


第一章 绪论:算力-数字经济时代的“热核武器”
1.1 从通用计算到智能计算的范式转移
人类社会正经历着继蒸汽革命、电气革命、信息革命之后的第四次工业革命-智能革命。在这场变革中,算力(ComputingPower)不再仅仅是信息技术的附属品,而是跃升为新的核心生产力,其战略地位等同于工业时代的石油与电力。根据中国信通院(CAICT)与 IDC 的最新研究,全球计算产业正处于从“通用计算”向“智能计算”(Intelligent Computing)加速演进的拐点 。
通用计算以 CPU 为核心,擅长逻辑控制与串行处理;而智能计算则以 GPU、NPU、ASIC 等加速器为核心,专注于处理大规模并行矩阵运算,这是深度学习(Deep Learning)与大语言模型(LLM) 的数学基础。分析显示, 随着多模态大模型(Multimodal Models) 的爆发,算力需求呈现指数级增长,最新的多模态模型在训练和推理阶段对算力的需求是同等规模单模态模型的 2-3 倍 。这种需求的激增导致了全球算力基础设施的重构,原本以 CPU 为中心的服务器架构正在被“CPU+xPU”的异构计算架构所取代。
1.2 地缘政治下的“硅基主权”
当前,AI 算力已不仅仅是技术指标,而是国家综合国力的核心体现,甚至可以说是“硅基主权”的象征。美国通过《芯片与科学法案》及一系列出口管制措施,试图在高端 AI 芯片领域对我国实施“卡脖子”战略,构建起一道“算力铁幕”。这种外部压力倒逼我国必须在底层架构、芯片制造、软件生态及智算中心建设上走上一条独立自主、甚至是非对称竞争的道路 。
本报告将站在产业与技术的最前沿,深度剖析这一变局。我们将不仅关注芯片本身的 PFLOPS(每秒千万亿次浮点运算), 更将视野拓宽至互联带宽、显存容量、软件栈效率以及数据中心的能源效率(PUE), 揭示在这场算力军备竞赛中,我国企业如何通过架构创新与产业链协同,在缝隙中寻求突围。
第二章 标准体系与顶层设计:智算产业的“度量衡”
2.1 全球 AI 标准化博弈
在 AI 算力领域,标准即话语权。国际上, ISO/IEC JTC 1/SC 42 正在加速制定人工智能相关标准,而 ITU-T 则在通信与 AI 融合(AI for Network, Network for AI)方面布局 。
2.2 中国 AI 产业综合标准化体系建设指南(2024 版)深度解读
为应对碎片化的产业现状,工信部等四部门在 2024 年联合发布了《国家人工智能产业综合标准化体系建设指南》(2024 版)。这一顶层设计文件具有极高的战略指导意义, 它不仅是标准的列表,更是产业发展的路线图。
2.2.1 关键标准维度
该指南明确了七大重点方向,其中与智算密切相关的包括:
基础支撑标准: 重点规范智能芯片、智能传感器、算力中心、系统软件等底层设施。这标志着国家层面开始着手解决国产 AI 芯片软硬件接口不统一、互联协议不兼容的顽疾 。关键技术标准: 涵盖了大模型训练、自然语言处理、智能体(Agent)等技术。特别是针对生成式 AI(GenerativeAI), 标准体系强调了安全性与可控性.计算中心标准: 针对智算中心(Intelligent ComputingCenter) 的建设、评测、能效指标(PUE、WUE)制定了明确规范, 旨在遏制各地盲目建设、利用率低下的现象 。
2.2.2 测评基准(Benchmarks)的重构
长期以来,AI 芯片的性能评估主要依赖 MLPerf 等西方主导的基准测试。然而, 随着国产架构的多元化,我国正在构建自主的测评体系。
.AIIA DNN Benchmark: 由中国人工智能产业发展联盟(AIIA)推动, 旨在建立不仅包含峰值算力,还包含实际业务场景(如 CV、NLP 推理延迟) 的综合评价体系 。
CESI 信创标准: 中国电子技术标准化研究院(CESI)正在牵头制定针对国产 AI 芯片的兼容性与性能分级标准,这将成为政府采购和“东数西算”工程选型的关键依据 。
深度洞察: 标准体系的建立标志着我国 AI 算力产业从“野蛮生长”进入“规范化发展”阶段。未来,不符合互联互通标准(如CXL、国产 Chiplet 接口标准) 的芯片企业将被边缘化,而能够主导标准制定的龙头企业(如华为、阿里)将获得更大的生态控制力。
第三章 全球 AI 芯片技术巅峰:以英伟达为锚点
