


1. 执行摘要与战略背景
2026年1月,蚂蚁集团(Ant Group)旗下的机器人子公司 Robbyant(蚂蚁灵波技术)正式开源发布了 LingBot-VLA(灵波-VLA)模型,这一举动标志着具身智能(Embodied AI)领域的一个重要转折点。作为一款拥有40亿参数(4B)的视觉-语言-动作(Vision-Language-Action, VLA)基础模型,LingBot-VLA 不仅在架构设计上融合了最前沿的视觉语言模型(VLM)与生成式动作策略,更在科学层面上提供了业界亟需的实证证据:在真实世界机器人数据上,VLA 模型的性能随着数据规模的增加呈现出未饱和的线性增长趋势。
长期以来,机器人学习领域受困于“莫拉维克悖论”(Moravec's paradox)的现代变体——虽然人工智能在抽象推理(如围棋、编程)上已超越人类,但在简单的感知运动技能(如折叠毛巾、清理桌面)上仍举步维艰。造成这一困境的核心原因被称为“数据墙”(Data Wall):与其能够以低成本从互联网获取数万亿 tokens 的文本数据不同,高质量的机器人交互数据极其稀缺、昂贵且难以标准化。此前的研究,如 Google 的 RT-1 和 RT-2,虽然验证了 VLA 范式的可行性,但往往受限于单一机型或封闭的训练数据,难以证明该路径在异构硬件和开放场景下的普适性。
LingBot-VLA 的发布打破了这一僵局。该项目基于 20,000 小时 的真实世界多机型数据进行预训练,这一规模在公开文献中处于绝对领先地位。模型架构上,它采用了“理解-执行”解耦的混合专家(Mixture of Experts)设计:利用 Qwen2.5-VL 作为强大的语义理解底座,结合 Flow Matching(流匹配)技术作为连续动作生成专家,成功解决了离散化动作空间带来的精度损失和时序抖动问题。此外,为了解决视觉感知中的“透明物体盲区”问题,Robbyant 同步发布了 LingBot-Depth,这是一种基于掩码深度建模(Masked Depth Modeling)的深度补全模型,赋予了机器人处理玻璃、金属等高挑战性材质的能力。
本报告将对 LingBot-VLA 进行详尽的解构,从模型架构的数学原理到大规模训练的基础设施优化,从 GM-100 基准测试的性能剖析到 Apache 2.0 协议下的开源生态影响,旨在为人工智能研究员、机器人工程师及行业分析师提供一份全景式的技术参考。
2. 具身智能的演进:从单一策略到 VLA 基础模型
要理解 LingBot-VLA 的技术地位,必须将其置于具身智能发展的历史坐标系中。过去十年,机器人控制策略经历了从基于模型的控制(Model-Based Control)到模仿学习(Imitation Learning),再到如今的 VLA 基础模型的范式转移。
2.1 传统模仿学习的局限性
在 VLA 概念出现之前,主流的学习方法是行为克隆(Behavior Cloning, BC)。BC 将机器人操作视为一个监督学习问题,即学习一个从当前观测 到动作 的映射函数 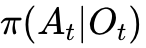 。尽管 BC 在特定任务(如抓取特定物体)上表现出色,但它存在严重的泛化瓶颈:
。尽管 BC 在特定任务(如抓取特定物体)上表现出色,但它存在严重的泛化瓶颈:
分布外(OOD)失效:一旦环境光照变化、物体位置偏移或出现未见过的干扰物,简单的卷积神经网络(CNN)策略往往会失效。
语义理解缺失:传统 BC 策略无法理解“把红色的积木放在绿色的盘子里”这类涉及属性推理和多步规划的语言指令。
数据效率低下:每个新任务通常需要重新收集数百条演示数据并从头训练。
2.2 VLA 范式的崛起与早期尝试
VLA 模型的出现是为了解决上述问题。其核心思想是“借力”——利用在大规模互联网数据上预训练的视觉语言模型(VLM)所蕴含的丰富世界知识和常识推理能力,将其迁移到机器人控制中。
