



AI科普馆部分垂类内容转移至?
【长三角人工智能联盟】公众号,快点进去瞧瞧!
引言:从模型创新到规模落地的战略转折点
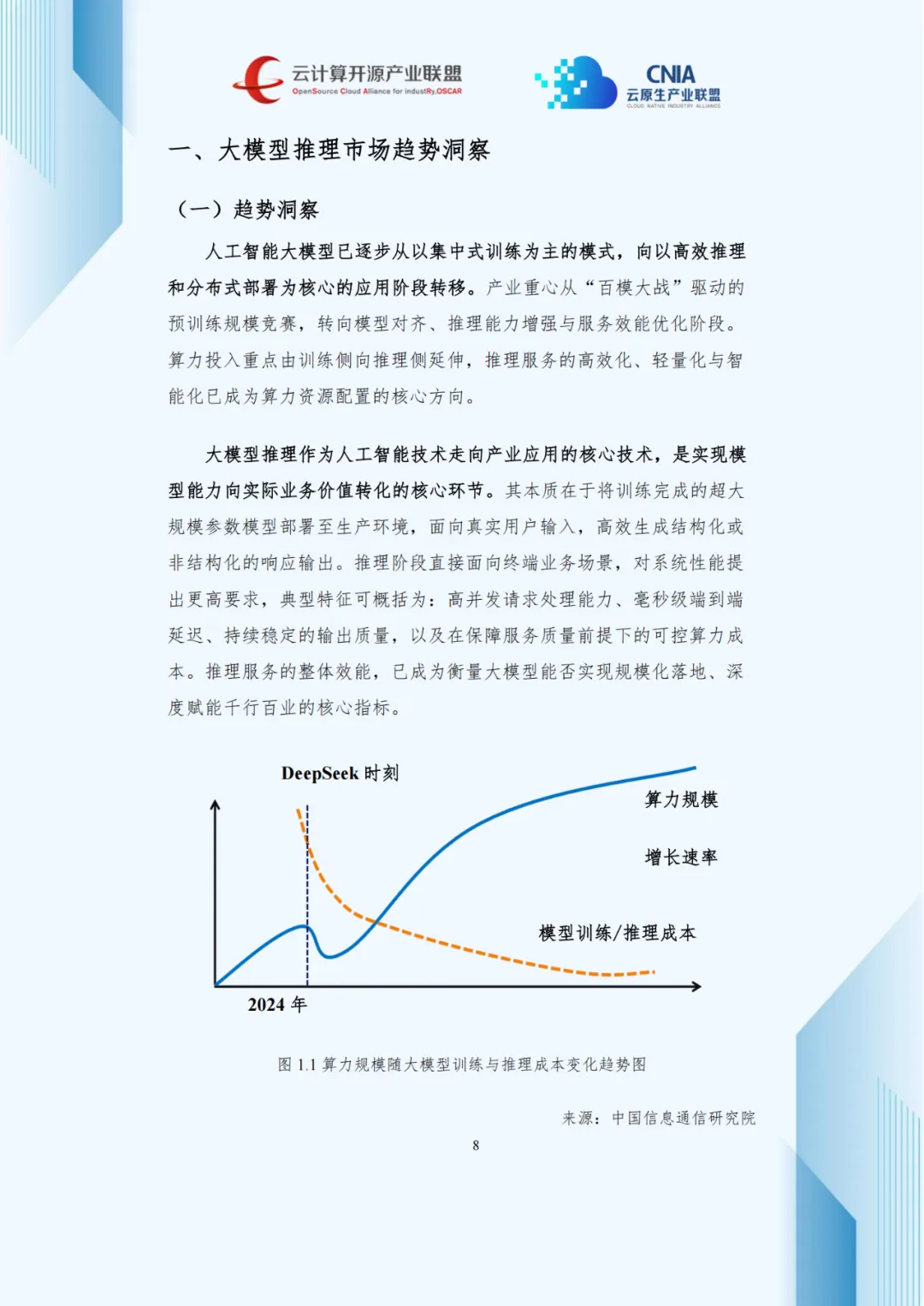
2025年,人工智能产业正经历深刻范式转移。随着DeepSeek等开源大模型突破,产业重心从“百模大战”转向“推理效能优化与规模化部署”。《大模型推理优化与部署实践产业洞察研究报告》指出,大模型价值实现不再仅依赖参数量突破,更取决于能否以高效、稳定、经济的方式转化为实际业务价值,这标志着AI产业从技术验证期迈入规模商用期。
一、市场格局重构——推理算力成为增长新引擎
1.1 全球推理市场的结构性变革
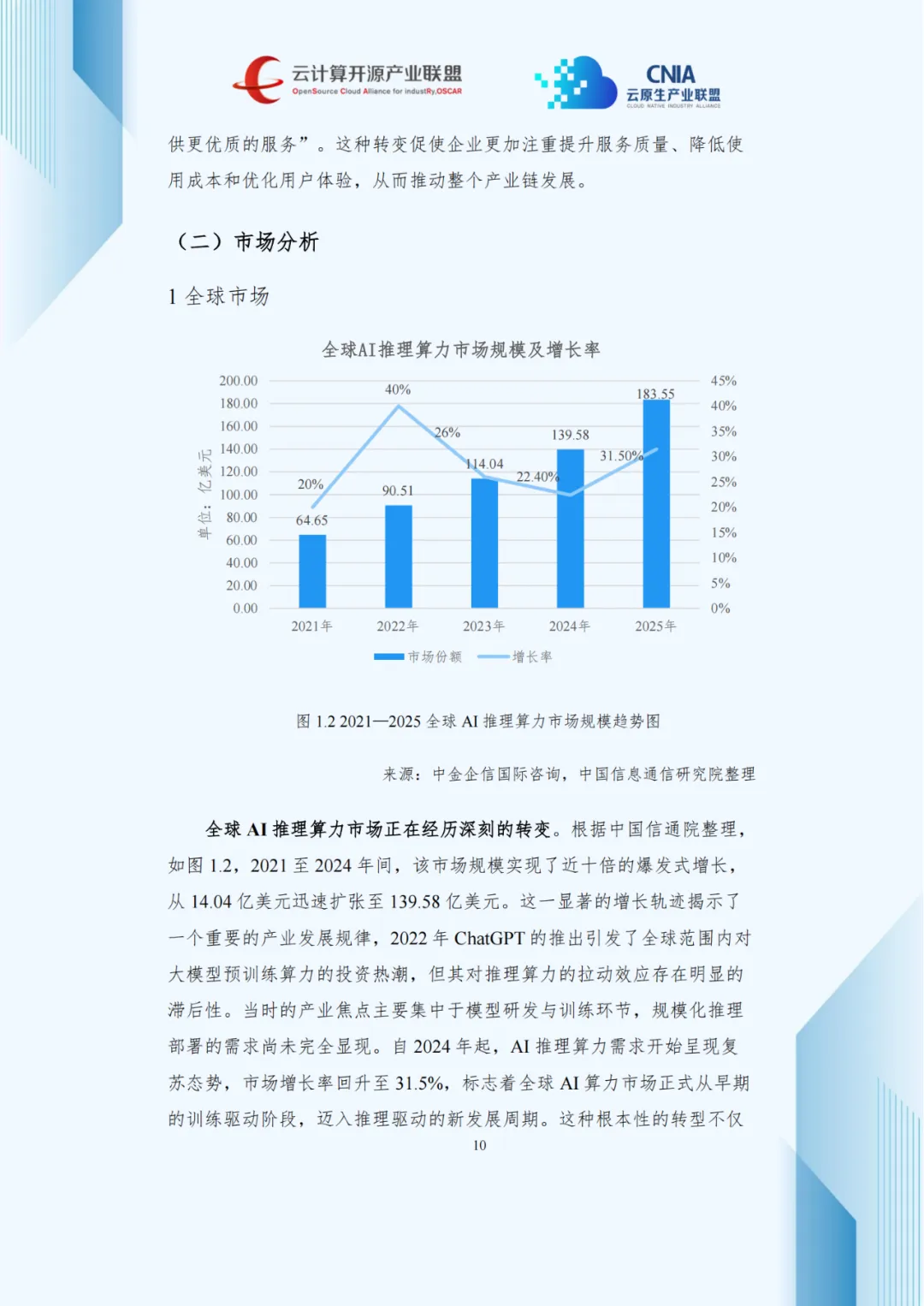
