


量:GPU与ASIC(专用集成电路)需求正经历快速放量,机构普遍预计26年ASIC出货量或实现对英伟达GPU的赶超。
据Marvell预测,定制加速芯片市场规模将从23年的66亿美元增至28年的554亿美元,期间复合增速53%,占加速芯片市场的份额将从16%升至25%。自研ASIC旨在优化成本、管控供应链风险,并向更高能效、更低功耗及更广泛的应用场景发展。
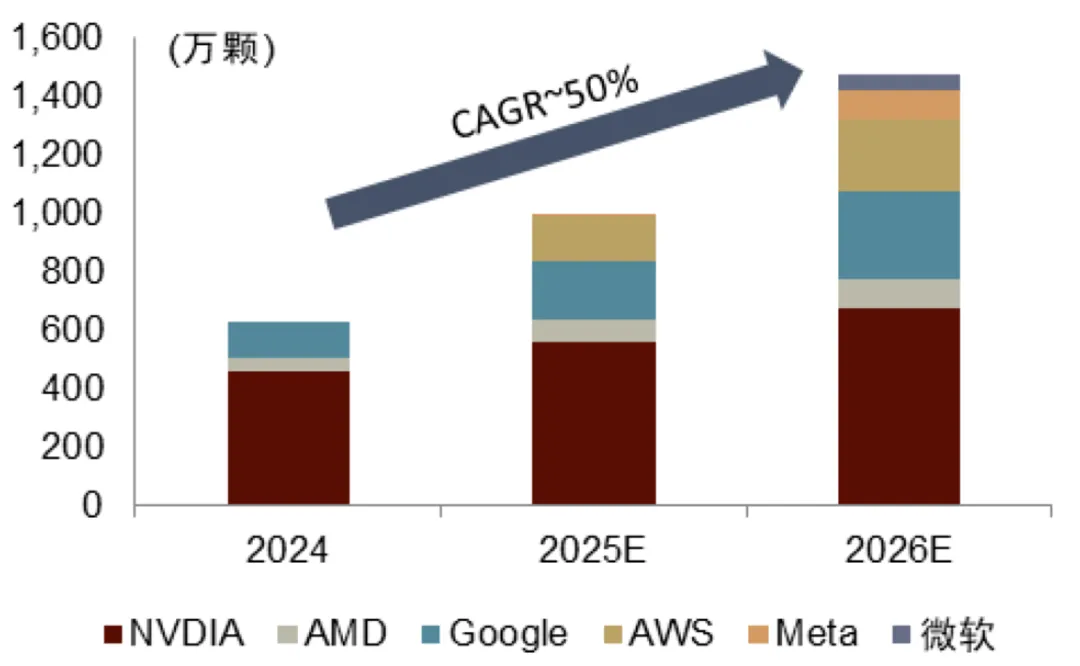
图表. 主要企业GPU和ASIC出货量预测
资料来源:各公司公告、中金公司研究部
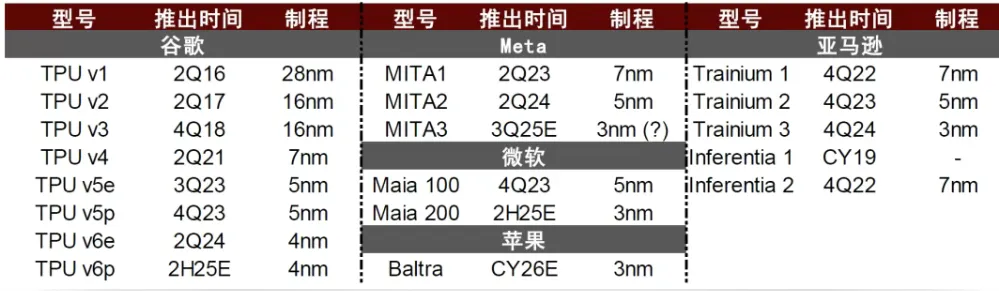
图表. 主要科技企业自研AI芯片进展
资料来源:各公司官网、The Information、中金公司研究
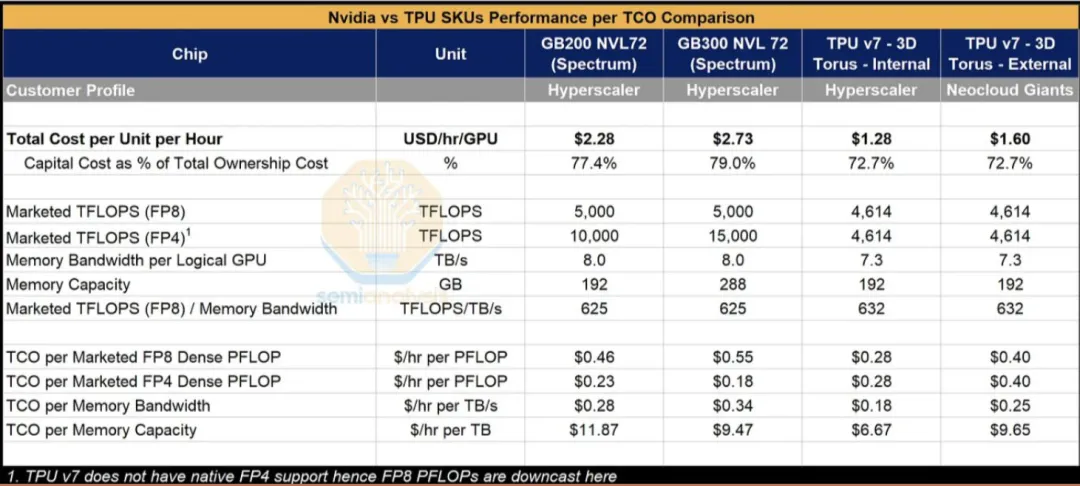
图表. 谷歌TPU v7与英伟达GB200、GB300的总拥有成本TCO对比
资料来源:Semianlysis
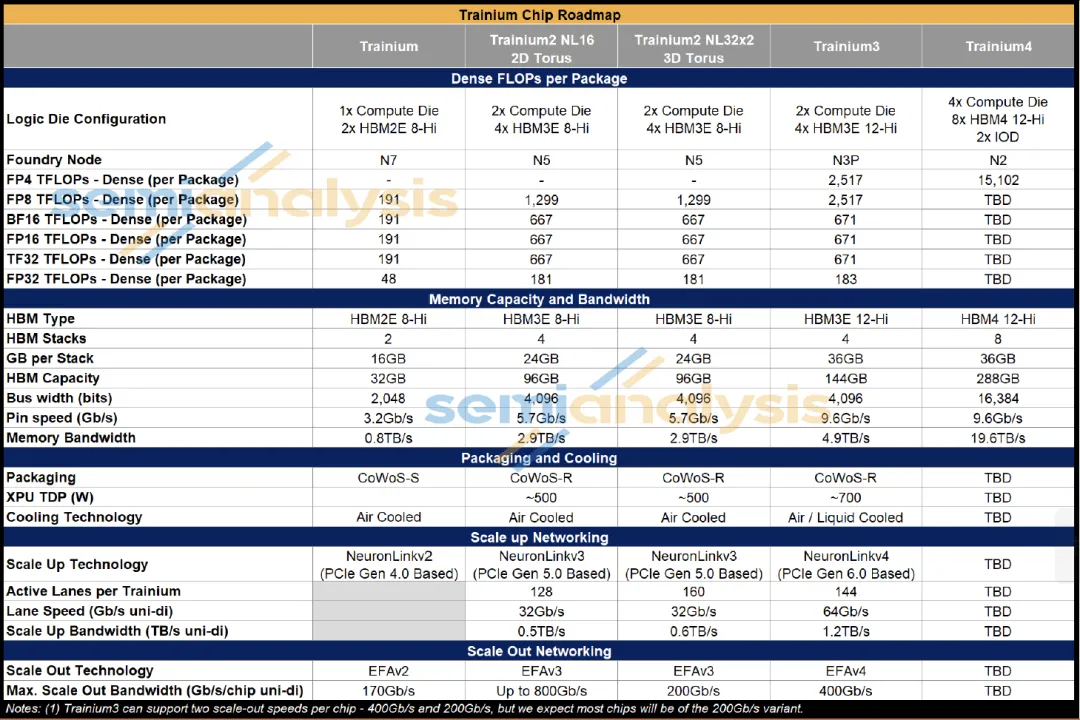
图表. 亚马逊Trainium系列升级路线图
资料来源:Semianlysis
参考彭博一致预期及公司指引,北美头部云服务提供商(CSP)预计25年总资本开支(含融资租赁)将增至约3661亿美元,同比+47.4%,26年有望保持16.4%的增速至4262亿美元。据TrendForce,预计26年AI 服务器出货量同比+20%以上,占服务器市场比重升至17%。
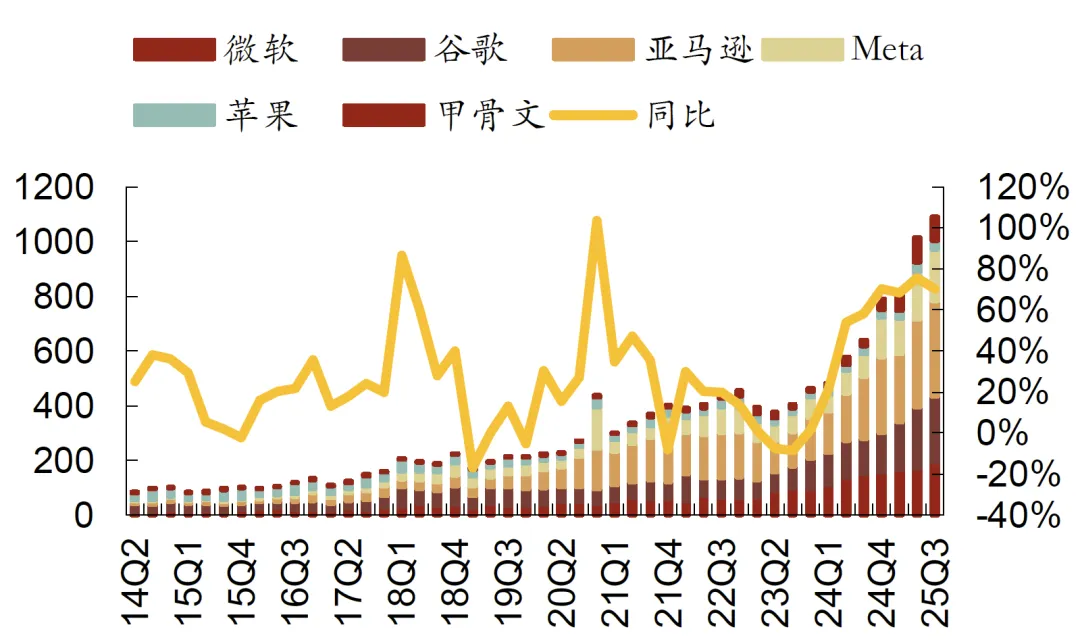
图表. 全球主要互联网厂商资本开支情况(单位:亿美元)
资料来源:彭博、公司公告、招商证券
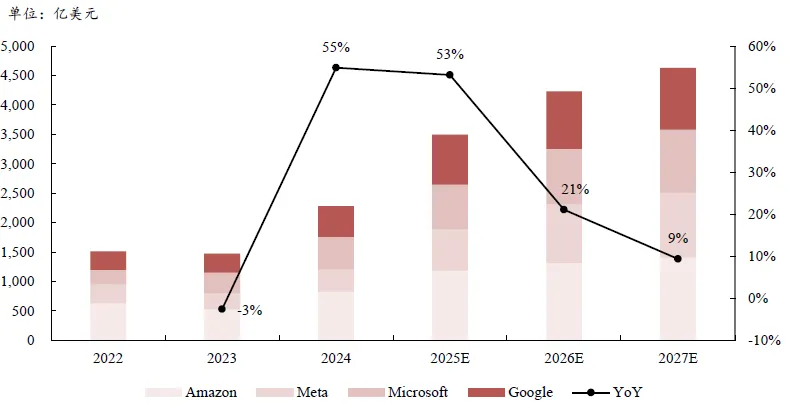
图表. 北美科技巨头资本开支展望(单位:亿美元)
资料来源:彭博、中银证券
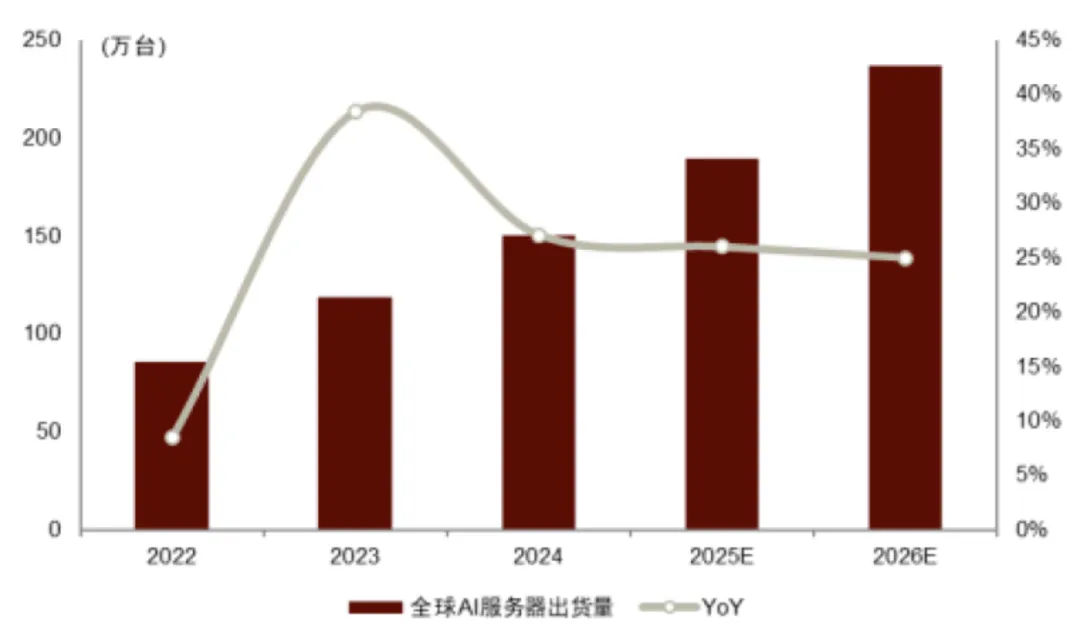
图表. 2022-2026年AI服务器出货量
资料来源:Prismark、中金公司研究部
价:伴随AI芯片尺寸增大、算力密度与功耗持续上升,对介电常数、介质损耗及散热性能的要求愈发严苛。在此趋势下,高频高速材料(如M9、石英布等)的应用及高多层/高阶设计,PCB的单板价值量预期显著上行。此外,正交背板、CoWoP等新技术的推广普及,预计将成为后续增长的关键动力。

图表. 英伟达AI GPU产品路线
资料来源:2025 GTC
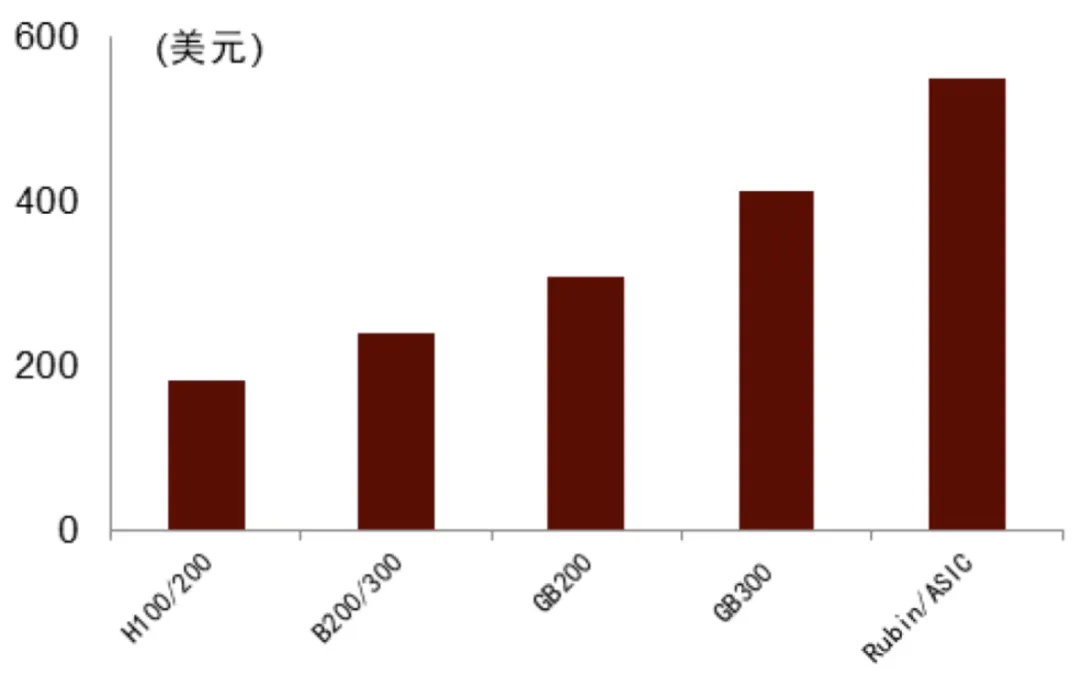
图表. GPU与ASIC的PCB单卡价值量持续提升
资料来源:各公司公告、中金公司研究部
注:不同机构的测算差异较大,观察趋势为主
依据中金测算,
1)H100/H200系列服务器PCB价值量约1.1万元,单服务器8颗GPU,单GPU对应PCB价值量约1318元(183美元);
2)B系列主要变量为OAM(OCP Accelerator Module)加速卡采用M7材料5阶HDI(High Density Interconnector高密度互联),单价提升,UBB(Universal Baseboard)与CPU主板部分价值量基本持平,对应整体PCB价值量约1.4万元,较前代+31%,单服务器8颗GPU,单GPU对应PCB价值量约1728元(240美元);
