


жң¬ж–ҮдёәиҠӮйҖүеҶ…е®№
еҰӮйңҖжӣҙеӨҡжҠҘе‘ҠпјҢиҒ”зі»е®ўжңҚиҙӯд№°
еҸҜиҙӯд№°еҚ•д»ҪжҠҘе‘ҠжҲ–жү“еҢ…пјҲ300е…ғпјҢ300еӨҡд»Ҫдәәе·ҘжҷәиғҪжҠҘе‘ҠпјҢиҰҶзӣ–е…·иә«жҷәиғҪгҖҒе·ҘдёҡжңәеҷЁдәәгҖҒдәәеҪўжңәеҷЁдәәгҖҒвҖңдәәе·ҘжҷәиғҪ+вҖқпјү
1.AIеёӮеңәй«ҳйҖҹжү©еј пјҢжңүжңӣеј•йўҶж–°дёҖд»Је·Ҙдёҡйқ©е‘Ҫ
1.1.AIжҺЁеҠЁз”ҹдә§еҸҳйқ©пјҢиЎҢдёҡжӯҘе…Ҙ蓬еӢғеҸ‘еұ•жңҹ
пјҲ1пјүдәәе·ҘжҷәиғҪпјҲArtificial IntelligenceпјҢAIпјүжҳҜдёҖз§ҚжЁЎжӢҹдәәзұ»жҷәиғҪзҡ„жҠҖжңҜпјҢж—ЁеңЁдҪҝжңәеҷЁиғҪеӨҹеғҸдәәзұ»дёҖж ·жҖқиҖғгҖҒеӯҰд№ е’Ңи§ЈеҶій—®йўҳгҖӮAIж¶өзӣ–дәҶеӨҡз§ҚжҠҖжңҜе’Ңж–№жі•пјҢеҢ…жӢ¬ж·ұеәҰеӯҰд№ гҖҒжңәеҷЁеӯҰд№ гҖҒи®Ўз®—жңәи§Ҷи§үе’ҢиҮӘ然иҜӯиЁҖеӨ„зҗҶзӯүгҖӮиҮӘ1956е№ҙиҫҫзү№иҢ…ж–Ҝдјҡи®®йҰ–ж¬ЎжҸҗеҮәAIжҰӮеҝөд№ӢеҗҺпјҢAIз»ҸеҺҶдәҶж—©жңҹзҡ„иҗҢиҠҪејҸеҸ‘еұ•пјҢ20дё–зәӘ70е№ҙд»ЈеҮәзҺ°зҡ„专家系з»ҹе®һзҺ°дәҶAIд»ҺзҗҶи®әз ”з©¶иө°еҗ‘е®һйҷ…еә”з”ЁгҖҒд»ҺдёҖиҲ¬жҺЁзҗҶзӯ–з•ҘжҺўи®ЁиҪ¬еҗ‘иҝҗз”Ёдё“й—ЁзҹҘиҜҶзҡ„йҮҚеӨ§зӘҒз ҙпјҢдҪҶеҗҺз»ӯAIеӣ дёәдёҖзі»еҲ—й—®йўҳйҷ·е…ҘеҸ‘еұ•з“¶йўҲпјҢиҝӣе…Ҙ21дё–зәӘпјҢйҡҸзқҖзҪ‘з»ңжҠҖжңҜзҡ„еҸ‘еұ•пјҢж•°жҚ®зҡ„иҺ·еҸ–еҸҳеҫ—жӣҙеҠ е®№жҳ“пјҢдә‘и®Ўз®—зҡ„е…ҙиө·жҸҗдҫӣдәҶејәеӨ§зҡ„и®Ўз®—иғҪеҠӣпјҢдёәж·ұеәҰеӯҰд№ зҡ„еә”з”ЁжҸҗдҫӣдәҶеңҹеЈӨпјҢ2010е№ҙиө·пјҢд»Ҙж·ұеәҰзҘһз»ҸзҪ‘з»ңдёәд»ЈиЎЁзҡ„AIжҠҖжңҜ蓬еӢғеҸ‘еұ•пјҢеә”з”ЁиҗҪең°еңәжҷҜеӨҡзӮ№ејҖиҠұпјҢе°Өе…¶еңЁиҝ‘еҮ е№ҙпјҢеӨ§и§„жЁЎйў„и®ӯз»ғжЁЎеһӢж—¶д»ЈејҖеҗҜпјҢжө·еҶ…еӨ–д»ҘChatGPTгҖҒDeepSeekзӯүдёәд»ЈиЎЁзҡ„AIжЁЎеһӢз«һиөӣеҰӮзҒ«еҰӮиҚјпјҢж Үеҝ—зқҖAIиҝӣе…ҘдәҶдёҖдёӘж–°зҡ„зәӘе…ғгҖӮ

пјҲ2пјүжҢүз…§жҷәиғҪзЁӢеәҰеҲ’еҲҶпјҢAIдё»иҰҒеҲҶдёәзӢӯд№үдәәе·ҘжҷәиғҪпјҲANIпјүгҖҒйҖҡз”Ёдәәе·ҘжҷәиғҪпјҲAGIпјүе’Ңи¶…зә§дәәе·ҘжҷәиғҪпјҲASIпјүпјҢзӣ®еүҚAGIе’ҢASIе°ҡеӨ„дәҺзҗҶи®әе’ҢжҺўзҙўйҳ¶ж®өгҖӮANIпјҲArtificial Narrow IntelligenceпјүеҸҲз§°ејұдәәе·ҘжҷәиғҪжҢҮдё“жіЁдәҺзү№е®ҡд»»еҠЎзҡ„дәәе·ҘжҷәиғҪзі»з»ҹпјҢиғҪеӨҹй«ҳж•Ҳжү§иЎҢзү№е®ҡеҠҹиғҪпјҢдҪҶе…¶иғҪеҠӣеұҖйҷҗдәҺйў„и®ҫд»»еҠЎпјҢдёҚе…·еӨҮйҖҡз”ЁжҷәиғҪгҖӮAGIпјҲArtificial General IntelligenceпјүжҢҮе…·еӨҮдёҺдәәзұ»зӣёеҪ“зҡ„з»јеҗҲжҷәиғҪпјҢиғҪеӨҹзҗҶи§ЈгҖҒеӯҰд№ е’Ңжү§иЎҢд»»дҪ•жҷәеҠӣд»»еҠЎпјҢе…·еӨҮиҮӘдё»еӯҰд№ е’ҢжҺЁзҗҶиғҪеҠӣгҖӮASIпјҲArtificial Super IntelligenceпјүжҢҮеңЁеҮ д№ҺжүҖжңүйўҶеҹҹи¶…и¶Ҡдәәзұ»жҷәиғҪзҡ„дәәе·ҘжҷәиғҪпјҢе…·еӨҮиҮӘжҲ‘ж”№иҝӣиғҪеҠӣпјҢеҸҜиғҪеңЁз§‘еӯҰгҖҒиүәжңҜзӯүйўҶеҹҹиҝңи¶…дәәзұ»гҖӮзӣ®еүҚпјҢANIе·Іе№ҝжіӣеә”з”ЁдәҺеӣҫеғҸе’ҢиҜӯйҹіиҜҶеҲ«гҖҒиҮӘеҠЁй©ҫ驶зӯүеңәжҷҜпјҢAGIе°ҡжңӘжңүе®һйҷ…еә”з”ЁпјҢд»ҚеӨ„дәҺзҗҶи®әйҳ¶ж®өпјҢдҪҶSoraзҡ„й—®дё–ж— з–‘дҪҝжҲ‘们зҰ»AGIжӣҙиҝӣдәҶдёҖжӯҘгҖӮ
пјҲ3пјүз”ҹжҲҗејҸдәәе·ҘжҷәиғҪпјҲGenerative Artificial IntelligenceпјҢGen AIпјүжҳҜAIйўҶеҹҹзҡ„йҮҚиҰҒеҲҶж”ҜпјҢдёҚеҗҢдәҺдј з»ҹзҡ„AIд»…еҜ№иҫ“е…Ҙж•°жҚ®иҝӣиЎҢеӨ„зҗҶе’ҢеҲҶжһҗпјҢGen AIиғҪеӨҹеӯҰд№ е№¶з”ҹжҲҗе…·жңүйҖ»иҫ‘зҡ„ж–°еҶ…е®№гҖӮGen AIеҸҜд»ҘеӯҰд№ е№¶жЁЎжӢҹдәӢзү©зҡ„еҶ…еңЁи§„еҫӢпјҢжҳҜдёҖз§ҚеҹәдәҺз®—жі•е’ҢжЁЎеһӢз”ҹжҲҗе…·жңүйҖ»иҫ‘жҖ§е’ҢиҝһиҙҜжҖ§зҡ„ж–Үжң¬гҖҒеӣҫзүҮгҖҒеЈ°йҹігҖҒи§Ҷйў‘гҖҒд»Јз ҒзӯүеҶ…е®№зҡ„жҠҖжңҜгҖӮж—©жңҹGen AIдё»иҰҒй’ҲеҜ№еҚ•дёҖжЁЎжҖҒпјҢеҰӮ GPTзі»еҲ—з”ҹжҲҗж–Үжң¬гҖҒStyleGANз”ҹжҲҗеӣҫеғҸгҖӮйҡҸзқҖжҠҖжңҜиҝӣжӯҘпјҢGen AI ејҖе§Ӣз»“еҗҲеӨҡжЁЎжҖҒжЁЎеһӢпјҢдҫқиө–дәҺеӨҚжқӮзҡ„жңәеҷЁеӯҰд№ жЁЎеһӢпјҢе®һзҺ°ејӮжһ„ж•°жҚ®зҡ„з”ҹжҲҗејҸиҫ“еҮәпјҢеҲӣе»әи·ЁжЁЎжҖҒеҺҹеҲӣеҶ…е®№пјҲдҫӢеҰӮж–Үжң¬гҖҒеӣҫеғҸгҖҒи§Ҷйў‘гҖҒйҹійў‘жҲ–иҪҜ件代з Ғпјүд»Ҙе“Қеә”з”ЁжҲ·зҡ„жҸҗзӨәжҲ–иҜ·жұӮгҖӮеңЁеә”з”ЁеұӮйқўпјҢGen AIеҸҜжҳҫи‘—жҸҗеҚҮз”ҹдә§ж•ҲзҺҮпјҢж №жҚ®иҙқжҒ©пјҢGen AIеҸҜеңЁиҗҘй”Җж–№йқўзј©еҮҸ30%-50%еҶ…е®№еҲӣйҖ жүҖйңҖзҡ„ж—¶й—ҙж¶ҲиҖ—пјҢеңЁиҪҜ件ејҖеҸ‘ж–№йқўзј©зҹӯ15%зҡ„д»Јз Ғзј–еҶҷж—¶й—ҙгҖӮ
