


—— NUMA / IRQ / softirq / RSS 的全景理解与标准实践
在 25G / 40G / 100G 网络时代,Linux 网络性能瓶颈早已不在“协议效率”,而在:
NUMA 拓扑是否正确
中断(IRQ)是否落在正确的 CPU
softirq 是否失控
RSS / RPS / XPS 是否破坏缓存亲和性
大量线上事故反复证明一个事实:
CPU 使用率是最不可靠的网络性能指标
这份白皮书的目标只有一个:
给出一套“从硬件到内核、从队列到 CPU”的完整网络调优方法论
一、核心结论(Executive Summary)
在开始细节之前,先给出结论性原则:
NUMA 是第一性原理
IRQ 决定 softirq 在哪里跑
softirq 决定延迟是否可控
RSS / RPS / XPS 决定数据是否“搬家”
缓存亲和性比 CPU 利用率更重要
如果你只记住这 5 条,已经超过 80% 的工程师。
二、为什么 NUMA 决定网络性能上限
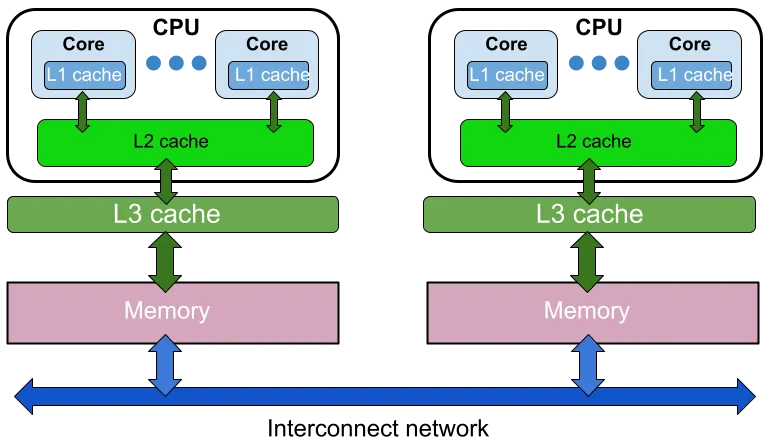
2.1 NUMA 的本质
NUMA(Non-Uniform Memory Access)的核心不是“多节点”,而是:
CPU 访问不同内存,延迟和带宽完全不同
网络 I/O 的真实路径是:
网卡 DMA → 内存 → CPU → 协议栈 → 应用一旦这条路径跨 NUMA:
DMA 在 node0
CPU 在 node1
内存在 node0
你面对的是:
远端内存访问
cache line bounce
不可预测延迟
2.2 从 /sys/devices 看 NUMA 真相
/sys/devices/system/node//sys/devices/system/cpu/
nodeX:NUMA 节点
cpuX/topology/numa_node:CPU 属于哪个 NUMA
/sys/class/net/ethX/device/numa_node:网卡在哪个 NUMA
这是内核调度和内存分配的“事实来源”。
三、IRQ:网络路径真正的起点
3.1 一个被低估的事实
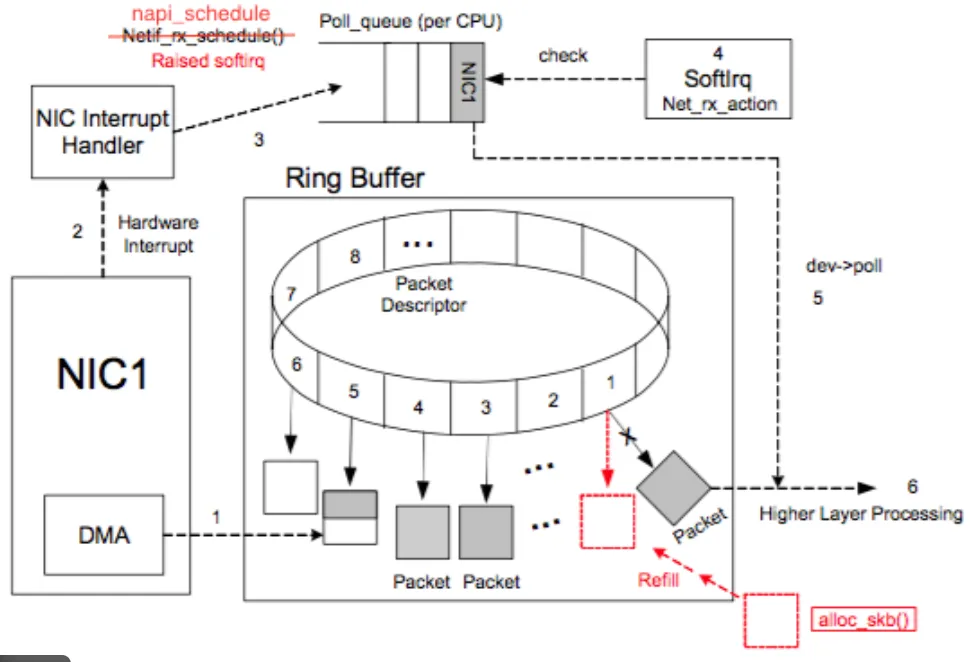
每一个网络包,都是从 IRQ 开始进入系统的
NIC → IRQ → hardirq → softirq → 协议栈IRQ 落在哪个 CPU,决定了:
cache 热度
softirq 抢占对象
NUMA 是否跨节点
3.2 /proc/interrupts 的工程意义
cat /proc/interrupts | grep eth你看到的不是“统计信息”,而是:
网络负载的 CPU 分布图
3.3 IRQ 与 NUMA 的铁律
网卡在哪个 NUMA,IRQ 就必须在哪个 NUMA
违反这条规则,后续所有优化全部无效。
四、softirq 与 ksoftirqd:延迟失控的信号
4.1 softirq 是“真正干活的人”
NET_RX:收包
NET_TX:发送完成
默认规则:
softirq 在触发 IRQ 的 CPU 上执行
4.2 ksoftirqd 的真实含义
ksoftirqd 出现意味着:
softirq 无法在 IRQ 上下文完成
网络处理被延迟
延迟开始不可预测
ksoftirqd 不是解决方案,而是系统退化的标志。
4.3 为什么 CPU 看起来不忙,延迟却高?
