



《人工智能安全风险测评白皮书(2025年)》由中国信息安全测评中心联合北京奇虎科技、中国科学院自动化研究所、中电信人工智能科技等十余家单位共同编写。白皮书围绕“为何测、测什么、怎么测、测哪些”四个核心问题展开,系统梳理了人工智能安全风险测评的理论框架、技术体系与实践路径,构建了一套覆盖人工智能全生命周期的安全风险测评体系。
“先进制造研究院”公众号首页对话框回复“人工智能安全风险测评”,可下载《人工智能安全风险测评白皮书(2025年)》。
01 为何测:AI安全已成国家战略与产业刚需
“为何测”直指人工智能安全风险测评的根本动因。当前,全球人工智能技术高速迭代,生成式AI正以前所未有的广度与深度重塑社会生产生活方式。
同时,人工智能广泛应用带来前所未有的安全挑战。虚假信息传播、隐私侵犯、就业冲击等风险逐渐浮出水面,尤其在法律、政治和社会舆论领域,AI伪造内容已引发各国政府高度关注。
中国2023年提出《全球人工智能治理倡议》,明确“推动建立风险等级测试评估体系”;2025年发布《关于深入实施‘人工智能+’行动的意见》,要求“提升安全能力水平”“建立健全人工智能技术监测、风险预警、应急响应体系”。
全球范围内,美国发布《人工智能风险管理框架》,欧盟通过《人工智能法案》,英国设计柔性监管路径,新加坡规划问责导向治理。安全测评已成为国际共识。
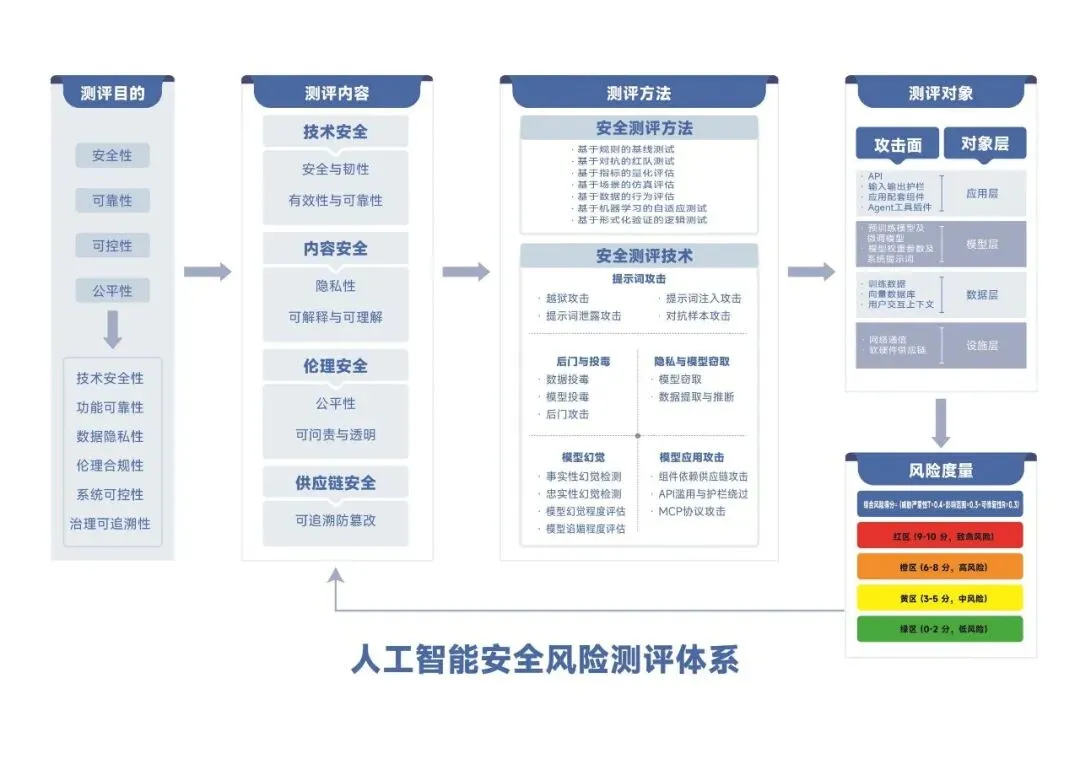
02 测什么:全生命周期与五大维度的风险覆盖
“测什么”定义了人工智能安全风险测评的内容边界。白皮书构建了全景式、全链路的人工智能安全风险分析体系,横向贯穿七个生命周期阶段:
系统规划与设计、数据采集与处理、模型训练与构建、模型验证与确认、平台部署与集成、系统运行与监测、用户使用与影响。
纵向对应五大关键维度:应用环境、数据和输入、人工智能模型、任务和输出、人类社会。通过“风险定位—攻击分析—目标对标”三层逻辑闭环,实现从技术层到社会层的全域风险映射。
以模型训练与构建阶段为例,风险定位集中于模型鲁棒性不足与恶意逻辑植入;攻击技术包括对抗样本训练、后门植入等;目标需对标“可靠性”与“安全性”。