пјҲ4пјүAIе…·жңүз®—еҠӣгҖҒз®—жі•гҖҒж•°жҚ®дёүеӨ§иҰҒзҙ пјҢе…¶дёӯеҹәзЎҖеұӮжҸҗдҫӣз®—еҠӣж”ҜжҢҒпјҢйҖҡз”ЁжҠҖжңҜе№іеҸ°и§ЈеҶіз®—жі•й—®йўҳпјҢеңәжҷҜеҢ–еә”з”ЁжҢ–жҺҳж•°жҚ®д»·еҖјгҖӮж•°жҚ®жҳҜAIеӯҰд№ е’ҢжҲҗй•ҝзҡ„еҹәзҹіпјҢеҶіе®ҡдәҶз®—жі•жҳҜеҗҰиғҪеҫ—еҲ°жңүж•Ҳзҡ„и®ӯз»ғе’ҢдјҳеҢ–пјҢж•°жҚ®зҡ„иҙЁйҮҸе’Ңж•°йҮҸд№ҹзӣҙжҺҘеҪұе“ҚеҲ°AIжЁЎеһӢзҡ„еҮҶзЎ®жҖ§е’Ңж•ҲзҺҮпјӣз®—жі•жҳҜAIзҡ„зҒөйӯӮпјҢеҶіе®ҡдәҶAIеҰӮдҪ•еӨ„зҗҶж•°жҚ®е’Ңи§ЈеҶій—®йўҳпјҢе…¶и®ҫи®Ўе’ҢйҖүжӢ©зӣҙжҺҘе…ізі»еҲ°AIзҡ„жҖ§иғҪе’Ңеә”з”Ёж•Ҳжһңпјӣз®—еҠӣжҳҜAIиҝҗиЎҢзҡ„еҠЁеҠӣпјҢз®—еҠӣжҸҗдҫӣдәҶжү§иЎҢз®—жі•е’ҢеӨ„зҗҶж•°жҚ®жүҖйңҖзҡ„и®Ўз®—иө„жәҗпјҢејәеӨ§зҡ„з®—еҠӣеҸҜд»Ҙж”ҜжҢҒеӨҚжқӮе’ҢеӨ§и§„жЁЎзҡ„AIеә”з”ЁгҖӮе…¶дёӯз®—еҠӣжҢҮи®Ўз®—и®ҫеӨҮеңЁеҚ•дҪҚж—¶й—ҙеҶ…еӨ„зҗҶж•°жҚ®зҡ„иғҪеҠӣпјҢ
AIз®—еҠӣжҳҜдё“й—Ёй’ҲеҜ№AIд»»еҠЎпјҲеҰӮзҹ©йҳөиҝҗз®—гҖҒзҘһз»ҸзҪ‘з»ңи®ӯз»ғпјүдјҳеҢ–зҡ„и®Ўз®—иғҪеҠӣпјҢйңҖж”ҜжҢҒй«ҳ并иЎҢжҖ§е’ҢеӨ§и§„жЁЎж•°жҚ®еӨ„зҗҶпјҢйҖҡеёёз”Ёжө®зӮ№иҝҗз®—ж¬Ўж•°пјҲFLOPSпјүиЎЎйҮҸпјҢиЎҚз”ҹзҡ„иҝҳжңүTFLOPSпјҲдёҮдәҝж¬Ў/з§’пјүгҖҒPFLOPSпјҲеҚғдёҮдәҝж¬Ў/з§’пјүзӯүеёёи§ҒеҚ•дҪҚпјҢз®—еҠӣзҡ„ж ёеҝғ硬件еҢ…жӢ¬GPUгҖҒASICгҖҒFPGAзӯүгҖӮ
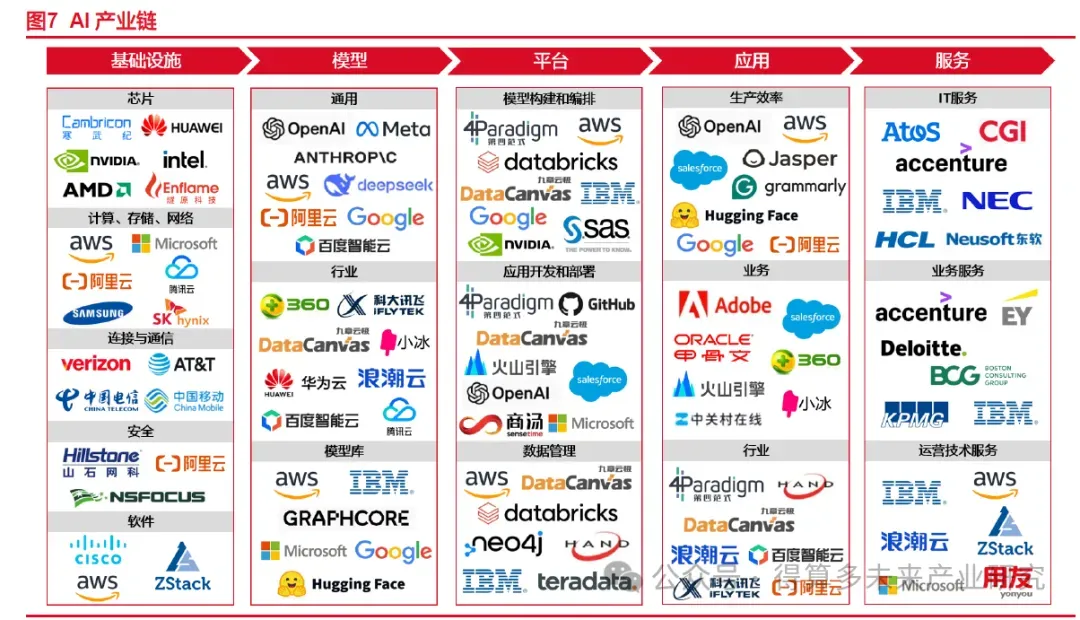
1.2.AIдә§дёҡй“ҫж¶өзӣ–еҹәзЎҖи®ҫж–ҪеҲ°еә”з”ЁиҗҪең°еӨҡдёӘзҺҜиҠӮ
пјҲ1пјүAIдә§дёҡй“ҫеҸҜеӨ§иҮҙеҲҶдёәеҹәзЎҖи®ҫж–ҪеұӮгҖҒжЁЎеһӢеұӮгҖҒе№іеҸ°еұӮгҖҒеә”з”ЁеұӮеҸҠжңҚеҠЎеұӮпјҢе…¶дёӯеҹәзЎҖи®ҫж–ҪеұӮеҢ…еҗ«иҠҜзүҮгҖҒеӯҳеӮЁгҖҒзҪ‘з»ңзӯүпјҢжЁЎеһӢеұӮеҢ…еҗ«йҖҡз”ЁжЁЎеһӢгҖҒиЎҢдёҡжЁЎеһӢзӯүгҖӮдёҠжёёеҹәзЎҖи®ҫж–ҪеұӮжҳҜAIдә§дёҡй“ҫзҡ„еҹәзЎҖпјҢдё»иҰҒж¶үеҸҠж•°жҚ®гҖҒз®—еҠӣзӯүеҹәзЎҖиҪҜ硬件пјҢеҢ…жӢ¬AIиҠҜзүҮпјҢд»ЈиЎЁеҺӮе•ҶеҜ’жӯҰзәӘгҖҒиӢұдјҹиҫҫзӯүпјӣи®Ўз®—гҖҒеӯҳеӮЁгҖҒзҪ‘з»ңж–№йқўпјҢд»ЈиЎЁеҺӮе•Ҷдәҡ马йҖҠгҖҒеҫ®иҪҜгҖҒйҳҝйҮҢгҖҒдёүжҳҹз”өеӯҗзӯүгҖӮжЁЎеһӢеұӮжҳҜAIдә§дёҡй“ҫзҡ„ж ёеҝғйғЁеҲҶпјҢеҢ…жӢ¬йҖҡз”ЁеӨ§жЁЎеһӢе’ҢиЎҢдёҡеӨ§жЁЎеһӢзӯүгҖӮе№іеҸ°еұӮе’ҢжЁЎеһӢеұӮж·ұеәҰз»‘е®ҡпјҢдҪҝеӨ§жЁЎеһӢжӣҙдҫҝдәҺдҪҝз”Ёе’Ңжҷ®еҸҠгҖӮйҡҸзқҖAIеӨ§жЁЎеһӢзҡ„еҸ‘еұ•пјҢе№іеҸ°дёӯеӨҡз§ҚжЁЎеһӢйҖүжӢ©гҖҒеҰӮдҪ•е°ҶеӨ§жЁЎеһӢй«ҳж•Ҳдё”еҸҜйқ ең°йғЁзҪІдәҺз”ҹдә§зҺҜеўғжҳҜеҪ“еүҚзҡ„ж ёеҝғй—®йўҳгҖӮеә”з”ЁеұӮжҳҜAIдә§дёҡй“ҫзҡ„з»Ҳз«ҜзҺҜиҠӮпјҢдё»иҰҒж¶үеҸҠAIеңЁеҗ„дёӘйўҶеҹҹзҡ„еә”з”Ёе’ҢиҗҪең°пјҢиҖҢеӨ§жЁЎеһӢзҡ„дёҚж–ӯжӣҙж–°еҚҮзә§жңүеҠ©дәҺеҠ йҖҹеә”з”ЁеңәжҷҜзҡ„еҲӣж–°еҸҠе•ҶдёҡеҢ–иҗҪең°гҖӮ
пјҲ2пјү2024е№ҙе…ЁзҗғAIеёӮеңә规模жңүжңӣиҫҫеҲ°6.16дёҮдәҝзҫҺе…ғпјҢеҗҢжҜ”еўһй•ҝ30.1%гҖӮж №жҚ®Frost & SullivanпјҢиҮӘ2020е№ҙиө·пјҢе…ЁзҗғAIеёӮеңә规模д»Ҙй«ҳдәҺ20%зҡ„еҗҢжҜ”еўһйҖҹе‘ҲзҺ°иҝ…зҢӣеўһй•ҝзҡ„жҖҒеҠҝпјҢд»Һ2019е№ҙзҡ„1.91дёҮдәҝзҫҺе…ғжңүжңӣжү©еј иҮі2024е№ҙзҡ„6.16дёҮдәҝзҫҺе…ғпјҢеҗҢжҜ”еўһйҖҹйҖҗе№ҙдёҠеҚҮпјҢ2025е№ҙејҖе§ӢиҷҪ然预计еўһйҖҹеҗҢжҜ”ж”ҫзј“пјҢдҪҶж•ҙдҪ“еёӮеңәжңүжңӣеңЁ2027е№ҙжү©еј иҮі11.64дёҮдәҝзҫҺе…ғпјҢдҪ“зҺ°еҮәе…ЁзҗғAIиЎҢдёҡдә•е–·ејҸзҡ„еҸ‘еұ•йҖҹеәҰгҖӮ