3)GB200 NVL72转为机柜设计,高密度互连实现72个GPU的协同计算。不同于传统架构使用PCIe交换芯片或重定时器(Retimer)连接CPU与GPU,Blackwell架构通过NVLink-C2C将1颗Grace CPU和2颗B200 GPU直接焊接在同一PCB(Bianca板)上,显著提升计算效率。
测算GB200 NVL72单机柜PCB价值量约16万元,单GPU对应PCB价值量为2224元(309美元)。

图表. GB200 Compute tray计算托盘示意图(2块Bianca板,含1颗CPU+2颗GPU)
资料来源:Semianalysis

图表. GB200 Switch tray交换托盘示意图
资料来源:Semianalysis
4)GB300 NVL72 的计算托盘包含一块UBB板承载2颗CPU+4个SXM puck插槽(4块OAM板)、4块Connect X-7/8网卡板及Bluefield3 DPU板,单Switch tray无较大改动。单机柜PCB价值量约21.4万元,单GPU对应PCB价值量为2973元(413美元),较GB200增长约34%。

图表. GB300 Compute tray计算托盘示意图
资料来源:ServeTheHome

图表. GB300 Switch tray交换托盘示意图
资料来源:ServeTheHome
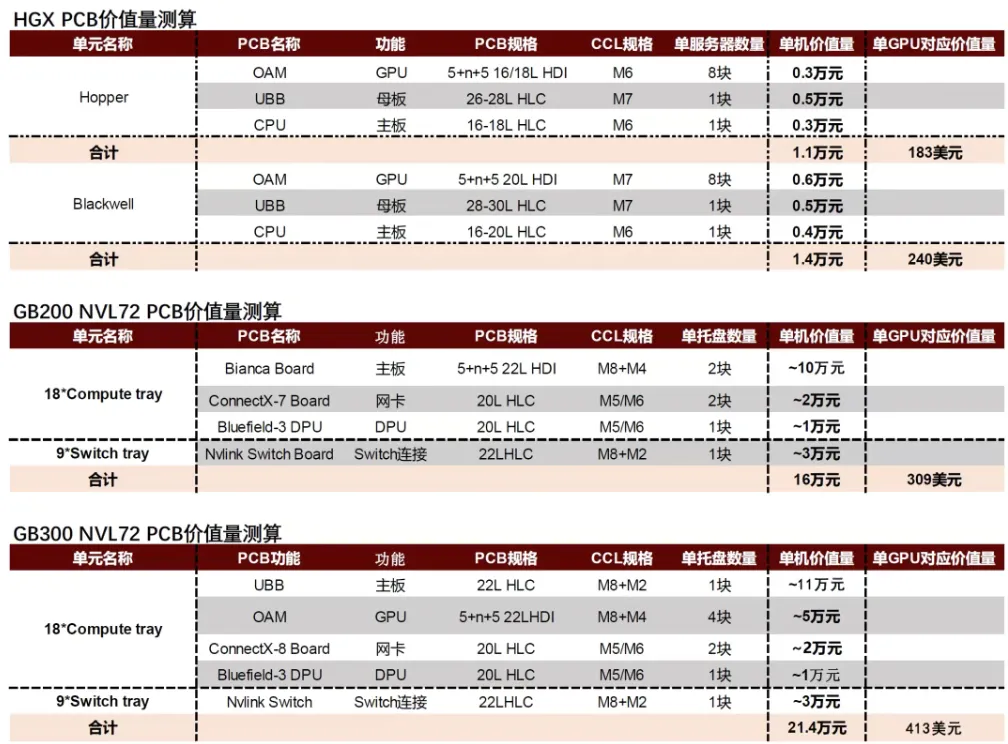
图表. HGX、GB200 NVL72、GB300NVL72 PCB价值量测算
资料来源:Semianalysis、中金公司研究部
5)Rubin架构采用无缆化设计,柜内PCB需求预计大幅上行:基于台积电3nm工艺与HBM4显存,单GPU在FP4精度下算力达50PFLOPS,结合Vera CPU构成融合算力引擎。该架构采用全无缆化与100%全液冷设计,核心配置包括2颗Vera CPU(定制Arm架构,88核176线程,互连速度1.8TB/s)与8颗Rubin GPU(FP4算力最高50 PFLOPS,单颗配备288GB HBM4内存),并集成BlueField-4数据处理器。平台支持14.4TB/s NVLink与800GB/s ConnectX-9,显著提升数据传输与外设兼容性。
性能方面,平台FP8训练能力1.2 ExaFLOPS,较前代GB300 NVL72提升3.3倍;配套HBM4内存带宽13 TB/s,快速内存容量75TB,提升60%;NVLink与CX9速率分别达260TB/s与28.8TB/s,均为前代两倍。
Rubin在26年的升级中,通过无缆化设计与硬件集成度的提高,显著提升了单GPU对应的 PCB 与覆铜板(CCL)价值量。
依据券商产业链跟踪信息,Computer Tray新增以40层以上、M9+Q布材料的中板(Midplane),以替代原有的短铜缆。同时,因集成额外8个GPU,该部分新增4块5阶22层HDI板,同样为M9+Q布材料。Computer Tray与Switch Tray之间计划采用PCB背板进行互连,目前该方案正处于测试打样阶段。
此外,Computer与Switch主板在层数与 HDI 阶数上均升级:Computer主板将采用M8+二代布方案,Switch主板则将在M8.5+二代布或M8.5+Q布方案中选择。整体板材规格较上一代实现全面升级,单GPU对应的PCB、CCL价值量预期大幅提升。GFHK预计VR200单GPU PCB成本将升至1050美元。
