


1. 摘要 (Executive Summary)
随着以ChatGPT为代表的生成式人工智能(GenAI)和大语言模型(LLM)的爆发式增长,数据中心算力基础设施正经历着前所未有的物理极限挑战。作为AI算力的核心引擎,GPU的单芯片热设计功耗(TDP)已从NVIDIA A100时代的400W飙升至H100的700W,乃至Blackwell B200架构的1000W以上 。这种指数级的功耗增长,不仅对散热系统提出了严苛要求,更将供电网络(Power Delivery
Network, PDN)逼到了物理学的边缘。

在传统的服务器供电架构中,多相电压调节模组(Multiphase VRM)长期面临着“瞬态响应速度”与“系统效率”之间的零和博弈。为了满足AI芯片极高的电流跳变速率(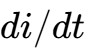 > 1000A/s)并维持亚毫伏级的电压稳定性,传统方案不得不堆砌大量的输出电容(MLCC/POSCAP),这在寸土寸金的GPU载板上已不再可行。
> 1000A/s)并维持亚毫伏级的电压稳定性,传统方案不得不堆砌大量的输出电容(MLCC/POSCAP),这在寸土寸金的GPU载板上已不再可行。
跨电感电压调节器(Trans-Inductor Voltage Regulator, TLVR) 技术应运而生,成为打破这一僵局的关键“破局者”。本报告深入剖析发现,TLVR通过引入次级串联绕组,创造性地实现了多相电感之间的“电耦合”,使得在负载瞬变发生的纳秒级时间内,所有相能同时响应,将等效瞬态电感降低至物理极限,从而在不牺牲稳态效率的前提下,实现了超高带宽的瞬态响应 。
本调研显示,TLVR已成为NVIDIA H100及未来B200世代服务器的标准供电配置,直接取代了部分传统的耦合电感和Vicor的专有架构 。对于磁性元件产业链而言,这不仅仅是一次技术迭代,更是一场价值重估。单台AI服务器(如HGX H100)中TLVR电感的用量激增至120颗以上,单机价值量(ASP)较传统服务器提升5倍以上 。
然而,机遇伴随着挑战。TLVR引入的次级高频环路对PCB布局、EMI控制以及磁芯材料(铁氧体回归)提出了全新的工程难题。本报告将从第一性原理出发,全链路拆解TLVR的技术壁垒、市场空间、竞争格局及落地挑战,为投资者、硬件架构师及产业链从业者提供一份详尽的决策参考。
2. 技术深钻:第一性原理分析 (Technical Deep Dive: First Principles Analysis)
要理解TLVR的革命性意义,首先必须从物理学角度剖析传统VRM在面对AI负载时遭遇的根本性瓶颈。
2.1 痛点溯源:传统多相VRM的物理墙
现代高性能GPU(如NVIDIA H100)的核心电压(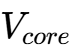 )通常在0.7V至0.9V之间,而电流需求(
)通常在0.7V至0.9V之间,而电流需求(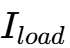 )可瞬间突破1000A。当GPU从待机状态切换到满负荷矩阵运算时,电流需求会在极短时间内(<100ns)发生剧烈变化。根据法拉第电磁感应定律,电感上的电压决定了电流的变化率:
)可瞬间突破1000A。当GPU从待机状态切换到满负荷矩阵运算时,电流需求会在极短时间内(<100ns)发生剧烈变化。根据法拉第电磁感应定律,电感上的电压决定了电流的变化率:
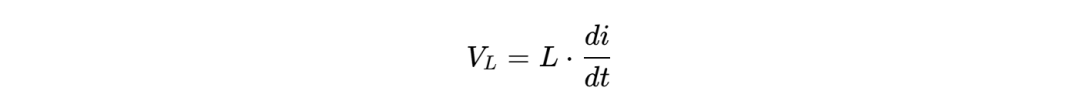
在降压转换器(Buck Converter)中,电流的上升斜率受限于输入电压与输出电压之差以及电感值:
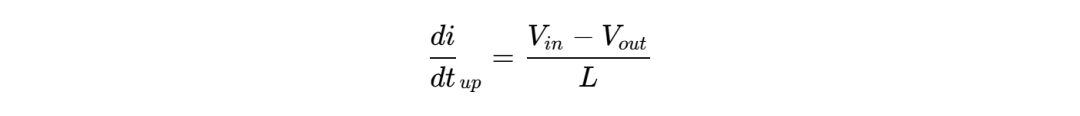
这里存在一个无法调和的Trade-off(权衡):
为了更快的瞬态响应(High
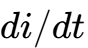 ):必须减小电感值()。这就好比为了让车加速更快,必须减轻飞轮的惯性。
):必须减小电感值()。这就好比为了让车加速更快,必须减轻飞轮的惯性。为了更高的效率(High Efficiency):必须增大电感值(),以减小电流纹波(Ripple Current)。过大的纹波会产生显著的导通损耗(
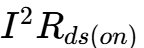 )和磁芯损耗,还会导致输出电压纹波过大。
)和磁芯损耗,还会导致输出电压纹波过大。
在AI时代之前,业界通过增加相位数量(Multiphase)和堆叠输出电容来缓解这一矛盾。然而,面对AI芯片对PCB面积的极致压缩和对电压波动(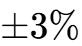 )的零容忍,物理瓶颈显现:电容没地方放了,且由于电感不能无限做小(否则效率崩塌),VRM的带宽被锁死在几十kHz量级,远低于GPU所需的MHz级响应需求 。
)的零容忍,物理瓶颈显现:电容没地方放了,且由于电感不能无限做小(否则效率崩塌),VRM的带宽被锁死在几十kHz量级,远低于GPU所需的MHz级响应需求 。
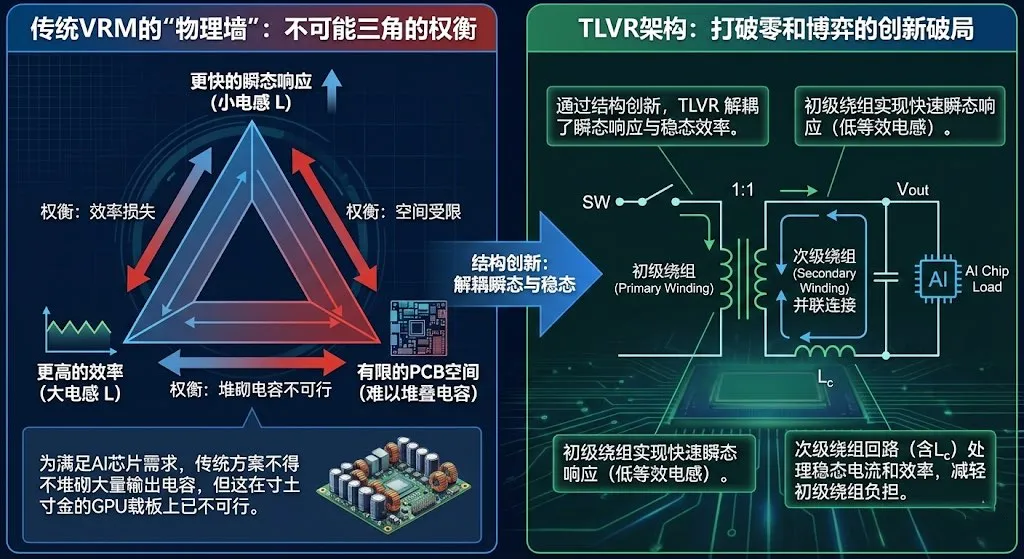
2.2 TLVR解决方案:打破“不可能三角”