2.AIеӨ§жЁЎеһӢжҳҜAIеҸҳйқ©зҡ„йҮҚиҰҒзҺҜиҠӮд№ӢдёҖ
2.1.вҖңScaling LawвҖқй©ұеҠЁеӨ§жЁЎеһӢдёҚж–ӯиҝӣжӯҘ
пјҲ1пјүAIеӨ§жЁЎеһӢжҢҮдҪҝз”ЁеӨ§и§„жЁЎж•°жҚ®е’ҢејәеӨ§зҡ„и®Ўз®—иғҪеҠӣи®ӯз»ғеҮәжқҘзҡ„вҖңеӨ§еҸӮж•°вҖқжЁЎеһӢпјҢйҖҡеёёе…·жңүй«ҳеәҰзҡ„йҖҡз”ЁжҖ§е’ҢжіӣеҢ–иғҪеҠӣпјҢеҸҜд»Ҙеә”з”ЁдәҺиҮӘ然иҜӯиЁҖеӨ„зҗҶгҖҒеӣҫеғҸиҜҶеҲ«гҖҒиҜӯйҹіиҜҶеҲ«зӯүйўҶеҹҹгҖӮ2022е№ҙ11жңҲ30ж—ҘпјҢдјҙйҡҸзқҖChatGPTзҡ„жҺЁеҮәпјҢе…¶дә®зңјзҡ„иҜӯиЁҖз”ҹжҲҗиғҪеҠӣжҺҖиө·дәҶе…ЁзҗғиҢғеӣҙеҶ…зҡ„AIеӨ§жЁЎеһӢзғӯжҪ®пјҢGeminiгҖҒLlamaгҖҒж–ҮеҝғдёҖиЁҖгҖҒSORAгҖҒDeepSeekзӯүеҗ„зұ»еӨ§жЁЎеһӢеҰӮйӣЁеҗҺжҳҘз¬ӢиҲ¬ж¶ҢзҺ°гҖӮеӨ§жЁЎеһӢдҪңдёәAIдә§дёҡй“ҫдёӯзҡ„ж ёеҝғзҺҜиҠӮпјҢжҺЁеҠЁдәҶиҮӘ然иҜӯиЁҖеӨ„зҗҶгҖҒи®Ўз®—жңәи§Ҷи§үзӯүйўҶеҹҹзҡ„зӘҒз ҙпјҢжҳҫи‘—жҸҗеҚҮдәҶAIзҡ„зҗҶи§Је’Ңз”ҹжҲҗиғҪеҠӣпјҢ并且еңЁеҢ»з–—гҖҒйҮ‘иһҚгҖҒж•ҷиӮІгҖҒиҮӘеҠЁй©ҫ驶зӯүеӨҡдёӘиЎҢдёҡдёӯеҫ—еҲ°е№ҝжіӣеә”з”ЁпјҢжңүжңӣеј•йўҶдәәзұ»жӯҘе…Ҙ第еӣӣж¬Ўе·Ҙдёҡйқ©е‘ҪгҖӮ
пјҲ2пјүжҢүз…§иҫ“е…Ҙж•°жҚ®зұ»еһӢзҡ„дёҚеҗҢпјҢеӨ§жЁЎеһӢеҸҜеҲҶдёәеӨ§иҜӯиЁҖжЁЎеһӢгҖҒи§Ҷи§үеӨ§жЁЎеһӢгҖҒеӨҡжЁЎжҖҒеӨ§жЁЎеһӢдёүеӨ§зұ»пјӣд»Һи®ӯз»ғиҢғејҸзңӢпјҢеӨ§жЁЎеһӢд№ҹеҸҜеҲҶдёәеҹәеә§жЁЎеһӢгҖҒжҺЁзҗҶжЁЎеһӢе’ҢеӨҡжЁЎжҖҒжЁЎеһӢгҖӮ1пјүд»Һиҫ“е…Ҙж•°жҚ®зұ»еһӢзңӢпјҢеӨ§иҜӯиЁҖжЁЎеһӢпјҲLLMпјҢLarge Language ModelпјүжҳҜжҢҮеңЁиҮӘ然иҜӯиЁҖеӨ„зҗҶпјҲNatural Language ProcessingпјҢNLPпјүйўҶеҹҹдёӯзҡ„дёҖзұ»еӨ§жЁЎеһӢпјҢйҖҡеёёз”ЁдәҺеӨ„зҗҶж–Үжң¬ж•°жҚ®е’ҢзҗҶи§ЈиҮӘ然иҜӯиЁҖпјҢе®ғ们еңЁеӨ§и§„жЁЎиҜӯж–ҷеә“дёҠиҝӣиЎҢдәҶи®ӯз»ғпјҢд»ҘеӯҰд№ иҮӘ然иҜӯиЁҖзҡ„еҗ„з§ҚиҜӯжі•гҖҒиҜӯд№үе’ҢиҜӯеўғ规еҲҷпјӣи§Ҷи§үеӨ§жЁЎеһӢжҳҜжҢҮеңЁи®Ўз®—жңәи§Ҷи§үпјҲComputer VisionпјҢCVпјүйўҶеҹҹдёӯдҪҝз”Ёзҡ„еӨ§жЁЎеһӢпјҢйҖҡеёёз”ЁдәҺеӣҫеғҸеӨ„зҗҶе’ҢеҲҶжһҗпјҢиҝҷзұ»жЁЎеһӢйҖҡиҝҮеңЁеӨ§и§„жЁЎеӣҫеғҸж•°жҚ®дёҠиҝӣиЎҢи®ӯз»ғд»Ҙе®һзҺ°еҗ„з§Қи§Ҷи§үд»»еҠЎпјҢеҰӮеӣҫеғҸеҲҶзұ»гҖҒзӣ®ж ҮжЈҖжөӢгҖҒдәәи„ёиҜҶеҲ«зӯүпјӣеӨҡжЁЎжҖҒеӨ§жЁЎеһӢпјҲMLLMпјҢMultimodal LLMпјүжҳҜжҢҮиғҪеӨҹеӨ„зҗҶеӨҡз§ҚдёҚеҗҢзұ»еһӢж•°жҚ®зҡ„еӨ§жЁЎеһӢпјҢдҫӢеҰӮж–Үжң¬гҖҒеӣҫеғҸгҖҒйҹійў‘зӯүеӨҡжЁЎжҖҒж•°жҚ®пјҢиҝҷзұ»жЁЎеһӢз»“еҗҲдәҶNLPе’ҢCVзҡ„иғҪеҠӣпјҢд»Ҙе®һзҺ°еҜ№еӨҡжЁЎжҖҒдҝЎжҒҜзҡ„з»јеҗҲзҗҶи§Је’ҢеҲҶжһҗпјҢиғҪжӣҙе…Ёйқўең°зҗҶи§Је’ҢеӨ„зҗҶеӨҚжқӮзҡ„ж•°жҚ®гҖӮ2пјүд»Һи®ӯз»ғиҢғејҸзңӢпјҢйҷӨеҺ»дёҠж–ҮжҸҗеҲ°зҡ„еӨҡжЁЎжҖҒжЁЎеһӢпјҢеҹәеә§жЁЎеһӢпјҲFoundation ModelsпјүжҳҜдёҖз§ҚеӨ§и§„жЁЎзҡ„йў„и®ӯз»ғжЁЎеһӢпјҢйҖҡеёёз”ЁдәҺжҸҗдҫӣеҹәзЎҖзҡ„иҜӯиЁҖзҗҶи§Је’Ңз”ҹжҲҗиғҪеҠӣпјҢзү№зӮ№жҳҜеҸӮж•°ж•°йҮҸеәһеӨ§пјҢиғҪеӨҹеӨ„зҗҶеӨҚжқӮзҡ„иҜӯиЁҖд»»еҠЎпјӣжҺЁзҗҶжЁЎеһӢпјҲInference ModelsпјүжҳҜеңЁеҹәеә§жЁЎеһӢзҡ„еҹәзЎҖдёҠиҝӣиЎҢиҝӣдёҖжӯҘи®ӯз»ғе’ҢдјҳеҢ–зҡ„жЁЎеһӢпјҢе®ғдё“жіЁдәҺжҸҗеҚҮжЁЎеһӢзҡ„жҺЁзҗҶиғҪеҠӣпјҢйҖҡеёёйҖҡиҝҮејәеҢ–еӯҰд№ зӯүжҠҖжңҜжқҘеўһејәжЁЎеһӢзҡ„жҖ§иғҪпјҢиғҪеӨҹеӨ„зҗҶжӣҙеӨҚжқӮзҡ„д»»еҠЎпјҢе…·еӨҮиҮӘ主规еҲ’е’ҢеҶізӯ–зҡ„иғҪеҠӣгҖӮ