报告数据显示,2021至2024年全球AI推理算力市场规模实现近十倍增长,从14.04亿美元扩至139.58亿美元。ChatGPT在2022年引爆预训练算力投资热潮,但对推理算力的拉动存在滞后性,2024年推理算力需求复苏,增长率回升至31.5%,全球AI算力市场正式进入推理驱动周期。
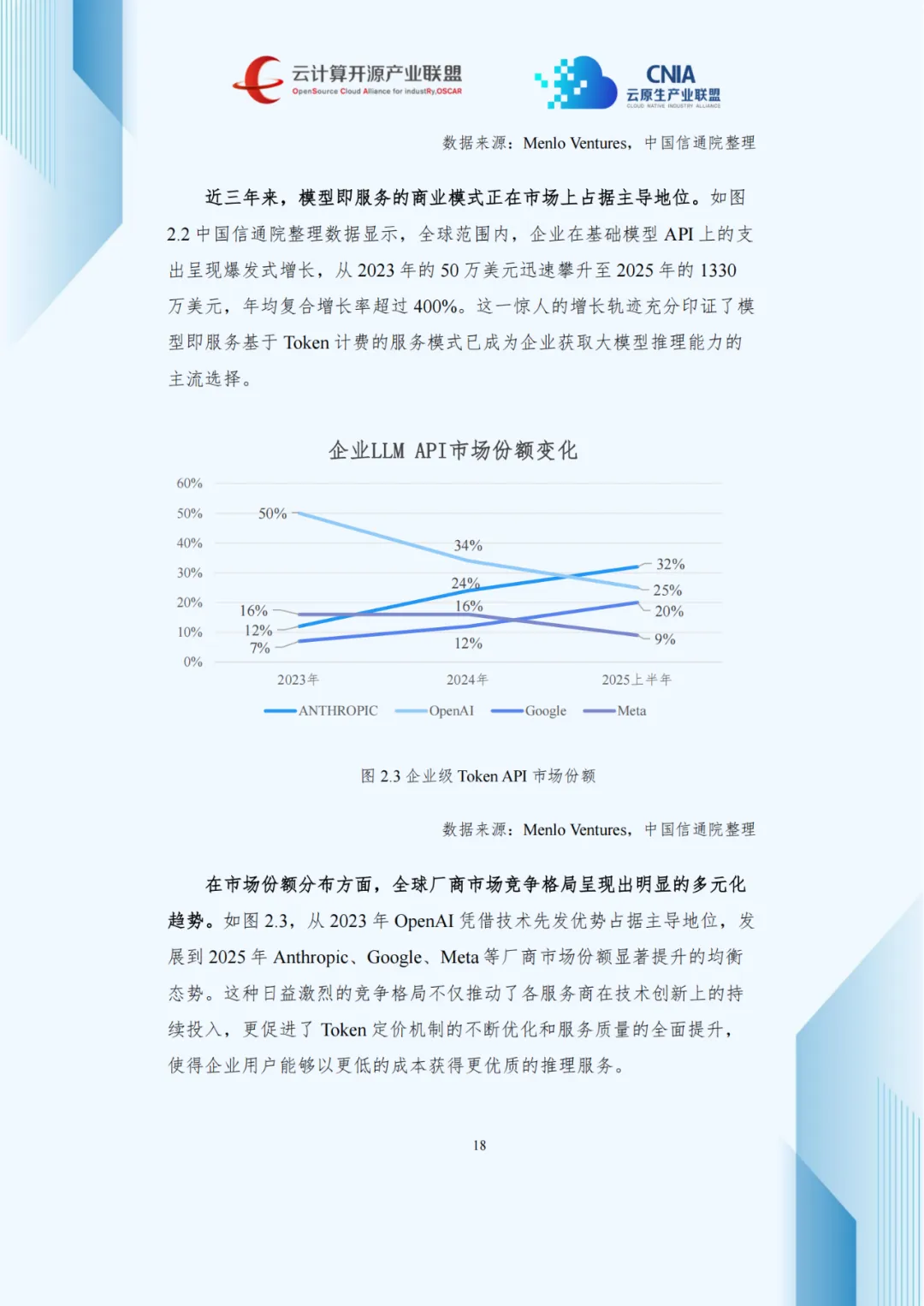
这一转型源于多重因素:大模型技术成熟支撑商用落地,智能体技术催生密集推理需求,开源模型降低使用门槛。Gartner数据显示,2025年全球超75%企业通过API调用推理服务,Token计费成主流。亚马逊、谷歌、微软三大云厂商的“模型市场”生态占据超65%全球份额,形成强集聚效应。
1.2 中国市场的“弯道超车”与本土特色