而在用户使用与影响阶段,风险延伸至社会层面,如生成内容引发歧视或误导;攻击手段包括社会工程攻击、舆论操控等;目标需锚定“公平性”与“可信赖性”。
03 怎么测:多元化技术路径与全栈分层测评
“怎么测”明确了人工智能安全风险测评的方法论体系。白皮书提出基于“技术特性—风险类型—应用场景”匹配逻辑,构建多元化测评技术路径,形成“静态筛查—动态攻击—量化评估—场景验证”闭环体系。
基于规则的基线测试将政策标准、伦理准则转化为可执行的刚性规则,适用于合规性快速筛查。
基于对抗的红队测试模拟攻击者视角,通过提示词注入、多模态对抗样本生成等手段主动挖掘系统脆弱性。
基于指标的量化评估通过客观、可计算的指标体系,将定性安全描述转化为定量数据,实现不同系统、不同阶段的安全水平对比。
基于场景的仿真评估构建贴近真实应用的场景库,通过“沉浸式测试”发现场景化特有风险。
测评对象覆盖全栈分层:设施层(硬件、云环境、网络设施)、数据层(训练数据集、用户交互数据)、模型层(预训练模型、微调模型、模型参数)、应用层(智能聊天机器人、内容生成工具)。四层对象既各有侧重,又相互关联,形成完整的安全防护链条。
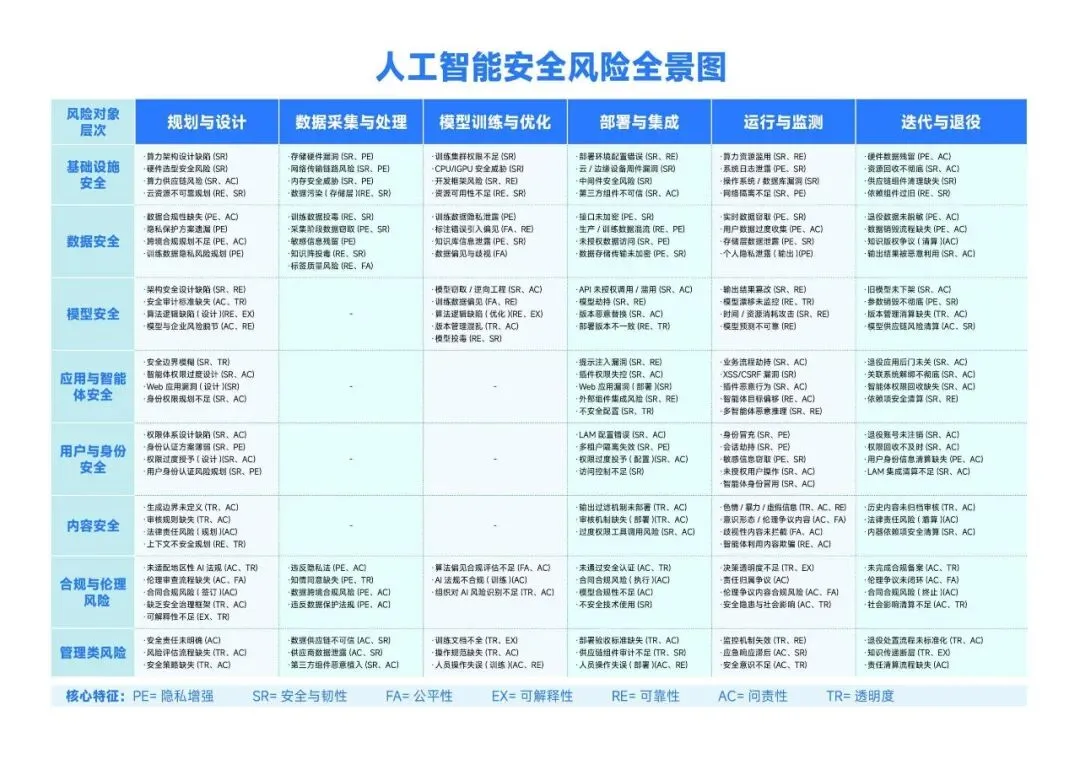
04 测哪些:人工智能安全风险全景图
“测哪些”细化了人工智能安全风险测评的具体场景。白皮书绘制了“人工智能安全风险全景图”,对关键维度进行调整以突出测评内容,将全生命周期中的“模型训练与构建”与“模型验证与确认”合并为“模型训练优化”,将“用户使用与影响”扩充为“迭代与退役”。
由此,风险全景图既能呈现不同阶段的“异质风险”,又在八个层次呈现“同质风险”:
基础设施安全:算力架构设计缺陷、硬件选型安全风险、云资源不可靠规则等;
数据安全:训练数据投毒、敏感信息残留、用户数据过度收集等;
模型安全:模型窃取与逆向工程、模型投毒、API未授权调用等;
应用与智能体安全:提示注入漏洞、插件权限失控、智能体目标偏移等;
用户与身份安全:权限体系设计缺陷、身份冒充、会话劫持等;
内容安全:生成边界未定义、输出过滤机制未部署、色情/暴力/虚假信息等;