пјҲ3пјүж·ұеәҰеӯҰд№ дҪңдёәжңәеҷЁеӯҰд№ дёӯзҡ„йҮҚиҰҒеҲҶж”ҜпјҢд№ҹжҳҜеӨ§жЁЎеһӢжҸҗдҫӣдәҶејәеҠӣзҡ„жҠҖжңҜж”Ҝж’‘пјҢж·ұеәҰеӯҰд№ ж¶өзӣ–и®ӯз»ғе’ҢжҺЁзҗҶдёӨдёӘйҳ¶ж®өпјҢе…¶дёӯи®ӯз»ғеҸҲеҲҶдёәйў„и®ӯз»ғгҖҒеҗҺи®ӯз»ғдёӨдёӘжӯҘйӘӨгҖӮи®ӯз»ғпјҲTrainingпјүжҳҜжҢҮйҖҡиҝҮз»ҷе®ҡзҡ„и®ӯз»ғж•°жҚ®йӣҶпјҢеҲ©з”Ёж·ұеәҰеӯҰд№ з®—жі•жқҘдёҚж–ӯең°и°ғж•ҙе’ҢдјҳеҢ–зҘһз»ҸзҪ‘з»ңжЁЎеһӢзҡ„еҸӮж•°пјҢдҪҝе…¶иғҪеӨҹд»Һж•°жҚ®йӣҶдёӯеӯҰд№ е№¶еҪўжҲҗеҜ№жңӘзҹҘж•°жҚ®зҡ„йў„жөӢиғҪеҠӣгҖӮе…¶дёӯйў„и®ӯз»ғпјҲPre-trainingпјүйҖҡеёёеҸ‘з”ҹеңЁжЁЎеһӢејҖеҸ‘зҡ„ж—©жңҹйҳ¶ж®өпјҢзӣ®зҡ„жҳҜеңЁеӨ§и§„жЁЎж•°жҚ®йӣҶдёҠеӯҰд№ йҖҡз”Ёзү№еҫҒпјҢдёәеҗҺз»ӯд»»еҠЎеҘ е®ҡеҹәзЎҖпјҢйў„и®ӯз»ғдёҚй’ҲеҜ№зү№е®ҡд»»еҠЎпјҢиҖҢжҳҜиҝҪжұӮе№ҝжіӣзҡ„йҖӮз”ЁжҖ§гҖӮеҗҺи®ӯз»ғпјҲPost-TrainingпјүеҸ‘з”ҹеңЁйў„и®ӯз»ғд№ӢеҗҺпјҢжЁЎеһӢйғЁзҪІеүҚжҲ–йғЁзҪІеҲқжңҹпјҢеҗҺи®ӯз»ғй’ҲеҜ№зү№е®ҡзҡ„д»»еҠЎжҲ–ж•°жҚ®йӣҶиҝӣиЎҢйўқеӨ–и®ӯз»ғпјҢд»ҘдјҳеҢ–жЁЎеһӢжҖ§иғҪпјҢеҢ…жӢ¬Supervised Fine-tuningпјҲSFTпјҢзӣ‘зқЈеҫ®и°ғпјүе’ҢReinforcement Learning from Human FeedbackпјҲRLHFпјҢдәәзұ»еҸҚйҰҲзҡ„ејәеҢ–еӯҰд№ пјүзӯүзҺҜиҠӮгҖӮжҺЁзҗҶпјҲInferenceпјүжҳҜжҢҮеңЁз»ҸиҝҮи®ӯз»ғеҗҺпјҢе°Ҷе·Із»Ҹи®ӯз»ғеҘҪзҡ„жЁЎеһӢеә”з”ЁеҲ°зңҹе®һзҡ„ж•°жҚ®дёҠпјҢи®©жЁЎеһӢеҜ№зңҹе®һзҡ„ж•°жҚ®иҝӣиЎҢйў„жөӢжҲ–еҲҶзұ»гҖӮ
пјҲ4пјүScaling LawдҪңдёәеӨ§жЁЎеһӢйў„и®ӯз»ғ第дёҖжҖ§еҺҹзҗҶпјҢд»ҚжҳҜй©ұеҠЁжЁЎеһӢиҝӣжӯҘзҡ„йҮҚиҰҒе®ҡеҫӢгҖӮ规模е®ҡеҫӢпјҲScaling Lawпјүд№ҹз§°е°әеәҰе®ҡеҫӢгҖҒзј©ж”ҫе®ҡеҫӢзӯүпјҢеңЁAIйўҶеҹҹдёӯиў«дёҡз•Ңи®ӨдёәжҳҜеӨ§жЁЎеһӢйў„и®ӯз»ғ第дёҖжҖ§еҺҹзҗҶпјҢжҸҸиҝ°дәҶеңЁжңәеҷЁеӯҰд№ йўҶеҹҹпјҢзү№еҲ«жҳҜеҜ№дәҺеӨ§иҜӯиЁҖжЁЎеһӢиҖҢиЁҖпјҢжЁЎеһӢжҖ§иғҪпјҲLпјҢжЁЎеһӢеңЁжөӢиҜ•йӣҶдёҠзҡ„дәӨеҸүзҶөжҚҹеӨұпјүдёҺжЁЎеһӢзҡ„еҸӮж•°йҮҸеӨ§е°ҸпјҲNпјүгҖҒи®ӯз»ғжЁЎеһӢзҡ„ж•°жҚ®еӨ§е°ҸпјҲDпјүд»ҘеҸҠи®ӯз»ғжЁЎеһӢдҪҝз”Ёзҡ„и®Ўз®—йҮҸпјҲCпјүд№Ӣй—ҙеӯҳеңЁдёҖз§ҚеҸҜйў„жөӢзҡ„е…ізі»гҖӮиҝҷз§Қе…ізі»йҖҡеёёиЎЁзҺ°дёәйҡҸзқҖиҝҷдәӣеӣ зҙ зҡ„еўһй•ҝпјҢжЁЎеһӢжҖ§иғҪдјҡжҢүз…§дёҖе®ҡзҡ„е№ӮеҫӢиҝӣиЎҢж”№е–„гҖӮйў„и®ӯз»ғйҳ¶ж®өзҡ„Scaling Lawдҫқ然жҳҜзӣ®еүҚGPTиҢғејҸдёӯжҲҗжң¬жңҖй«ҳзҡ„и®ӯз»ғйҳ¶ж®өпјҢ99%зҡ„и®Ўз®—еңЁйў„и®ӯз»ғйҳ¶ж®өдёӯгҖӮ
пјҲ5пјүеӨ§жЁЎеһӢдёӯеӯҳеңЁдёҖз§ҚвҖңж¶ҢзҺ°вҖқзҺ°иұЎпјҢиҝӣдёҖжӯҘиҜҒжҳҺжЁЎеһӢеҸӮж•°йҮҸзӯүеұһжҖ§еӨ§е°Ҹзҡ„йҮҚиҰҒжҖ§гҖӮвҖңж¶ҢзҺ°вҖқеңЁзү©зҗҶеӯҰдёӯзҡ„и§ЈйҮҠжҳҜжҢҮзі»з»ҹзҡ„йҮҸеҸҳеј•иө·иЎҢдёәзҡ„иҙЁеҸҳпјҢеңЁAIйўҶеҹҹдёӯпјҢж¶ҢзҺ°иғҪеҠӣпјҲEmergent AbilitiesпјүеңЁиҫғе°Ҹзҡ„жЁЎеһӢдёӯдёҚеҮәзҺ°пјҢйҖҡеёёеҸӘеңЁеӨ§жЁЎеһӢдёӯеҮәзҺ°пјҢе°Өе…¶жҳҜеӨ§иҜӯиЁҖжЁЎеһӢгҖӮдёӢеӣҫжҳҫзӨәдәҶеҜ№дәҺGPT-3зӯүжЁЎеһӢй’ҲеҜ№ж¶өзӣ–ж•°еӯҰгҖҒеҺҶеҸІгҖҒжі•еҫӢзӯүзӯүдёҖзі»еҲ—дё»йўҳзҡ„еҹәеҮҶжөӢиҜ•пјҢз»“жһңжҳҫзӨәпјҢеҜ№дәҺGPT-3гҖҒGopherе’ҢChinchillaпјҢе°ҸдәҺзӯүдәҺ10BеҸӮж•°ж—¶пјҢеҮҶзЎ®зҺҮзӯүиЎЁзҺ°з»“жһң并没жңүи¶…иҝҮйҡҸжңәеӨӘеӨҡпјҢдҪҶдёҖж—ҰеҸӮж•°йҮҸиҫҫеҲ°70B-280Bж—¶пјҢжҖ§иғҪеӨ§еӨ§и¶…и¶ҠдәҶйҡҸжңәж•ҲжһңпјҢиҝҷдёӘз»“жһңжҲ–ж„Ҹе‘ізқҖи·Ёи¶ҠжҹҗдёӘйҳҲеҖјпјҢжЁЎеһӢи§ЈеҶіеӨ§йҮҸд»ҘзҹҘиҜҶдёәеҹәзЎҖзҡ„гҖҒж¶өзӣ–еӨҡдёӘйўҶеҹҹзҡ„й—®йўҳзҡ„иЎЁзҺ°дјҡеҮәзҺ°иҙЁзҡ„йЈһи·ғпјҲеҜ№дәҺжІЎжңүжЈҖзҙўжҲ–и®ҝй—®еӨ–йғЁеҶ…еӯҳзҡ„зЁ еҜҶиҜӯиЁҖжЁЎеһӢжқҘиҜҙпјүпјҢиҝӣдёҖжӯҘдҪ“зҺ°жЁЎеһӢеҸӮж•°йҮҸгҖҒж•°жҚ®йҮҸзӯүеӨ§е°Ҹзҡ„йҮҚиҰҒжҖ§гҖӮ
2.2.еӨ§жЁЎеһӢе•ҶдёҡеҢ–жЁЎејҸжңүжңӣйҖҡиҝҮAI Agentе®һзҺ°иҪ¬еһӢ
пјҲ1пјүжңӘжқҘдә”е№ҙе…ЁзҗғеӨ§жЁЎеһӢиЎҢдёҡеёӮеңә规模зҡ„CAGRжңүжңӣиҫҫеҲ°36.23%гҖӮйҡҸзқҖAIжҠҖжңҜзҡ„дёҚж–ӯиҝӣжӯҘе’Ңеә”з”ЁеңәжҷҜзҡ„ж—ҘзӣҠдё°еҜҢпјҢеӨ§жЁЎеһӢзҡ„еёӮеңә规模ж—ҘзӣҠжү©еұ•пјҢ2021е№ҙпјҢе…ЁзҗғеӨ§жЁЎеһӢеёӮеңә规模еҗҢжҜ”еўһй•ҝ132%пјҢ2020е№ҙиҮі2024е№ҙпјҢе…ЁзҗғеӨ§жЁЎеһӢеёӮеңә规模жңүжңӣд»Һ25дәҝзҫҺе…ғйЈһйҖҹжү©еј иҮі280дәҝзҫҺе…ғпјҢеўһй•ҝеҚҒеҖҚд»ҘдёҠпјҢ2025е№ҙжҲ–е°Ҷжү©еј иҮі366дәҝзҫҺе…ғпјҢеҗҢжҜ”еўһй•ҝ30.71%пјҢиҷҪ然еўһйҖҹжңүжүҖж”ҫзј“пјҢдҪҶжңӘжқҘдә”е№ҙпјҢе…ЁзҗғеӨ§жЁЎеһӢиЎҢдёҡеёӮеңә规模жңүжңӣд»Ҙ36.23%зҡ„е№ҙеӨҚеҗҲеўһй•ҝзҺҮжү©еј иҮі2029е№ҙзҡ„1314дәҝзҫҺе…ғгҖӮ
пјҲ2пјүзӣ®еүҚпјҢеӨ§жЁЎеһӢзҡ„дё»иҰҒзӣҲеҲ©жЁЎејҸжҳҜеҹәдәҺз”ЁйҮҸзҡ„дёҖз§Қе•ҶдёҡжЁЎејҸпјҢж ёеҝғзҗҶеҝөжҳҜйҖҡиҝҮAPIи°ғ用收иҙ№пјҢжӯӨеӨ–иҝҳжңүе№ҝе‘ҠгҖҒжЁЎеһӢжҺЁзҗҶйғЁзҪІж–№еҗ‘зҡ„дёҡеҠЎжЁЎејҸгҖӮеҹәдәҺз”ЁйҮҸзҡ„收иҙ№жЁЎж•°дё»иҰҒжҢүз…§TokensгҖҒи°ғз”Ёж¬Ўж•°гҖҒж—¶й—ҙеҢәй—ҙзӯүз»ҙеәҰжқҘ收иҙ№пјҢд№ҹжҳҜеҪ“еүҚдё»жөҒзҡ„зӣҲеҲ©ж–№ејҸгҖӮйҷӨжӯӨд№ӢеӨ–пјҢжЁЎеһӢеңЁдә‘з«ҜжҲ–иҖ…жң¬ең°йғЁзҪІд№ҹжҳҜжЁЎеһӢзӣҲеҲ©зҡ„йҮҚиҰҒеҪўејҸпјҢиҝҳжңүдёҖдәӣAIеӨ§жЁЎеһӢзӣёе…ізҡ„appеӣ дёәдёӢиҪҪйҮҸе·ЁеӨ§пјҢеҗёеј•еҲ°йғЁеҲҶе•Ҷ家жҠ•ж”ҫе№ҝе‘ҠпјҢиҝӣиҖҢеҪўжҲҗдәҶе№ҝе‘Ҡ收е…ҘгҖӮ
пјҲ3пјүжЁЎеһӢAPI жң¬иҙЁжҳҜдёҖз§ҚMaaSпјҲModel as a serviceпјүжЁЎејҸпјҢжҳҜжө·еӨ–еӨ§жЁЎеһӢзҡ„ж ёеҝғ
е•ҶдёҡжЁЎејҸпјҢеӣҪеҶ…еёӮеңәз”ұдәҺе·®ејӮеҢ–зЁӢеәҰиҫғдҪҺпјҢ规模зӣёеҜ№иҫғе°ҸпјҢдҪҺд»·з«һдәүзӯ–з•ҘжҲ–е°Ҷй•ҝжңҹжҢҒз»ӯгҖӮAPIпјҲApplication Programming InterfaceпјҢеә”з”ЁзЁӢеәҸзј–зЁӢжҺҘеҸЈпјүжҳҜдёҖдәӣйў„е…Ҳе®ҡд№үзҡ„еҮҪж•°пјҢзӣ®зҡ„жҳҜжҸҗдҫӣеә”з”ЁзЁӢеәҸдёҺејҖеҸ‘дәәе‘ҳеҹәдәҺжҹҗиҪҜ件жҲ–硬件еҫ—д»Ҙи®ҝй—®дёҖз»„дҫӢзЁӢзҡ„иғҪеҠӣпјҢиҖҢеҸҲж— йңҖи®ҝй—®жәҗз ҒпјҢжҲ–зҗҶи§ЈеҶ…йғЁе·ҘдҪңжңәеҲ¶зҡ„з»ҶиҠӮпјҢеңЁеӨ§жЁЎеһӢеұӮйқўпјҢејҖеҸ‘иҖ…йҖҡиҝҮAPI иҝҷдёҖж ҮеҮҶеҢ–жҺҘеҸЈи°ғз”ЁеӨ§жЁЎеһӢеҠҹиғҪпјҢиҖҢж— йңҖд»ҺеӨҙи®ӯз»ғжЁЎеһӢпјҢеҸӘйңҖеҸ‘йҖҒиҜ·жұӮеҚіеҸҜиҺ·еҫ—жЁЎеһӢзҡ„иҫ“еҮәгҖӮйҖҡиҝҮAPI и°ғз”Ёд»ҺиҖҢзӣҲеҲ©зҡ„зү№зӮ№жҳҜз®ҖеҚ•жҳ“з”ЁгҖҒеӨҚжқӮжҖ§дҪҺе’Ңе®ҡеҲ¶еҢ–зЁӢеәҰдҪҺпјҢжЁЎеһӢиғҪеҠӣжҳҜе”ҜдёҖзҡ„е·®ејӮеҢ–д№ӢеӨ„пјҢиҝҷжң¬иҙЁжҳҜдёҖз§ҚеҹәдәҺеә•еұӮжЁЎеһӢз”ЁйҮҸзҡ„жЁЎејҸпјҢеҶҚеўһеҠ дёҖйғЁеҲҶдә§е“ҒеұӮзҡ„жәўд»·жһ„жҲҗе®ҡд»·гҖӮAPI иЎҢдёҡйңҖжұӮж–№иҫғдёәзўҺзүҮеҢ–пјҢжқҘиҮӘеҗ„дёӘиЎҢдёҡпјҢд»Һдҫӣз»ҷеұӮйқўзңӢпјҢжЁЎеһӢAPI жҳҜжө·еӨ–еӨ§жЁЎеһӢзҡ„ж ёеҝғе•ҶдёҡжЁЎејҸпјҢд»ҺеӣҪеҶ…еёӮеңәзңӢпјҢз”ұдәҺеӣҪеҶ…жЁЎеһӢиғҪеҠӣзјәд№Ҹе·®ејӮеҢ–пјҢиЎҢдёҡдҪҺд»·з«һдәүи¶ӢеҠҝзӯүеӣ зҙ пјҢж•ҙдҪ“еёӮеңә规模иҫғе°ҸпјҢйҡҫд»ҘжҲҗдёәжЁЎеһӢеҺӮе•Ҷзҡ„дё»иҰҒ收е…ҘжқҘжәҗгҖӮ
пјҲ4пјүжҢүз…§Tokenи®Ўд»·жҳҜеӨ§йғЁеҲҶеӨ§жЁЎеһӢAPIзҡ„收иҙ№ж–№ејҸпјҢеӣҪеҶ…еӨ–еӨ§жЁЎеһӢеҜ№дәҺTokenзҡ„ж ҮеҮҶ并дёҚз»ҹдёҖпјҢе®ҡд»·д№ҹе·®еҲ«иҫғеӨ§пјҢе…¶дҪҷиҝҳжңүжҢүз…§ж—¶й—ҙеҢәй—ҙи®Ўд»·гҖҒи°ғз”Ёж¬Ўж•°зӯүи®Ўд»·жЁЎејҸгҖӮTokenеңЁеӨ§жЁЎеһӢдёӯзҡ„еҗ«д№үжҳҜжңҖе°Ҹж–Үжң¬еҚ•е…ғпјҢеҸҜд»Ҙзӣҙи§Ӯең°зҗҶи§Јдёәеӯ—жҲ–иҜҚпјҢдҪҶзӣ®еүҚTokenе’ҢеҚ•дёӘжұүеӯ—гҖҒиӢұж–Үеӯ—жҜҚд№Ӣй—ҙзҡ„关系并没жңүз»ҹдёҖзҡ„и®ЎйҮҸж ҮеҮҶпјҢеҗ„еӨ§жЁЎеһӢд№ҹеҗ„дёҚзӣёеҗҢпјҢдҪҶжҖ»дҪ“жқҘиҜҙ1дёӘtokenвүҲ1-1.8дёӘжұүеӯ—пјҢеңЁиӢұж–Үж–Үжң¬дёӯпјҢ1дёӘtokenвүҲ3-4дёӘеӯ—жҜҚгҖӮе®ҡд»·ж–№йқўпјҢдёҚд»…еҜ№дәҺдёҚеҗҢеӨ§жЁЎеһӢ收иҙ№ж ҮеҮҶдёҚеҗҢпјҢеҜ№дәҺдёҖдәӣеӨ§жЁЎеһӢжқҘиҜҙпјҢеңЁдёҚеҗҢж—¶й—ҙж®өдҪҝз”Ёзҡ„е®ҡд»·д№ҹдёҚеҗҢгҖӮжӯӨеӨ–пјҢжҢүз…§ж—¶й—ҙеҢәй—ҙи®Ўд»·дё»иҰҒжҳҜй’ҲеҜ№дёӘдәәз”ЁжҲ·зҡ„и®ўйҳ…еҲ¶ж”¶иҙ№жЁЎејҸпјҢеҸҜжҢүз…§е№ҙгҖҒжңҲгҖҒе‘Ёзӯүз»ҙеәҰиҙӯд№°жңҚеҠЎпјҲеҰӮChatGPTпјүпјҢжҢүз…§и°ғз”Ёж¬Ўж•°зҡ„и®Ўд»·жЁЎејҸеҲҷж–№дҫҝз”ЁжҲ·жҢүйңҖиҙӯд№°гҖӮ