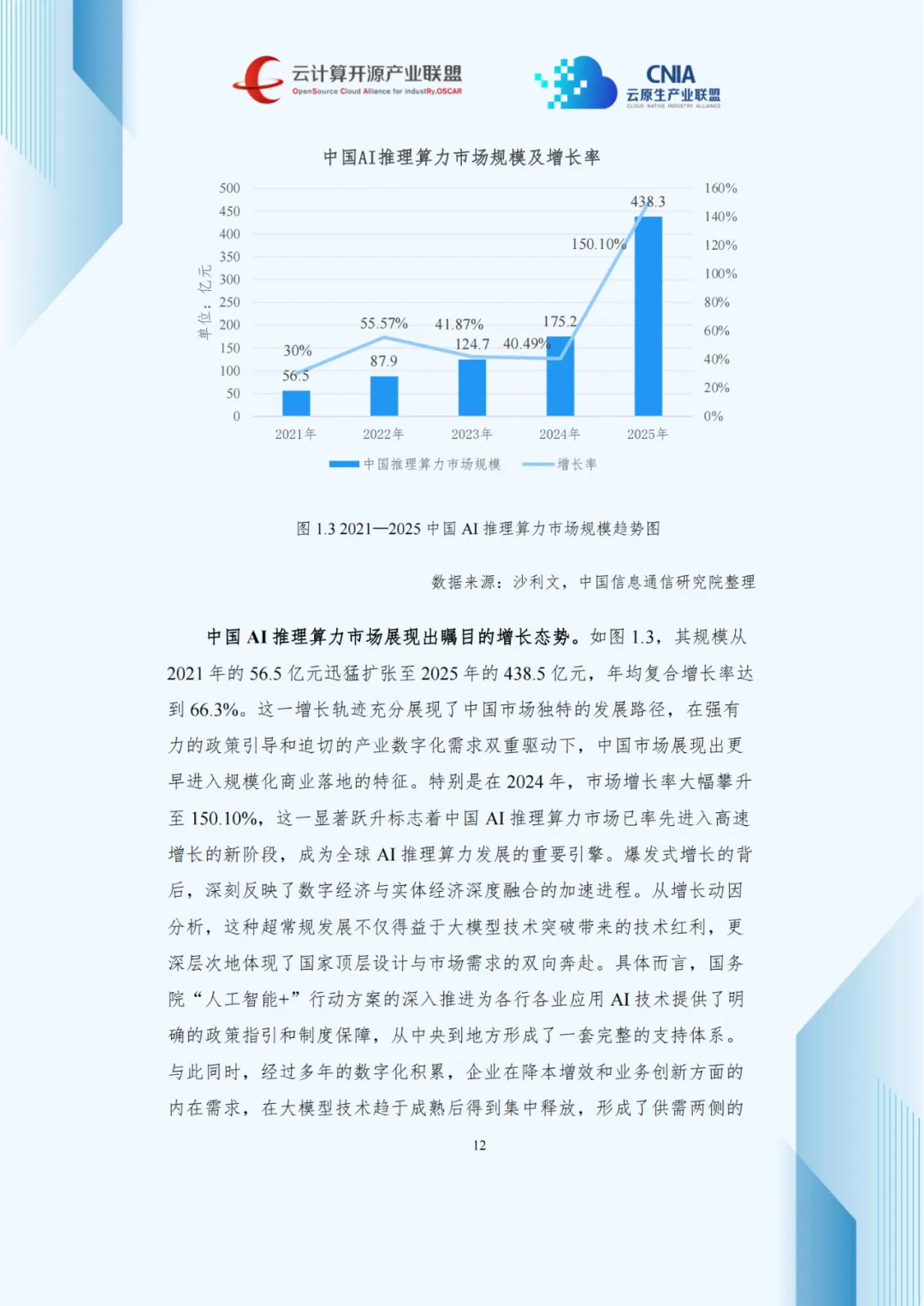
中国AI推理算力市场增速更为迅猛,2021至2025年规模从56.5亿元扩至438.5亿元,年均复合增长率达66.3%,2024年增长率攀升至150.10%,率先进入高速增长阶段,成为全球核心引擎。
这一态势得益于政策与市场双向驱动:国务院“人工智能+”行动方案提供政策支撑,企业降本增效与创新需求在技术成熟后集中释放,形成供需良性互动。
国产化生态是中国市场的鲜明特色,华为昇腾、寒武纪等国产芯片推理性能持续提升,在特定场景可媲美国际产品,尤其在政务、金融等安全敏感领域,国产算力方案已成为首选。
二、部署方式演进——四元格局下的场景化选择
2.1 从单一模式到多元化部署生态
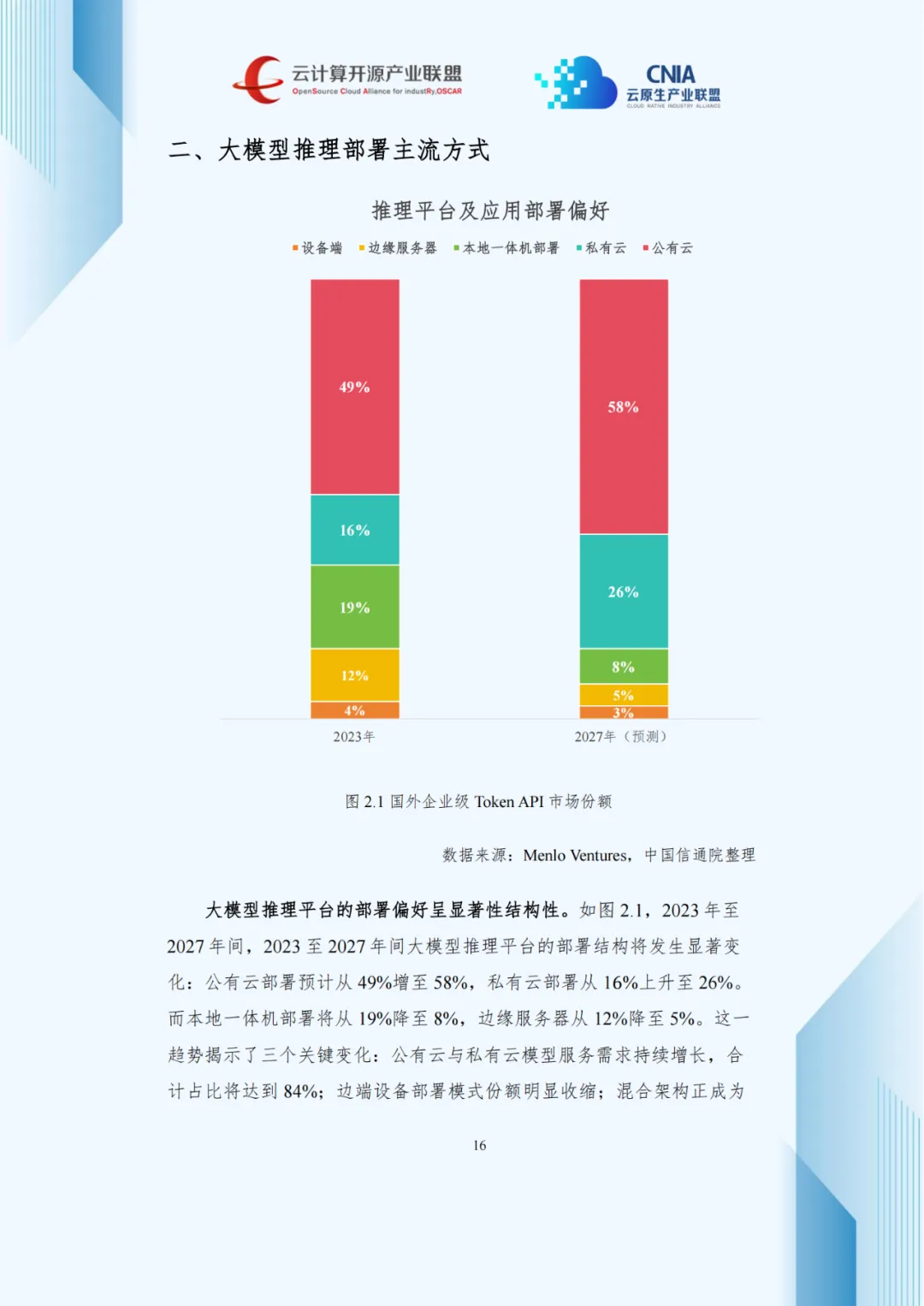
