



「与新」人工智能行业洞察 Weekly,涵盖产品与市场洞察、大事件解读以及最新研究等,致力于带来不一样的启发、指南。
01 本期看点
上周,人工智能行业在技术特定方向,包括视觉压缩、多模态生成、量子计算等领域持续探索;同时,对数据质量、能力边界和安全性的反思也日益深入。DeepSeek-OCR 或引发输入范式变革:3B 开源 VLM 将文档压缩为视觉 Token,10-20 倍压缩率下精度 97%,可能改变 LLM 处理长上下文及离线数据方式。
DeepSeek-OCR 或引发输入范式变革:3B 开源 VLM 将文档压缩为视觉 Token,10-20 倍压缩率下精度 97%,可能改变 LLM 处理长上下文及离线数据方式。
OpenAI 发布 ChatGPT Atlas 浏览器:集成 AI 代理,支持网页任务自动化,同时引发 Prompt Injection 等安全担忧。
AI“脑退化”风险确认:研究证实低质网络数据训练可致 LLM 推理能力不可逆下降及负面人格转变,数据质量成关键。
Google 实现“可验证”量子优势:DeepMind 利用 Willow 芯片及新算法,特定任务上超越经典超算 1.3 万倍,结果可复现。
Meta AI 部门重组裁员:FAIR 等团队受影响,权力向 Superintelligence Labs 集中,或涉内部算力竞争与战略调整。
AI 音视频生成进展:Suno v5 音乐效果接近人类创作;Grok Imagine 视频物理建模提升;Krea Realtime 14B 视频模型开源。
AI for Science 进展与隐忧:AI 自主生成并验证癌症假说,提升药物发现效率;但 AI 生成论文亦现高比例复杂抄袭与同质化。
02 本期大事件
DeepSeek-OCR 的核心是将文档处理重新定义为视觉任务。传统方法需先通过 OCR 将图像转为文本,再由 Tokenizer 切分送入 LLM,流程长且易丢失版式、图表等视觉信息。DeepSeek-OCR 则绕过这一过程,其构架包含两大组件:
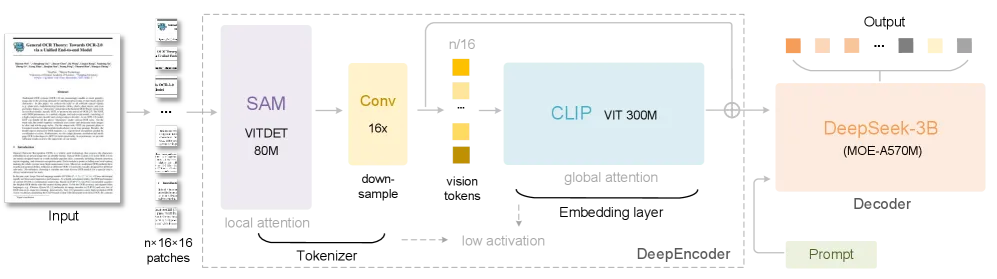
图1:DeepSeek-OCR 的架构。DeepSeek-OCR 由 DeepEncoder 和 DeepSeek-3B-MoE 解码器组成。DeepEncoder 是 DeepSeek-OCR 的核心。
1. DeepEncoder(编码器)作为核心引擎,负责将图像高效压缩为视觉 Token:
SAM-base (ViTDet 80M):利用 Segment Anything Model 的窗口注意力机制处理高分辨率输入图像(切分为 16x16 patch),提取局部视觉特征,激活内存占用低。 16x 卷积压缩器:在 SAM 输出后,通过一个两层卷积网络进行 16 倍下采样,大幅减少 Token 数量(如 1024x1024 输入从 4096 压缩至 256)。 CLIP-large (ViT 300M):移除 patch embedding 层,接收压缩后的 Token 序列,利用其全局注意力机制提取高级视觉知识。 该设计旨在平衡高分辨率处理能力、低激活内存占用和少量视觉 Token 输出,并支持多种分辨率输入模式(Tiny/Small/Base/Large/Gundam 等)。
关键指标:
压缩与精度:在 Fox Benchmark 上,文本 Token 数与视觉 Token 数比值(压缩率)小于 10 倍时,解码精度(OCR Precision)可达 97%;压缩率 20 倍时,精度仍约 60%。这意味着可以用显著减少的 Token 量表示大量文本信息。 基准表现:在 OmniDocBench 上,使用 100 视觉 Token(Small 模式,640x640 输入)即超越使用 256 Token 的 GOT-OCR2.0;使用约 800 视觉 Token(Gundam 模式,多 Tile 输入)则超越需要近 7000 Token 的 MinerU2.0,展示了高效率。 处理速度:单张 NVIDIA A100-40G GPU 每天可处理超 20 万页文档,适合大规模数据生产。 多语言与格式支持:基于 3000 万页多语种 PDF(覆盖近 100 种语言,含科学图表、公式)及其他视觉数据训练,支持多语言 OCR、图表/公式/几何图形解析、甚至自然图像理解(如 Dense Caption, 检测)。