要认清差距与方向,必须首先深度解剖行业标杆-英伟达(Nvidia)。
3.1 Blackwell 架构:不仅是芯片,是平台英伟达在 2024 年推出的 Blackwell 架构(B200/GB200)代表了当前硅基计算的物理极限与系统工程的巅峰 。
3.1.1 核心技术指标突破
晶体管规模与工艺: Blackwell GPU 拥有 2080 亿个晶体管,采用台积电(TSMC)定制的 4NP 工艺。值得注意的是, 它实际上是由两个通过 10TB/s 芯片间互联(C2C)连接的掩模版(Reticle)极限尺寸的 Die 组成的,这验证了“Chiplet”技术在高性能计算中的必然性 。精度革命(FP4): 第二代 Transformer 引擎引入了 FP4 精度支持。相比于 Hopper 架构的 FP8, FP4 将推理吞吐量翻倍,达到 20 PFLOPS。这意味着英伟达通过算法与硬件的协同,在不单纯依赖制程微缩的情况下,实现了算力密度的跃升 。第五代 NVLink: 单个 GPU 的 NVLink 双向带宽达到 1.8TB/s。这使得一个包含 72 个 GPU 的 NVL72 机架可以作为一个统一的逻辑 GPU 运行,总带宽达到 130 TB/s 。
深度洞察: 英伟达的护城河已不再仅仅是 GPU 核心本身,而是互联(Interconnect)。当单芯片性能接近物理极限时,英伟达通过 NVLink Switch 将瓶颈转移到了机柜层面,实际上是将“数据中心定义为芯片”。这种架构使得竞争对手不仅要追赶芯片性能,还要追赶整个集群的网络拓扑能力。
3.2 软件生态:CUDA 的锁定效应
CUDA 生态系统经过 17 年的积累, 已拥有超过 400 万开发者。尽管 AMD ROCm 和 Intel oneAPI 试图突围,但在大模型训练的稳定性、算子库的丰富度以及开发者习惯上, CUDA 仍具有压倒性优势。然而,这种垄断也促使了开源社区(如 OpenAI Triton)和中国厂商加速寻找解耦方案。
第四章 中国 AI 芯片产业全景:技术路线与核心竞争力
面对制裁,我国 AI 芯片产业呈现出“百花齐放、技术路线多元化”的特征。从 GPU、GPGPU 到 DSA(NPU/TPU)、ASIC 乃至类脑计算, 中国企业正在全方位试错与突围。
4.1 华为昇腾(Huawei Ascend): 全栈自主的领头羊
华为是目前中国唯一拥有从芯片、算子库(CANN)、深度学习框架(MindSpore)到大模型(盘古)全栈能力的厂商。
Ascend 910C 分析: 作为针对 Nvidia H100 的对标产品, 910C 在 FP16 算力上据报道已达到 H100 的 60%-80%水平 。
制造工艺: 采用 SMIC 的 N+2(类 7nm)工艺及多重曝光技术。虽然良率(Yield Rate)初期较低(约20%), 但近期已提升至 40%左右,展现了极强的工程迭代能力 。
架构优势: 基于达芬奇(Da Vinci)架构的 3D Cube计算单元,专为张量运算优化。与 GPU 相比,其在特定矩阵运算中的能效比更高,但编程灵活性略逊于GPU。
集群能力: 华为推出了“CloudMatrix”架构,通过高密度的以太网(RoCE)互联替代被禁运的高端InfiniBand,试图用网络规模换取单点性能的不足 。
软件栈 CANN: 华为正致力于将 CANN 开源, 以打破CUDA 的垄断。通过提供类似 PyTorch 的算子接口, 降低迁移成本。深度分析显示, DeepSeek 等国内头部模型厂商已开始针对 Ascend 架构进行原生优化,这是生态成熟的关键信号 。
4.2 寒武纪(Cambricon): 云边端一体化
寒武纪作为中科院背景的“国家队”,坚持通用的智能处理器指令集(MLU ISA)。
思元(Siyuan) 590/690: benchmarks 显示,思元 590在部分稠密训练任务中能达到 Nvidia A100 80%的性能 。思元 690 则瞄准 H100 级别。
生态位: 寒武纪在“云边端”一体化上具有优势,其推理卡在国产服务器中占有率较高。尽管连年亏损,但在 2024 年Q3 首次实现季度盈利,证明了国产替代的市场需求足以支撑其生存 。
4.3 摩尔线程(Moore Threads): GPU 路线的坚守者
