


已经不记得自己看过多少关于Prompt的文章或者视频了,总感觉明白了又不深入,有种很不踏实的感觉。直到昨天偶然发现谷歌官方出品的《Prompt Engineering》,看完后顿时感觉打通了任督二脉,直接出师!如果你有时间,一定要学习下原文,链接我放在评论区了。
如果你只想了解怎么写,不必知道其中的原理,可以看第4、5部分以及文末的往期精选;如果你想深入了解提示词工程,知其所以然,以便更好的灵活运用,那就从头开始吧~下面我们正式开始让人耳目一新的知识点分享:
1.为什么叫提示词“工程”?
2.写好的Prompt不是一劳永逸的!
提示的有效性受到诸多因素的影响:所使用的模型、模型的版本、模型的训练数据、模型配置、措辞选择、风格语调、结构以及上下文等等。你可能试过,同样的Prompt用不同的工具(如chatgpt、Gemini、Qwen、豆包)给出的结果都不同,这是因为工具背后运行的模型不同。所以针对不同模型要用不同的Prompt,这里的效果只能自己根据需求摸索,形成最适合自己的提示词库。另外,模型一升级,也会对你用的提示词的效果有所影响,所以就需要不断优化和调整。看到这里,大家是不是感觉没必要眼馋别人的提示词库了??
3.LLM可以配置输出参数
1)输出长度 (Output length)
这个大家估计都有一个模糊的感觉,就是让他返回多长的结果呗。
但是有一个新的知识点:通过配置限制Token数量(max_tokens)是一种强制截断,它本身并不能促使模型生成简洁的内容!看到这我傻眼了?...如果要实现简洁的回答,通常需要在提示本身中给出具体指令,比如“用一句话总结”。
2)采样控制 (Sampling controls)
这个有点点专业,偶尔有一些工具会把以下3个控制手段暴露出来,如果你只想了解怎么写Prompt,这部分可以跳过。下面介绍的三种手段可以单独用,也可以配合使用。
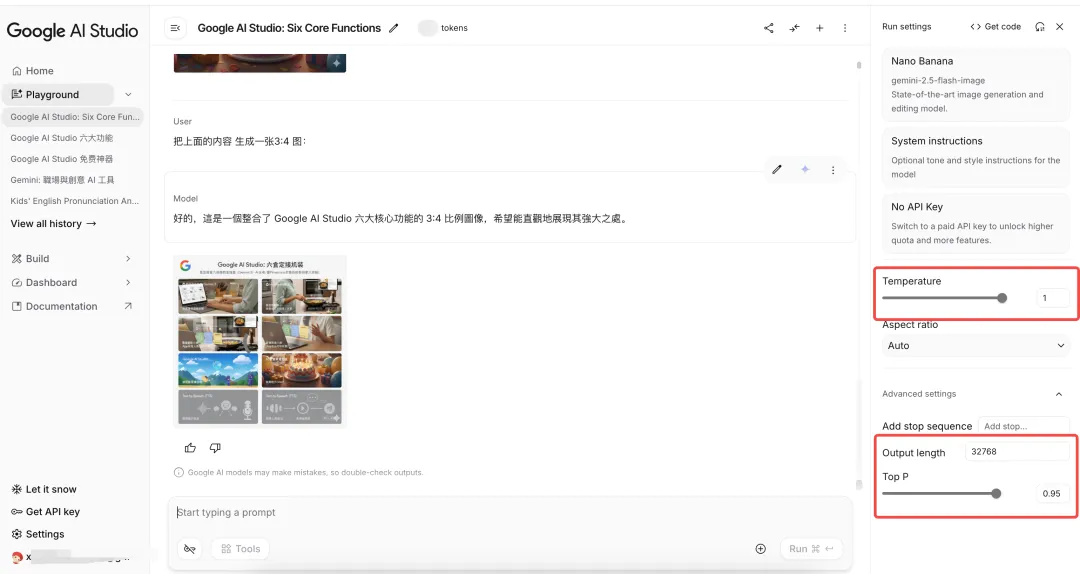
温度 (Temperature)
温度控制Token选择中的随机程度。可以为不同任务选择合适的温度:事实问答需要低温,而故事生成(创造性工作)需要高温。温度为0是确定性的,即始终选择概率最高的Token(如果两个Token具有相同的最高预测概率,根据平局处理方式的不同,温度为 0 时可能不总是得到相同的输出)。
Top-K
采样从模型预测的分布中选择概率最高的 K 个Token。Top-K值越高,模型的输出越具创造性和多样性;Top-K值越低,模型的输出越受限制和基于事实。Top-K为 1 等同于每次只取概率最高的那一个(贪婪解码)。