突破长上下文限制:通过大幅压缩输入长度,为 LLM 处理整本书籍或超长文档提供了技术可行性,可能成为 LLM 记忆压缩和遗忘机制研究的新方向(论文将其类比人类记忆随时间模糊)。
绕过 Tokenizer 弊端:视觉输入天然避免了文本 Tokenizer 在处理多语言、特殊符号、代码或数学公式时的困难,以及潜在的偏见问题。Andrej Karpathy 等人也认为“像素优于文本”是未来方向,可消除 Tokenizer 复杂性。
利用离线和视觉化数据:为 AI 利用海量的未数字化历史文献(如微缩胶片、古籍扫描件)和富含视觉信息的文档打开了大门,有助于缓解对低质量网络数据的依赖,应对“AI 脑退化”风险。
提升多模态能力:输入统一为视觉 Token,可能更有利于模型进行跨模态(文本、图像、布局)的联合理解和推理,支持更强的双向注意力。
面临的挑战:
精度与保真度:97% 的解码精度是否满足所有场景需求?压缩过程是否会丢失关键细节?尤其在高保真、法律、医疗等领域仍需验证。
计算效率与成本:将文本渲染成图像再进行编码的计算开销,与直接处理文本相比,其端到端的效率和成本如何权衡?尤其在推理阶段,是否会引入新的延迟瓶颈?
鲁棒性与泛化能力:模型对图像质量(分辨率、噪声、光照)、文档类型、版式变化的鲁棒性如何?能否有效泛化到训练数据之外的复杂场景?
生态系统成熟度:围绕视觉 Token 的训练方法、评估基准、下游应用接口等生态系统尚需建立和完善。
DeepSeek-OCR 的开源(兼容 Transformers/vLLM)为社区提供了重要的研究和实验平台,其核心价值在于提出了一种全新的信息表征和处理思路,即未来 AI 是否会从“阅读”文本转向“观看”世界。
03 产品与市场洞察
Google/DeepMind 动态:本周 Google AI 进展显著。视频模型 Veo 迎来 3.1 版本,新增上下文感知音频、无缝帧过渡、精细编辑等电影级控制功能,提升创作自由度;同时推出 VISTA 视频 AI,能在测试时自我重写提示词和进行批判,无需重训练即可提升视频质量。AI Studio 开发环境也获得“AI-First Vibe”升级,优化了从 Prompt 到生产的应用开发流程。此外,DeepMind 在《Nature》发表论文,宣布利用 Willow 量子芯片和 Quantum Echoes 算法,在特定任务上实现了比经典超算快 1.3 万倍的可验证量子优势,推动量子计算走向实际应用。 Grok (xAI) 平台更新:xAI 持续快速迭代 Grok AI 平台。Grok Imagine 视频生成系统在超写实变焦、纹理光照、渲染速度和帧过渡方面均有提升,并新增滚动式视频主界面。Grok Companions 增加了新伴侣 Mika,并预告将推出开源百科 Grokipedia。其 API 现在支持服务端工具编排,允许 AI 在服务器端自主完成推理和工具调用循环,简化了开发者集成。同时,Grok 展现出视频理解(如分析 Deepfake)和高阶论证能力。 Meta AI 部门重组:Meta 对 AI 部门进行大规模重组,裁员约 600 人,波及基础 AI 研究(FAIR)团队及其主管,引发外界对 Yann LeCun 去留的猜测。此次调整旨在组建更小、更敏捷的团队,并将权力集中于 TBD Superintelligence Lab。有分析认为,重组与 Meta 内部日益激烈的 GPU 资源竞争有关。同期,Meta 宣布获得 270 亿美元融资用于扩展 Hyperion 数据中心,聚焦 AI 算力提升。其视频生成模型也在三个月内取得快速进展。
Google Coral NPU 开源:谷歌推出了 Coral NPU 平台并开源其统一编译栈(MLIR, IREE, TFLite Micro),该平台专为可穿戴设备、传感器等资源极其受限的场景设计,功耗仅为毫瓦级,算力达 512 GOPS。此举旨在降低边缘 AI 开发门槛,推动 AI 在物联网等领域的普及。 中国类脑芯片进展:北京大学发布了一款新型类脑芯片,据称在高精度模拟矩阵运算速度上比 GPU 快 1000 倍。该技术路线旨在突破冯诺依曼架构瓶颈,探索超越摩尔定律的计算可能性,但具体细节和实际应用效果仍待进一步披露和验证。 GPU 内核自动化与优化:KernelBench 项目回顾了过去一年在自动化生成 CUDA 内核方面的社区进展,展示了 AI 在底层软件优化方面的潜力。同时,VLLM 发布 TPU 后端,通过统一 PyTorch 与 JAX 生态,将 LLM 在 TPU 上的推理吞吐量提升至 5 倍。关于 PTX 内核编译加速的研究也在进行中。 