TLVR(Trans-Inductor Voltage Regulator)通过拓扑结构的创新,彻底解耦了“瞬态响应”与“稳态纹波”之间的强关联。其核心在于引入了一个次级串联环路,实现了“牵一发而动全身”的电流控制机制。
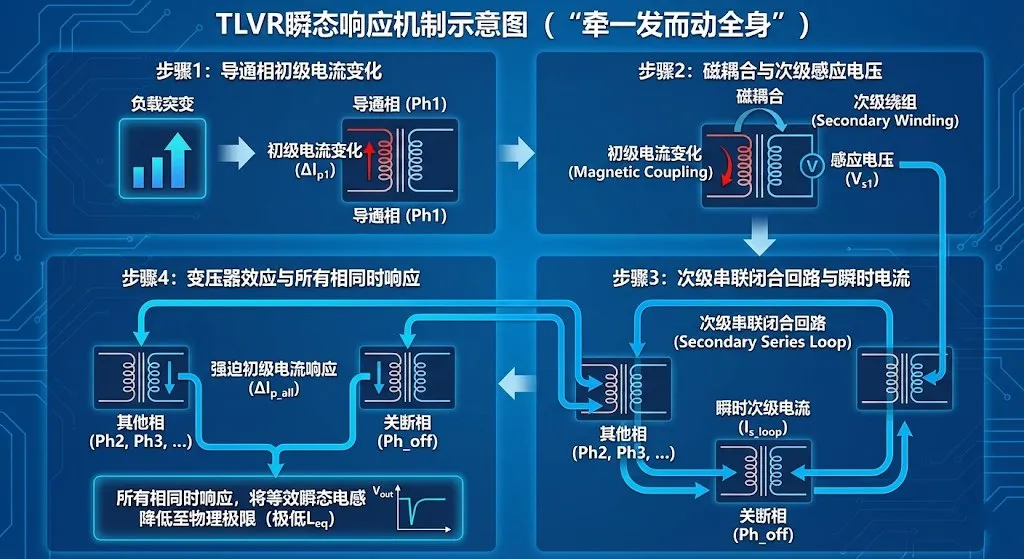
2.2.1 结构原理
不同于传统电感只有一组线圈,TLVR电感本质上是一个1:1的变压器:
初级绕组(Primary Winding):像传统Buck电感一样连接在开关节点(Switch Node)和输出端(
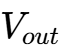 )之间。
)之间。次级绕组(Secondary Winding):所有相的次级绕组首尾相连,串联成一个闭合回路。
补偿电感(Tuning Inductor):在次级回路中串联一个额外的调谐电感,用于调节回路阻抗。
2.2.2 瞬态工作机制(The Mechanics of "Action at a Distance")
当负载突变(例如GPU突然拉电流),控制器的某一相(或几相)率先响应,增加占空比。
传统VRM:只有导通的这一相电流开始爬升,其他相“无动于衷”,整体电流爬升速度慢。
TLVR架构:
导通相的初级电流变化,通过磁耦合在次级绕组感应出电压。
由于次级是串联闭合回路,这个感应电压瞬间在整个次级回路中产生电流 。
这个次级电流流经所有其他相的次级绕组。
通过变压器效应,次级电流反过来强迫所有相的初级电流同时发生变化。
结果:所有相(即使是处于关断状态的相)都被“强制”参与到瞬态响应中。从负载端看,所有相的电感仿佛在瞬间并联了起来。等效瞬态电感(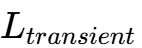 )急剧下降至接近漏感(Leakage Inductance)的水平,从而实现了极高的电流压摆率(Slew Rate) 。
)急剧下降至接近漏感(Leakage Inductance)的水平,从而实现了极高的电流压摆率(Slew Rate) 。
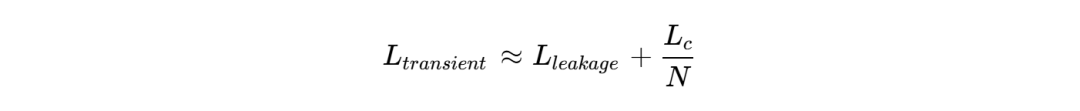
其中 N为相数。相数越多,瞬态电感越小,响应越快。这完美契合了AI服务器动辄16相甚至24相供电的设计趋势。
2.3 关键参数对比:TLVR vs. 传统Molding Choke
TLVR电感在物理特性上与传统的一体成型电感(Molding Choke)存在显著差异,这些差异直接决定了其制造难度和成本。
关键参数 | 传统功率电感 (Standard Molding Choke) | TLVR电感 (Dual-Winding Inductor) | 技术深层解析 |