Top-P
采样选择累积概率不超过某个值(P)的最高概率Token。P的值范围从0(贪婪解码)到 1,Top-P 的作用是划定一个高质量的“合理候选词池”,而温度的作用是在这个词池内部增加或减少随机性,两者结合使用能更好地控制输出。在实际应用中,Top-P 的值通常设定在 0.9 到 1.0 之间。
在Google AI studio中这几个可以设置,大家可以体验下,这款工具也是有很多免费的强大功能,整理好后我单独写一篇。
4.写好提示词的小众技巧
原文档中介绍了常见的系统提示词、用户提示词、上下文提示词,zero-shot、one-shot、few-shot,思维链等各大博主提到的常见的手段,我这里就不再赘述了,只提一个信息,few-shot大概是3~5个例子,别太少了。我之前的这篇文章里有提及一些手段,如果需要可以瞅瞅:不懂技术的产品经理要被淘汰了!Prompt提示词怎么写?概念、秘籍、框架,一篇搞定
今天重点说以下3种:
1)回退提示
官方知识点:
核心机制:要求 LLM 首先考虑一个与具体任务相关的更普遍、更抽象的问题,然后将这个普遍问题的答案作为上下文,用于指导解决最初的特定任务。
目的与效果:这种“回退”过程能够激活 LLM 的背景知识和推理过程,鼓励其进行批判性思考。最终,它有助于 LLM 生成更准确、更有创意、更扎实、更具洞察力的具体输出。
本质:它是一种引导式头脑风暴,通过关注一般原则来帮助减轻 LLM 响应中的偏见。
个人感受:这个方法感觉和思维链很像,但它是针对思考的起点的,这种方式使模型从一个更广泛、更高级别的角度来看待问题。而思维链是在思考的过程中做文章,它使模型将其逻辑推理外化为可见的步骤,确保计算或逻辑推导的每一步都正确,从而保证最终答案的可靠性。从应用场景来看,回退提示更适合创造性的任务,比如编故事情节,如果不使用这个方式,可能故事会比较通用和平庸,通过让LLM输出写故事的几点框架,再写出的故事可能会更符合预期。
2)自我一致性
这个听着名字很迷糊,但实际上就是多问几次,然后看结果哪种更多?。
学术一点讲,自我一致性的核心观点是,虽然单个推理路径可能有缺陷,但正确答案很可能可以通过多个有效路径达到。它以计算成本换取了鲁棒性,但成本很高。
最后这句话是针对产品经理等专业人士的,普通人我们多问问不花钱,以后不确定的答案,就一个模型多问几次、多个模型分别问,然后看看哪个回答是对的...