因为:
ksoftirqd 是普通内核线程
可被抢占
可被延迟调度
结果是:
CPU idle ≠ 网络没排队
五、RSS / RPS / XPS:队列与 CPU 的“隐形调度器”
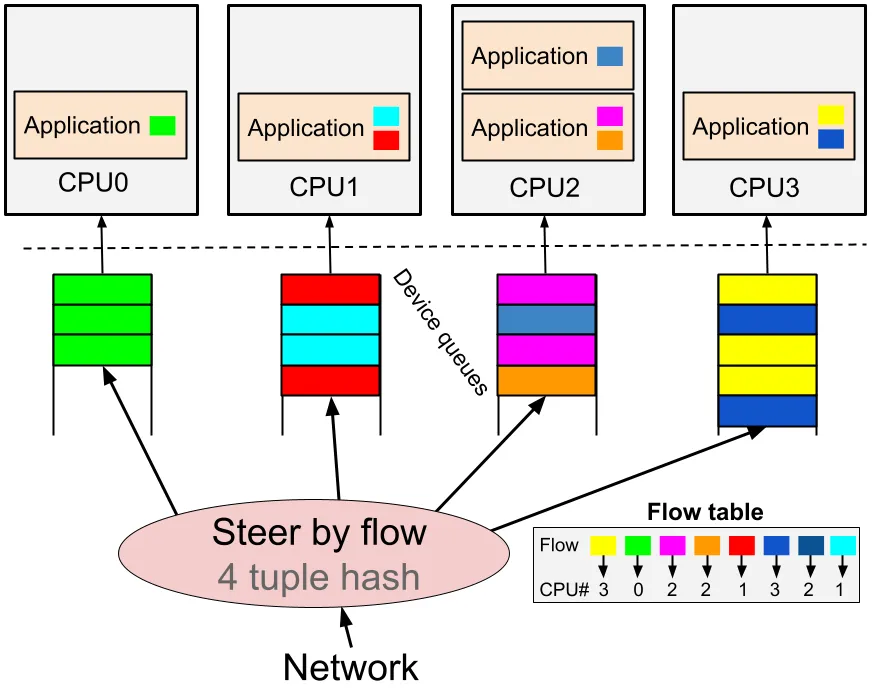
5.1 RSS(Receive Side Scaling)
硬件级分流
决定包进入哪个 RX 队列
一个队列 = 一个 IRQ
优点:
无 CPU 迁移
cache 友好
结论:
RSS 是必须启用的第一优先级机制
5.2 RPS(Receive Packet Steering)
软件级 CPU 重定向
在 softirq 阶段生效
代价:
IPI
skb 迁移
cache miss
结论:
RPS 是兜底方案,不是性能优化手段
5.3 XPS(Transmit Packet Steering)
决定 TX 队列由哪个 CPU 使用
解决发送方向 cache 失配
结论:
XPS 是高性能发送路径的关键组件
六、标准 NUMA + 网卡布局(见我的文章:《NUMA + 网卡:高性能网络的标准布局》)
6.1 标准硬件布局
CPU0 (node0) ── PCIe ── NIC0CPU1 (node1) ── PCIe ── NIC1
6.2 标准软件布局(单网卡)
NUMA node0├── 网卡 eth0├── RX/TX IRQ CPU├── softirq CPU└── 网络应用线程
6.3 CPU 划分模板
假设 node0 CPU 为 0–15:
七、irqbalance 的正确使用姿势
默认 irqbalance:不懂 NUMA
高性能场景:
要么关闭
要么限制 CPU mask
irqbalance 适合“平均”,不适合“性能”
八、排障路径(工程实战)
8.1 延迟抖动排查顺序
网卡 NUMA
IRQ CPU
softirq 分布
ksoftirqd 是否活跃
RSS / RPS / XPS 是否合理
8.2 常见“反模式”
九、上线前终极检查清单
硬件
网卡 PCIe 插槽 NUMA 正确
内核
IRQ 在本 NUMA
无异常 ksoftirqd
softirq 分布均衡
网络
RSS 队列合理
XPS 已配置
RPS 非必要不开
应用
绑核
绑 NUMA 内存(numactl)
十、结论(白皮书级总结)
Linux 高性能网络的本质不是“调参数”
而是:
正确的 NUMA 归属
清晰的 IRQ 边界
可控的 softirq 执行
稳定的 cache 亲和性
当你做到:
数据不跨 NUMA
中断不抢应用
包不在 CPU 间搬家
性能与稳定性,会自然出现。