合规与伦理风险:未适配地区性AI法规、违反隐私法、算法偏见合规评估不足等;
管理类风险:安全责任未明确、风险评估流程缺失、监控机制失效等。
从全景图中提取五大测评重点:供应链安全测评、数据安全测评、模型安全测评、价值观与伦理对齐测评、运行态系统安全测评,实现风险测评从“框架”到“重点”的精准落地。
例如在供应链安全测评中,需关注硬件供应链的供应韧性、完整性与计算安全性,评估地缘政治风险下的“断供”可能性;在数据安全测评中,需聚焦训练数据来源合规性、数据存储传输安全性、敏感数据泄露风险等。
05 关键技术:红队测试体系深度解析
在“怎么测”的具体实施层面,红队测试技术成为重要组成部分。白皮书重点介绍了覆盖输入、训练、模型、输出、部署等五个层次的红队测试技术。
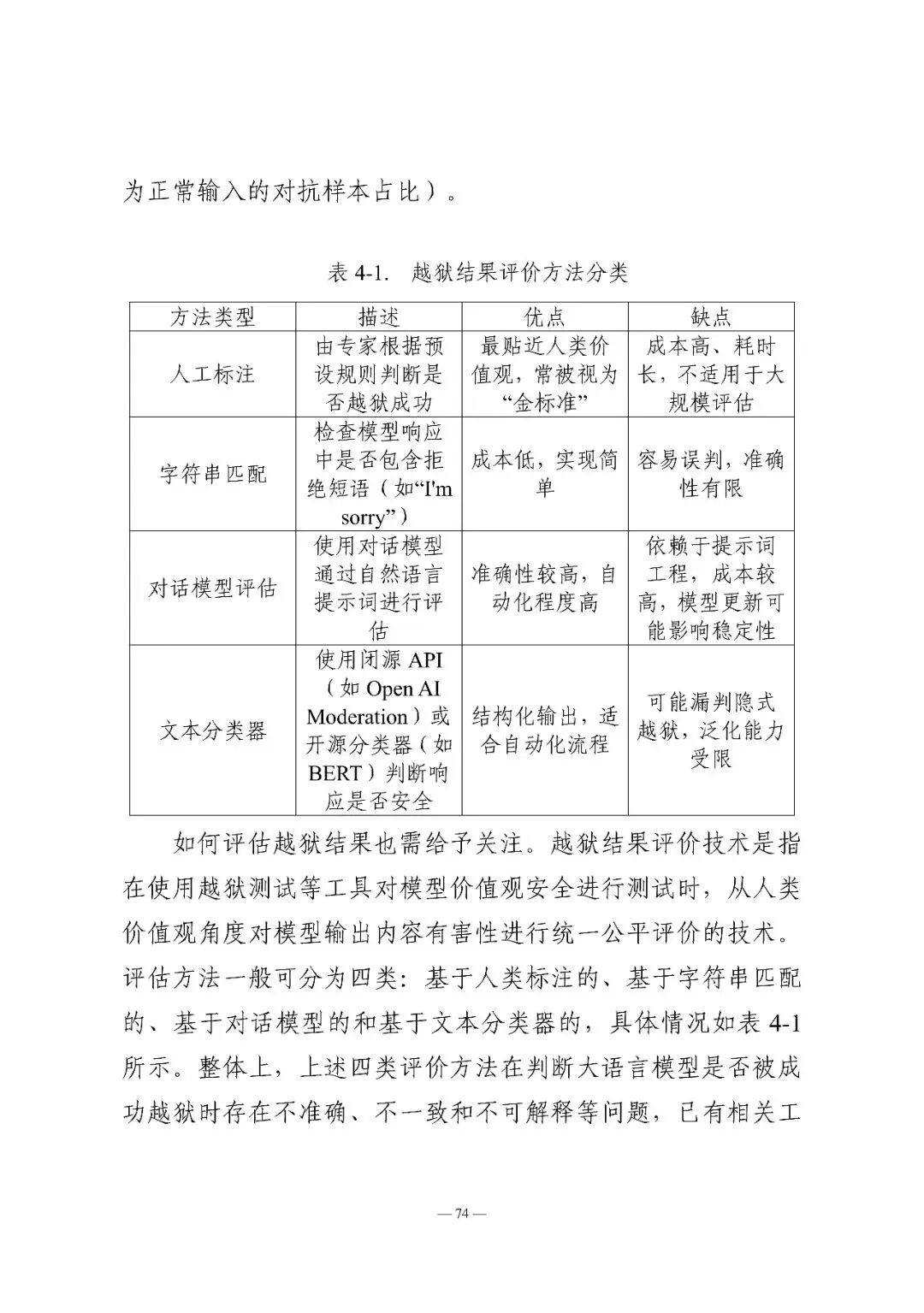
输入层测试聚焦“输入操纵”,包括越狱测试、提示词注入测试、提示词泄露测试、对抗样本测试等。研究发现,仅需250份恶意文档就可能在LLM中制造出后门漏洞,且这一结论与模型规模或训练数据量无关。
训练层测试通过污染训练或微调数据,使模型存在先天安全缺陷。当训练数据集中仅有0.01%的虚假文本时,模型输出的有害内容会增加11.2%。
输出层测试通过设计特定策略输入看似正常的查询,利用模型推理逻辑缺陷诱导错误输出,或通过分析模型输出行为提取敏感信息。
部署层测试聚焦LLM系统的运行环境与交互接口,利用部署配置漏洞或供应链弱点实施测试,包括组件供应链测试、API滥用与护栏绕过等。
06 风险度量:四级风险等级划分体系
测评的最终产出需要可量化、可比较的风险评估。白皮书构建了“基础指标量化—综合维度加权—风险等级映射”的多层级测评指标体系。
基础指标针对设施层、数据层、模型层、应用层的核心安全维度,定义可直接计算的量化指标,如“对抗样本成功率”“护栏拦截率”“偏见指数”等。
综合风险等级通过加权整合基础指标,结合“威胁严重性、影响范围、可修复性”三维度,形成量化评分,映射为四级风险等级:
绿区(低风险):漏洞数量少,威胁严重性低,影响范围局限,可快速修复;