пјҲ5пјүе®ҡеҲ¶еҢ–жңҚеҠЎдё»иҰҒжҳҜжҢҮжЁЎеһӢжҺЁзҗҶйғЁзҪІпјҢеҢ…еҗ«дә‘з«ҜгҖҒжң¬ең°гҖҒиҫ№зјҳеҸҠж··еҗҲйғЁзҪІпјҢжҳҜеӣҪеҶ…еӨ§жЁЎеһӢеёӮеңәзҡ„ж ёеҝғдёҡеҠЎжЁЎејҸпјҢиҙЎзҢ®дәҶеӨ§йғЁеҲҶиҗҘ收пјҢе…¶дёӯдә‘з«ҜйғЁзҪІжҳҜзӣ®еүҚжңҖдёәжҷ®йҒҚзҡ„еӨ§жЁЎеһӢйғЁзҪІж–№ејҸгҖӮ1пјүдә‘з«ҜйғЁзҪІжҳҜеҪ“еүҚжЁЎеһӢжҺЁзҗҶйғЁзҪІзҡ„дё»жөҒж–№ејҸпјҢеҲҶдёәз§Ғжңүдә‘йғЁзҪІе’Ңе…¬жңүдә‘йғЁзҪІпјҢз§Ғжңүдә‘йғЁзҪІжҳҜдјҒдёҡе°ҶжЁЎеһӢйғЁзҪІеңЁиҮӘе·ұз®ЎзҗҶзҡ„дә‘еҹәзЎҖи®ҫж–ҪдёҠпјҢз»“еҗҲдәҶжң¬ең°йғЁзҪІзҡ„жҺ§еҲ¶жқғе’Ңдә‘зҡ„зҒөжҙ»жҖ§пјҢе…¬жңүдә‘йғЁзҪІеҲҷжҳҜдјҒдёҡе°ҶжЁЎеһӢе’Ңж•°жҚ®жүҳз®ЎеңЁдә‘жңҚеҠЎе•ҶжҸҗдҫӣзҡ„еҹәзЎҖи®ҫж–ҪдёҠпјӣ 2пјүжң¬ең°йғЁзҪІйңҖиҰҒдјҒдёҡжңүе®Ңе–„зҡ„ITеҹәзЎҖи®ҫж–ҪпјҢжҳҜе°ҶеӨ§жЁЎеһӢйғЁзҪІеңЁдјҒдёҡиҮӘе·ұзҡ„зү©зҗҶжңҚеҠЎеҷЁдёҠпјҢйҖӮз”ЁдәҺйңҖиҰҒжһҒй«ҳж•°жҚ®йҡҗз§ҒжҲ–еҜ№еӨ–йғЁдҫқиө–жңүдёҘж јиҰҒжұӮзҡ„еңәжҷҜпјӣ3пјүиҫ№зјҳйғЁзҪІжҳҜжҢҮе°ҶеҺҹжң¬иҝҗиЎҢеңЁдә‘з«ҜжҲ–еӨ§еһӢжңҚеҠЎеҷЁдёҠзҡ„еӨ§жЁЎеһӢйҖҡиҝҮдјҳеҢ–е’ҢеҺӢзј©еҗҺпјҢйғЁзҪІеңЁйқ иҝ‘ж•°жҚ®дә§з”ҹжәҗеӨҙжҲ–еә”з”ЁеңәжҷҜзҡ„вҖңиҫ№зјҳи®ҫеӨҮвҖқпјҲеҰӮжүӢжңәгҖҒдј ж„ҹеҷЁгҖҒжң¬ең°жңҚеҠЎеҷЁгҖҒIoTи®ҫеӨҮзӯүпјүдёҠиҝҗиЎҢзҡ„жҠҖжңҜж–№жЎҲпјҢж ёеҝғзӣ®ж ҮжҳҜйҖҡиҝҮжң¬ең°еҢ–еӨ„зҗҶпјҢеҮҸе°‘еҜ№дә‘з«ҜжңҚеҠЎеҷЁзҡ„дҫқиө–пјҢд»ҺиҖҢжҸҗеҚҮе“Қеә”йҖҹеәҰгҖҒдҝқжҠӨж•°жҚ®йҡҗз§ҒпјҢ并йҖӮеә”зҪ‘з»ңдёҚзЁіе®ҡзҡ„зҺҜеўғпјӣ4пјүж··еҗҲйғЁзҪІжҳҜе°Ҷз§Ғжңүдә‘е’Ңе…¬жңүдә‘з»“еҗҲдҪҝз”ЁпјҢе°ҶдёҖдәӣе…ій”®д»»еҠЎпјҲеҰӮи®ӯз»ғгҖҒеӨ§и§„жЁЎж•°жҚ®еӨ„зҗҶпјүж”ҫеңЁз§Ғжңүдә‘дёӯпјҢиҖҢе°ҶжҺЁзҗҶд»»еҠЎжҲ–е…¶д»–йқһжңәеҜҶд»»еҠЎж”ҫеңЁе…¬жңүдә‘дёӯгҖӮ
пјҲ6пјүд»ҺеӣҪеҶ…еӨ§жЁЎеһӢйЎ№зӣ®иҗҪең°зҡ„еә”з”ЁйўҶеҹҹзңӢпјҢ2024е№ҙиҗҪең°йЎ№зӣ®ж•°йҮҸжҺ’еңЁеүҚдёүдҪҚзҡ„еҲҶеҲ«дёәйҖҡдҝЎгҖҒж•ҷ科е’Ңж”ҝеҠЎпјҢиҗҪең°йЎ№зӣ®йҮ‘йўқеүҚдёүдҪҚеҲҶеҲ«жҳҜж”ҝеҠЎгҖҒж•ҷ科е’ҢиғҪжәҗгҖӮд»Һ2024е№ҙеӣҪеҶ…е…¬ејҖжҠ«йңІзҡ„еӨ§жЁЎеһӢиҗҪең°йЎ№зӣ®зңӢпјҢеңЁж•ҷ科гҖҒйҖҡдҝЎгҖҒиғҪжәҗгҖҒж”ҝеҠЎгҖҒйҮ‘иһҚзӯүиЎҢдёҡж•°йҮҸе’ҢйҮ‘йўқйғҪзӣёеҜ№иҫғеӨҡгҖӮе…¶дёӯпјҢд»Һж•°йҮҸз»ҙеәҰзңӢпјҢжҺ’еҗҚеүҚдә”зҡ„иЎҢдёҡеҲҶеҲ«дёәйҖҡдҝЎпјҲ25.99%пјүгҖҒж•ҷ科пјҲ25.33%пјүгҖҒж”ҝеҠЎпјҲ11.38%пјүгҖҒиғҪжәҗпјҲ11.18%пјүе’ҢйҮ‘иһҚпјҲ8.75%пјүпјҢд»ҺйҮ‘йўқз»ҙеәҰзңӢпјҢжҺ’еҗҚеүҚдә”зҡ„иЎҢдёҡеҲҶеҲ«дёәж”ҝеҠЎпјҲ34.64%пјүгҖҒж•ҷ科пјҲ15.95%пјүгҖҒиғҪжәҗпјҲ11.14%пјүгҖҒйҖҡдҝЎпјҲ11.04%пјүе’ҢйҮ‘иһҚпјҲ3.71%пјүпјҢжҖ»дҪ“жқҘиҜҙпјҢж”ҝеҠЎиЎҢдёҡеҚ•дёӘйЎ№зӣ®ж¶үеҸҠйҮ‘йўқиҫғеӨ§пјҢе…¶ж¬ЎдёәиғҪжәҗгҖӮ
пјҲ7пјүйҡҸзқҖжЁЎеһӢиғҪеҠӣдёҚж–ӯжҸҗеҚҮпјҢдёҡеҠЎдёҚж–ӯжҲҗзҶҹпјҢжңӘжқҘд»ҘAI Agentдёәд»ЈиЎЁзҡ„еҹәдәҺз»“жһңе’Ңд»·еҖјеҲӣйҖ зҡ„е•ҶдёҡжЁЎејҸжңүжңӣйҖҗжӯҘиҗҪең°гҖӮеӨ§жЁЎеһӢзҡ„дёүз§Қеә”з”ЁжЁЎејҸеҲҶеҲ«дёәEmbeddingгҖҒCopilotе’ҢAgentпјҢеңЁEmbeddingжЁЎејҸдёӯпјҢеӨ§жЁЎеһӢиў«йӣҶжҲҗеҲ°зҺ°жңүзҡ„еә”з”ЁзЁӢеәҸжҲ–жңҚеҠЎдёӯпјӣCopilotжЁЎејҸдёӯпјҢеӨ§жЁЎеһӢе……еҪ“еҠ©жүӢзҡ„и§’иүІпјҢдёәз”ЁжҲ·жҸҗдҫӣе®һж—¶зҡ„е»әи®®е’Ңж”ҜжҢҒпјӣAgentжЁЎејҸдёӯпјҢеӨ§жЁЎеһӢиў«иөӢдәҲдәҶдёҖе®ҡзЁӢеәҰзҡ„иҮӘдё»жқғгҖӮиҝ‘ж—ҘпјҢManusдҪңдёәвҖңе…ЁзҗғйҰ–ж¬ҫйҖҡз”ЁAI AgentвҖқй—®дё–пјҢеј•еҸ‘еёӮеңәзғӯжғ…гҖӮAIAgentд»ҘеӨ§жЁЎеһӢдёәж ёеҝғеј•ж“ҺпјҢдҪҶжҳҜеҢәеҲ«дәҺз”ЁжҲ·еҹәдәҺжҸҗзӨәиҜҚпјҲpromptпјүдёҺAIжЁЎеһӢдәӨдә’пјҢAI