由前英伟达高管创立,摩尔线程走的是全功能 GPU(MUSA 架构)路线,兼顾图形渲染与 AI 计算。
MTT S4000: 拥有 48GB 显存, FP32 算力 25 TFLOPS。其最大的亮点是 MUSIFY 工具,号称能实现 CUDA 代码的“零成本”迁移 。这对于拥有大量 CUDA 存量代码的客户极具吸引力。
万卡集群(KUAE): 摩尔线程发布了 KUAE 智算中心解决方案, 旨在解决国产 GPU 大规模集群并联难的问题,对标英伟达 SuperPOD 。
4.4 海光信息(Hygon): x86 生态的延伸
海光 DCU(Z100 系列)源于 AMD 授权的 GCN 架构,属于GPGPU 路线。
深算一号/二号: 其最大优势在于对 ROCm 生态的兼容性,使得基于开源生态的迁移相对容易。在科学计算(HPC)和AI 混合负载场景中表现优异 。
4.5 存算一体与光计算:换道超车的新势力
除了传统电子芯片, 中国在后摩尔时代的颠覆性技术上布局激进。
存算一体(Computing-in-Memory):像知存科技(Witmem)、SynSense(时识科技)等初创企业,利用存储单元直接进行计算,消除了冯·诺依曼架构的“存储墙”问题,在端侧 AI 能效上实现了数量级的提升 。
. 光计算(Optical Computing): 曦智科技(Lightelligence)等公司探索利用光子进行矩阵运算,具有超低延迟和超低功耗的特点,有望在未来 6G 通信与计算融合场景中发挥关键作用 。
4.6 关键性能指标对比与供需分析
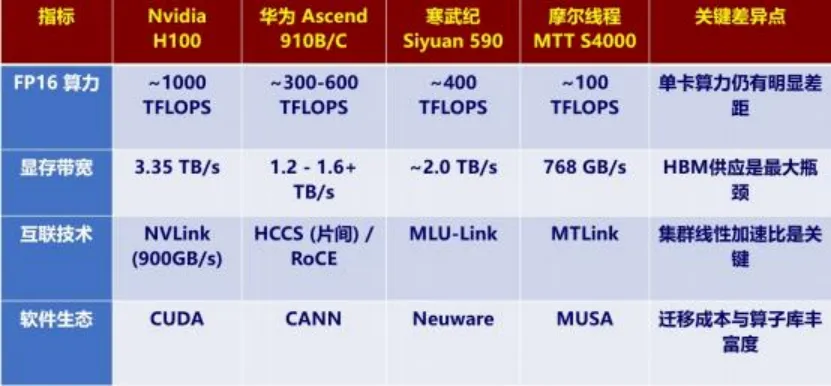
供需矛盾分析: 目前我国算力市场存在严重的结构性矛盾。
1. 高端短缺: 用于万亿参数大模型训练的高端算力(如H100/B200 级)极度匮乏, 国产芯片产能受限于 CoWoS 封装和 HBM 良率,无法完全满足头部互联网厂商的需求 。
2. 中低端过剩: 各地政府主导建设的智算中心大量采购了中低端国产算力,但由于软件生态不完善,实际利用率( Utilization Rate)并不高,部分甚至处于闲置状态 。
第五章 智算中心:数字经济的“新基建”与商业化困局
5.1 全球与中国智算中心建设现状
全球范围内,智算中心主要由 Google、Microsoft、Meta 等超大规模云厂商(Hyperscalers)主导,其特点是高度定制化、软硬协同优化。 相比之下,我国的智算中心建设呈现出鲜明的“政府引导、国企主导”特征。截至 2024 年中,我国已建设或规划了超过 250 个智算中心 。
5.2 “东数西算”与算力调度
我国实施了宏大的“东数西算”工程, 旨在将东部密集的算力需求引导至能源丰富的西部地区。
挑战: 训练任务(对延迟不敏感)可以西迁,但推理任务(要求低延迟)必须靠近用户。这就要求建立国家级的算力调度网(Computing Power Network), 像调度电力一样调度算力 。
进展: 中国电信等运营商已发布了全国算力调度平台,尝试解决异构算力并网的难题 。
5.3 商业化落地与存在的问题
核心痛点:利用率与生态隔离。 很多智算中心虽然硬件指标达标,但缺乏成熟的 Model-as-a-Service(MaaS)服务能力。企业用户不仅需要裸金属服务器,更需要好用的工具链和模型服务。
补贴模式: 为解决国产芯片“难用、贵”的问题,各地政府推出了“算力券”(Compute Vouchers)政策,补贴企业使用国产算力,人为降低使用门槛 。
商业模式转型: 从简单的“出租机柜”向“出租 Token”转型。智算中心开始与大模型厂商绑定,通过预置 DeepSeek、 ChatGLM 等模型,提供 API 服务 。
第六章 产业链深水区:制造、封装与存储的攻坚战
我国 AI 芯片能否突围,不取决于设计能力,而取决于制造与封测的供应链韧性。
6.1 HBM:存储墙的翻越
HBM(高带宽内存)是 AI 芯片的“肺活量”。目前全球 HBM市场被 SK 海力士、三星、美光垄断。
国产化进展: 长鑫存储(CXMT)正引领国产 DRAM 技术突破,并尝试推进 HBM2/3 的量产。但受限于光刻机与量测设备,产能爬坡缓慢 。
替代方案: 在 HBM 受限的情况下,部分国产芯片转向使用大容量 GDDR6 或尝试 3D 混合键合(Hybrid Bonding)技术(如长江存储的 Xtacking 技术延伸), 试图在封装层面解决带宽问题 。