结构 (Structure) | 单绕组,磁粉一体成型 | 双绕组(初级+次级),分立磁芯组装 | TLVR必须保证初次级之间的高压隔离(通常>100VDC),以防次级环路浮地电压击穿 。 |
磁芯材料 (Core Material) | 金属合金粉末 (Metal Alloy Powder) | 铁氧体 (Ferrite) 或 高性能金属复合材料 | TLVR的次级环路会引入高频交流纹波。金属粉末虽然饱和电流高,但高频磁损(Core Loss)大;铁氧体磁损极低,更适合TLVR的高频特性,但存在硬饱和风险 。 |
耦合系数 (Coupling ) | N/A (无耦合) | 极高 ( | 必须紧密耦合以确保能量从初级高效传递到次级。传统耦合电感通常是负耦合( |
电感值定义 | 标称电感量 | 磁化电感 | TLVR的设计重点在于控制漏感 |
直流电阻 (DCR) | 极低 (< 0.3 mΩ) | 略高 | 由于需要在有限的窗口面积内绕制两个线圈,初级线圈的截面积可能受限,导致DCR略微增加,影响满载效率。 |
饱和电流 ( | 软饱和 (Soft Saturation) | 硬饱和 (Hard Saturation - 若用铁氧体) | 铁氧体一旦过流,感值会瞬间跌落,导致电流失控。因此TLVR设计必须留有严格的安全裕量 。 |
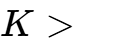
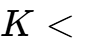
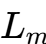
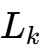
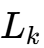
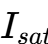
3. 市场驱动力与应用场景 (Market Drivers)
TLVR并非单纯的技术炫技,而是AI算力爆发背景下的“必选项”。
3.1 AI算力激增与48V-1V架构演进
NVIDIA H100和B200的出现,标志着数据中心彻底进入了“高压传输、低压大电流应用”的时代。
OCP Open Rack V3 (ORV3) 的推动:为了降低传输损耗(
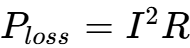 ),Google和Meta主导的OCP ORV3标准将机架母线电压从12V提升至48V。这意味着供电架构必须完成从48V到GPU核心电压(~1V)的转换 。
),Google和Meta主导的OCP ORV3标准将机架母线电压从12V提升至48V。这意味着供电架构必须完成从48V到GPU核心电压(~1V)的转换 。48V生态的竞争:在NVIDIA A100时代,Vicor凭借其专利的分比式电源架构(Factorized Power Architecture, FPA) 垄断了48V到1V的转换市场。然而,FPA是封闭生态,供应链风险高且成本昂贵。
TLVR的战略地位:在H100世代,NVIDIA和超大规模数据中心厂商(Hyperscalers)积极引入TLVR方案(如MPS和Infineon方案)作为Vicor的替代。TLVR允许使用标准的多相Buck控制器和MOSFET,不仅打破了单一供应商垄断,还显著降低了成本 。
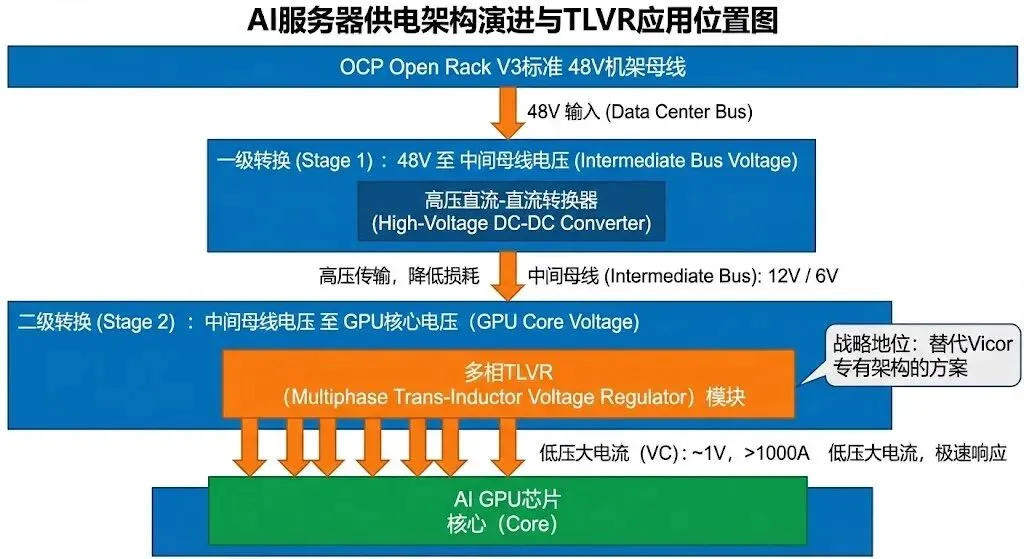
架构佐证:在NVIDIA HGX H100参考设计中,主流配置已转向采用两级转换:第一级将48V转换为中间母线电压(如12V或6V),第二级采用多相TLVR将中间电压转换为GPU核心电压 。
3.2 定量分析:单台AI服务器的TLVR价值量测算
让我们拆解一台典型的 AI服务器(如搭载8张H100 GPU的HGX平台),估算TLVR电感的市场机会。
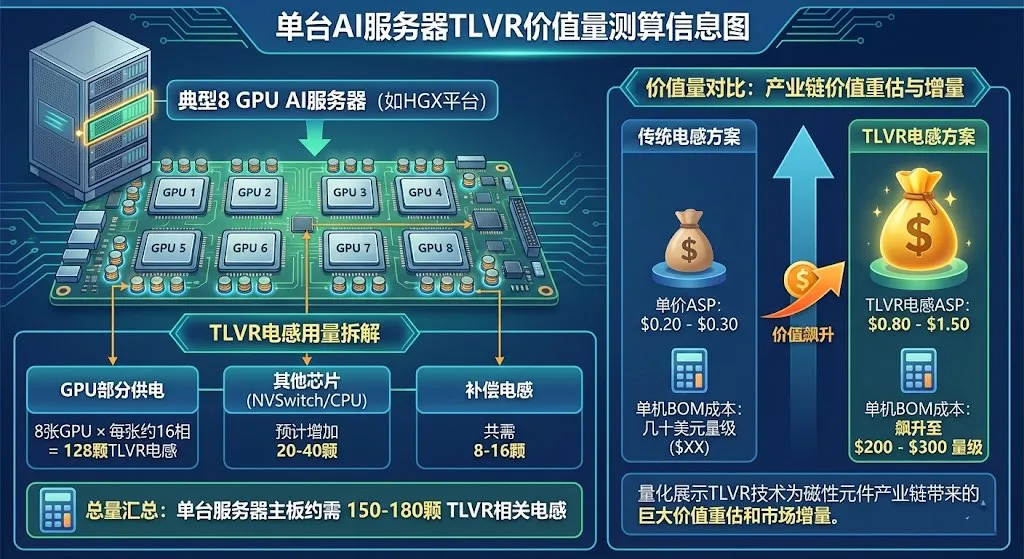
GPU功耗需求:单张H100 SXM5功耗700W,核心电压0.8V,意味着电流约为875A。
相位估算:考虑到DrMOS的热降额(通常单相承载50A-70A),单张GPU需要约 12至16相 供电。
计算:
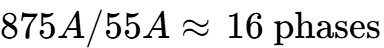 。
。
单板用量 (Usage per Board):
GPU部分:8张GPU 16相 = 128颗 TLVR电感。
NVSwitch/CPU部分:板上的4颗NVSwitch芯片及CPU也可能采用TLVR供电,预计增加20-40颗。
补偿电感 :每组GPU的VRM回路需要1颗补偿电感,共8-16颗。
总计:单台AI服务器主板上约需 150-180颗 TLVR相关电感 。
价值量提升 (Value Uplift):
传统服务器Molding Choke单价:约 $0.20 - $0.30。
TLVR电感单价:由于良率、双绕组工艺和专利因素,目前ASP约在 $0.80 - $1.50 之间 。
结论:单台AI服务器仅在电感上的BOM成本就从传统服务器的几十美元飙升至 $200 - $300 美元量级。考虑到未来每年数十万台的AI服务器出货量,这是一个数亿美元的新增细分市场。
4. 产业链与竞争格局 (Competitive Landscape)
TLVR电感的制造不仅仅是绕线,更是材料学与精密制造的竞争。
4.1 技术壁垒:为何TLVR难以制造?
材料学的两难(Ferrite vs. Metal):
TDK路线(铁氧体):TDK的VLBUC系列采用铁氧体磁芯。优势是高频损耗极低(TLVR次级环路纹波频率很高),且容易实现高压隔离(100V withstand)。难点在于铁氧体易碎且饱和特性极硬,需要极其精确的气隙(Air Gap)控制来防止大电流下饱和 。
其他厂商路线(金属粉末/复合材料):如Cyntec、Eaton部分产品。优势是软饱和特性好,机械强度高。劣势是高频损耗大,热管理极具挑战。目前趋势看,低损耗铁氧体在TLVR应用中正占据上风 。
结构复杂性:
TLVR需要引出4个引脚(初级2个+次级2个),且必须保持共面性(Coplanarity)以确保焊接可靠性。在6mm x 6mm或更小的尺寸内绕制两组高绝缘线圈,对自动化绕线设备提出了极高要求 。
漏感控制 (
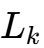 Tolerance):
Tolerance):
在传统电感中,漏感是杂散参数;在TLVR中,漏感是决定瞬态响应速度的关键参数。厂商必须将漏感的一致性控制在极窄范围内,这直接考验磁芯模具的精度 。
4.2 全球玩家版图 (Key Suppliers)
供应商 | 核心产品系列 | 技术路线与竞争优势 | 市场地位 |
Cyntec (乾坤) | TLM系列 | 模组化与集成。作为Delta(台达)的关联公司,Cyntec在Power Module集成方面极强,为ODM提供高密度的一体化解决方案 。 | Tier 1 (ODM市场主力) |
TDK | VLBUC系列 | 铁氧体专家。主打低损耗和高耐压(100V)。针对VR14/VR15服务器设计,强调其铁氧体材料在高频纹波下的热稳定性优势 。 | Tier 1 (NVIDIA参考设计常客) |
Pulse Electronics (Yageo) | PGL/PAL系列 | 大电流与自动化。提供高达125A的饱和电流产品。强调自动化制造带来的成本优势和一致性。拥有垂直安装和卧式安装多种形态 。 | Tier 1 (广泛用于超大规模数据中心) |
Eaton | TL/TLP系列 | 耦合电感鼻祖。利用其在耦合电感领域的长期专利积累,平滑过渡到TLVR。提供与传统电感兼容的封装(Footprint Compatible),便于客户设计切换 。 | Tier 1 (主要供应商之一) |
Coilcraft | SLV系列 | 高性能复合材料。以XGL/XAL材料技术闻名,在TLVR中主打定制化服务和极低的DCR 。 | Tier 1.5 (高性能细分市场) |
4.3 替代性技术风险:来自未来的威胁
虽然TLVR是当下的主流,但未来的技术演进仍存在变数:
垂直供电(Vertical Power Delivery, VPD):
威胁:随着电流突破1500A,PCB水平传输的损耗(
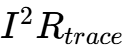 )变得不可接受。VPD将VRM直接放置在GPU芯片正下方,消除了“最后一英寸”的传输路径。
)变得不可接受。VPD将VRM直接放置在GPU芯片正下方,消除了“最后一英寸”的传输路径。与TLVR的关系:VPD是一种物理布局,它可以采用TLVR拓扑(如Infineon的TDM22545T模块支持VPD) ,但也可能采用Vicor的电流倍增技术。如果Vicor的VPD方案在下一代(Rubin)中卷土重来,TLVR的独立电感形态将受到模块化方案的挤压。
集成稳压器(Integrated Voltage Regulator, IVR):
威胁:将电感集成到芯片封装内部(如Intel FIVR)。这需要微型空芯电感或薄膜电感。
判断:目前IVR受限于散热和电流密度,尚无法支撑700W+的AI大芯片,但在CPU和低功耗ASIC领域是长期威胁 。未来3-5年内,TLVR在AI大功率场景仍是主流。
5. 推广与落地挑战 (Challenges)
TLVR虽然性能卓越,但其系统级应用的难度远高于传统VRM。
5.1 系统级挑战:PCB布局与控制器调教
次级环路的噩梦 (Layout Penalty):
TLVR需要在PCB上走一圈连接所有电感次级的“高频环路”。这个环路携带高频交流电流,极易成为EMI辐射源。如果布局不当(如环路面积过大),不仅辐射超标,还会引入寄生电感,削弱TLVR的瞬态性能 。
解决方案:需要多层PCB设计,将次级走线埋入内层并做严格的屏蔽处理,这增加了PCB成本和设计难度。
控制器支持 (Controller Ecology):
TLVR的传递函数与传统Buck不同,增加了极点和零点。普通的PID控制器可能无法稳定工作。
厂商动态:
Infineon:推出了XDPE19283B等数字控制器,专门针对TLVR优化了环路补偿算法 。
MPS:凭借MP2965/MP2971系列,利用其数字COT(Constant On-Time)控制技术,天然契合TLVR的快速响应特性,在H100方案中占据了重要份额 。
Renesas:通过RAA2系列支持AMD SVI3和Intel VR14/15标准,确保在通用服务器平台的兼容性 。
5.2 成本与良率瓶颈
成本结构:TLVR电感不仅仅是多了一个绕组,更涉及到磁芯材料的升级(高性能铁氧体)和复杂的组装工艺。目前TLVR电感的成本主要受限于良率和测试成本。由于必须测试初次级间的耦合系数和耐压,测试工时大幅增加。
良率挑战:在自动化生产中,保证初级和次级线圈在模具中的相对位置不发生微米级偏移是极其困难的。任何偏移都会导致漏感一致性变差,进而导致多相VRM中的均流(Current Sharing)失效,引发局部过热 。
6. 结论与SWOT分析
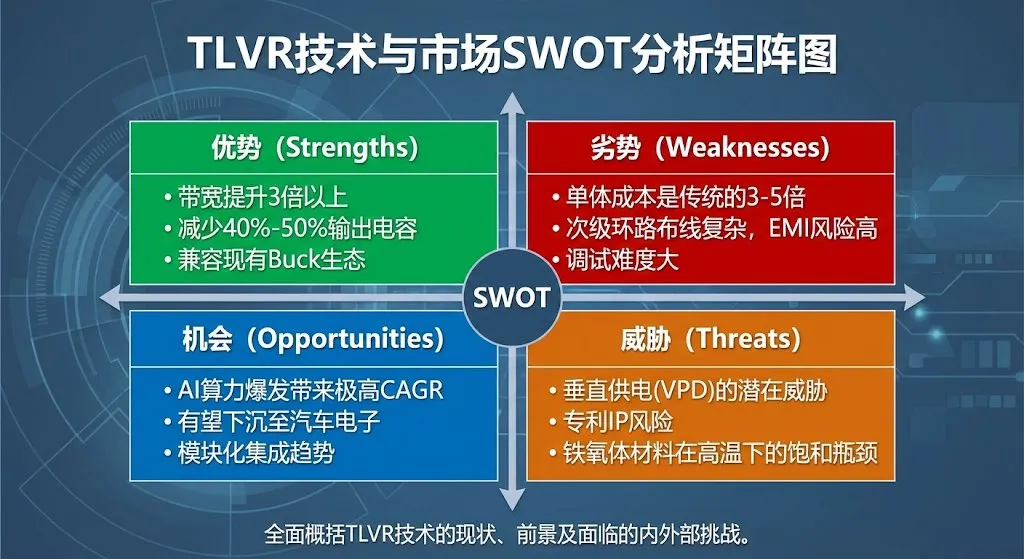
6.1 SWOT分析概览
优势 (Strengths) | 劣势 (Weaknesses) |
瞬态响应:物理层面上解耦了带宽与效率的矛盾,带宽提升3倍以上。 电容减免:可减少40%-50%的输出电容用量,节省宝贵的PCB板级空间。 开放生态:相比Vicor专有协议,TLVR兼容现有Buck生态,供应链安全。 | BOM成本:单体电感成本是传统的3-5倍。 设计复杂度:次级环路布线复杂,EMI风险高。 调试难度:需要专门的控制器算法配合,对电源工程师要求高。 |
机会 (Opportunities) | 威胁 (Threats) |
AI算力爆发:H100/B200及未来Rubin架构的刚需,市场年复合增长率(CAGR)极高。 汽车电子:随着自动驾驶算力提升(如NVIDIA Thor),TLVR有望下沉至车载计算平台。 模块化集成:将TLVR电感与DrMOS封装在一起(如Infineon TDM),减少PCB设计难度。 | 垂直供电 (VPD):如果电流密度进一步提升,VPD可能改变电感形态。 专利纠纷:部分早期耦合电感专利尚未过期,存在IP风险。 材料瓶颈:铁氧体在极高温下的饱和特性限制了功率密度的进一步提升。 |
6.2 总结与展望
TLVR电感并非仅仅是电子元件的微创新,它是摩尔定律在电力电子领域的救亡图存。在AI芯片电流突破1000A大关的当下,TLVR是唯一能在保持高效率的同时提供纳秒级能量响应的成熟技术方案。
对于产业链而言,未来的决胜点在于材料学的突破(开发更低损耗、更高饱和磁通密度的铁氧体)和集成化技术(将TLVR与Power Stage合封)。尽管面临VPD等新技术的潜在挑战,但在未来3-5年的AI服务器黄金周期内,TLVR电感将是确定性极高的增量市场,也是连接电网能量与AI算力智慧之间最关键的物理桥梁。

往期推荐