报告梳理出四种主流推理部署方式,覆盖不同场景需求,在技术架构、成本、安全及运维复杂度上各具差异。
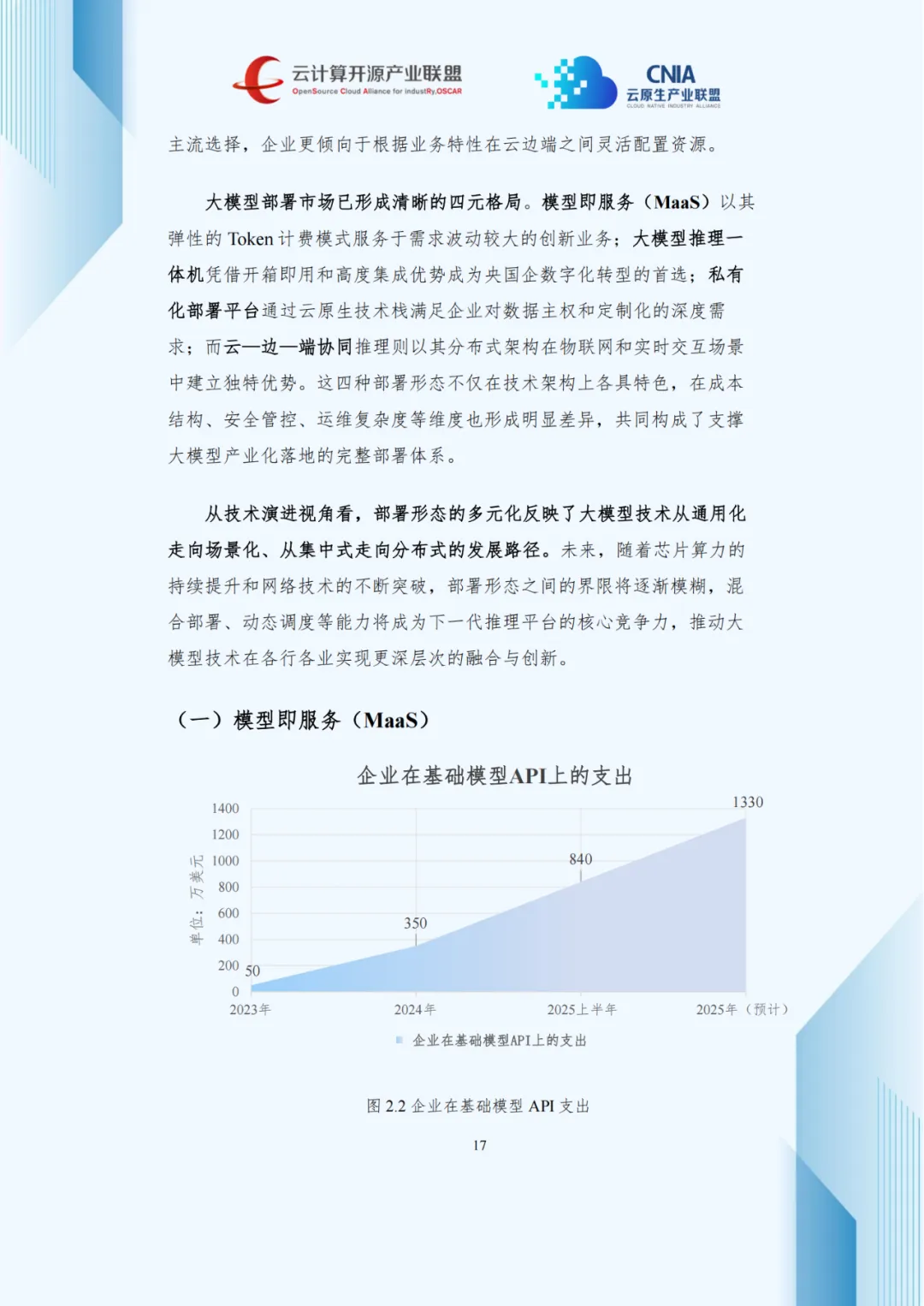
模型即服务(MaaS)凭借Token弹性计费与即开即用优势,成为中小企业首选。数据显示,2023至2025年企业基础模型API支出从50万美元增至1330万美元,年均复合增长率超400%,印证其商业化价值。
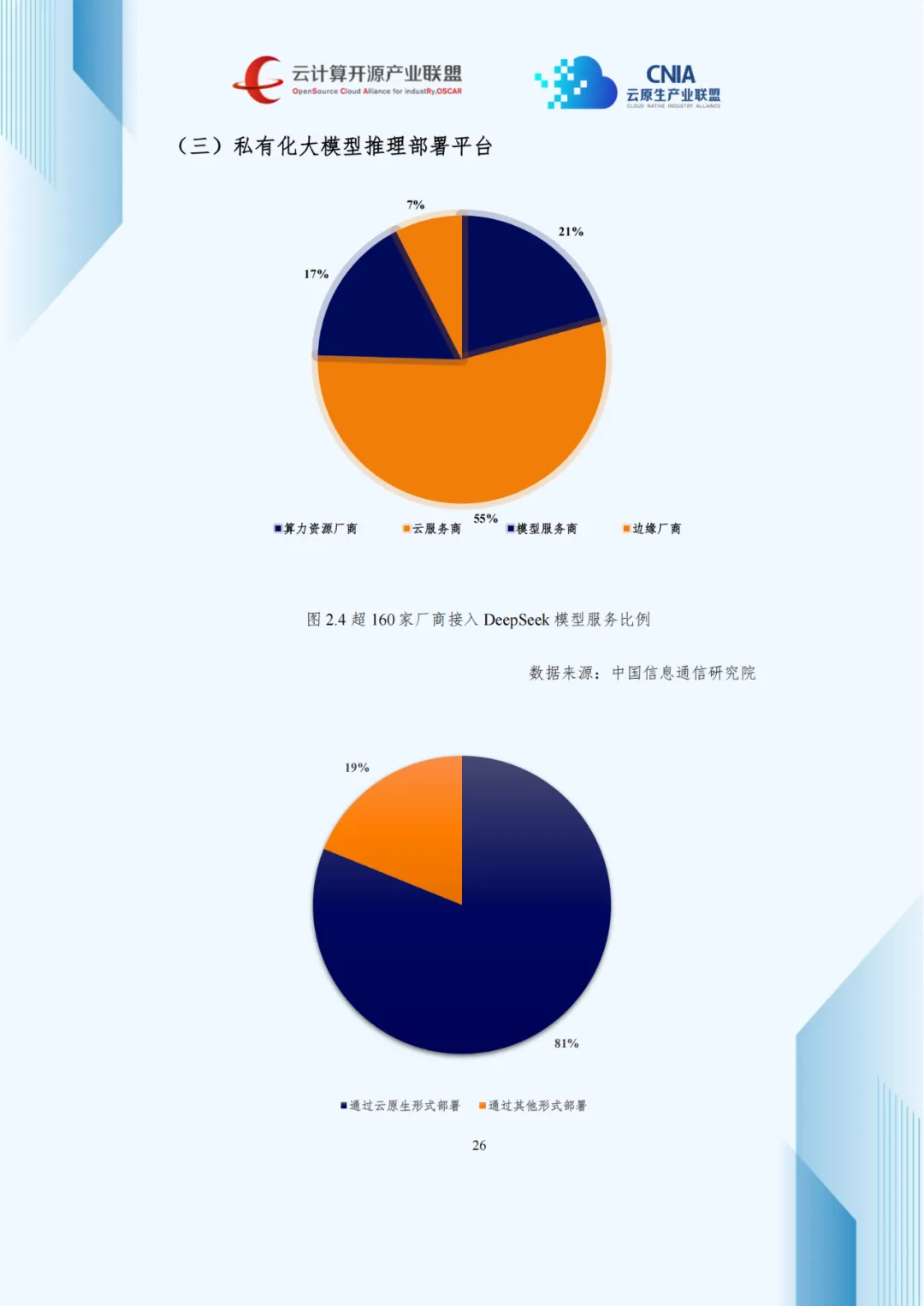
大模型推理一体机以开箱即用、数据不出域特点,受央企和政务单位青睐。截至2025年5月,45%央企完成DeepSeek模型部署,未来三年央企市场空间预计超五千亿元。