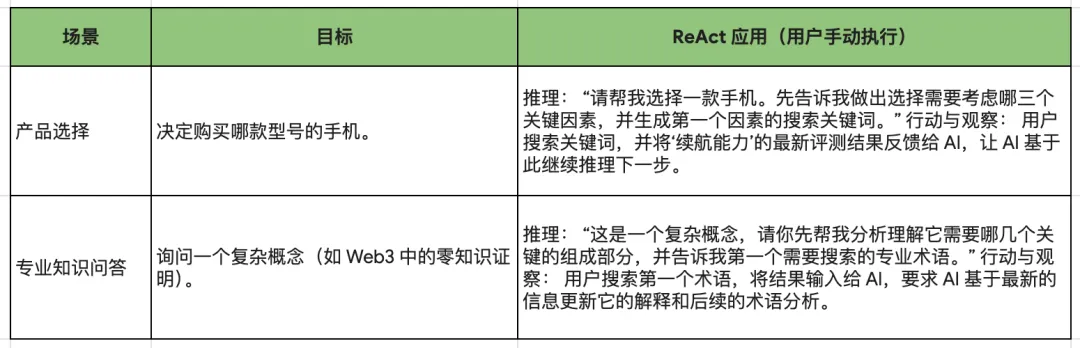
3)ReAct
推理与行动(Reason and act, ReAct)提示是一种范式,通过将推理和行动结合到一个思想 - 行动循环中来工作。LLM 首先对问题进行推理并生成行动计划。然后它执行计划中的行动并观察结果。接着,LLM 使用观察结果更新其推理并生成新的行动计划。这个过程持续进行,直到 LLM 找到问题的解决方案。
5.最佳实战:
这里也提到了大家长知道的提供示例、具体说明、限制输出等方面,可以看下面的图,基本上看文字就知道说的是啥意思。有几个关键点,我下面单独再说下:
1)简洁设计
提示应该简洁、清晰、易于理解,但不是说你不需要把背景交代清楚,这里只是说你应该选择的表达方式。
原文示例:
修改前 ::我现在正在访问纽约,我想了解更多关于好地点的信息。我和两个 3 岁的孩子在一起。我们假期应该去哪里?
重写后 :扮演游客的旅行指南。描述在纽约曼哈顿适合带 3 岁孩子参观的好地方。
2)使用指令而非约束
指令 (instruction) 提供关于响应的期望格式、风格或内容的明确指示。它指导模型应该做什么或产生什么。约束 (constraint) 是对响应的一组限制或边界。它限制模型不应该做什么或避免什么。与和人沟通一样,积极正面的回答大模型也喜欢,所以我们要少用约束型话术。但约束在某些情况下仍然很有价值,例如,防止模型生成有害或有偏见的内容,或者当需要严格的输出格式或风格时。
原文示例:
推荐:生成一篇关于排名前5的视频游戏机的1段博客文章。仅讨论游戏机本身、制造商公司、年份和总销量。
不推荐 :生成一篇关于排名前5的视频游戏机的1段博客文章。不要列出视频游戏名称。
3)在提示中使用变量

4)尝试不同的输出格式
除了提示输入格式,考虑尝试输出格式。对于非创造性任务,如提取、选择、解析、排序、排名或分类数据,尝试输出以结构化格式(如 JSON 或 XML)返回,结构化是避免大模型幻觉的一种方式。

5)记录各种提示尝试
最后这个,是我觉得最最最有价值的建议!这对于AI产品经理来说是更重要的,普通用户把自己试过的好的提示词整理起来即可。这样的方式方便学习、比较和复现。

官方内容介绍到这,以下是我的一点个人感受:
与大模型交流时,你就把大模型当作你带的实习生,二者的合作过程非常相似!给他布置任务时,应该这么做:
先明确自己的需求,心里想明白。如本次工作的大方向、背景信息、目标任务、输出结果的要求等等。
用什么样的方式讲。你说话时的传达方式对方是否能听懂(如用词是否准确、表达方式,是不是方便对方理解),对人还有语气的问题,对AI不需要语气?,更简单一些。
多次配合中不断磨合。这个很虚,但实际带人过程中却是非常重要的一环,如何在短时间内磨合好,将大大影响后续你俩合作的输出成果。
以上是我看完这篇白皮书印象深刻的点,提示词工程是一门实践大于理论的学科,大家不要纸上谈兵,多去使用才能提高。快行动起来吧。大家有什么新收获,记得来评论区留言哦~
往期精选: