架,使同一硬件能高效执行多种算法,降低专用化带来的僵化风险。
黄仁勋强调的“全栈AI架构”正是看到了这一趋势:未来的竞争不仅是芯片的竞争,更是平台和生态系统的竞争。英伟达从GPU出发,已构建了涵盖芯片、系统、软件、开发工具的全栈能力,这是任何单一ASIC厂商难以比拟的。
回到黄仁勋的断言,ASIC确实在特定AI推理场景中表现优异,但AI的创新能力依赖于计算平台的灵活性。在算法快速演进、应用场景多元化的当下,GPU的通用性和成熟生态使其难以被取代。
然而,AI芯片的竞争格局仍在动态变化。中国自主研发的AI芯片正在崛起,云计算巨头也在定制自己的ASIC。未来的AI计算市场可能会形成 “GPU主导训练,多种架构共存推理” 的多元格局。
但一切皆有可能,或许下一个替代GPU的产品或技术已经在路上,而且已经走了很远了……