6.2 先进封装:CoWoS 的国产化替代
台积电的 CoWoS 产能是全球 AI 芯片出货的最大瓶颈。我国拥有世界级的封测厂商-长电科技(JCET)和通富微电(Tongfu)。
技术突破: 国内封测厂正在大力发展 2.5D/3D 封装技术,利用 Chiplet 架构将多颗 7nm/14nm 芯片互联, 以面积换性能,绕过单一高端制程的限制。这被称为“先进封装救国”路线 。
6.3 EDA 工具:设计的底座
华大九天(Empyrean) 已实现数字电路设计全流程工具的覆盖,特别是在 7nm 及以上工艺节点上具备了较完善的支持能力, 降低了国产 AI 芯片设计的门槛和被断供风险 。
第七章 面向未来:6G 与 AI 的深度融合
未来的算力将不再局限于数据中心,而是弥漫在网络之中。我国在 6G 领域的布局,为 AI 算力提供了全新的想象空间。
7.1 原生智能网络(AI-Native Network)
ITU 发布的 IMT-2030(6G)框架中, 明确提出“泛在智能” (Ubiquitous Intelligence)是 6G 的核心能力之一 。这意味着 AI推理和训练功能将下沉到基站和网络边缘。
空天地一体化: 中国移动和中国电信已发射 6G 架构验证卫星,测试星地一体化的算力协同。未来,卫星网络将成为全球分布式 AI 计算的一部分 。
7.2 频谱优势
我国率先将 6GHz 频段(6425-7125 MHz)全部分配给 IMT (移动通信), 而非像美国那样分配给 Wi-Fi。这为 6G 广域覆盖和高带宽 AI 数据传输预留了宝贵的“黄金频段”,可能使我国在 6G时代的 AI 网络基础设施上再次领先 。
7.3 语义通信(Semantic Communication)
我国研究团队已在现网中测试基于 AI 的语义通信技术,通过传输信息的“含义”而非比特,实现了在低带宽下传输高质量 AI 内容,这对于解决算力中心之间海量数据传输的带宽瓶颈具有革命性意义 。
第八章 结论与展望:构建具有韧性的算力生态
8.1 核心观点总结
1. 脱钩已成定局, 自主是唯一出路: 幻想供应链缓和是不切实际的。我国 AI 芯片必须做好长期在“非最先进工艺”下通过架构创新(Architecture)和系统工程(SystemEngineering)来提升竞争力的准备。
2. 算力基建化,服务化: 智算中心将像电网一样,成为社会公共品。未来的竞争在于谁能提供更廉价、更易用、更绿色的Token。
3. 软件生态决定生存: 硬件差距可以通过堆料弥补,软件差距则需要时间与人才。CANN、MUSA 等国产软件栈的成熟度, 以及与 PyTorch 等主流框架的融合度,将决定国产芯片的生存。
8.2 攻关方向建议
技术层面: 加大对 Chiplet 互联标准、存算一体、光互联等颠覆性技术的投入,在摩尔定律停滞的时代寻找新赛道。
产业层面: 推动“算力-算法-数据”闭环。鼓励国产大模型优先适配国产芯片,通过大规模应用场景(如自动驾驶、智慧城市)反哺芯片迭代。
政策层面: 优化补贴政策,从“补建设”转向“补应用”,坚决剔除低效、重复建设的伪智算中心。
结语:
在这场关乎国运的算力竞赛中,我国虽然面临严峻的外部封锁,但拥有全球最大的应用场景、最完备的基础设施建设能力和庞大的工程师红利。通过“以网强算”、“软硬协同”和“举国体制”的独特优势,我国有望在硅基主权时代构建起一套独立于西方之外、且具备强大生命力的智能计算生态系统。这不仅是技术的突围,更是文明演进路径的探索。
巴特星球是一个专注于AI的创新社区,以AI为生产工具、数据为生产资料,结合WEB3新型生产关系共建共享共创社区,欢迎大家参与AI大模型开发应用+学习交流+兼职创业+社区运营,抱团取暖!社区的愿景是利用AI技术让大家自由公平的享受科技带来的优势,让用户享受AI带来的颠覆性价值红利!
“巴特AI星球学习交流群”知识星球内容架构如下,每周持续上新行业最新资料,付59加入知识星球社区成为会员后,随时可享如下权益:
1、可浏览,学习和下载该星球上的任意AI教程;
2、欢迎对Web3,AIGC大模型,智能体和分布式ai云平台开发等感兴趣的小伙伴加入我们社区一起进行学习和交流;
3、招募社会大使,校园大使和合作伙伴;
社区助手微信:13940498192