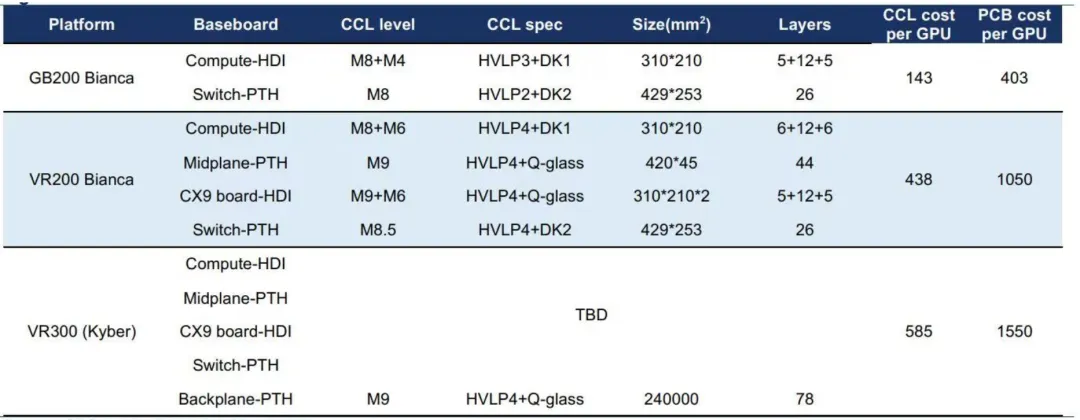
图表. GB200、VR200、VR300价值量测算
资料来源:GFHK
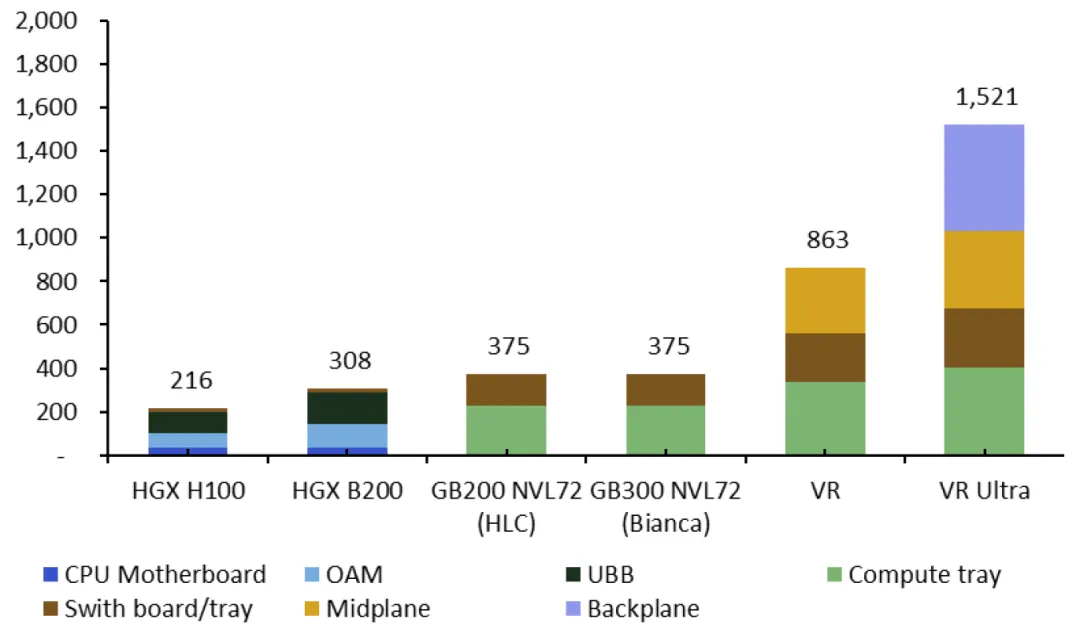
图表. 英伟达各代单GPU的PCB价值量测算
资料来源:花旗

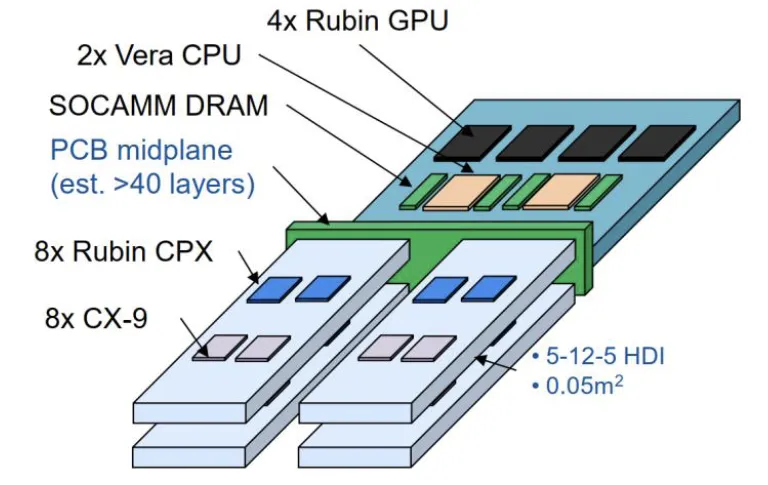
图表. 英伟达Rubin NVL144 CPX计算托盘
资料来源:英伟达、Prismark
GFHK 26年1月研报:预计在接下来的2-3年内,PCB扩展将成为Nvidia和ASIC平台的必然趋势。ASIC方面:1)AWS的T3液体冷却版本将采用与英伟达类似的oberon架构,每个机架包含9个计算托盘和9个交换机托盘,PCB/CCL内容仍在持续增长;2)Meta的Minerva将利用背板来连接L形计算托盘和交换机刀片;3)谷歌:正着手从27年V8p开始添加基于M9的交换机托盘。该方案预计将在26年Q1末敲定。
英伟达方面:基于M9 CCL的两款Rubin主板(包括中板和CPX板)将于26年Q1逐步投入生产。另一方面,Kyber产品线将引入背板技术,采用Q布 M9 解决方案。近期背板方面的研发工作已显示出显著的改进效果,对即将到来的1月测试结果持乐观态度。
上游材料关注M9、HVLP4铜材、PCB钻头(高使用率和价格上调)。
26年1月CES演讲更新:Vera Rubin已投入量产,由6类芯片实现协同,
1)Vera CPU:2270亿个晶体管,支持1.8 TB/s的NVLink-C2C连接、1.2 TB/s的LPDDR5X和1.5 TB系统级存储(3X Grace);
2)Rubin GPU:3360亿个晶体管,HBM4带宽达22 TB/s(2.8X Balckwell),单GPU NVLink互连带宽3.6 TB/s(2X Balckwell);
3)CX9(超级网卡):200G PAM4 Serdes的800Gb/s以太网连接,230亿个晶体管;
4)Bluefield-4 DPU:1260亿个晶体管,800Gb/s网卡速率,是BF3的2X Networking、6X Compute、3X存储带宽。
5)NVLink 6交换机芯片:400G Serdes,1080亿个晶体管,Scale-Up Fabric 3.6TB/s,连接18个compute nodes、72个Rubin GPU。
6)Spectrum-X以太网CPO:放置于rack顶部,102.4Tb/s Scale-Out交换架构,封装200G硅光,128个800Gb/s接口或512个200Gb/s接口,3520亿个晶体管。

图表. 英伟达Rubin六颗芯片
资料来源:英伟达
VR平台继续沿用NVL72机架设计与出货方案,机架背部部署约5000根铜缆(总长约2英里),自上而下布线,支持400GB/s传输速率。Rubin机柜的晶体管数量增至上一代的1.7倍,峰值推理性能提升5倍,训练性能提升3.5倍。
计算板集成约1.7万个组件,AI算力100 PFLOPS(为Blackwell的5倍),采用全液冷设计,无电缆、软管或风扇。每板搭载8个CX9、2个Vera CPU及4个Rubin GPU。组装时间从上一代的2小时缩短至5分钟,自动化效率显著提高,供电、散热、互联不再是后期拼装组件,而是在系统设计初期被纳入整体架构,降低系统复杂度,提升性能与可靠性。
存储系统采用英伟达Context Memory存储平台,为独立机架,每8个计算机架配置1个存储器架,新增16TB内存。存储架构已重新设计,层级依次为HBM、内存、机架SSD、网络SSD。


图表. 英伟达Vera Rubin计算托盘
资料来源:英伟达、花旗
PCB市场规模预测:据Prismark,24年PCB全球产值735.65亿美元,同比+5.8%,传统业务需求复苏缓慢,但AI领域服务器与交换机等需求强劲。Prismark上修25年全球PCB市场规模预计将+15.4%至848.9亿美元,增量围绕AI,包括AI服务器、高速互联所需的高阶HDI、高多层板、先进封装载板等,预计24-29年全球PCB产值复合增速或达8.2%。
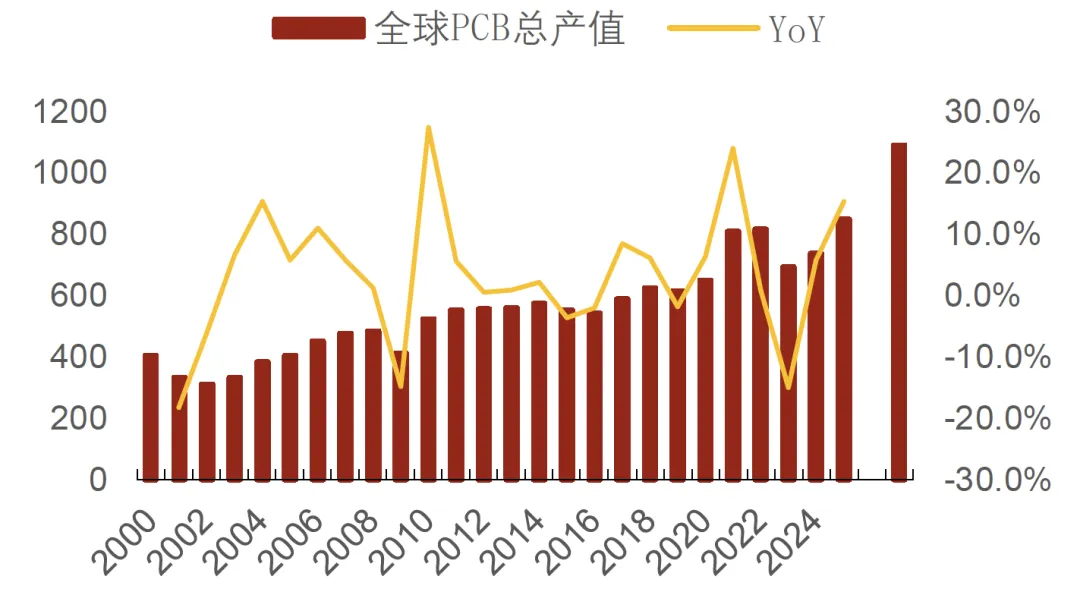
图表. 2020-2029年全球PCB市场规模(单位:亿美元)
资料来源:Prismark、招商证券
细分层面,Prismark预计服务器用PCB于25年市场规模约159.75亿美元,同比+46.3%,至29年将达257.29亿美元,期间复合增速18.7%;有线侧网通(交换机、光模块等)PCB于25年市场规模约83.9亿美元,同比+36.3%,至29年将达127.59亿美元,期间复合增速15.7%
GFHK预测AI PCB市场TAM将在25-27年达到284亿、898亿、1844亿人民币,供给过剩风险有限。
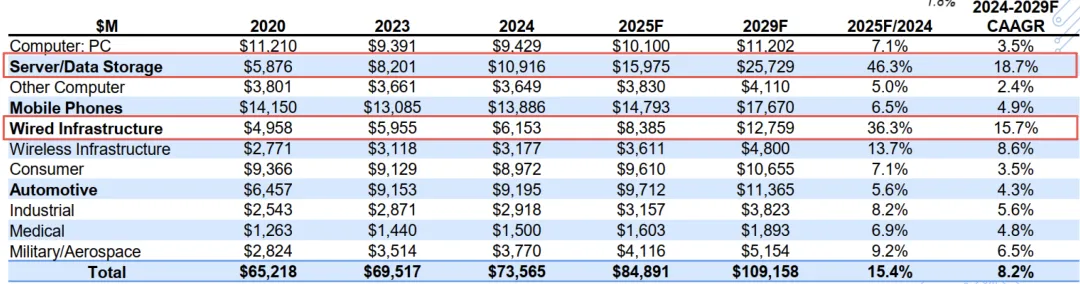
图表. 2020-2029年PCB细分领域市场规模预测
资料来源:Prismark
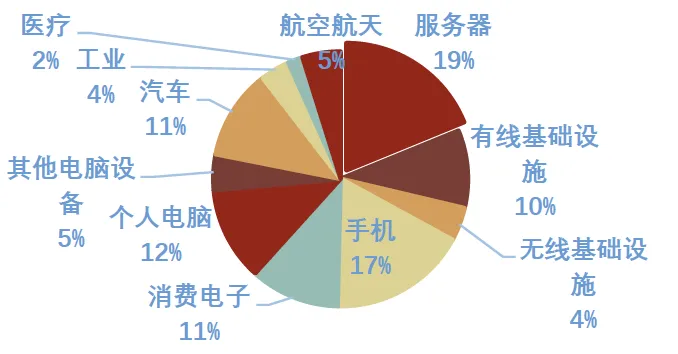
图表. 25年全球PCB按下游应用分市场规模占比(预估)
资料来源:Prismark、招商证券
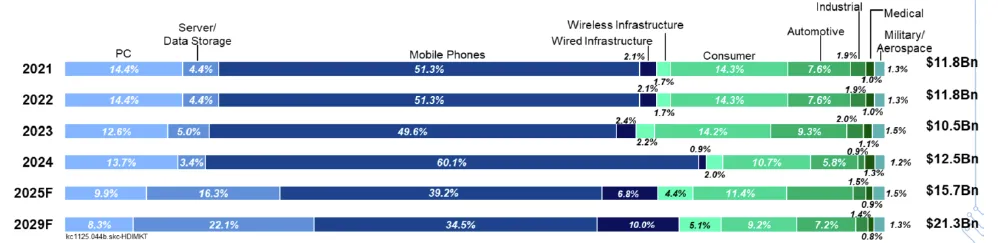
图表. 全球HDI按下游应用领域结构及展望
资料来源:Prismark
产能利用率:依据招商证券,25年H2多数厂商产能利用率在95%左右,同环比双升,Q3在93%-97%之间,头部企业对26年展望保持乐观,下游订单能见度普遍在3个月以上,积极拓展IC载板、高多层板、HDI等高端产能。
2.行业发展趋势
1)行业向高多层板、HDI等方向升级
AI要求在有限的空间内集成高速信号传输、高密度和高可靠性,推动PCB向高性能、高层、高复杂及HDI方向升级,加工难度同时提升。
AI服务器PCB层数从8-16层升至20层以上,并需使用超低损耗材料(Df≤0.005),运用多层导电层与绝缘材料交替压合层间通过金属化孔实现电气连接,结合精密背钻、树脂塞孔等先进工艺。
高多层加工步骤较HDI较少,将铜箔、半固化片(PP)与内层芯板交替叠层后真空热压成型,再进行机械/激光钻孔、沉铜电镀及图形转移,难点在于压合偏移、高精度内层图形加工及微孔加工缺陷。
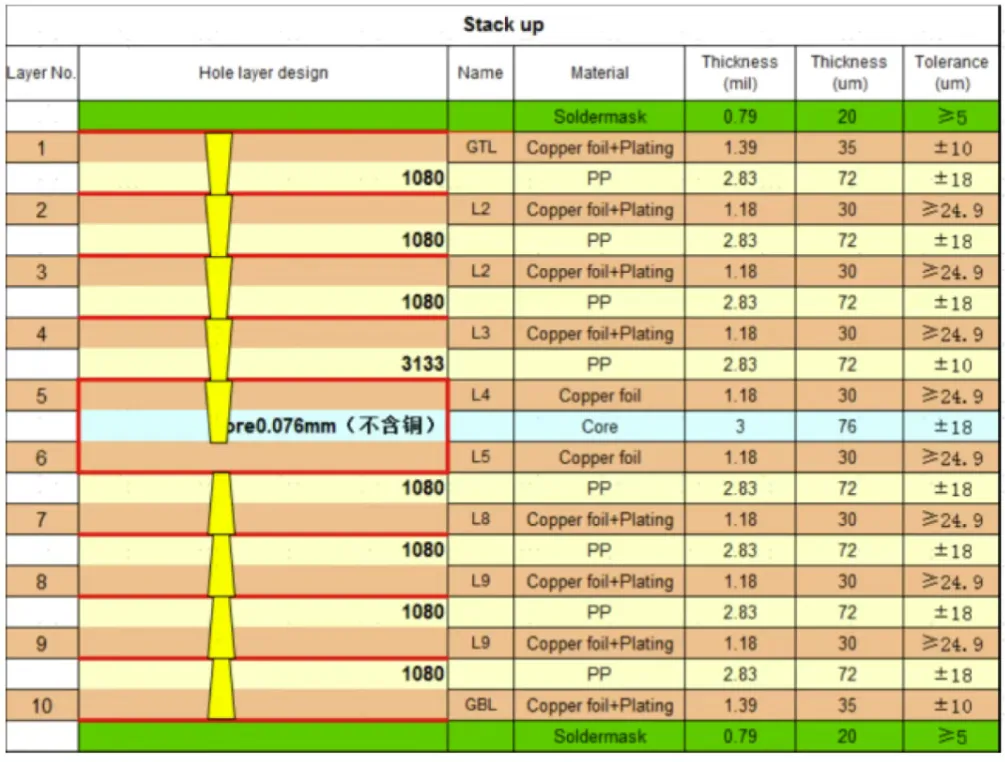
图表. 多层通孔板示意图
资料来源:深泽电路官网
高阶HDI通常在3阶以上,相较高多层,HDI难度更高、成本更高、良率低,其工艺核心在于通过微孔(孔径≤100μm)、盲埋孔及任意层互连技术,实现超高布线密度(线宽/线距≤50μm),以满足高集成度设备需求。制造需多次循环“激光钻孔-电镀填孔-层压”流程,每轮循环增加一层互连,最终形成高阶堆叠,且必须采用低介电常数(Dk≤3.8)、低损耗因子(Df≤0.005)的基材。
HDI加工难点包括:层压偏移与翘曲;盲孔对位精度要求苛刻;微孔电镀空洞率高;成本高且良率承压,依赖高价的日本(三菱电机)/德国(Schmoll)激光钻孔设备,且多次层压会累积并放大加工误差,推高成本、压低良率。
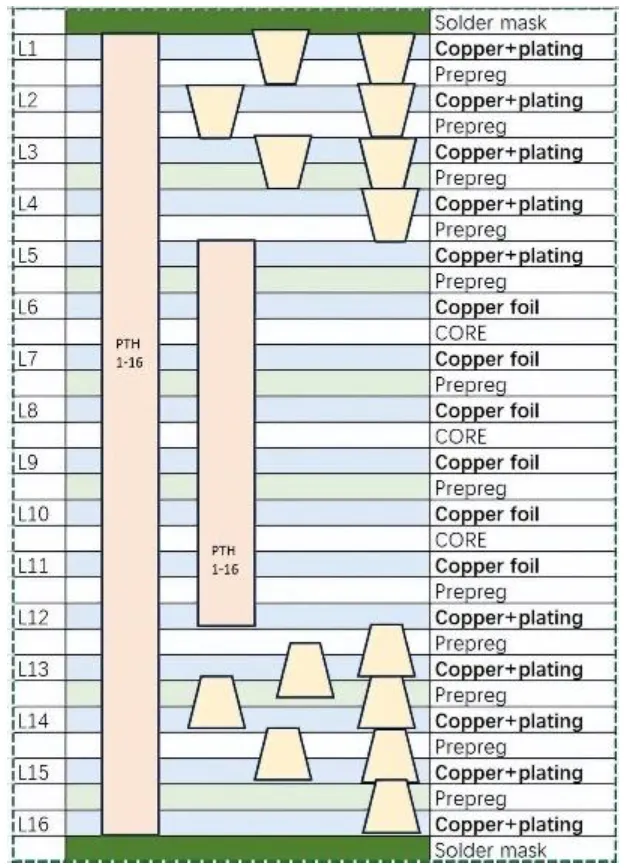
图表. 高阶HDI示意图
资料来源:马路科技官网
预期高多层与HDI技术路线在不同应用场景中协同发展、持续并存:HDI虽可实现更高加工密度,但高多层有散热性能佳、高速信号完整、综合成本较低等优势。例如,7阶26层AI GPU加速卡用HDI板采用M7级CCL材料,需经历7次激光钻孔与压合工序。相较于低阶HDI,其加工步骤显著增加,工艺复杂性及良率控制难度大幅提升。

图表. 7阶26层AI 服务器GPU加速卡HDI 截面图
资料来源:《AI服务器GPU加速卡PCB制作关键技术》
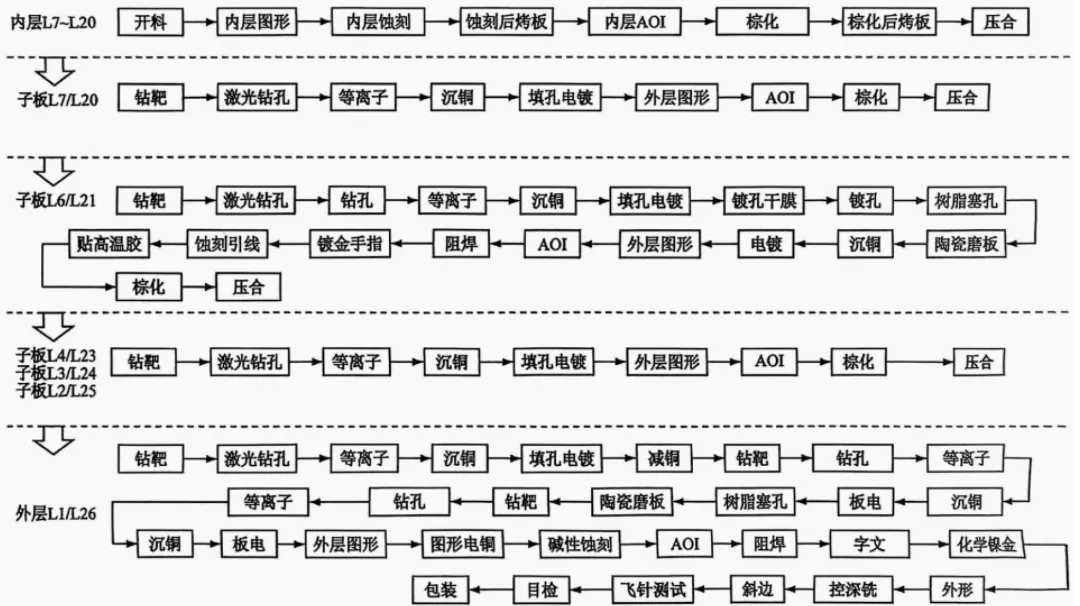
图表. 7阶26层AI 服务器GPU加速卡HDI加工流程
资料来源:《AI服务器GPU加速卡PCB制作关键技术》
据产业链调研,不同阶数HDI的产能消耗有明显差异,例如,2阶与5阶HDI的产能消耗比约为1:5。据高盛,估测27年AI服务器应用中30层以上多层板的占比或达16%,6 层以上HDI占比或达23%,M9及以上CCL的占比或达14%。高端产品预计会对产能形成显著占用,良率或被整体拉低。
高端玻纤布产能紧张:存在产能缺口,关注相关公司,或促使产业更倾向使用材料更少的HDI方案。
招商证券粗略估算26年国内AI PCB产能约1200亿,需求端约1500亿(Prismark预测在1700亿),仍存缺口。
高盛近期大幅上修预测,25-27年全球AI服务器PCB市场规模预计合计为47.1亿美元、100.2亿美元、271.2亿美元(此前预估170亿美元),其中GPU服务器应用PCB规模为22.4亿美元、44.9亿美元、158.9亿美元;ASIC应用PCB规模为24.6亿美元、55.2亿美元、112.4亿美元。
增速最快的PCB细分为OAM加速器模组与Switch Board交换板,对应26年预期增速为115%、181%,对应27年预期增速为223%、299%。至27年,GPU服务器PCB中各部分价值量占比为OAM 42%;UBB基板4%;Mainboard主板1.2%;Midplane中板8%;Backplane背板12%;交换板31%。
CCL层面,25-27年全球市场规模预计为24.0亿美元、58.0亿美元、187.0亿美元(此前预估80亿美元),其中GPU服务器应用规模为12.5亿美元、27.3亿美元、117.3亿美元;ASIC应用规模为11.5亿美元、30.8亿美元、69.7亿美元。
增速最快的CCL细分同样为OAM加速器模组与Switch Board交换板,对应26年预期增速为152%、180%,对应27年预期增速为330%、313%。
至27年,PCB多层板结构占比拆分:小于20层8%,20-30层53%,30层以上39%;HDI结构占比拆分:4+N+4占比2%,5+N+5占比63%,6+N+6占比34%。至27年AI CCL中M9及以上占比或达45%。
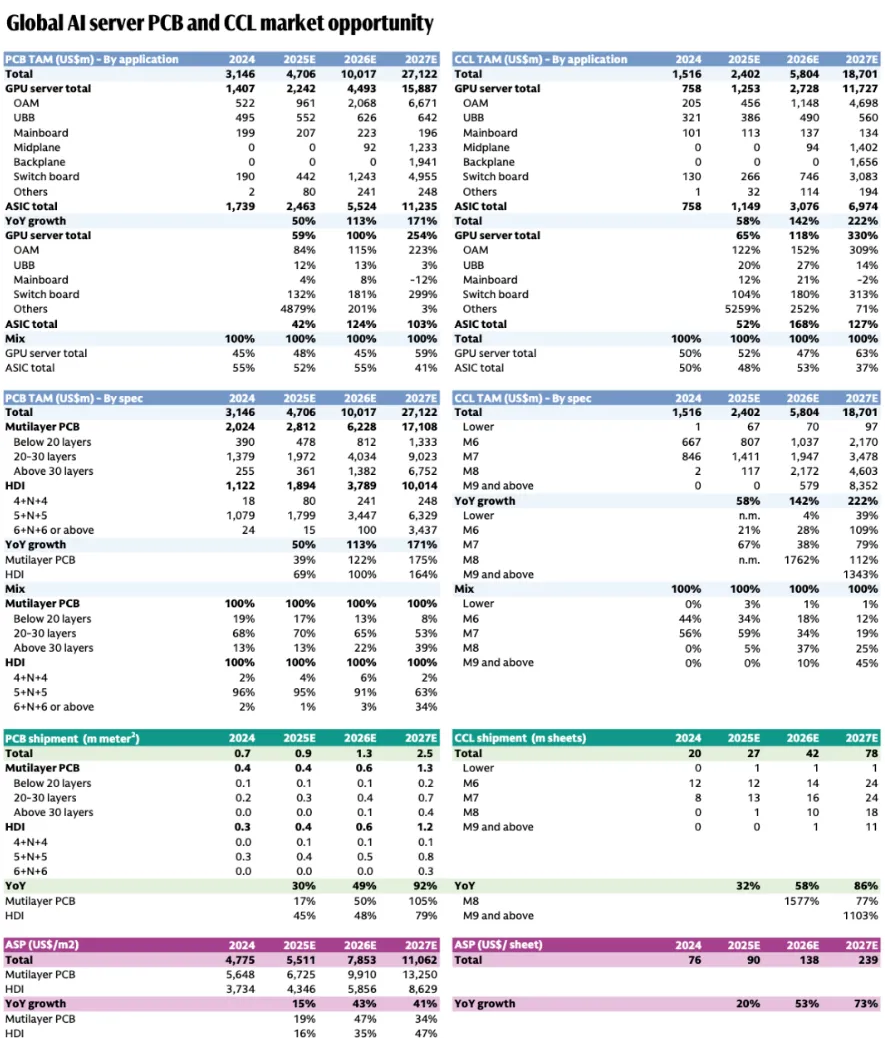
图表. AI PCB与CCL市场预测
资料来源:高盛
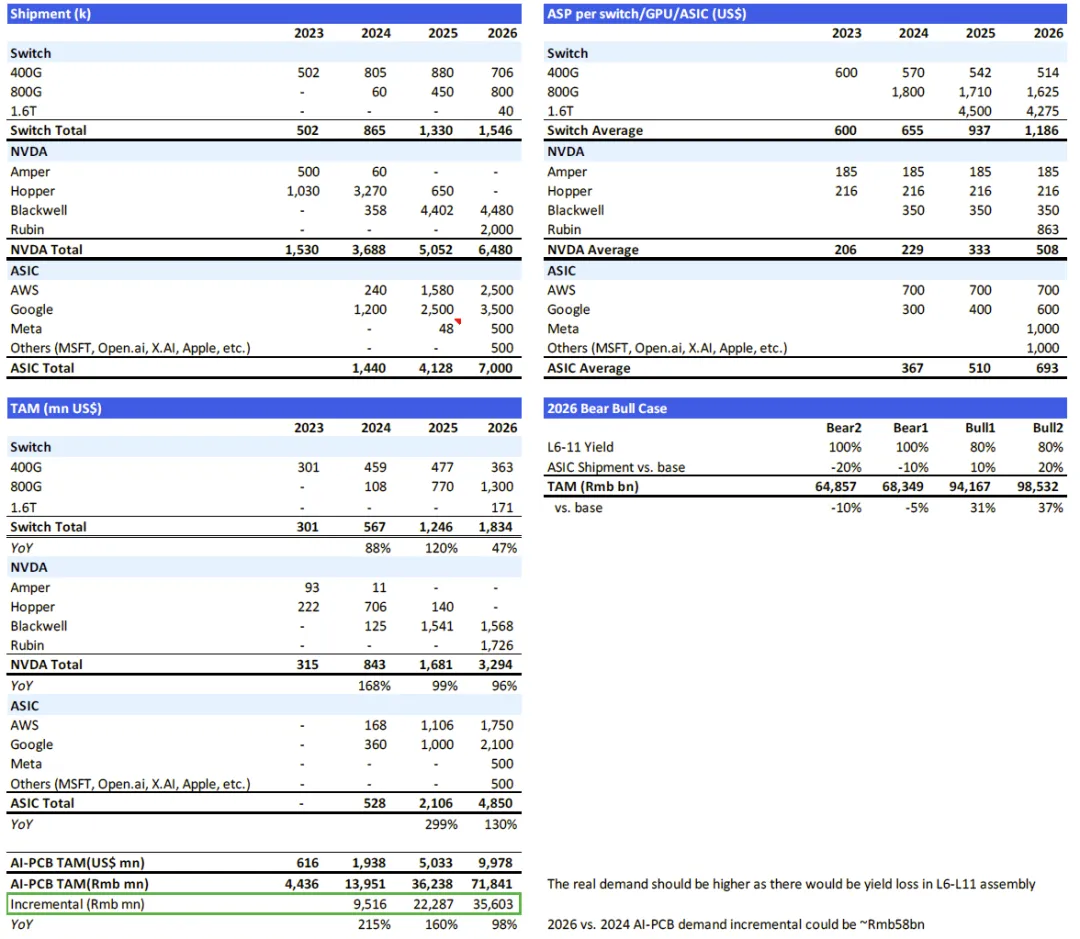
图表. AI PCB市场规模预测
资料来源:花旗
2)PCB供应商加速扩产,高端产能供不应求
全球PCB产能集中在亚洲(大陆、台湾、日本、韩国),据Prismark,24年亚洲地区市占率约93.1%,其中大陆市场额393亿美元,占比53.9%。
主要PCB供应商自24年Q3开启加速投资,国内PCB行业进入密集扩产期,但供给端扩张瓶颈在于日系激光钻孔设备交付周期、特种玻纤布产能受限等,投建至设防仍需时间,短期高端产能处于供不应求状态。25前三季度国内PCB 厂商购建固定资产、无形资产和其他长期资产支付的现金额同比+53.9%,且加大了对泰国、越南等东南亚国家产能投资。
现阶段国内PCB 新增的产能主要集中在高阶HDI、高频高速高多层板及汽车板,CCL厂商新增产能以替代海外高阶CCL及载板基材为主。
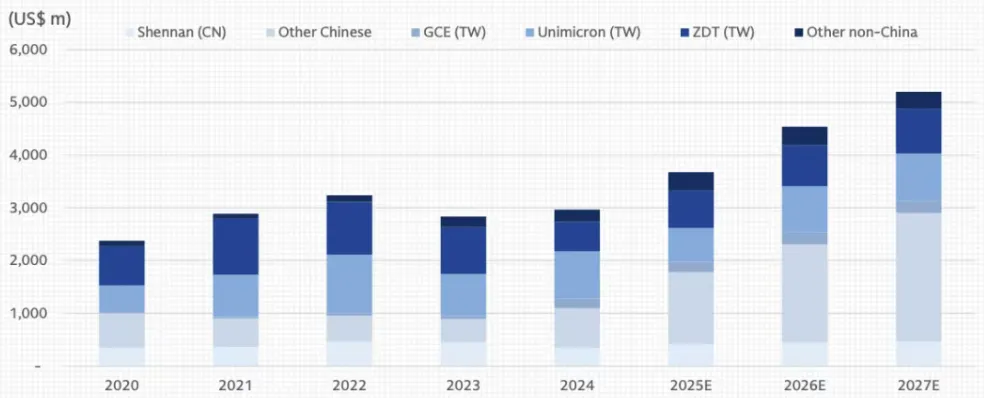
图表. 全球PCB供应商资本开支(25-27年同比增速24%、23%、15%)
资料来源:公司公告、高盛
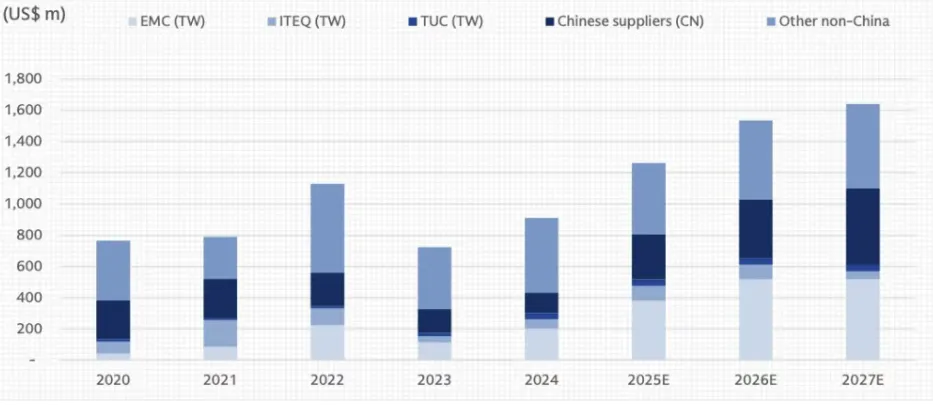
图表. 全球CCL供应商资本开支(25-27年同比增速38%、22%、7%)
资料来源:公司公告、高盛
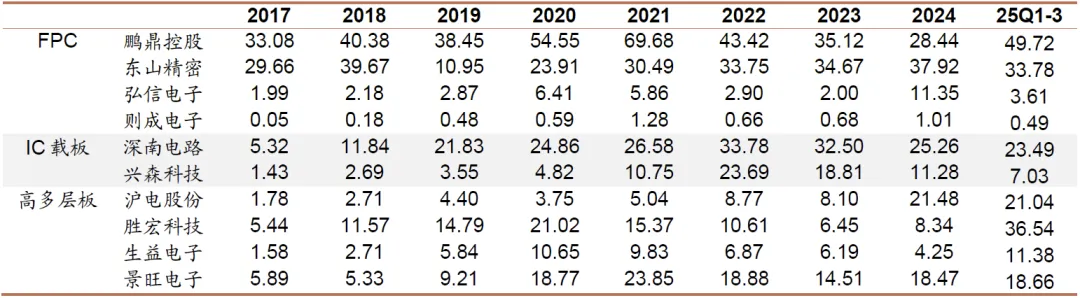
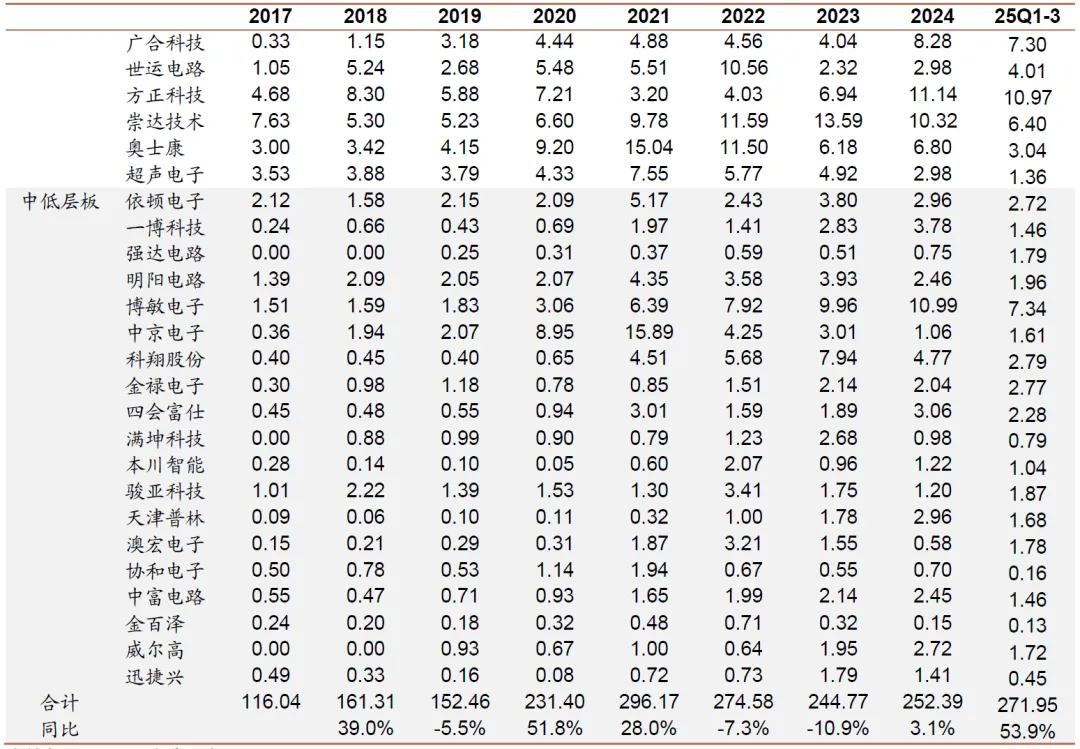
图表. 中游PCB制造厂商资本开支变化(单位:亿元)
资料来源:Wind、招商证券
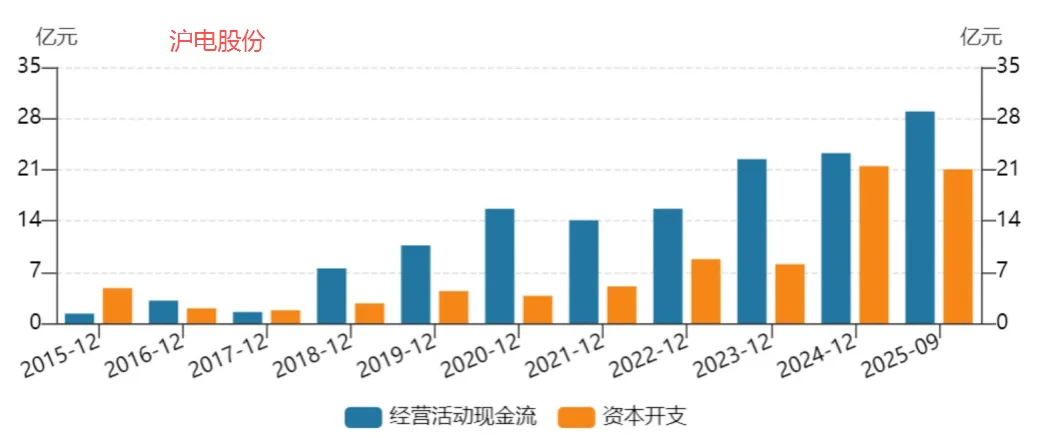
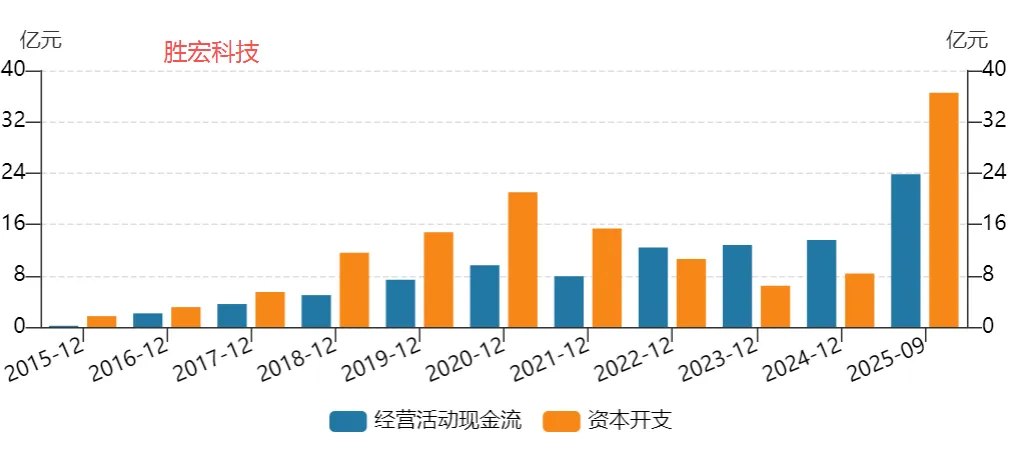
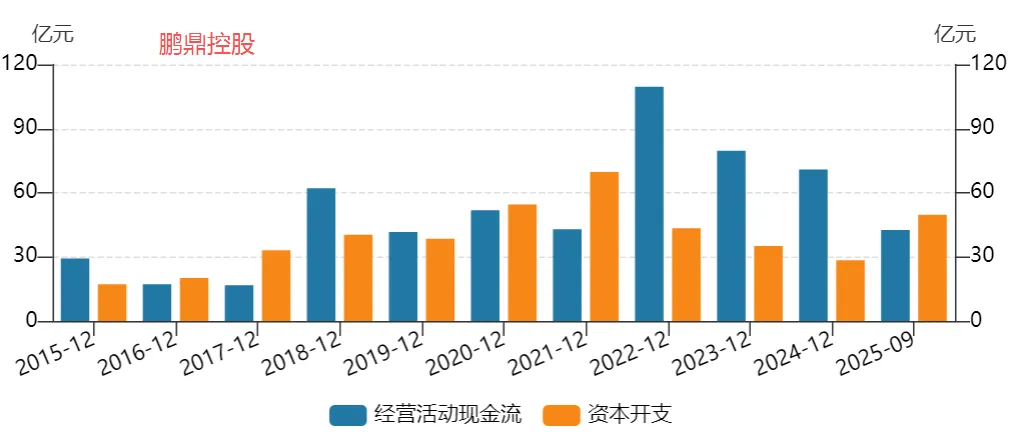
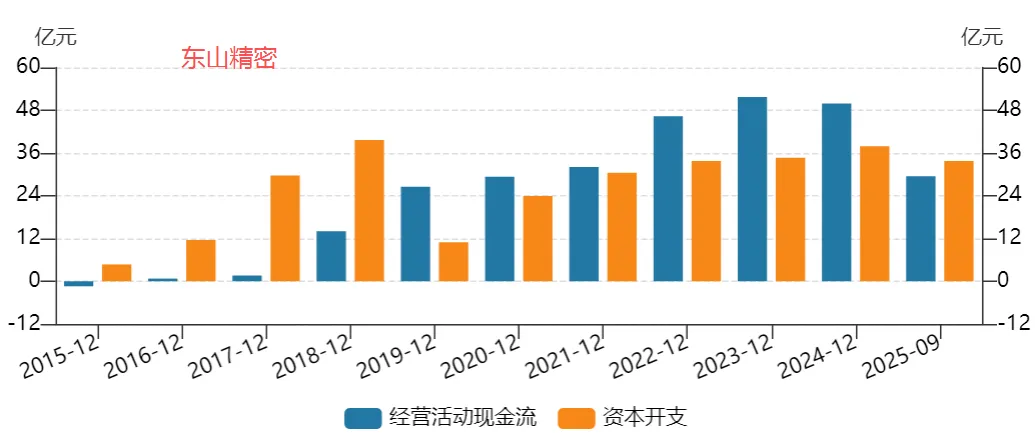
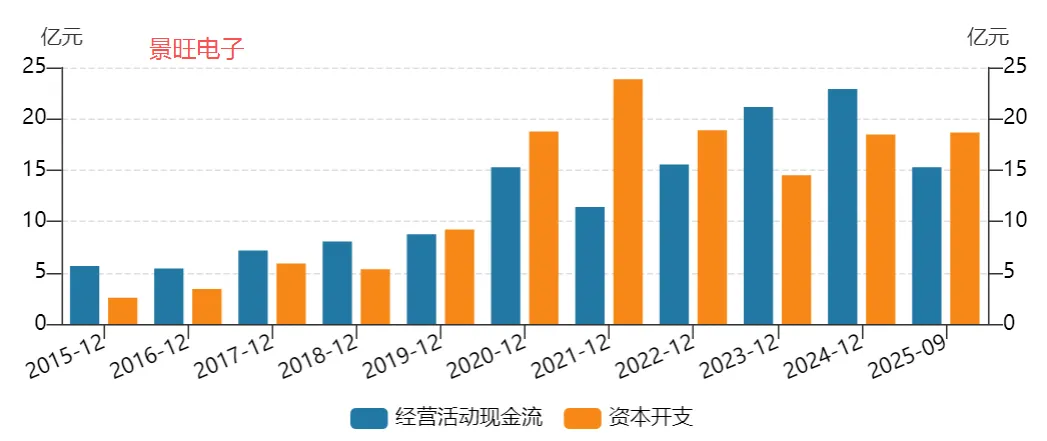
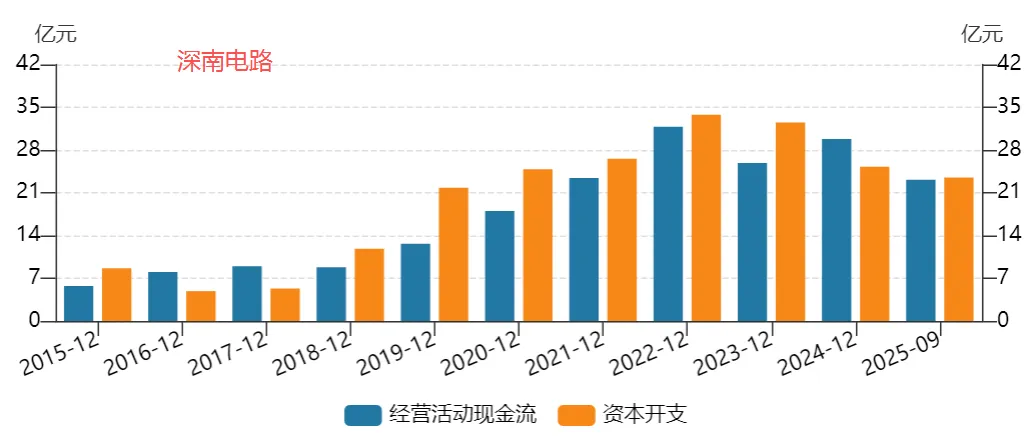
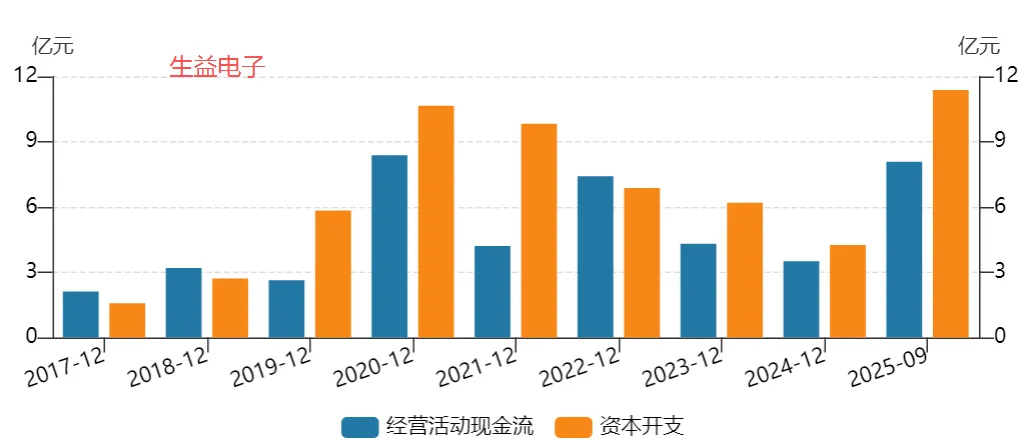
图表. 主要大陆PCB企业经营活动现金流与资本开支
资料来源:Wind
东南亚高端化产能预计于25年Q4-26年Q1逐步释放:跟踪相关公司高阶产能爬坡进度及行业供需格局变化。
据Prismark,预计25年全球HDI市场规模157.2亿美元,同比+25.6%,预计到29年或达213亿美元,期间复合增速11.2%,其中AI服务器与网络增速显著高于行业平均,依次为29.6%、36.0%。
高盛预计25年PCB与CCL的Capex增速为24%/38%,26E为23%/22%,27E放缓至15%/7%。但扩产并不能缓解产能紧张,预计产能利用率持续高位,源于AI基建继续爬坡+技术升级带来额外摩擦降低良率+层数越高意味工序与产能占用更多,有效产出受限。
3)正交背板或在RubinUltra部分替代铜缆
根据英伟达于25年GTC大会上公布的信息,Rubin Ultra(计划于27年发布)在设计上有明显升级,其芯片面积从H100的1x reticle(掩膜)增至4倍,并集成1024GB HBM4e内存(由16颗64GB颗粒组成)。
据Semianalysis预测,Rubin Ultra可能采用两颗56mm×65mm的GPU芯片,通过搭载D2D接口的薄型I/O芯片进行互连,预计其对PCB的面积和性能要求将大幅提高。FP4 推理性能将达15Exaflops(较GB300 提升14倍),HBM4e内存容量升级至1TB。
此外,英伟达宣布,Rubin Ultra的机柜方案亦将更新:从原先水平放置托盘的Oberon机柜改为垂直放置的Kyber机柜,通过90°旋转机架实现更高托盘密度。每个机柜包含4个计算容器compute canister,每容器装载18个计算刀片compute blade,每刀片配备2颗R300 GPU与2颗Vera CPU,单机柜共集成144颗GPU。
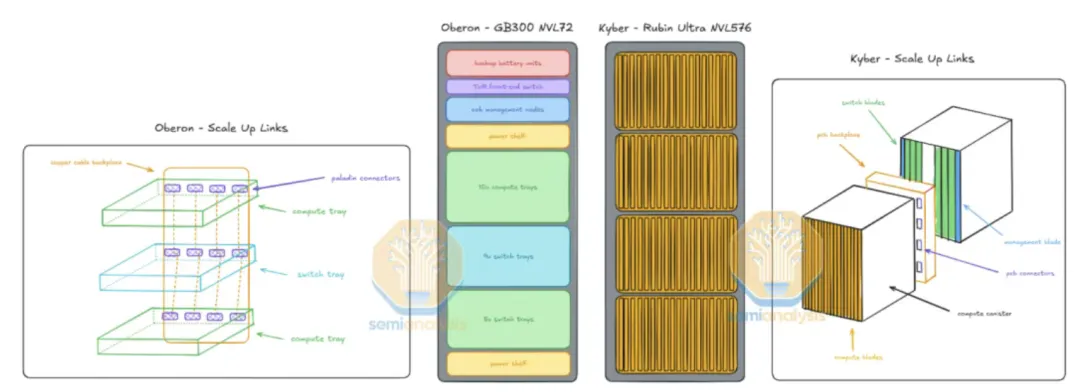
图表. NVL576方案机柜变化
资料来源:Semianalysis
核心在于通过一块70L以上的大型背板,将单个计算单元内的18个Computer Tray与6个Switch Tray直接互连,显著提升系统集成度。这块超高层PCB背板预计将采用M9+Q布或M9.5+Q布材料设计,目前正处于样品测试与优化阶段,计划于27年进入量产。该方案的落地,预计将为达系PCB市场带来新的增长空间。
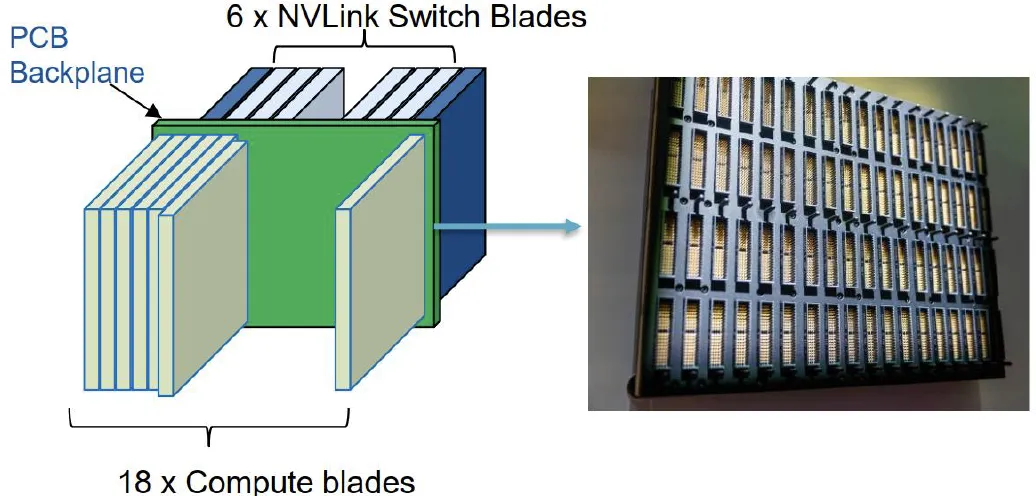
图表. Rubin Ultra NVL576正交背板互联方案
资料来源:Prismark、英伟达GTC
整体来看,随着机柜密度提升,PCB凭借高密度集成与更优的散热性能,预计将逐步替代部分铜缆,成为机柜内部更高效、便捷的互联方案。然而,铜缆在高速信号完整性与中距传输方面仍具优势,可能仍将保留部分应用空间。
4)关注CoWoP与HDI载板化趋势
芯片性能持续提升趋势中,对数据传输速率与功耗控制提出了更高要求,推动PCB与封装载板之间的技术加速融合。SLP(Substrate-Like PCB,类载板)过往应用于苹果手机主板,相比传统PCB具有更轻薄、高密度、细线路(线宽/线距更小)等优势。其制造采用mSAP工艺,该工艺以超薄基铜(2–3μm)实现精密布线,将线宽/线距从传统HDI的40–50μm缩减至20–35μm,更好满足高速、低损耗信号传输需求。
中金判断,mSAP工艺将进一步推动PCB向封装基板领域延伸,具体体现在三个方面:工艺融合(以mSAP替代减成法)、功能融合(在PCB中集成RDL实现芯片级互连)以及结构融合(应用于CoWoP等先进封装技术)。若未来CoWoP成为主流的封装工艺,PCB市场规模有望进一步扩张。
CoWoP(Chip on Wafer on PCB)通过将硅中介层互连的芯片组件直接键合至PCB,取代了传统有机封装基板(ABF),从而提升系统集成度,并将类载板(SLP)技术扩展至更大尺寸的服务器级产品。
该技术缩短了关键信号的传输路径,传统封装中信号需经中介层、封装基板再至主板,而CoWoP实现了中介层与PCB的直接连通,大幅降低了传输延迟,并提升了如PCIe 6.0与HBM3等高速接口的等效带宽利用率,实现更短的信号路径、更低的插入损耗、更高的热学和力学灵活性。
为实现上述性能,下层PCB需具备类似载板的性能标准,其制造将引入更多mSAP(改良型半加成工艺)工序,推动产品从高阶HDI向更大尺寸、更高层数的SLP升级。此前,SLP技术主要应用于高端手机主板及1.6T光模块PCB,但其尺寸与层数相对有限。若CoWoP技术未来在AI服务器中获得应用,单颗GPU或ASIC对应的PCB价值量预计将实现显著提升。
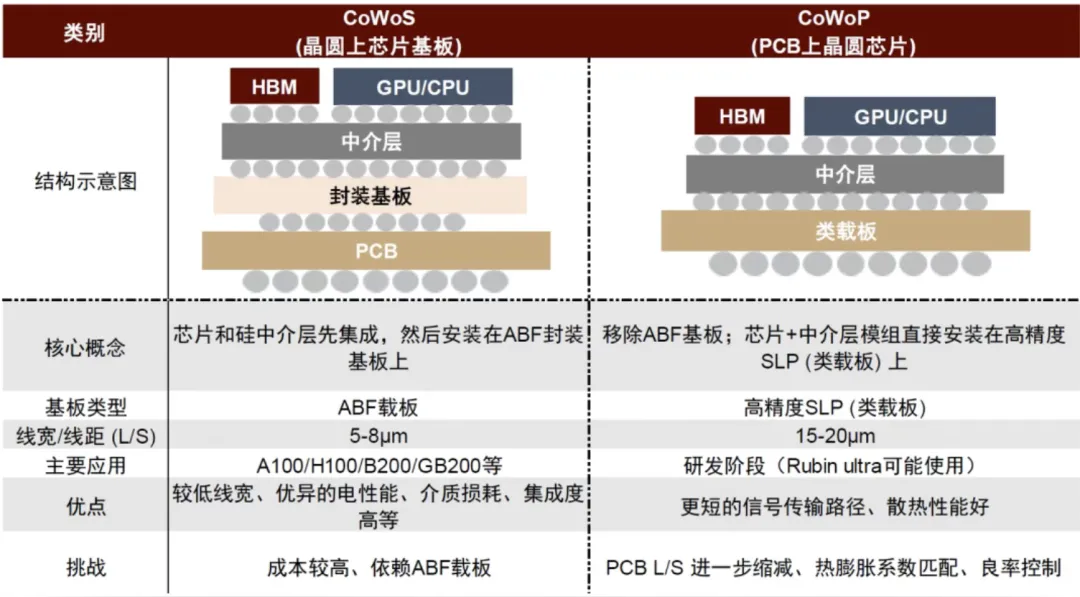
图表. CoWoP或将成为潜在新工艺
资料来源:Semivision、中金科技硬件团队
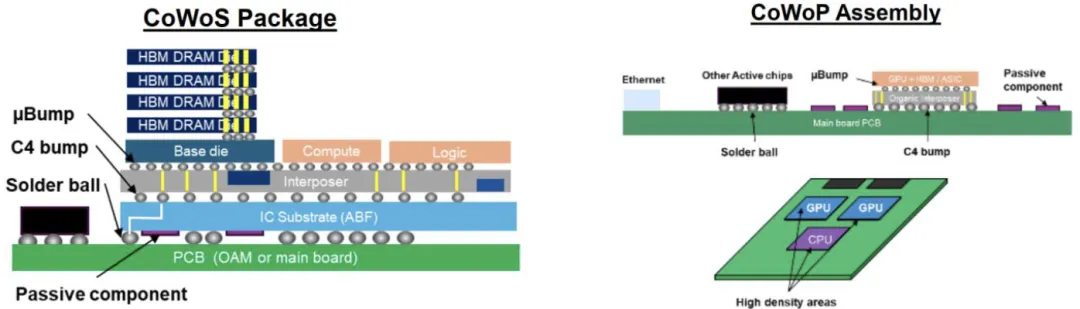
图表. CoWoS与CoWoP技术图示
资料来源:Prismark
CoWop工艺要求苛刻:
1)对PCB的图形化精度要求极高,系统板需替代部分封装载板的功能,实现高密度互连,其线宽/线距(L/S)需达到15-20μm甚至更精细,同时对板的平整度与尺寸稳定性也提出了前所未有的严苛标准;
2)对热机械可靠性的考验严峻,由于芯片与中介层直接贴装于PCB表面,在热循环过程中,因材料间热膨胀系数(CTE)失配而引发的焊点疲劳风险和整体翘曲问题将更为突出。
3)对制造环境与综合良率的挑战巨大,要求传统PCB产线升级至接近先进封装的标准,通常需在ISO1-5级的洁净环境中生产,且最终组装环节的良率要求极高,对缺陷的容忍度低。
3.价值量拆分
PCB 的上游主要为铜箔、玻纤布、树脂等原材料;覆铜板(CCL)为制备PCB重要的中间产品,经过刻蚀等工艺制备成PCB。
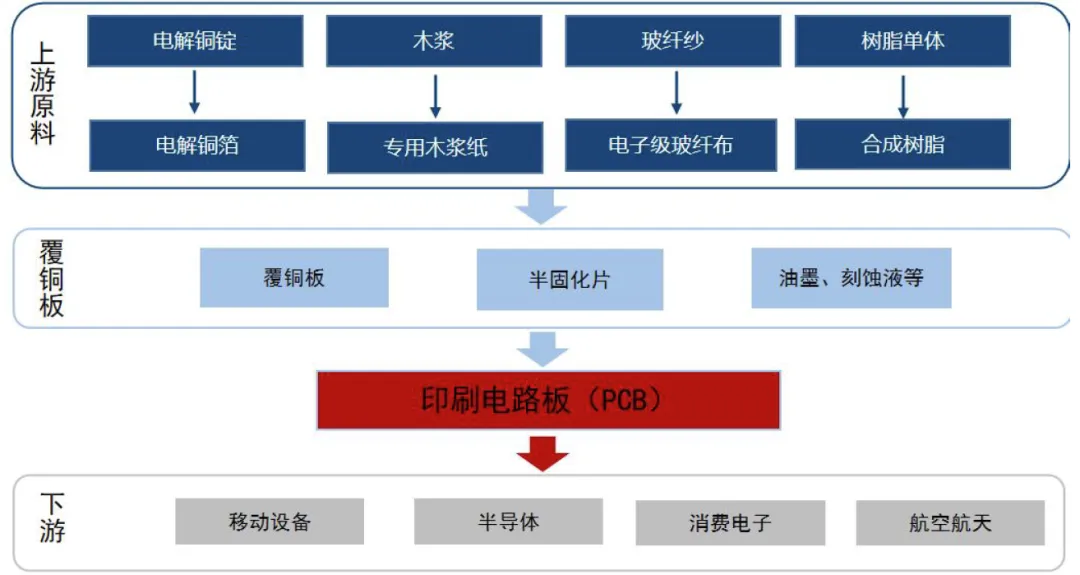
图表. PCB产业链图谱
资料来源:前瞻产业研究院
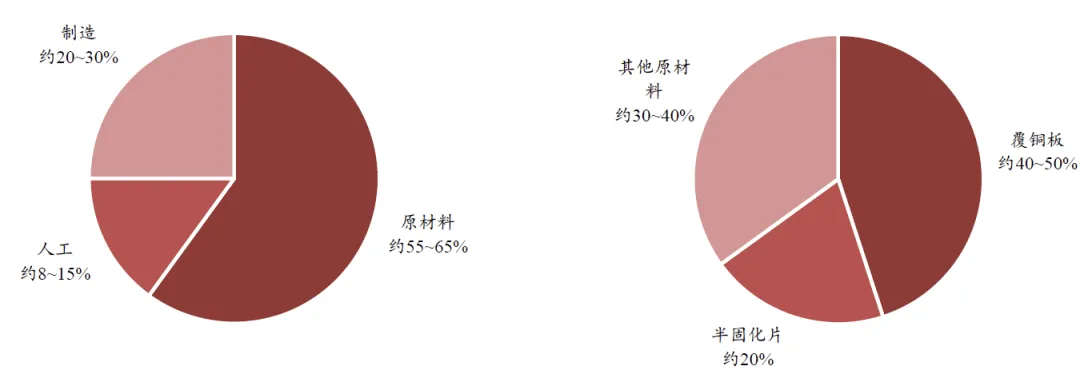
图表. PCB成本大概构成(左)与原材料采购占比(右)
资料来源:沪电、深南、胜宏、广和公告、中银证券
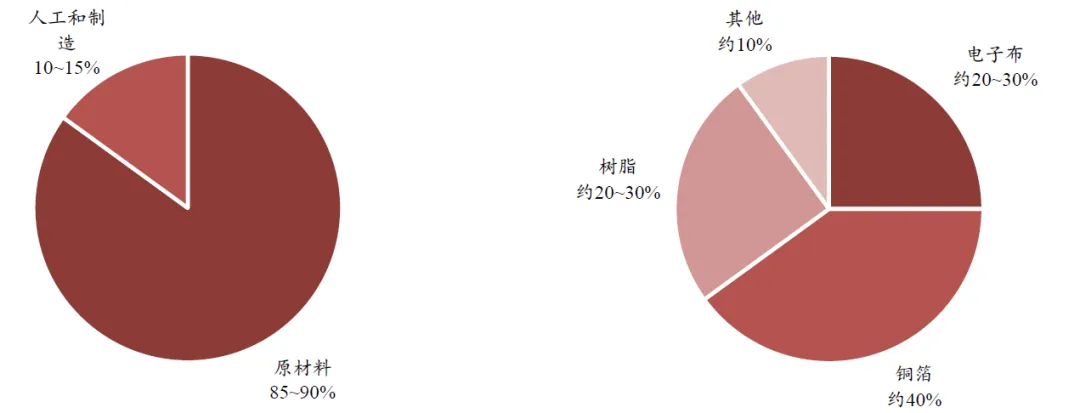
图表. CCL成本大概构成(左)与南亚新材17-19年原材料采购占比(右)
资料来源:生益、南亚公告、中银证券
AI 服务器PCB 中,覆铜板以及其上游的电子布、铜箔、树脂的成本构成占比相较于普通PCB更高。
4.核心公司动态
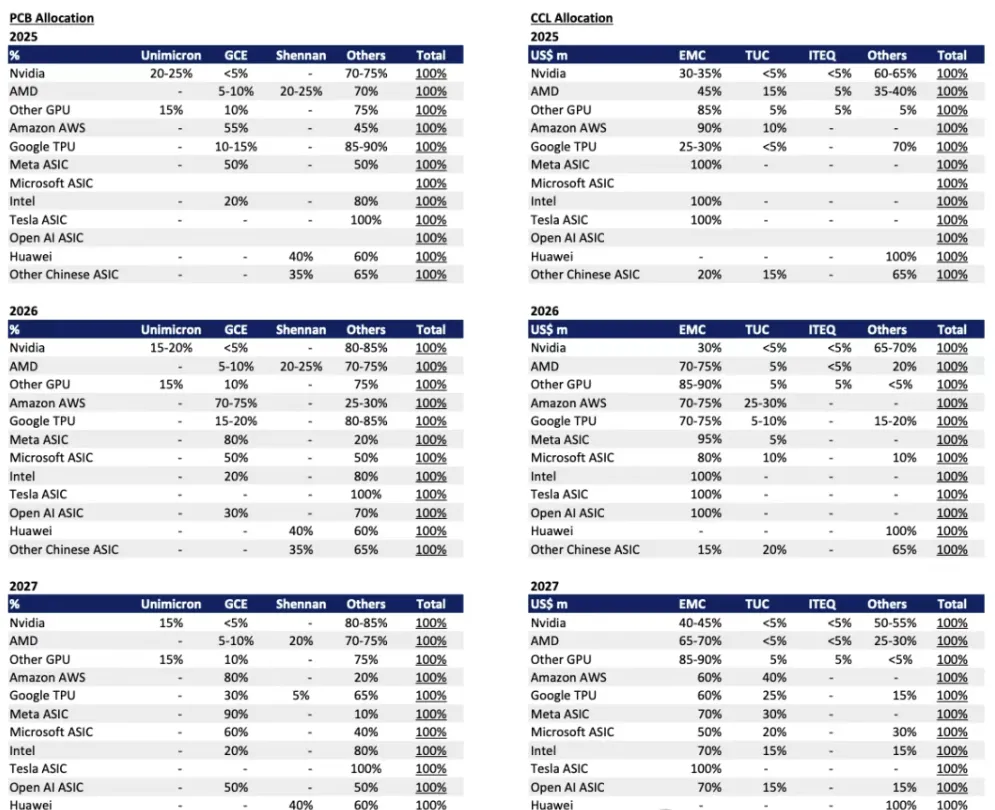
图表. PCB与CCL供应商份额预测
资料来源:高盛
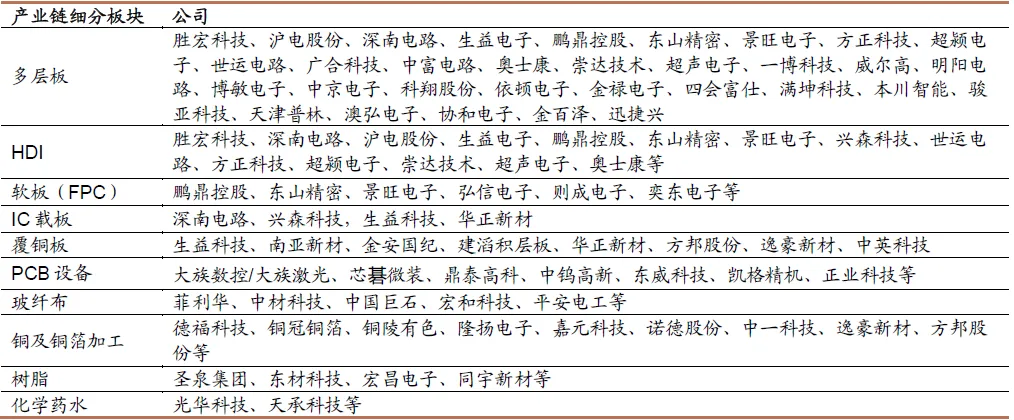
图表. PCB产业链公司
资料来源:招商证券
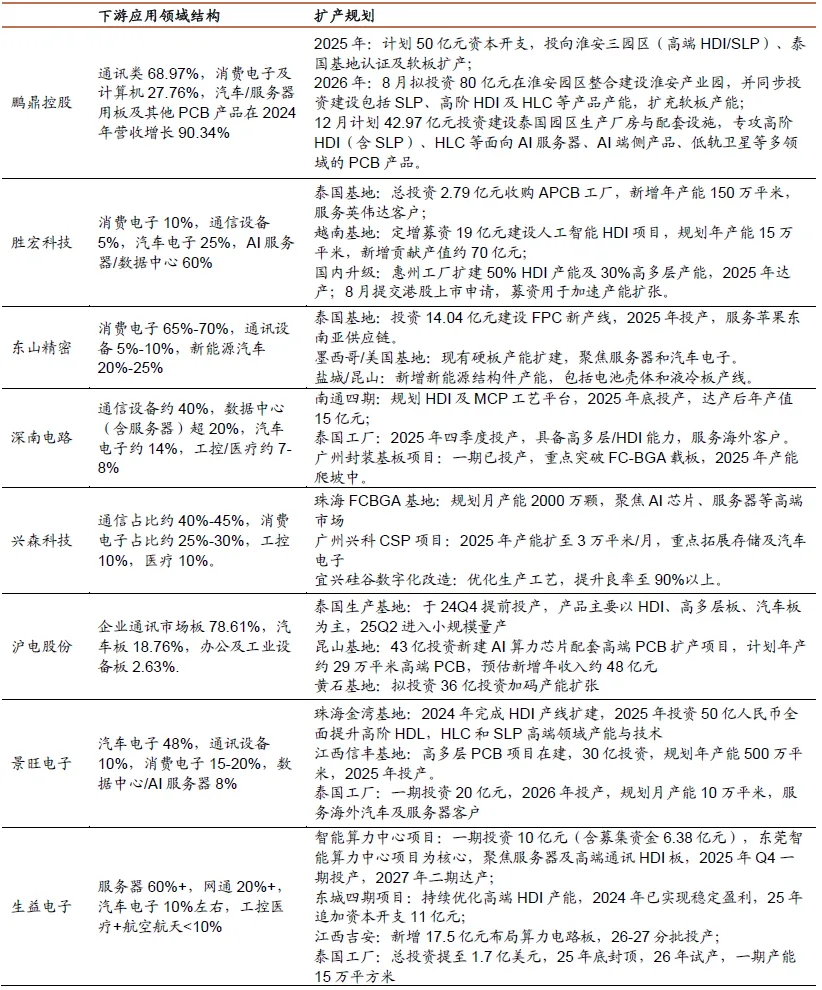
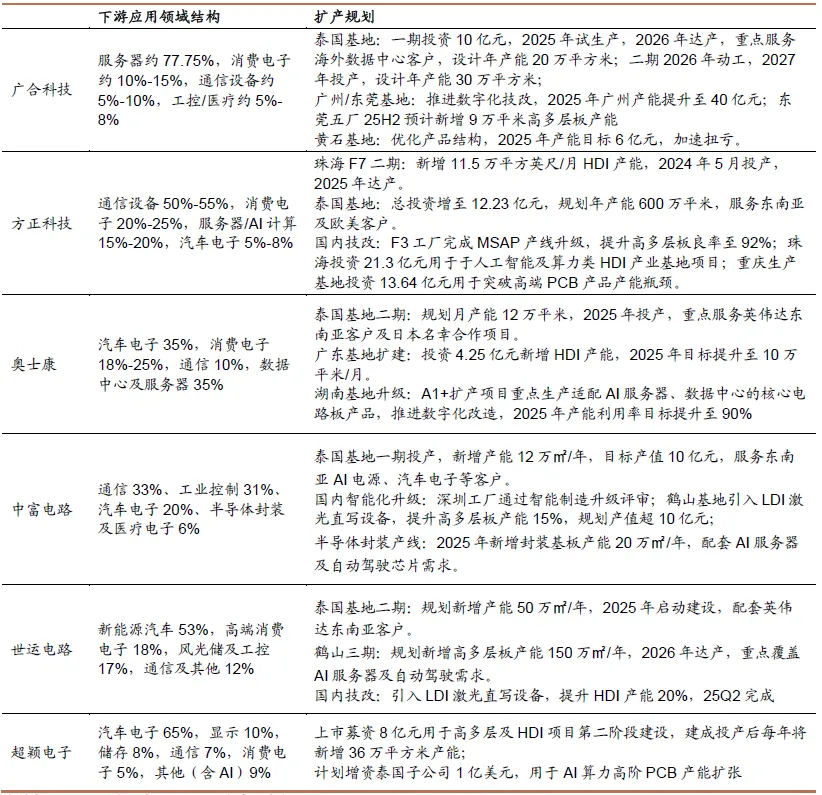
图表. 主要PCB供应商扩产计划
资料来源:招商证券
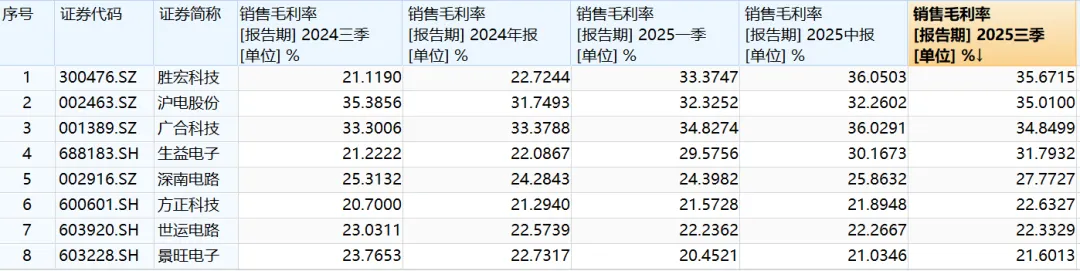
图表. 主要PCB毛利率变化
资料来源:Wind
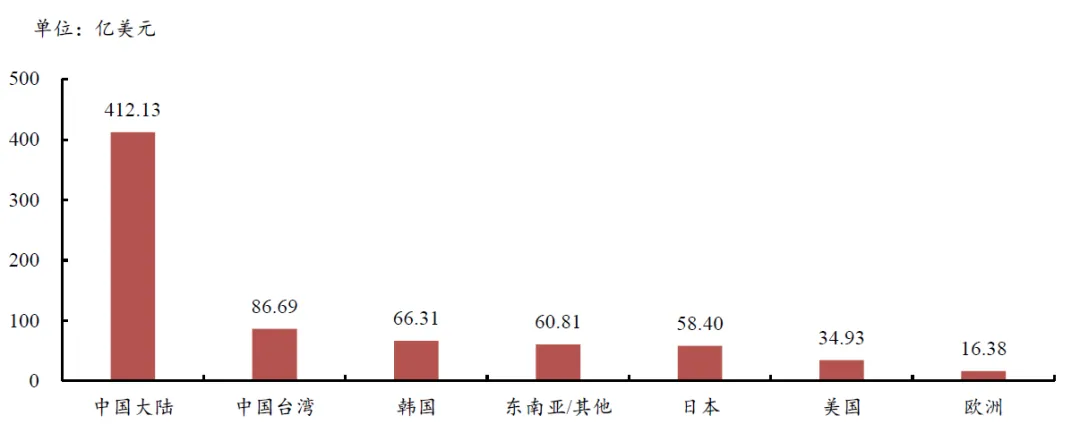
图表. 24年全球PCB产值分布
资料来源:Wind