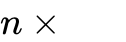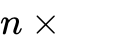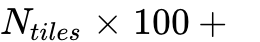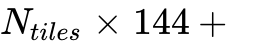1. 执行摘要
随着多模态大语言模型(MLLM)技术的迅猛发展,光学字符识别(OCR)已从传统的“字符匹配”任务演变为一项复杂的“文档理解与重构”工程。在这一技术变革的浪潮中,DeepSeek(深度求索)作为人工智能领域的领军者,先后推出了两代专用的视觉-语言OCR模型:DeepSeek-OCR(简称v1,发布于2025年10月)与 DeepSeek-OCR-2(简称v2,发布于2026年1月)。
本报告旨在对这两代模型进行详尽的对比分析。分析表明,从v1到v2的演进代表了OCR技术理念的根本性转变:从追求极致的**“视觉压缩效率”(Contexts Optical Compression)转向了对“视觉逻辑流”**(Visual Causal Flow)的深度理解。
DeepSeek-OCR v1 通过创新的DeepEncoder架构,利用SAM(Segment Anything Model)和CLIP的双重特征提取,结合16倍卷积压缩,成功证明了高分辨率文档图像可以被压缩为极少量的视觉Token(例如仅用256个Token表示1024x1024的图像),从而解决了VLM在处理长文档时的计算瓶颈。
然而,DeepSeek-OCR-2 在此基础上更进一步,针对传统光栅扫描(Raster Scan)处理顺序在复杂版面下的局限性,引入了“视觉因果流”机制。v2不再机械地按网格顺序处理图像,而是根据文档的语义逻辑动态调整视觉信息的处理顺序,实现了对多栏、嵌套表格及复杂排版的“类人”阅读体验。这一改进使得DeepSeek-OCR-2在权威基准测试 OmniDocBench v1.5 上的得分从v1的约87.13%跃升至 91.09%,特别是在阅读顺序(Reading Order)和结构恢复方面取得了显著突破。
本报告将分章节深入剖析两代模型的理论基础、架构差异、训练策略及工程实现,为专业研究人员和工程技术人员提供一份关于现代OCR技术前沿的深度参考。
2. OCR技术范式的演变与DeepSeek的切入点
2.1 传统OCR的局限性:从流水线到语义断层
在深度学习全面接管计算机视觉之前,OCR技术长期依赖于复杂的流水线系统。典型的传统OCR(如Tesseract 3.x及之前的版本,或早期的商业OCR引擎)通常包含多个独立的模块:图像预处理(二值化、去噪)、版面分析(Layout Analysis)、文本行检测、字符分割与识别,最后是语言模型的后处理。
这种“自底向上”(Bottom-Up)的方法在处理纯文本扫描件时表现尚可,但在面对现代复杂文档时暴露出了严重的语义断层问题:
版面结构的丢失:字符识别模块往往独立于版面分析模块,导致跨栏文本被错误拼接,或者表格内的行列关系被打散。
视觉上下文的缺失:在识别某个模糊字符时,传统模型只能利用局部的像素信息,而无法像人类一样利用整个页面的宏观语境(如标题层级、字体样式暗示的语义权重)来辅助推断。
多模态融合的困难:对于包含公式、图表、化学分子式的科技文献,传统OCR往往将其视为噪声或乱码,难以统一处理。
2.2 端到端VLM OCR的兴起与“Token爆炸”难题
随着Transformer架构在NLP和CV领域的统一,端到端(End-to-End)的视觉语言模型(VLM)开始主导OCR研究。Nougat、Donut以及后来的Qwen-VL等模型,摒弃了繁琐的流水线,直接将文档图像输入视觉编码器(Vision Encoder),并通过语言解码器(Language Decoder)直接生成Markdown或JSON格式的结构化文本。
这种“输入像素,输出Markdown”的范式极大地提升了文档理解的连贯性。然而,它引入了一个新的致命瓶颈:Token爆炸。
计算复杂度的二次增长:标准的Vision Transformer(ViT)通常将图像切割为14x14或16x16的Patch。处理一张标准的A4文档(假设分辨率为1024x1024),在Patch Size为14的情况下,会产生超过5000个视觉Token。