私有化部署平台依托云原生技术,满足企业数据主权与定制化需求,81%企业选择云原生私有化部署,云厂商占比达55%。
云—边—端协同推理凭借分布式架构适配物联网与实时场景,预计2027年设备端与边缘服务器推理负载占比达84%。
2.2 部署偏好的结构性变化与混合趋势
报告预测,2023至2027年部署结构将显著调整:公有云从49%升至58%,私有云从16%升至26%,本地一体机与边缘服务器分别降至8%和5%。公有云与私有云合计占比将达84%,混合架构成为主流。
企业普遍采用混合策略:核心业务私有化部署保安全,创新业务用MaaS快速验证,边缘场景靠一体机保实时性,体现产业生态的成熟度与场景适配能力。
三、技术优化体系——全栈协同实现效能突破
3.1 硬件适配的多元化发展路径
模型规模扩大与场景复杂化推动硬件生态多元化,形成GPU、NPU、ASIC三类架构并行格局。
GPU凭并行计算能力与成熟生态主导通用场景,NPU聚焦神经网络计算、能效比突出,ASIC通过全定制设计实现极致性能功耗比,在大规模特定场景优势显著。
3.2 推理引擎的创新突破
vLLM、SGLang等新一代开源框架通过架构创新提升效能:PagedAttention技术缓解内存碎片,将显存利用率从50%-60%提至80%以上;连续批处理技术动态衔接计算资源,GPU利用率达60%-80%。
主流云厂商积极跟进,AWS Bedrock集成vLLM降本35%以上,Google Cloud Vertex AI融合RadixAttention技术,端到端延迟降低40%以上;火山引擎、硅基流动等国内厂商基于开源框架定制优化,实现性能与成本双提升。