RT-1 (Robotics Transformer 1):Google DeepMind 的早期尝试,将图像和语言指令作为输入,输出离散化的动作 Token。它证明了 Transformer 架构在机器人控制中的有效性,但其视觉骨干网络较弱,缺乏深度的语义推理能力。
RT-2 (Robotics Transformer 2):直接微调 PaLI-X 或 PaLM-E 等大型 VLM。RT-2 将动作编码为文本 Token(如 "1 128 55" 代表特定动作向量),从而实现了“连贯思维链”(Chain of Thought)推理与动作生成的统一。然而,RT-2 是闭源模型,且其离散化动作生成在高频控制(如 50Hz)下存在延迟和精度问题。
OpenVLA:基于 Llama 2 和 SigLIP 构建的开源 VLA。它推动了社区的发展,但在处理复杂、长时程任务和高精度操作时,受限于 Llama 语言模型的自回归生成速度和精度。
2.3 LingBot-VLA 的“务实主义”突破
Robbyant 将 LingBot-VLA 定义为“务实(Pragmatic)”的基础模型。这种“务实”体现在它并不盲目追求参数规模(如 70B 或 100B),而是聚焦于解决阻碍 VLA 实际部署的三个核心痛点:
动作的连续性与平滑性:放弃粗糙的 Token 离散化,采用生成式模型(Flow Matching)输出高精度连续轨迹。
感知的鲁棒性:通过 LingBot-Depth 解决真实世界中普遍存在的透明/反光物体感知难题。
训练与推理的效率:在保证性能的前提下,将模型控制在 4B 参数量级,并优化训练工具链,使其具备在边缘端部署和大规模低成本迭代的潜力。
3. 模型架构深度解析:理解与行动的解耦与融合
LingBot-VLA 的架构设计体现了“混合专家”(Mixture of Experts, MoE)的设计哲学,但并非传统意义上的 MoE 层,而是功能模块上的专家分工。它由两个核心部分组成:“理解专家”(Understanding Expert)和“动作专家”(Action Expert),两者通过特定的融合机制协同工作。
3.1 理解专家:Qwen2.5-VL 的视觉语义基座
LingBot-VLA 选择了 Qwen2.5-VL 作为其感知道路和语义推理的基座。这一选择在当前 VLA 领域具有独特的技术优势。
3.1.1 动态分辨率与细粒度感知
相比于 Llama 或传统的 ViT 基座,Qwen2.5-VL 的核心优势在于其 Naivety-Aware Vision Encoding(朴素感知视觉编码)和对动态分辨率的支持。
技术细节:传统的 VLA 模型(如 OpenVLA)通常将输入图像强制缩放为
 或
或  的固定分辨率。在机器人操作场景中,关键物体(如螺丝、电线接口)往往只占据视野的极小部分。强制缩放会导致这些关键细节丢失,造成操作失败。Qwen2.5-VL 支持可变长宽比和高分辨率输入,能够保留图像的原始细节。
的固定分辨率。在机器人操作场景中,关键物体(如螺丝、电线接口)往往只占据视野的极小部分。强制缩放会导致这些关键细节丢失,造成操作失败。Qwen2.5-VL 支持可变长宽比和高分辨率输入,能够保留图像的原始细节。OCR 与空间推理:Qwen2.5-VL 在光学字符识别(OCR)和空间几何理解上表现优异。这意味着 LingBot-VLA 能够理解诸如“按下写着‘启动’的按钮”或“抓取左边数第二个瓶子”这样依赖细粒度视觉特征的指令,这是许多基于 CLIP 的模型所不具备的。
3.1.2 4B 参数量的黄金平衡点
LingBot-VLA 采用了约 40 亿参数(4B)的配置。这实际上是基于 Qwen2.5-VL-3B 模型构建的(3B 语言基座 + 视觉编码器 + 动作头)。
推理延迟:7B 或 13B 的模型在边缘设备(如 Jetson Orin 或工控机)上很难实现 10Hz 以上的推理速度,这对于实时闭环控制是致命的。4B 模型在经过量化(Int8/Int4)后,可以轻松部署在端侧,满足 10-20Hz 的控制频率需求,体现了“务实”的设计理念。
3.2 动作专家:Flow Matching(流匹配)生成策略
LingBot-VLA 最具创新性的架构决策之一是摒弃了主流的自回归离散 Token 预测(如 RT-2 使用的 Token Binning),转而采用 Flow Matching 技术进行连续动作生成。
3.2.1 离散化 vs. 连续生成
离散化方法的弊端:将连续的关节角度或末端位姿(
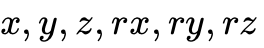 )离散化为 256 个区间(Bins),不仅引入了量化误差,还破坏了动作空间的拓扑结构。例如,Bin 127 和 Bin 128 在语义 Token 空间中可能毫无关联,但在物理空间中却是相邻的。此外,自回归生成(预测 后预测 )会导致推理延迟随动作维度线性增加。
)离散化为 256 个区间(Bins),不仅引入了量化误差,还破坏了动作空间的拓扑结构。例如,Bin 127 和 Bin 128 在语义 Token 空间中可能毫无关联,但在物理空间中却是相邻的。此外,自回归生成(预测 后预测 )会导致推理延迟随动作维度线性增加。Flow Matching 的优势:Flow Matching 是一种基于连续归一化流(Continuous Normalizing Flow, CNF)的生成模型,与扩散模型(Diffusion Models)有深刻的数学联系,但训练更高效,推理路径更直直。
数学原理:Flow Matching 学习一个向量场
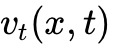 ,该向量场定义了如何将简单的先验分布(如高斯噪声
,该向量场定义了如何将简单的先验分布(如高斯噪声 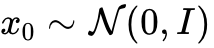 )随时间 $t \in $ 平滑地推演(Flow)到目标动作分布 。
)随时间 $t \in $ 平滑地推演(Flow)到目标动作分布 。轨迹生成:LingBot-VLA 的动作专家不是预测单一时间步的动作 ,而是预测未来的一个动作块(Action Chunk),例如
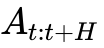 ( 为预测视界,通常为 16-64 步)。这种“分块预测”保证了动作的时序连贯性,消除了机器人运动中的“抖动”现象,使其动作更像人类般流畅。
( 为预测视界,通常为 16-64 步)。这种“分块预测”保证了动作的时序连贯性,消除了机器人运动中的“抖动”现象,使其动作更像人类般流畅。
3.2.2 融合机制
视觉语言基座(VLM)与动作专家(Action Expert)通过共享注意力机制(Shared Self-Attention)或跨注意力(Cross-Attention)进行融合。
信息流:多视角的图像()和语言指令()首先通过 Qwen2.5-VL 编码为深层语义特征
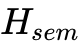 。这些特征作为条件(Conditioning),注入到 Action Expert 的网络中。
。这些特征作为条件(Conditioning),注入到 Action Expert 的网络中。本体感知注入:机器人的当前本体状态(Proprioception,如关节角度)直接输入到 Action Expert 中,与 VLM 的语义特征结合。这种设计确保了 VLM 负责“高层规划”(要去哪里),Action Expert 负责“底层控制”(怎么动关节),两者各司其职又紧密耦合。
4. 数据壁垒的突破:20,000 小时的规模化定律验证
在深度学习时代,架构往往决定了上限,而数据决定了实际性能。LingBot-VLA 最核心的科学贡献在于其构建并验证了目前已知最大规模的真实世界机器人数据集之一。
4.1 数据集的构成与多样性
LingBot-VLA 的训练数据包含了约 20,000 小时 的真实世界操作数据。为了理解这一数字的量级,对比 RT-1 的数据集(约 130,000 条轨迹,折合约数千小时),LingBot 的数据规模提升了一个数量级。更重要的是数据的多样性:
4.1.1 跨机型(Cross-Embodiment)数据
数据集涵盖了 9 种不同的双臂机器人配置。具体机型包括:
AgiBot G1 (智元 G1):人型机器人,具有高自由度的双臂和拟人化构型。
AgileX (松灵):配合机械臂的移动底盘复合机器人。
Galaxea R1Pro (银河通用):另一款高性能泛用型机器人。
Bimanual Franka:经典的科研用双臂 Franka Emika Panda 平台。
以及其他来自 Leju(乐聚)、Kupasi(库帕斯)、Boden Intelligence(博登智能)等合作伙伴的机器人。
战略意义:传统的机器人学习往往过拟合于特定机型的运动学参数(臂长、关节限位)。LingBot-VLA 通过学习 9 种机型的数据,迫使模型学习“动作意图”而非机械记忆。例如,学习“倒水”这一动作的抽象表征,无论是由 Franka 还是 AgiBot 执行,其核心轨迹特征是相似的。这使得模型具备了零样本或少样本迁移到第 10 种新机型的能力。
4.1.2 人类视频与混合训练
除了机器人自身的数据,LingBot-VLA 还整合了人类操作视频数据。
数据来源:利用 VR 设备(如 PICO 4 Ultra)或穿戴式摄像头(如 GoPro)采集的第一人称(Egocentric)人类手部操作数据。
领域适应:人类手部与机械夹爪存在巨大的形态差异(Domain Gap)。Robbyant 可能采用了跨形态映射技术,或者让模型直接从视频中学习“物体状态的变化”(Object-Centric Learning),从而指导机器人的动作生成。这种数据极其丰富且易于获取,是突破“数据墙”的关键补充。
4.2 规模化定律(Scaling Laws)的实证
在 NLP 领域,Kaplan 等人提出的 Scaling Laws 指导了 LLM 的发展。在机器人领域,这一规律是否适用一直存疑。LingBot-VLA 的报告提供了首个大规模实证。
实验设计:研究团队分别使用 3,000、5,000、10,000 和 20,000 小时的数据训练模型,并在同一测试集上评估。
结论:随着数据量的增加,模型在下游任务上的成功率呈现持续上升趋势,并未出现性能饱和(Saturation)。
启示:这意味着 VLA 模型的性能目前仍受限于数据量,而非模型架构。如果我们能收集 10 万或 100 万小时的数据,机器人的智能水平将继续大幅提升。这一结论为行业加大在数据采集基础设施上的投入提供了理论依据。
4.3 合成数据:RoboTwin 2.0
为了弥补真实数据的某些长尾场景缺失,Robbyant 利用了 RoboTwin 2.0 仿真平台生成合成数据。
数字孪生:在仿真引擎(如 Isaac Sim 或 MuJoCo)中构建与真实环境 1:1 对应的数字孪生场景。
域随机化(Domain Randomization):在仿真中随机改变光照、纹理、桌面高度、物体物理属性。这种“强干扰”训练提高了模型对真实世界环境变化的鲁棒性(Sim-to-Real Transfer)。实验表明,引入合成数据后,模型在以零样本迁移到新任务时获得了 228% 的性能提升。
5. 感知进阶:LingBot-Depth 与透明物体难题
真实世界与仿真环境最大的区别之一在于传感器的噪声和物理缺陷。传统的 RGB-D 相机(如 RealSense、Orbbec)通过主动红外结构光或 ToF 测距。这些技术在面对 透明物体(玻璃杯)、高反光物体(金属勺)或 黑色吸光物体 时会完全失效,输出全是空洞(NaN)的深度图。这被称为“吸血鬼问题”(物体在传感器中不可见)。
5.1 掩码深度建模(Masked Depth Modeling, MDM)
为了解决这一顽疾,Robbyant 开发并开源了 LingBot-Depth 模型。
核心思想:将深度图中的传感器失效区域(空洞)视为“掩码”(Mask),利用类似 BERT 或 MAE 的自监督学习机制,训练模型利用 RGB 图像的纹理信息和未失效区域的深度信息,去“脑补”出失效区域的深度。
训练数据:使用了 200 万张真实世界 RGB-D 图像和 100 万张仿真图像。仿真图像提供了完美的深度真值(Ground Truth),教会模型“完美的深度图应该长什么样”;真实图像提供了传感器噪声的分布模式。
性能提升:在 NYUv2 等基准测试中,LingBot-Depth 将深度误差降低了 70%。更重要的是,它使得 LingBot-VLA 在抓取透明玻璃杯等任务上的成功率从接近 0% 提升到了 50-85%。
6. 性能评估:GM-100 基准与竞品对比
为了客观评估 LingBot-VLA 的能力,Robbyant 建立了一个极其严格的评估基准:GM-100 (Great March 100)。
6.1 GM-100 基准概览
GM-100 包含 100 个精心设计的操作任务,旨在覆盖机器人操作的长尾分布。
任务类型:
刚体操作:积木堆叠、工具使用、物体分类。
柔性体操作:折叠毛巾、整理线缆(这是传统机器人的噩梦)。
铰接体操作:拉开抽屉、开关门、操作微波炉。
精细操作:插拔 USB、盖笔帽。
评估协议:共计 22,500 次真实机器人测试试验(Trials)。这种规模的实机测试在学术界是前所未有的,确保了结果的统计显著性。
6.2 实验结果对比
在 GM-100 基准上,LingBot-VLA 与当前最先进的(SOTA)模型进行了对比,包括 Physical Intelligence 的 π0.5 (Pi-Zero)、NVIDIA 的 GR00T N1.6 以及开源基线 WALL-OSS。
模型 (Model) | 成功率 (无深度增强) | 成功率 (含深度增强) | 进度得分 (Progress Score) |
LingBot-VLA | 15.74% | 17.30% | 35.41% |
π0.5 (Pi-Zero) | 13.02% | N/A | 27.65% |
GR00T N1.6 | 7.59% | N/A | 15.99% |
WALL-OSS | 4.05% | N/A | 10.35% |
深度数据解读:
绝对领先优势:LingBot-VLA 的成功率(17.30%)相比于最强竞品 π0.5(13.02%)高出了约 33%(相对提升)。相比于开源社区常用的 WALL-OSS,性能提升了 4 倍。
基准的难度:17.30% 的绝对数值看似不高,这反映了 GM-100 的极高难度。这些任务大多是在非结构化环境中进行的,且包含大量未见过的物体。在如此苛刻的“开放世界”设定下,任何超过 10% 的成功率都代表了具备一定的通用泛化能力,而非单纯的过拟合。
深度信息的作用:引入 LingBot-Depth 后,成功率从 15.74% 提升至 17.30%。这 1.56% 的提升主要来自于那些涉及透明、反光物体的任务,证明了全栈感知优化的必要性。
6.3 仿真基准 (RoboTwin 2.0)
在仿真环境中,LingBot-VLA 展现了更强的统治力:
清洁场景:88.56% 成功率。
随机化场景:86.68% 成功率。这表明模型不仅学会了任务逻辑,而且对环境干扰(光照、背景杂乱)具有极强的免疫力。
7. 工程优化与工具链:让大模型跑得动、训得快
训练一个 4B 参数、处理多模态视频流的模型,对计算基础设施提出了巨大挑战。Robbyant 开源的工具链包含了一系列系统级优化。
7.1 分布式训练策略 (FSDP)
LingBot-VLA 采用了 Fully Sharded Data Parallel (FSDP) 技术。
原理:FSDP 不仅将数据分片(Data Parallel),还将模型参数、梯度和优化器状态(Optimizer States)切分到所有 GPU 上。对于 4B 模型,这意味着每个 GPU 只需要存储一小部分参数,极大降低了显存占用。
优势:这使得在消费级或工作站级显卡(如 8x RTX 4090 或 A100)上进行全量参数微调成为可能,而不需要昂贵的 H100 集群。
7.2 数据加载与算子加速
吞吐量:在 8-GPU 设置下,训练吞吐量达到了 261 样本/秒。这一速度是现有开源 VLA 框架的 1.5 至 2.8 倍。
优化细节:
I/O 优化:针对视频数据的解码瓶颈,工具链可能集成了 GPU 硬件解码(NVDEC)或高效的预取策略,防止 GPU 因等待数据而空转。
FlashAttention:集成了 FlashAttention-2 算子,显著加快了 Transformer 层的计算速度,降低了长序列(多帧图像 + 长指令)带来的显存开销。
7.3 后训练与微调 (Post-Training)
针对开发者最为关心的“如何适配我的机器人”问题,Robbyant 提供了完善的后训练工具。
LoRA (Low-Rank Adaptation):支持 LoRA 微调。开发者只需收集少量(如 50-100 条)新任务演示数据,冻结模型主体,仅训练低秩适配层(占总参数量 < 1%)。这不仅训练速度快,还能防止“灾难性遗忘”(Catastrophic Forgetting),即微调后模型丧失了原本的通用能力。
量化支持:为了适应端侧部署,工具链支持将模型量化为 Int8 或 Int4 精度。结合 Qwen2.5-VL 的高效架构,这意味着 LingBot-VLA 可以部署在算力受限的移动机器人机载电脑上。
8. 开源协议与生态影响
LingBot-VLA、LingBot-Depth 以及相关代码库均在 Apache 2.0 许可下发布。
8.1 Apache 2.0 的战略意义
Apache 2.0 是最宽松的开源协议之一,它允许商业使用、修改和分发,且无需开源衍生代码(不同于 GPL)。
商业化门槛降低:初创公司和硬件厂商可以直接将 LingBot-VLA 集成到自己的商业机器人产品中,而无需支付授权费或担心法律风险。这将极大地加速 VLA 技术在服务机器人、工业自动化等领域的落地。
生态卡位:通过开源高性能基座,Ant Group 意在建立具身智能的“Android 时刻”。如果大多数开发者都基于 LingBot 开发应用,Ant Group 将掌握核心标准和生态话语权,为其硬件产品(Robbyant R1)和云服务铺路。
8.2 对抗与合作
在中美科技竞争的背景下,LingBot-VLA 的发布证明了中国企业在具身智能领域已具备与 Google、Tesla 等美国巨头正面抗衡的实力。特别是在数据规模和实机测试验证上,LingBot 甚至走在了部分西方同行的前面。这种良性竞争将迫使全球研究社区加速开放,从而推动整个行业的进步。
9. 结论与展望
LingBot-VLA 不仅仅是一个模型,它是一套完整的、经过验证的具身智能解决方案。
对于研究者:它证明了 Scaling Laws 在机器人领域的有效性,指明了“堆数据”是一条通往通用机器人的可行路径。
对于开发者:它提供了一个免费、高性能、可商用的“大脑”,大大降低了开发复杂机器人应用的门槛。
对于行业:它展示了混合专家架构(VLM + Flow Matching)与大规模真实数据结合的巨大潜力,预示着机器人将从“预编程自动化”时代正式迈入“基于学习的通用智能”时代。
随着社区对 LingBot-VLA 的深度挖掘和二次开发,我们有理由相信,2026年将成为具身智能爆发的元年。LingBot-VLA 所验证的这条“数据驱动 + 多模态融合”的技术路线,将成为未来几年机器人学习无可争议的主流方向。