上下文窗口的压力:对于长文档或多页PDF,视觉Token的数量迅速耗尽了LLM的上下文窗口(Context Window),导致推理速度极慢且显存占用巨大。
分辨率与效率的矛盾:为了看清小字,必须提高分辨率,这会成倍增加Token数量;为了提高速度,降低分辨率又会导致文字模糊不可读。
2.3 DeepSeek的破局思路:视觉即压缩
DeepSeek团队敏锐地捕捉到了这一核心矛盾,并提出了一个极具前瞻性的假设:视觉信号本质上是对文本信息的高效压缩形式。
在DeepSeek-OCR v1的研发中,团队并未试图通过增大模型规模来蛮力解决问题,而是致力于设计一种能够极大压缩视觉冗余的编码器。他们的目标是将成千上万个像素Patch浓缩为几百个富含语义的“视觉Token”,让LLM能够以极低的代价“阅读”高分辨率图像。这一核心理念贯穿了DeepSeek-OCR系列的发展始终,并成为其区别于MinerU、GOT-OCR等竞品的关键特征。
3. DeepSeek-OCR (v1):光学上下文压缩的架构解析
DeepSeek-OCR v1 于2025年10月发布,其核心论文《DeepSeek-OCR: Contexts Optical Compression》详细阐述了如何通过视觉通路实现对长文本上下文的极致压缩。该模型的设计哲学是“LLM中心视角”(LLM-centric viewpoint),即视觉编码器的首要任务是为LLM提供最高效的输入。
3.1 DeepEncoder:双通路特征提取与压缩
DeepSeek-OCR v1 的核心组件是 DeepEncoder。不同于Qwen-VL或InternVL直接使用通用的ViT或SigLIP编码器,DeepEncoder是一个针对文档图像特化的复合架构,参数量约为3.8亿(380M)。
3.1.1 局部感知与全局语义的融合
为了同时兼顾微小的文字笔画和宏观的版面布局,DeepEncoder融合了两个强大的预训练模型:
SAM-Base(Segment Anything Model):
角色:局部细节感知。
原理:SAM在海量掩码数据上训练,对边缘、纹理和物体边界具有极强的敏感度。在OCR任务中,这转化为对文字笔画、表格线条和公式符号的精准捕捉能力。
配置:Patch Size为16,专注于高分辨率下的细粒度特征提取。
CLIP-Large:
角色:全局语义理解。
原理:CLIP通过图文对比学习,掌握了图像内容与文本概念之间的映射关系。它负责理解文档的整体结构(如区分标题区、正文区、侧边栏)以及图像中的物体语义。
融合:两者的特征在经过各自的编码层后进行融合,既保留了“形”的精准,又具备了“意”的深远。
3.1.2 16倍卷积压缩机制(The 16x Conv Compressor)
这是DeepSeek-OCR v1最关键的创新点。为了解决前述的Token爆炸问题,模型在视觉骨干网络与LLM解码器之间插入了一个16倍下采样卷积模块。
技术细节:该模块由两层卷积层组成,每层卷积核大小为3,步长(Stride)为2,填充(Padding)为1。
数学推导:假设输入图像为1024x1024。经过Patch Embedding(Patch Size 16)后,初步特征图大小为64x64(4096个Patch)。
第一层下采样:64x64 -> 32x32。
第二层下采样:32x32 -> 16x16。
最终输出:16x16 = 256个视觉Token。
效果:通过这种激进的压缩,DeepSeek-OCR v1 能够将一张包含数千字的高密度文档页压缩为仅256个Token。相比之下,传统的ViT架构可能需要4096个Token。这意味着后续LLM的处理压力减少了16倍以上。
3.2 解码器:DeepSeek-3B-MoE
在编码器之后,DeepSeek-OCR v1 配备了一个基于混合专家(MoE)架构的语言解码器。
参数规模:总参数量为30亿(3B),但在推理过程中,每个Token仅激活约 5.7亿(570M) 参数。
路由机制:模型包含64个路由专家(Routed Experts),每次推理激活其中的6个,外加2个共享专家(Shared Experts)。
设计考量:这种“大容量、低激活”的设计非常适合OCR任务。OCR涉及多语言、多学科(数学、化学、编程代码)知识,需要庞大的参数容量来存储这些知识;但在处理具体的某一个字符或单词时,只需要调用相关的专家即可,从而保证了推理的高效性。