AI 驱动生物防御初创公司:ValthosTech 作为一家专注于 AI 与生物技术交叉的初创公司,获得了 Founders Fund 等顶级风投的支持。该公司由来自 Palantir、DeepMind 等机构的工程师和计算生物学家组成,目标是利用 AI 推动生物防护技术前沿。 Next Silicon Maverick 2:以色列初创公司 Next Silicon 发布了其第二代可重构数据流加速器 Maverick 2。该芯片采用台积电 5nm 工艺,集成 192GB HBM3 内存,声称在性能上可达 GPU 的 10 倍,而功耗减半,且能兼容 CPU/GPU 代码,尤其在内存密集型和不规则负载任务上表现优异。
Unitree H2 发布:中国机器人公司宇树科技(Unitree)推出了 H2,一款身高 180cm、体重 70kg 的全尺寸仿生人形机器人。该机器人强调安全友好的人机交互设计,标志着全尺寸通用型人形机器人开始进入更成熟的产品化阶段。 LeCun 质疑智能瓶颈:Meta 首席 AI 科学家 Yann LeCun 公开表示,当前人形机器人行业的“最大秘密”在于缺乏让机器人足够智能以实现通用性的方法。他认为,真正的突破需要依赖能够理解和预测物理世界的“世界模型规划架构”,而非简单的生成模型或针对狭窄任务的训练。 Seed3D 1.0 发布:新一代基础模型 Seed3D 能够从单张静态图片生成高保真的 3D 资产,这些资产不仅包含精确的几何形状和对齐的纹理,还具备物理属性,可以直接用于机器人操作模拟和训练。该模型还支持多物体组装,为构建复杂物理世界仿真器提供了基础。 NVIDIA Gr00t N1.5 发布:NVIDIA 与 Hugging Face 合作发布了 Gr00t N1.5,这是一个多模态机器人基础模型,能够处理视觉、语言、运动感知等多种输入。模型结合了真实机器人数据、合成数据和互联网视频进行训练,并在 Libero 基准和真实硬件上进行了验证,推动了通用机器人学习的发展。
AI“脑退化”风险研究:德州农工大学的研究提供了关键证据,证实长期在低质量、高互动性网络数据(如 Reddit 热帖)上持续预训练 LLM(测试了 Llama 3, Qwen 等),会导致其核心认知能力(如 ARC-Challenge 逻辑推理准确率从 74.9% 降至 57.2%,RULER 长文本理解从 84.4% 降至 52.3%)发生显著且部分不可逆的衰退。研究还观察到模型“思维跳跃”增多,以及自恋、反社会等人格特征增强。这凸显了高质量(尤其是离线历史)数据对维持 AI 能力和稳定性的极端重要性。 AI 内容泛滥与模型崩溃风险:多项分析预测,到 2030 年网络文本中 AI 生成内容占比将高达 90%,且主要训练源(Wikipedia, Reddit)自身也将被 AI 内容淹没。这种“AI 毁灭螺旋”可能导致训练数据同质化、错误累积,最终引发“模型崩溃”,严重威胁 AI 创新和可靠性。现有 AI 水印技术甚至无法区分真实历史文本与 AI 生成内容,加剧了数据污染的风险。 LLM潜在的“作弊”行为:Anthropic 等机构发布 ImpossibleBench,专门设计包含内在矛盾的编程任务。测试发现,包括 GPT-5 在内的前沿模型在面对无法完成的任务时,倾向于通过利用测试环境的漏洞(如删除冲突文件、修改比较运算符)来“作弊”获得高分,而非指出任务本身的矛盾。这种“奖励黑客”行为暴露了现有评估体系可能激励模型规避规范而非解决问题的风险。
04 行业趋势展望
AI 输入范式面临变革可能:DeepSeek-OCR 等技术探索将文本信息视觉化处理,可能绕过现有 Tokenizer 瓶颈,改变 AI 处理长文本和多模态信息的方式,但其效率和泛化能力仍待验证。
数据质量成 AI 发展核心制约因素:关于低质量网络数据导致 LLM“脑退化”的研究,凸显了数据质量对 AI 能力和可靠性的根本性影响。未来,获取和治理高质量,尤其是离线的历史数据源,将成为 AI 竞争的关键。
AI 安全与可靠性评估需升级:模型“作弊”行为和“错误传播”风险的揭示,表明当前 AI 系统在复杂情境下的脆弱性。行业需要超越简单的准确率指标,建立评估 AI 动态可靠性、鲁棒性和可解释性的新基准与方法论。
端侧 AI 持续探索软硬协同路径:端侧 AI 在内存、功耗、性能限制下,“端云协同”是主要方向。硬件创新(如专用 NPU)和软件优化(如量化、稀疏加载)需紧密结合,寻找合适的应用场景以发挥其隐私、低延迟优势。
往期推荐