黄区(中风险):存在潜在漏洞,需特定条件触发,影响范围限于业务内部;
橙区(高风险):漏洞可被常规攻击手段利用,影响核心功能,可能导致业务中断或合规风险;
红区(致命风险):存在致命漏洞,可被轻易利用,影响范围涉及社会公众或触犯法律。
实际应用中采用非线性评估模型,若任一维度的风险超过阈值,则整体风险直接定级为最高,确保风险评估的严谨性。
未来,随着AI技术向自动化、全生命周期、跨模态方向演进,安全测评体系也需相应升级,以应对更复杂的挑战,确保人工智能在赋能社会的同时,始终处于人类可控的轨道上。
































































































温馨提示
如果你喜欢本文,请分享到朋友圈,想要获得更多信息,请关注“先进制造研究院”。一定不要忘了给“先进制造研究院”设星标哦!
先进制造研究院 · 简介
先进制造研究院是厦门焙垦文化科技有限公司旗下的重要创新机构,公司已在厦门两岸股权交易中心成功挂牌,企业代码为864016。作为一家根植于厦门的创新机构,积极参与区域内的产学研合作,始终坚持以客户需求为导向,我们专注于通过智库研究、教育培训和专业服务,推动制造业的转型升级和高质量发展。
侵权免责声明:
1. 本公众号发布的所有内容,包括但不限于文字、图片、音频、视频等,除特别标明外,均来源于网络或用户投稿,版权归原作者或原出处所有。我们致力于保护原作者版权,若涉及版权问题,请及时联系我们进行处理。
2. 本公众号部分信息来源于互联网或其他公众平台,我们尽可能确保信息的准确性与完整性,但并不保证其绝对无误或最新。对于因使用或信赖本公众号信息而引致的任何损失,本公众号概不负责,亦不负任何法律责任。
3. 对于用户在评论区发表的内容,本公众号不承担任何法律责任。
4. 若本文内容涉及引用,仅为交流学习、传递更多信息之目的,不为商业用途,其版权归原作者或原出版社所有,不对所涉及的版权问题负法律责任。若有来源标注错误或侵犯了您的合法权益,请作者与我们联系,我们将及时更正、删除,谢谢。
欢迎详询交流
