


如需报告请联系客服或扫码获取更多报告
1. 云端算力:迎接国产算力产业链上下游共振带动业绩放量
算力产业链自主化进程加速,看好国产算力业绩释放。中芯国际过去几年稳健推进先进制程扩产,市场开拓进度良好。整体来看,国产先进制程扩产稳步推进叠加产业链自主可控进展加速,将显著增强国内算力产业的供给保障能力。在 AI 推理和训练需求持续提升的背景下,国产算力厂商有望充分受益,业绩释放可期。
与此同时算力产业链迎来新的产业趋势,“运力”成为国产算力“赶超”海外龙头的关键一环。行业正在把互联方式从机柜之间的 Scale-Out 网络转向机柜内部的 Scale Up 网络(NVLink、UALink、PCIe 等),利用更短的传输距离实现更高带宽和更低延迟,从而提升整体吞吐。25 年下半年是国产超节点方案陆续进入公众视野的阶段,无论是互联网厂商、交换机厂商、GPU 自研厂商,各家均有亮眼产品陆续发布。我们看好接下来国产方案百花齐放,一方面,以华为、曙光为代表的全栈自研路径已有重磅方案发布,另一方面,看好第三方 Switch 芯片厂商绑定互联网大厂客户做进终端方案。随着国产算力逐渐进入放量期,国产超节点产业链有望迎来更高确定性的增长机遇。
2. 端侧算力:端云混合为 AI 场景赋能,端侧 SoC 持续受益于 AI创新浪潮
2026 年,端侧 AI 将正式接力云 AI,推动端云混合架构场景成为技术基建核心范式,其到来具备技术演进、硬件支撑与场景需求的三重必然性。纯云端架构的带宽成本、时延瓶颈、隐私安全问题日益凸显,而大模型的全局决策能力与端侧轻量化模型的实时处理能力形成天然互补,通过“云端训、端侧用、边侧补”的协同模式,破解算力分配与隐私安全矛盾。端侧芯片通过 NPU 加速等技术让终端可流畅运行轻量化大模型,2026年智能汽车、AI 眼镜、机器人等终端将成为率先爆发的核心载体,为架构落地筑牢基础。具体来看,智能汽车的自动驾驶需求侧实时感知与云端长时序决策协同,AI 眼镜实现人机全场景交互,机器人依赖端侧快速响应与云端全局调度。政策加持与产业生态完善进一步加速这一进程,端云混合架构不仅是技术升级的必然结果,更是 AI 从实验室走向规模化商用的关键支撑。

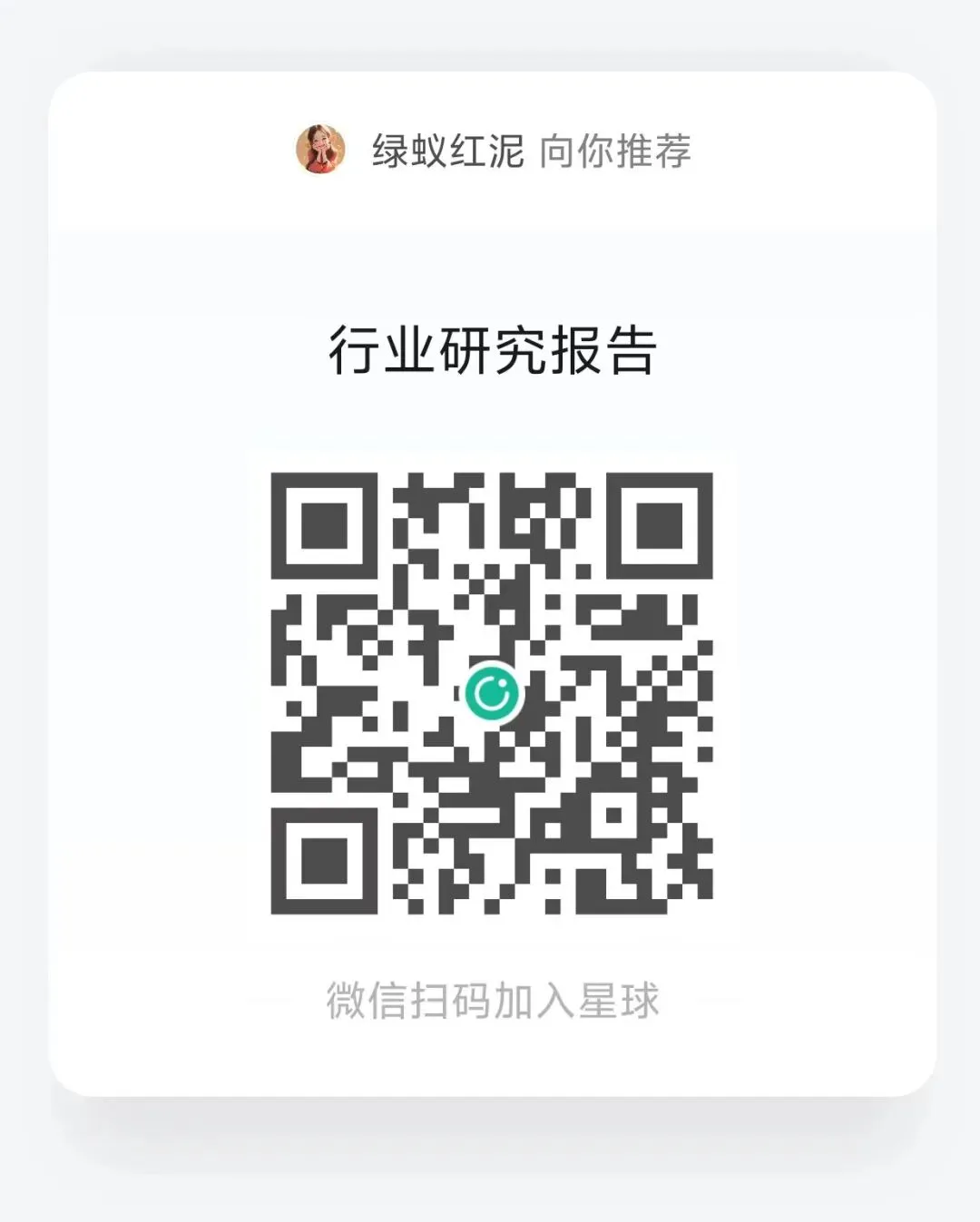
3. 3D DRAM:端侧 AI 存储 26 年为放量元年,产业趋势逐渐确立
25 年 3D DRAM 相关产品已发布,研发路径走通,步入商业化进展。瑞芯微在25 年 7 月的开发者大会发布两款用于端侧 AI 的 NPU:(1)RK1820:内置 2.5GB DDR,支持 3B 模型;(2)RK1828:内置 5GB DDR,支持 7B 模型,均采用 3D DRAM 架构。借助 3D DRAM 高带宽、低成本、可拓展的特性,主控芯片能支持语音识别、视频分析、长上下文对话等场景应用,适用于安防、机器人、车载、消费电子、办公、教育、家居、工业等端侧场景。
4. 端侧 AI 模型:架构优化突破物理瓶颈,利益分配决定生态版图
豆包手机助手落地后暴露的核心瓶颈在于系统级调用触及 App 话语权边界及 AI 行为风控问题;同时存在执行偏慢等体验问题。此后终端厂、模型厂与互联网平台均加速迭代相关产品。展望 2026 年,从技术架构看:
➢ 云端模型抬升复杂规划能力上限:在数据质量持续优化及后续训练体系不断成熟的驱动下,进一步抬升复杂规划与多步骤推理能力上限;
➢ 端侧模型将智能压缩落地:通过蒸馏承接云端模型能力,并以量化、注意力复杂度降维、MTP 等结构优化手段,叠加技能模块化与片上记忆系统的工程化设计,持续改善端侧执行成功率与交互时延等核心体验指标;
➢ Agent 技术路线:API 优先、GUI 兜底。其中 API 路径在合规性、稳定性及执行成功率方面具备显著优势,其渗透节奏取决于利益分配机制的可行性与成熟度;而 GUI 路径作为通用技术手段,将长期承担长尾应用与复杂异构环境的适配职能。
5. AI 终端:26 年 AI 终端创新元年开启。Meta、苹果、谷歌、OpenAI 均有新终端新品推出
2026 年 AI 终端创新元年开启。从 2026 年到 2028 年之间,海外头部大厂 Meta、苹果、谷歌、OpenAI 均有新终端新品推出。AI 终端形态以眼镜为代表,智能眼镜作为距离人的五官最近的可穿戴设备,仍然被认为是较理想的硬件终端形态,每家大厂均有眼镜形态产品处于开发过程中。而在眼镜的形态之外,我们同时看到 AI pin、摄像头耳机、桌面机器人等新形态的硬件也在布局之中。伴随模型迭代和新终端的应用场景开发加速,下一代爆款终端或在大厂创新周期中应运而生。新终端的产生离不开关键零组件的升级。
6. 长鑫链条:长鑫扩产确定性全面提升,DRAM 产业链进入新一轮景气上行通道
长鑫上市显著增强扩产确定性,存储进入新一轮中长期扩产周期。随着长鑫存储登陆资本市场进程持续推进,公司有望通过 IPO 募资及后续再融资工具显著增强资本实力,为其在 DRAM 领域的长期技术迭代与产能扩张提供坚实的资金保障。在当前国产存储加速替代、产业链自主可控战略持续强化的宏观背景下,具备稳定融资能力与持续资本开支投入能力的头部厂商将成为产业升级的核心载体。我们判断,长鑫在资本约束明显缓解后,未来数年资本开支强度有望维持高位运行,产线建设节奏与扩产量级均具备较强确定性,扩产周期具备较长持续性与较高能见度。
7. 晶圆代工:先进逻辑扩产量级有望翻倍,晶圆代工景气维持
供需紧约束叠加保供诉求,国内先进逻辑即将开启新一轮中长期扩产周期。在全球半导体供应链重构与国产替代进程加速的背景下,国内先进逻辑制程供给长期处于紧平衡状态,尤其在 7nm 及以下先进制程节点,国内产能缺口尤为突出。受制于海外供应链不确定性加剧,以及美日等国对先进制造设备及技术出口限制的潜在扰动,国内头部系统厂商与芯片设计公司对本土先进代工产能的依赖程度持续提升,对供应安全的重视程度显著上升。我们判断,自 2026 年起,基于“保供优先”的战略考量,国内先进逻辑产能将进入一轮规模可观、持续性较强的扩产周期,晶圆代工行业整体景气度有望维持在高位区间。
8. PCB:Rubin 开启 AI PCB 高端材料新时代,M9 与 Q 布掀起PCB 价值跃升潮
英伟达的机柜架构升级显著推动了 PCB 的量价齐升,ASIC 同步跟进,推动 PCB市场规模 26 年迈向 600 亿元。在当前的 GB200/300 NVL72 机柜中,计算板(Biancaboard)采用 22 层 HDI,交换板为 26 层通孔板,PCB 材料已使用了高性能的 M8 等级。迈入下一代 Rubin 系列机柜后,PCB 设计和规格发生了重大飞跃:首先,Rubin NVL144机柜新增了 Midplane,CPX-CX9 网卡模组,而计算板与交换板也做了重大升级,极大地提升了单个 PCB 的价值量。另外,Rubin Ultra NVL576 (Kyber) 机柜引入了革命性的正交背板方案,替代了铜缆连接并大幅提升芯片密度。由于数据传输速率要求超过224Gbps,PCB 材料必须升级到 M9 或 PTFE 等更高等级的极低损耗材料,同时层数和工艺要求也极高。Kyber 机柜所需的 4 块正交背板,结合更高规格的计算板,将使单机柜的 PCB 总价值量实现成倍增长。ASIC 方面,谷歌 TPU、亚马逊 Trainium、Meta MTIA系列芯片持续迭代,V7 Ironwood,V8 Zebrafish/Sunfish,Trainium3 等新产品持续推动PCB 板向更高性能材料,更高阶层结构升级,进一步打开 AI PCB 市场规模。
9. 光铜互联:Scale up&out 迭代持续,光铜双线共振
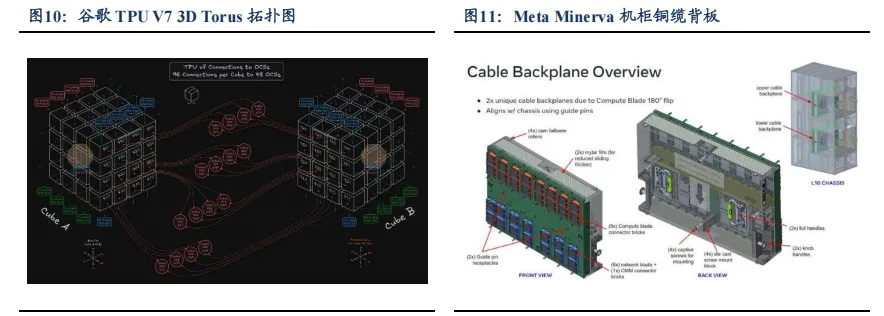
AI 算力集群 Scale up&out 迭代升级持续推进,短距高密度互联依赖铜缆筑牢基础,大规模高密度 AI 集群推升光模块需求,看好光铜双线共振。一方面,AI 算力集群持续提升的芯片:光模块比例推动光模块需求持续提升。以英伟达 Rubin NVL 144 满配CPX 为例,我们测算 3 层网络下其芯片:光模块比例可达到 1:12,Meta DSF 架构下,18432 颗 MTIA 集群需 18.432 万颗 800G 光模块。另一方面,铜缆依旧是 AI 算力中心短距低延时互联的核心选择,谷歌 TPU V7 采用 3D Torus 拓扑,单机柜 64 颗芯片通过80 根铜缆实现柜内互联,铜缆端口占比超六成,亚马逊 Trainium3 通过 AEC 铜缆完成背板及跨机架连接,整机柜需 216 根 64 端口 PCIe AEC 铜缆,支撑 144 颗芯片的 Scale up 带宽需求。
10. 服务器电源:数据中心功率密度飙升,HVDC 供电架构成核心主线
随着 AI 大模型训练与推理规模持续扩大,数据中心正从“计算密集型”快速演进为“电力密集型”基础设施,机柜功率密度成为制约算力扩展的核心变量。当前 AI 机柜功率已由传统通用服务器时代的 10–20kW 快速跃升至 100kW 以上,并在英伟达等头部厂商的路线图中进一步指向 300–600kW 区间。在这一功率水平下,传统以“AC 配电+ UPS+多级 AC/DC、DC/DC 转换”为核心的供电体系,在能效损耗、铜缆体积、系统复杂度及长期可靠性等方面已接近工程极限,逐步成为制约 AI 数据中心规模化部署与成本优化的关键瓶颈。