Agentе…·еӨҮйҖҡиҝҮзӢ¬з«ӢжҖқиҖғгҖҒи°ғз”Ёе·Ҙе…·йҖҗжӯҘе®ҢжҲҗз”ЁжҲ·з»ҷе®ҡзҡ„зӣ®ж Үзҡ„иғҪеҠӣпјҢдё»жү“вҖңзӣҙжҺҘе®ҢжҲҗе·ҘдҪңвҖқпјҢжң¬иҙЁжҳҜдёҖдёӘжҺ§еҲ¶еӨ§жЁЎеһӢжқҘи§ЈеҶій—®йўҳзҡ„д»ЈзҗҶзі»з»ҹгҖӮдёҺдёҠж–ҮжЁЎеһӢAPIдёҚеҗҢпјҢиҝҷз§ҚеҹәдәҺз»“жһңе’Ңд»·еҖјеҲӣйҖ зҡ„е•ҶдёҡжЁЎејҸжӣҙеҠ еӨҚжқӮпјҢдё”йңҖиҰҒеҸҜиЎЎйҮҸзҡ„з»“жһңе’ҢдәӨд»ҳд»·еҖјпјҢзӣ®еүҚжЁЎеһӢеҺӮе•Ҷзҡ„дә§е“ҒеҪўжҖҒиҝҳеҮ д№ҺдёҚж”ҜжҢҒеҜ№зӣҙжҺҘеҹәдәҺжЁЎеһӢдә§з”ҹзҡ„е®һйҷ…ж•ҲзӣҠеҺ»е®ҡд»·пјҢдҪҶиҝҷз§ҚжЁЎејҸиғҪжӣҙеҘҪең°ж»Ўи¶іе®ўжҲ·йңҖжұӮгҖӮзӣ®еүҚпјҢCopilotзұ»дә§е“ҒйҰ–е…Ҳе®һзҺ°е•ҶдёҡиҗҪең°пјҢAI AgentжҲ–йҰ–е…Ҳд»ҺеһӮзӣҙеңәжҷҜејҖе§ӢйҖҗжӯҘжҺўзҙўпјҢжңӘжқҘеңЁжЁЎеһӢиғҪеҠӣдёҚж–ӯдёҠеҚҮгҖҒдә§е“ҒжЁЎејҸжӣҙеҠ жҲҗзҶҹеҗҺпјҢжңүжңӣжҲҗдёәж–°зҡ„дёӢжёёеә”з”ЁеўһйҮҸзӮ№гҖӮ
2.3.еӨ§жЁЎеһӢз«һдәүж—Ҙи¶ӢзҷҪзғӯпјҢжңӘжқҘзҺ©е®¶ж јеұҖжҲ–е°ҶйҖҗжӯҘ收ж•ӣ
пјҲ1пјүеӨ§жЁЎеһӢзҡ„иғҪеҠӣж—Ҙж–°жңҲејӮпјҢжҠӨеҹҺжІідёҚжҳҺзЎ®пјҢ规模ж•Ҳеә”е°ҡжңӘжҳҫзҺ°пјҢеҺӮе•ҶйңҖиҰҒжҢҒз»ӯеӨ§йҮҸжҠ•е…ҘеҸӮдёҺеёӮеңәз«һдәүгҖӮдә’иҒ”зҪ‘ж—¶д»ЈпјҢеҺӮе•ҶеҸҜд»Ҙж №жҚ®з”ЁжҲ·з”»еғҸиҝӣиЎҢзӣёе…іжҺЁиҚҗпјҢеҪўжҲҗдәҶиҫғејәзҡ„з”ЁжҲ·е…ізі»зҪ‘з»ңпјҢ规模ж•Ҳеә”иғҪеӨҹжҳҫи‘—йҷҚдҪҺжҲҗжң¬пјҢдё”йғЁеҲҶAPPзҡ„иҝҒ移жҲҗжң¬иҫғй«ҳпјҢеӨҙйғЁеҺӮ家йғҪеҪўжҲҗдәҶиҮӘе·ұжё…жҷ°зҡ„жҠӨеҹҺжІіпјҢиғҪеӨҹз»ҙжҢҒзЁіе®ҡиҫғеҘҪзҡ„еҲ©ж¶Ұж°ҙе№ігҖӮеҢәеҲ«дәҺдә’иҒ”зҪ‘пјҢеӨ§жЁЎеһӢзӣ®еүҚдә§е“ҒиҫғдёәеҗҢиҙЁеҢ–пјҢиҝҒ移жҲҗжң¬иҫғдҪҺпјҢз”ЁжҲ·е…іеҝғзҡ„жҳҜжЁЎеһӢзҡ„жҷәиғҪзЁӢеәҰе’ҢжҲҗжң¬пјҢдё”зӣ®еүҚиЎҢдёҡд»ҚеӨ„дәҺеүҚжңҹеӨ§и§„жЁЎиө„жң¬жҠ•е…Ҙйҳ¶ж®өпјҢеӨ§жЁЎеһӢиғҪеҠӣдёҚж–ӯзӘҒз ҙдёҠйҷҗпјҢ规模ж•Ҳеә”е°ҡжңӘжҳҫзҺ°пјҢеӣ жӯӨеҺӮе•Ҷд»ҚйңҖиҰҒй•ҝжңҹеӨ§йҮҸжҠ•е…Ҙд»ҺиҖҢеҸӮдёҺеёӮеңәз«һдәүпјҢз»ҙжҢҒйўҶе…Ҳең°дҪҚгҖӮ
пјҲ2пјүд»Һжө·еӨ–еӨ§жЁЎеһӢеҺӮе•ҶжқҘзңӢпјҢж•ҙдҪ“з«һдәүж јеұҖж—ҘзӣҠзҷҪзғӯеҢ–пјҢе°Ҫз®ЎGPTжӢҘжңүе…ҲеҸ‘дјҳеҠҝпјҢдҪҶжҳҜд»ҘClaudeгҖҒGeminiзӯүдёәд»ЈиЎЁзҡ„еӨ§жЁЎеһӢжӯЈеңЁиҝ…йҖҹиҝҪиө¶зј©е°ҸжҖ§иғҪе·®и·қгҖӮжҖ»дҪ“жқҘиҜҙпјҢжЁЎеһӢиғҪеҠӣеҶіе®ҡеёӮеңәд»ҪйўқпјҢOpenAIеңЁ2023е№ҙеҲқеҸ‘еёғGPT-4ж—¶з”ұдәҺйўҶе…Ҳзҡ„жЁЎеһӢиғҪеҠӣеңЁеёӮеңәжңүиҫғејәзҡ„з«һдәүеҠӣпјҢдҪҶеҗҺз»ӯAnthropicгҖҒGoogleзӣёз»§иҝӯд»Јж——дёӢзҡ„еӨ§жЁЎеһӢпјҢзӣ®еүҚClaudeгҖҒGeminiзҡ„жңҖж–°ж——иҲ°зүҲеӨ§жЁЎеһӢе·Із»ҸеңЁжҖ§иғҪдёҠйҖҗжӯҘиө¶дёҠжҲ–еңЁжҹҗдәӣйўҶеҹҹи¶…и¶ҠGPTзі»еҲ—жЁЎеһӢпјҢжЁЎеһӢе·®и·қзӣёжҜ”2023е№ҙжҳҫи‘—зј©е°ҸгҖӮ
пјҲ3пјүзӣ®еүҚпјҢOpenAIгҖҒAnthropicгҖҒDeepMindеҪўжҲҗдәҶжө·еӨ–еӨ§жЁЎеһӢзҡ„第дёҖжўҜйҳҹзҺ©е®¶пјҢ第дәҢжўҜйҳҹеҢ…жӢ¬xAIгҖҒMetaзӯүпјҢ第дёүжўҜйҳҹзҺ©е®¶йҖҗжӯҘиў«еӨҙйғЁеҺӮе•Ҷеҗёж”¶пјҢе°ҸжЁЎеһӢеҺӮе•ҶеңЁжҝҖзғҲзҡ„еёӮеңәз«һдәүдёӢиў«ж·ҳжұ°еҮәжё…пјҢжңӘжқҘз«һдәүж јеұҖе°ҶйҖҗжӯҘ收ж•ӣиҮіеӨҙйғЁ5家еҺӮе•ҶгҖӮ1пјүOpenAIзӣ®еүҚе’Ңеҫ®иҪҜж·ұеәҰз»‘е®ҡпјҢзӣ®еүҚиҗҘ收д»ҚеӨ„дәҺйўҶе…Ҳең°дҪҚпјҢдё»иҰҒжқҘиҮӘдәҺGPTзҡ„и®ўйҳ…жңҚеҠЎгҖӮ2пјүAnthropicиҗҘ收жһ„жҲҗдёҺOpenAIе·®еҲ«иҫғеӨ§пјҢдё»иҰҒдёәAPIжңҚеҠЎпјҢзӣ®еүҚе’Ңдәҡ马йҖҠз»‘е®ҡпјҢиҝ‘дёҖе№ҙжқҘеёӮеңәд»Ҫйўқеҝ«йҖҹеўһй•ҝгҖӮ3пјүDeepMindиғҢйқ и°·жӯҢпјҢдёҺи°·жӯҢе·ҘдҪңжөҒиҝӣиЎҢж•ҙеҗҲпјҢеҸ‘еҠӣй’ҲеҜ№дёӯе°ҸдјҒдёҡзҡ„APIеёӮеңәгҖӮ4пјү马ж–Ҝе…ӢеёҰйўҶзҡ„xAIзӣ®еүҚжӯЈеңЁиҝ…йҖҹеҸ‘еұ•пјҢиҝ‘жңҹеҸ‘еёғзҡ„Grok3е®Јз§°еңЁеҹәеҮҶжөӢиҜ•дёӯеҮ»иҙҘGPT-4oпјҢжҪңеҠӣе·ЁеӨ§гҖӮ5пјүеҢәеҲ«дәҺе…¶д»–еҺӮе•ҶпјҢMetaйҖүжӢ©дәҶејҖжәҗи·ҜзәҝпјҢзӣ®еүҚе°ҡжңӘйҖҡиҝҮжЁЎеһӢиҝӣиЎҢе•ҶдёҡеҢ–пјҢжһ„йҖ еӣҙз»•Llamaзҡ„ејҖжәҗз”ҹжҖҒгҖӮ6пјүз”ұдәҺзӣ®еүҚжө·еӨ–еҹәзЎҖжЁЎеһӢйңҖиҰҒж•°зҷҫдәҝзҫҺе…ғзҡ„жҢҒз»ӯжҠ•е…ҘпјҢйңҖиҰҒеҺӮе•Ҷжң¬иә«иҫғејәзҡ„иө„жң¬ж”Ҝж’‘е’ҢдёҺе·ЁеӨҙзҡ„ж·ұеәҰеҗҲдҪңеёҰжқҘиө„жәҗж”ҜжҢҒпјҢ第дёүжўҜйҳҹзҡ„жЁЎеһӢеҺӮе•Ҷе·Із»Ҹиҝӣе…ҘеҮәжё…ж—¶жңҹпјҢйғЁеҲҶиў«еӨҙйғЁжЁЎеһӢеҺӮе•Ҷеҗёж”¶еҗҲ并пјҢж•ҙдҪ“з«һдәүж јеұҖ已收ж•ӣгҖӮ