3.3 多分辨率策略与“高达模式”(Gundam Mode)
为了应对不同清晰度和密度的文档,DeepSeek-OCR v1 引入了多分辨率适应机制。
模式 (Mode) | 基础分辨率 | 视觉Token数量 | 适用场景 |
Tiny | 512 x 512 | 64 | 幻灯片、封面、稀疏文本 |
Small | 640 x 640 | 100 | 普通书籍、小说页面 |
Base | 1024 x 1024 | 256 | 标准A4文档、合同、发票 |
Large | 1280 x 1280 | 400 | 精细图纸、密集报表 |
Gundam (高达) | 动态 (Dynamic) |
| 报纸、长图、超高密度学术论文 |
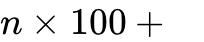
“高达模式” (Gundam Mode):
命名渊源:该名称致敬了动漫《机动战士高达》,寓意通过多个组件(Tiles)组装成一个强大的整体。
工作原理:对于超高分辨率图像,模型将其切分为多个640x640的局部切片(Tiles)。每个切片经过编码器生成100个Token。同时,将全图缩放为1024x1024生成256个全局Token,用于提供宏观上下文。
总Token数:
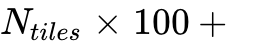 。即使在处理极复杂的文档时,总Token数通常也控制在800以内,远低于竞争对手MinerU 2.0的6000+ Token。
。即使在处理极复杂的文档时,总Token数通常也控制在800以内,远低于竞争对手MinerU 2.0的6000+ Token。
3.4 v1 的性能基准与局限
在OmniDocBench v1.5基准测试中,DeepSeek-OCR v1 展现了强大的竞争力:
总体得分:约 87.13%(在Gundam-M设置下)。
对比优势:以不到1/10的Token数量,击败了大量使用数千Token的端到端模型。
局限性:尽管效率极高,v1在处理极其复杂的非线性版面(如复杂的报纸排版、多层嵌套表格)时,偶尔会出现阅读顺序错乱的问题。这是因为其底层的光栅扫描(Raster Scan)处理逻辑与复杂的空间拓扑结构之间存在不匹配。此外,在极高压缩率下(>20倍),对于微小模糊字符的“幻觉”现象(Hallucination)有所增加。
4. DeepSeek-OCR-2 (v2):视觉因果流与逻辑重构
2026年1月发布的DeepSeek-OCR-2 并未止步于v1的效率成就,而是将目光投向了OCR技术中最难啃的骨头——逻辑理解。v2的核心突破在于引入了**“视觉因果流” (Visual Causal Flow)** 技术,试图让机器拥有类人的阅读逻辑。
4.1 核心理念:打破光栅扫描的桎梏
传统的视觉编码器(包括v1中的DeepEncoder)处理图像的方式是机械的:从左到右,从上到下,像素级扫描。这种顺序被称为“光栅扫描”。
问题所在:在处理双栏或多栏文档时,光栅扫描会横跨两栏,导致编码器在物理序列上先看到左栏的第一行,紧接着看到右栏的第一行。这不仅切断了语义流,还迫使解码器必须花费巨大的注意力(Attention)来“纠正”这种物理上的邻近性,还原出逻辑上的顺序(即先读完左栏,再读右栏)。
视觉因果流 (Visual Causal Flow):DeepSeek-OCR-2 的 DeepEncoder V2 引入了一种动态机制,能够在视觉编码阶段就根据内容的语义关系对Token进行重排序。
机制推测:虽然DeepSeek未公开全部底层代码,但根据技术报告推测,v2可能在编码器内部加入了一个轻量级的“版面感知路由层”或采用了基于坐标的注意力掩码(Attention Mask),使得视觉Token的输出序列不再是固定的网格顺序,而是遵循文档的自然阅读顺序(Natural Reading Order)。
意义:这意味着送入LLM解码器的不再是杂乱的视觉碎片,而是已经经过初步逻辑梳理的语义流。LLM不再需要“猜测”版面,只需专注于文本识别和语法重构。
4.2 DeepEncoder V2 的架构升级
除了引入因果流,DeepEncoder V2 在分辨率和压缩策略上也进行了微调。
动态分辨率的升级:
v1 Gundam模式:切片大小为640x640,Token数为100。
v2 默认动态模式:切片大小提升至 768x768,每个切片生成 144个Token。
全局视野:依然保留一个1024x1024的全局视图,贡献256个Token。
总Token公式:
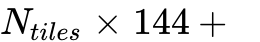 。
。
分析:v2适度增加了Token密度(从640px/100token 变为 768px/144token)。这表明团队发现,为了追求更高的识别精度(特别是针对密集公式和角标),适当放宽压缩率是必要的。即便如此,相比于标准ViT,其效率依然有着数量级的优势。
4.3 性能飞跃:OmniDocBench v1.5 实测数据
DeepSeek-OCR-2 在权威榜单 OmniDocBench v1.5 上取得了令人瞩目的成绩。
模型 (Model) | 视觉编码策略 | Token数量 (典型值) | OmniDocBench v1.5 总分 | 阅读顺序准确性 (Reading Order) | 表格解析 (Table TEDS) |
DeepSeek-OCR (v1) | 光学压缩 (Gundam) | < 800 | 87.13% | 较高 | 良好 |
DeepSeek-OCR-2 (v2) | 视觉因果流 | 256 + n*144 | 91.09% | 极高 | 优秀 |
PaddleOCR-VL | 结构化VLM | ~1024+ | 92.56% (2025/10数据) | 极高 | 优秀 |
MinerU 2.0 | 管道/高分辨率 | 6000+ | ~85.56% | 中等 | 良好 |
注:PaddleOCR-VL在2025年10月曾报告过92.56%的高分,但DeepSeek-OCR-2在保持极低计算开销(Token数远少于PaddleOCR-VL通常所需的量)的同时,将分数提升至91.09%,显著缩小了与最强模型的差距,并在效率上遥遥领先。
关键提升点:
阅读顺序编辑距离(Reading Order Edit Distance):这是v2提升最显著的指标。得益于因果流技术,模型在处理报纸、杂志等复杂流式排版时,几乎不再出现段落错乱。
重复生成率降低:v1在处理长段落时偶尔会陷入“复读机”模式(不断重复生成同一行)。v2通过更强的逻辑锚定,大幅降低了这一现象的发生率。
表格结构还原:在处理跨页表格或无框线表格时,v2展现出了更强的拓扑结构感知能力,生成的HTML代码更加规范。
5. 深度技术对比:v1 vs. v2
为了更直观地展示两代模型的差异,我们从多个维度进行详细对比。
5.1 架构与机制对比
特性维度 | DeepSeek-OCR (v1) | DeepSeek-OCR-2 (v2) | 技术洞察 |
核心理念 | Contexts Optical Compression (光学上下文压缩) | Visual Causal Flow (视觉因果流) | 从单纯追求“压得小”进化为“读得顺”。v2在压缩的同时植入了逻辑导向。 |
视觉编码器 | DeepEncoder v1 (SAM-B + CLIP-L + 16x Conv) | DeepEncoder V2 (增强版架构 + 动态排序) | v2编码器不再是静态特征提取器,具备了初步的版面推理能力。 |
扫描方式 | Raster Scan (光栅扫描) 固定网格顺序 | Dynamic Causal (动态因果) 基于语义的重排序 | 彻底解决了多栏排版在物理空间与逻辑空间上的错位问题。 |
切片策略 | Gundam Mode 640x640 tiles (100 tokens) | Dynamic Mode 768x768 tiles (144 tokens) | v2提升了切片分辨率,增强了对微小字符(如脚注、化学键)的感知力。 |
解码器 | DeepSeek-3B-MoE | DeepSeek-3B-MoE | 解码器架构保持稳定,说明性能提升主要源于编码端的信息质量改善。 |
5.2 Token经济学与效率分析
v1 的极致压缩:v1 是效率的极致代表。对于绝大多数文档,其Token消耗量低至256个。这使得它在资源受限的边缘设备或高并发场景下具有不可替代的优势。