пјҲ4пјүеӣҪеҶ…еӨ§жЁЎеһӢеҺӮе•Ҷдё»иҰҒеҲҶдёәеӣӣзұ»пјҢеҲҶеҲ«дёәдә’иҒ”зҪ‘дә‘еҺӮе•ҶгҖҒеӨ§жЁЎеһӢеҲӣдёҡе…¬еҸёгҖҒжЁЎеһӢжҺЁзҗҶе№іеҸ°еҸҠжҠҖжңҜзұ»еҺӮе•ҶпјҢе…¶дёӯдә’иҒ”зҪ‘дә‘еҺӮе•ҶеңЁжЁЎеһӢгҖҒз”ҹжҖҒе’Ңжё йҒ“дјҳеҠҝеҗ„ж–№йқўжӣҙдёәе…ЁйқўпјҢе…·еӨҮиҫғејәзҡ„з«һдәүеҠӣгҖӮеҜ№дәҺеӨ§жЁЎеһӢеҺӮе•ҶжқҘиҜҙпјҢжЁЎеһӢиғҪеҠӣжңҖдёәйҮҚиҰҒпјҢе…¶ж¬ЎжҳҜз”ҹжҖҒиғҪеҠӣе’Ңжё йҒ“иғҪеҠӣпјҢеӣҪеҶ…дә’иҒ”зҪ‘дә‘еҺӮе•Ҷе’ҢеӨ§жЁЎеһӢеҲӣдёҡе…¬еҸёеқҮе…·еӨҮиҫғй«ҳзҡ„жЁЎеһӢиғҪеҠӣпјҢдә‘еҺӮе•Ҷзҡ„з”ҹжҖҒиғҪеҠӣе’Ңжё йҒ“иғҪеҠӣеҗҢж ·дә®зңјпјҢдјҳеҠҝжӣҙдёәе…ЁйқўпјҢд»ЈиЎЁеҺӮе•ҶеҢ…жӢ¬йҳҝйҮҢгҖҒеӯ—иҠӮгҖҒзҷҫеәҰгҖҒи…ҫи®ҜзӯүгҖӮеӨ§жЁЎеһӢеҲӣдёҡе…¬еҸёд№ҹжӢҘжңүдјҳз§Җзҡ„жЁЎеһӢиғҪеҠӣпјҢдҪҶжҳҜз”ҹжҖҒиғҪеҠӣе’Ңжё йҒ“иғҪеҠӣејұдәҺдә’иҒ”зҪ‘дә‘еҺӮе•ҶпјҢд»ЈиЎЁеҺӮе•ҶеҢ…жӢ¬DeepSeekгҖҒжңҲд№Ӣжҡ—йқўгҖҒжҷәи°ұAIзӯүгҖӮжЁЎеһӢжҺЁзҗҶе№іеҸ°йҖҡеёёдёҚиҮӘе·ұз ”еҸ‘жЁЎеһӢпјҢиҖҢжҳҜж•ҙеҗҲејҖжәҗжЁЎеһӢз”ҹжҖҒпјҢйҖҡиҝҮAPIзӣҲеҲ©пјҢеҰӮзЎ…еҹәжөҒеҠЁгҖҒж— й—®иҠҜз©№зӯүгҖӮдј з»ҹзҡ„жҠҖжңҜзұ»еҺӮе•ҶжӢҘжңүз§ҜзҙҜзҡ„иҫғејәзҡ„жё йҒ“иғҪеҠӣпјҢжЁЎеһӢе’Ңз”ҹжҖҒиғҪеҠӣд№ҹиҫғејәпјҢд»ЈиЎЁеҺӮе•ҶеҰӮе•ҶжұӨ科жҠҖгҖҒ科еӨ§и®ҜйЈһгҖҒжҳҶд»‘дёҮз»ҙзӯүгҖӮ
пјҲ5пјүд»ҘйҳҝйҮҢдёәдҫӢпјҢе…¶дә‘дёҡеҠЎзӣёе…іиҗҘ收еҚ жҜ”жҖ»дҪ“иҗҘ收еңЁйҖҗе№ҙжҸҗеҚҮпјҢдҪ“зҺ°еӨҙйғЁжЁЎеһӢеҺӮе•ҶеңЁжҢҒз»ӯжҠ•е…Ҙиө„жәҗеҗҺпјҢдә‘дёҡеҠЎжҲ–е°ҶжҲҗдёәе…¶ж–°зҡ„еўһй•ҝзӮ№гҖӮ2020е№ҙпјҢйҳҝйҮҢдә‘иҗҘ收仅дёә555.76дәҝе…ғпјҢеҲ°2024е№ҙпјҢе…¶дә‘дёҡеҠЎиҗҘ收зҝ»еҖҚпјҢиҫҫеҲ°1134.96дәҝе…ғпјҢеңЁжҖ»иҗҘ收дёӯзҡ„еҚ жҜ”д№ҹд»Һ8.63%дёҠеҚҮиҮі11.56%пјҢжңӘжқҘдёүе№ҙпјҢйҳҝйҮҢе·ҙе·ҙеңЁдә‘е’ҢAIеҹәзЎҖи®ҫж–ҪдёҠзҡ„иө„жң¬ејҖж”Ҝе°Ҷиҫҫ3800дәҝе…ғпјҢдҪ“зҺ°дәҶеӨҙйғЁдә‘еҺӮе•ҶеҜ№AIзӣёе…іеҹәзЎҖе»әи®ҫзҡ„жҠ•е…ҘдҝЎеҝғпјҢAIдёҡеҠЎжңүжңӣжҲҗдёәеӨҙйғЁдә’иҒ”зҪ‘дә‘еҺӮе•ҶиҗҘ收еўһй•ҝзҡ„йҮҚиҰҒж”Ҝж’‘гҖӮ
пјҲ6пјүз”ұдәҺйҖҡз”ЁеҹәзЎҖжЁЎеһӢйўҶеҹҹз«һдәүиҫғдёәжҝҖзғҲпјҢдёҖж–№йқўпјҢеӣҪеҶ…еӨҙйғЁеӨ§еҺӮе°ҶжҢҒз»ӯжҠ•е…ҘйҖҡз”Ёзұ»дә§е“ҒпјҢз»“еҗҲжё йҒ“е®һеҠӣжү“йҖ з”ҹжҖҒеЈҒеһ’пјҢеҸҰдёҖж–№йқўпјҢйғЁеҲҶжЁЎеһӢеҺӮе•ҶжҲ–е°ҶејҖе§ӢиҒҡз„Ұе•ҶдёҡеҢ–еұӮйқўпјҢиҪ¬еһӢиҮізӣёеҜ№еһӮзӣҙзҡ„з»ҶеҲҶеңәжҷҜиҝӣиЎҢжңҚеҠЎпјҢеўһејәе·®ејӮеҢ–з«һдәүеҠӣгҖӮеӣҪеҶ…第дёҖжўҜйҳҹзҡ„еӨ§жЁЎеһӢеҺӮе•ҶеӨҡж•°з»јеҗҲеёғеұҖпјҢиғҪеӨҹжүҝеҸ—еӨ§йҮҸжҠ•иө„е’Ңй•ҝжңҹдәҸжҚҹзҡ„йў„жңҹпјҢдё”жӢҘжңүдё°еҜҢзҡ„ж¶Ҳиҙ№з«ҜеңәжҷҜе’ҢиҮӘиә«зҺ°жңүдёҡеҠЎдә§е“ҒиғҢд№ҰпјҢеӣ жӯӨжңӘжқҘеӣҪеҶ…йҖҡз”ЁжЁЎеһӢз«һдәүж јеұҖеҗҢж ·е°Ҷ收ж•ӣиҮіз¬¬дёҖжўҜйҳҹзҡ„е°‘ж•°зҺ©е®¶гҖӮеңЁиҝҷж ·зҡ„иЎҢдёҡиғҢжҷҜдёӢпјҢжЁЎеһӢеҲӣдёҡе…¬еҸёжҲ–й’ҲеҜ№Bз«ҜжЁЎеһӢе®ўжҲ·е°ҶиҒҡз„ҰдәҺжӣҙеҠ еһӮзӣҙгҖҒз»ҶеҲҶзҡ„е•ҶдёҡеҢ–еңәжҷҜгҖӮеҜ№дәҺдј з»ҹзҡ„жҠҖжңҜзұ»еҺӮе•ҶжқҘиҜҙпјҢзӣ®еүҚеӨҡж•°еңЁиҮӘиә«е·Іжңүзҡ„жё йҒ“дёӯжңҚеҠЎпјҢеҰӮйғЁеҲҶж”ҝеәңе’ҢиЎҢдёҡеӨ§е®ўжҲ·пјҢжңӘжқҘжҲ–е°Ҷе°қиҜ•е°ҶйҮҚеҝғиҪ¬еһӢиҮіеӨ§жЁЎеһӢгҖӮ