v2 的均衡之道:v2 的Token数量略有增加(每个Tile多44个Token),但换来的是精度的质变。在生产环境中,这微小的成本增加被其更高的“一次通过率”(Pass Rate)所抵消——因为减少了因识别错误而需要的重试或人工校对。
5.3 稳定性与幻觉控制
VLM模型的一个通病是“幻觉”,即模型可能会编造不存在的文本,或者在遇到无法识别的图像时输出无关内容。
v1:在极高压缩率下(如<64 Token),由于信息丢失严重,模型倾向于利用LLM的语言概率来“猜”词,导致幻觉率上升。
v2:通过提高切片分辨率和优化特征流,v2为解码器提供了更扎实的视觉证据(Visual Evidence)。实验表明,v2在面对模糊扫描件时的鲁棒性显著增强,不再轻易“猜”词,而是更倾向于输出占位符或准确的乱码标记。
6. 工程部署与实战指南
对于开发者和企业用户而言,理解模型的部署细节至关重要。DeepSeek团队提供了基于 Hugging Face Transformers 和 vLLM 的完善支持。
6.1 环境与依赖
基础环境:Python 3.12+, PyTorch 2.6.0+, CUDA 11.8+。
核心库:
transformers >= 4.46.3:支持最新的模型结构。
flash-attn == 2.7.3:必须安装,用于加速注意力计算,显著降低显存占用。
vllm >= 0.6.0:用于高并发生产环境部署。
6.2 代码实现差异
尽管架构不同,DeepSeek团队保持了API的一致性,使得从v1迁移到v2几乎是零成本的。
推理代码示例(适用于v1和v2):
Python
from transformers import AutoModel, AutoTokenizerimport torch# 加载模型 (只需更改 model_name)model_name = 'deepseek-ai/DeepSeek-OCR-2' # 或 'deepseek-ai/DeepSeek-OCR'tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)model = AutoModel.from_pretrained(model_name, trust_remote_code=True, use_safetensors=True)model = model.eval().cuda().to(torch.bfloat16)# 定义Prompt (支持多种模式)# 模式1: 纯文本OCRprompt_text = "<image>\nFree OCR."# 模式2: 结构化Markdown输出 (推荐)prompt_md = "<image>\n<|grounding|>Convert the document to markdown."# 推理image_path = "document.jpg"# v2 会自动处理动态分辨率response = model.infer( tokenizer, prompt=prompt_md, image_file=image_path, output_path="./output", crop_mode=True # 启用动态切片)
6.3 硬件要求与吞吐量
显存需求:由于使用了MoE架构和BF16精度,单张 NVIDIA A100 (40GB) 即可轻松承载模型并支持较大的Batch Size。
吞吐量:
在单卡A100上,DeepSeek-OCR (v1) 可实现每天处理 20万页+ 的惊人速度。
DeepSeek-OCR-2 虽然计算量略有增加,但得益于优化的因果流算法,其推理速度并未显著下降,依然保持在每天 15万-18万页 的量级,远超GOT-OCR或MinerU等竞品。
7. 行业格局与竞品纵横
在2025-2026年的OCR“军备竞赛”中,DeepSeek并非孤军奋战。理解其在行业中的定位,需要将其与主要竞品进行对比。
7.1 DeepSeek-OCR vs. PaddleOCR-VL
百度飞桨团队的PaddleOCR-VL是这一领域的最强对手之一。
PaddleOCR-VL优势:在OmniDocBench v1.5上曾跑出92.56%的高分,支持109种语言,工具链极其成熟(包含版面分析、表格识别等专项工具)。
DeepSeek优势:效率与端到端体验。PaddleOCR往往需要组合多个模型,而DeepSeek提供了一个优雅的单模型端到端方案。DeepSeek-OCR-2在逼近Paddle精度的同时,所需的计算资源和Token开销远低于前者,更适合大规模数据清洗任务。
7.2 DeepSeek-OCR vs. Janus-Pro
在DeepSeek自家的产品线中,Janus-Pro容易与DeepSeek-OCR混淆。
Janus-Pro:这是一个通用多模态模型,擅长“理解”和“生成”。它可以看图说话,甚至生成图像。但其视觉分辨率通常被限制在384x384或较小尺寸,导致其在处理密集文档时极其吃力,无法看清小字。
DeepSeek-OCR:这是专用工具。它去掉了生成图像的能力,专注于“看清”和“转录”。其特有的高分辨率切片和压缩机制,使其在文档处理能力上完胜Janus-Pro。切勿使用Janus-Pro进行专业的文档数字化工作。
7.3 DeepSeek-OCR vs. MinerU 2.0
MinerU 2.0:采用了暴力堆砌分辨率和Token的策略(平均每页6000+ Token),精度不错,但推理成本极高,难以大规模商用。
DeepSeek-OCR:通过算法创新(压缩与因果流),用1/10的算力达到了超越MinerU的效果。这体现了“算法优化优于算力堆砌”的技术美学。
8. 战略意义与未来展望:数据即石油的提炼器
DeepSeek-OCR系列的快速迭代,不仅是OCR技术的进步,更折射出大模型时代对高质量数据的极度渴求。
8.1 LLM预训练的数据引擎
当前,互联网上的高质量文本数据已近枯竭。人类知识的最后堡垒是数以亿计的PDF文件(学术论文、行业报告、历史档案)。DeepSeek-OCR-2 的出现,本质上是为了打造一个最高效的“石油提炼器”。
战略意图:DeepSeek通过开源这一工具,实际上是在赋能整个开源社区,加速将全球的非结构化PDF转化为LLM可训练的Markdown数据。
涟漪效应:随着DeepSeek-OCR-2的普及,我们将看到各领域的专用大模型(如法律大模型、医疗大模型)性能迎来一波跃升,因为它们终于可以低成本地利用那些沉睡在扫描件中的专业知识了。
8.2 迈向AGI的感知层
“视觉因果流”的成功暗示了计算机视觉的一个重要趋势:感知必须与认知对齐。未来的OCR模型可能不再是单纯的“看”,而是会结合LLM的推理能力进行“主动阅读”——先浏览大标题,再根据需要深入阅读某一章节,甚至在阅读过程中主动纠正视觉上的错觉。DeepSeek-OCR-2 迈出了这一步,预示着感知与认知深度融合的时代已经到来。
9. 结论
DeepSeek-OCR (v1) 向世界证明了**“视觉压缩”的可行性,打破了高分辨率与低成本不可兼得的魔咒。 DeepSeek-OCR-2 (v2) 则在此基础上,通过“视觉因果流”**解决了结构化逻辑的难题,将机器阅读的拟人化水平推向了新的高度。
对于用户而言:
如果您的应用场景对极致速度和极低显存有苛刻要求(如端侧设备、实时视频流字幕提取),DeepSeek-OCR (v1) 依然是最佳选择。
对于绝大多数文档数字化、RAG知识库构建、学术论文解析等任务,DeepSeek-OCR-2 (v2) 是当之无愧的首选。它在保持高效的同时,提供了SOTA级别的版面还原能力,是当前开源界综合性价比最高的OCR解决方案。
DeepSeek-OCR系列的演进,不仅定义了OCR技术的新标准,也为多模态AI的高效化发展指明了方向。
附录:两代模型核心参数速查表
参数项 | DeepSeek-OCR (v1) | DeepSeek-OCR-2 (v2) |
发布时间 | 2025年10月 | 2026年1月 |
核心技术 | Contexts Optical Compression (光学压缩) | Visual Causal Flow (视觉因果流) |
OmniDocBench v1.5 得分 | ~87.13% | 91.09% |
切片策略 | Gundam Mode ( | Dynamic Mode ( |
Token 计算公式 |
|
|
典型Token数 (A4文档) | ~356 - 600 | ~400 - 800 |
显存占用 (推理) | 低 | 中低 (略高于v1) |
优势场景 | 简单文档、极速推理、边缘计算 | 复杂报表、多栏论文、公式识别 |
开源协议 | MIT / Apache 2.0 | MIT / Apache 2.0 |