3.3 模型层优化的多重路径
量化技术从INT8统一量化升级至混合精度策略,在保留95%以上性能的同时,显存占用降60%-70%,推理速度提升2-3倍。
知识蒸馏通过“教师—学生”框架迁移能力,渐进式蒸馏使7B学生模型可达70B教师模型90%性能,推理速度提升5倍以上。
混合专家模型(MoE)以稀疏激活平衡容量与效率,DeepSeek等模型的细粒度设计,使千亿级模型单Token仅调用数十亿参数计算,显著降低推理成本。
四、性能测试标准化——建立行业共识的关键一步
4.1 多维度指标体系的构建
规模化部署推动性能评估标准化,报告提出覆盖处理能力、服务质量、请求特征的多维度指标体系。
处理能力维度,QPS反映吞吐能力,TPM衡量语义单元处理效率,卡均TPS分别体现提示词处理与文本生成性能;服务质量维度,TTFT影响响应感知,TPOT决定输出流畅度,E2E延迟与请求成功率保障业务可用与稳定。
4.2 测试环境的标准化与负载设计的真实性
标准化测试环境需覆盖软硬件及配置参数,硬件建立设备档案,软件采用版本锁定确保一致性。
测试负载基于真实场景构建,以公认数据集为基础,匹配实际输入输出分布特征,负载生成器采用双模式架构适配不同测试目标。
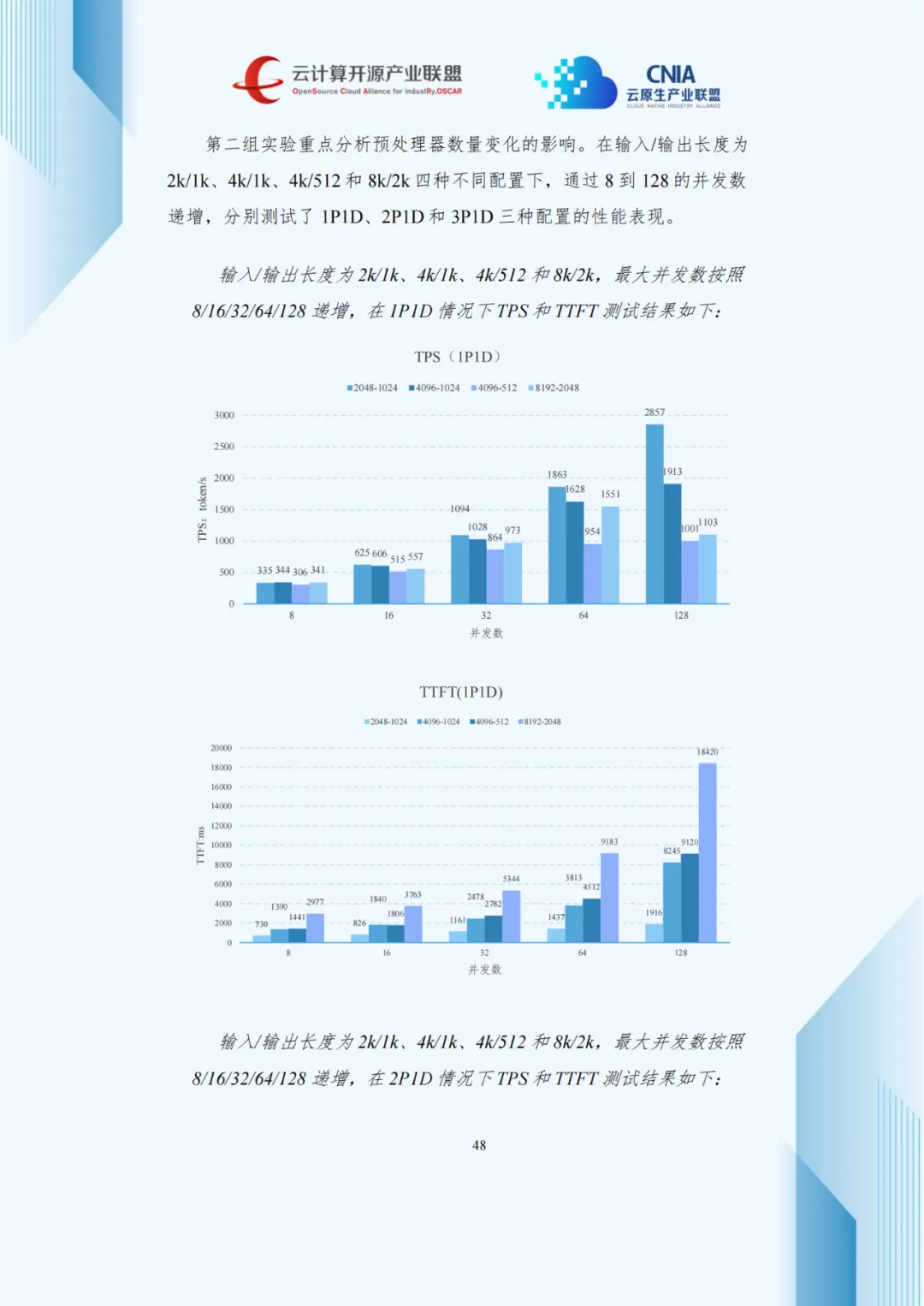
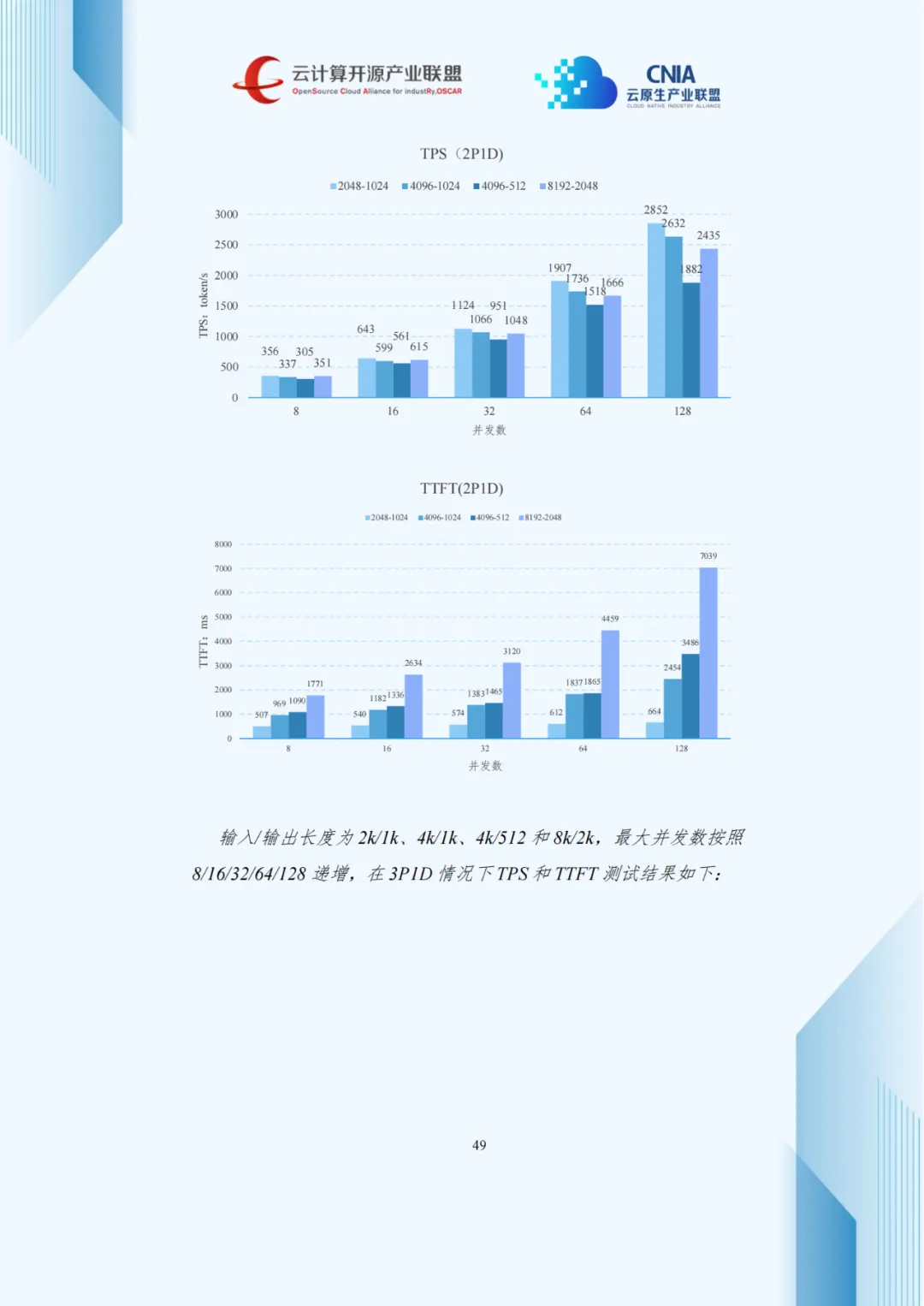
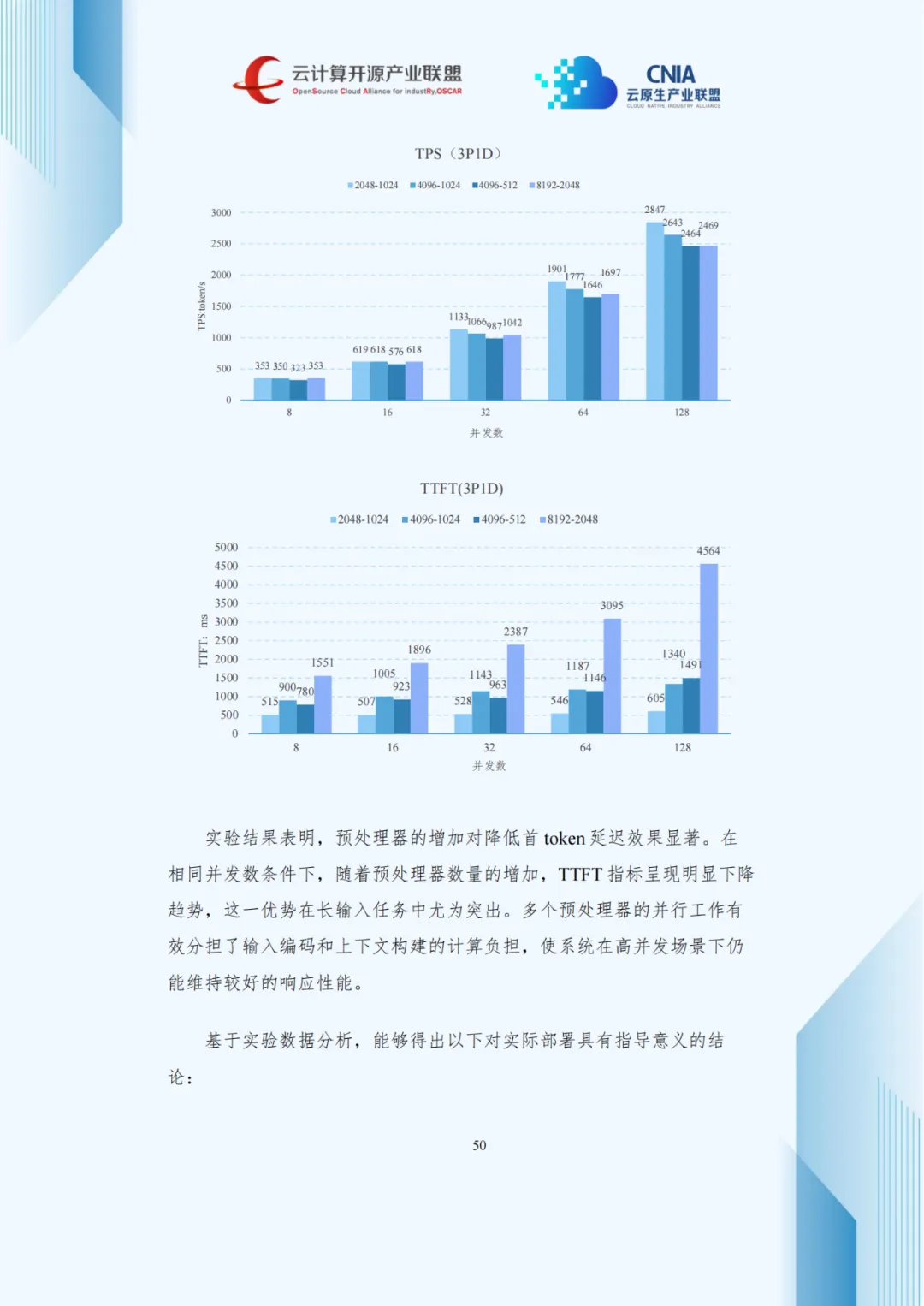
4.3 P/D分离架构的性能特征分析
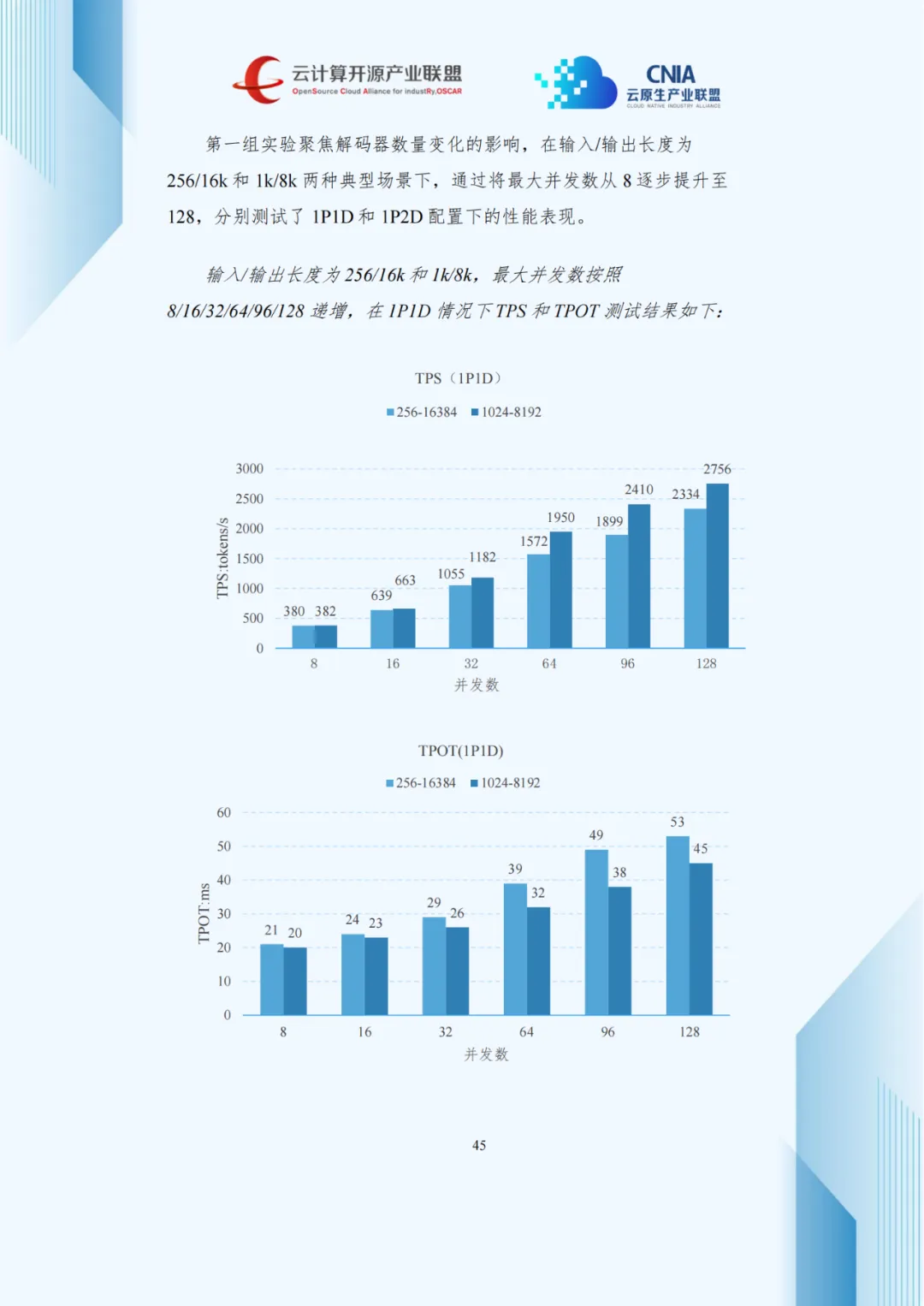
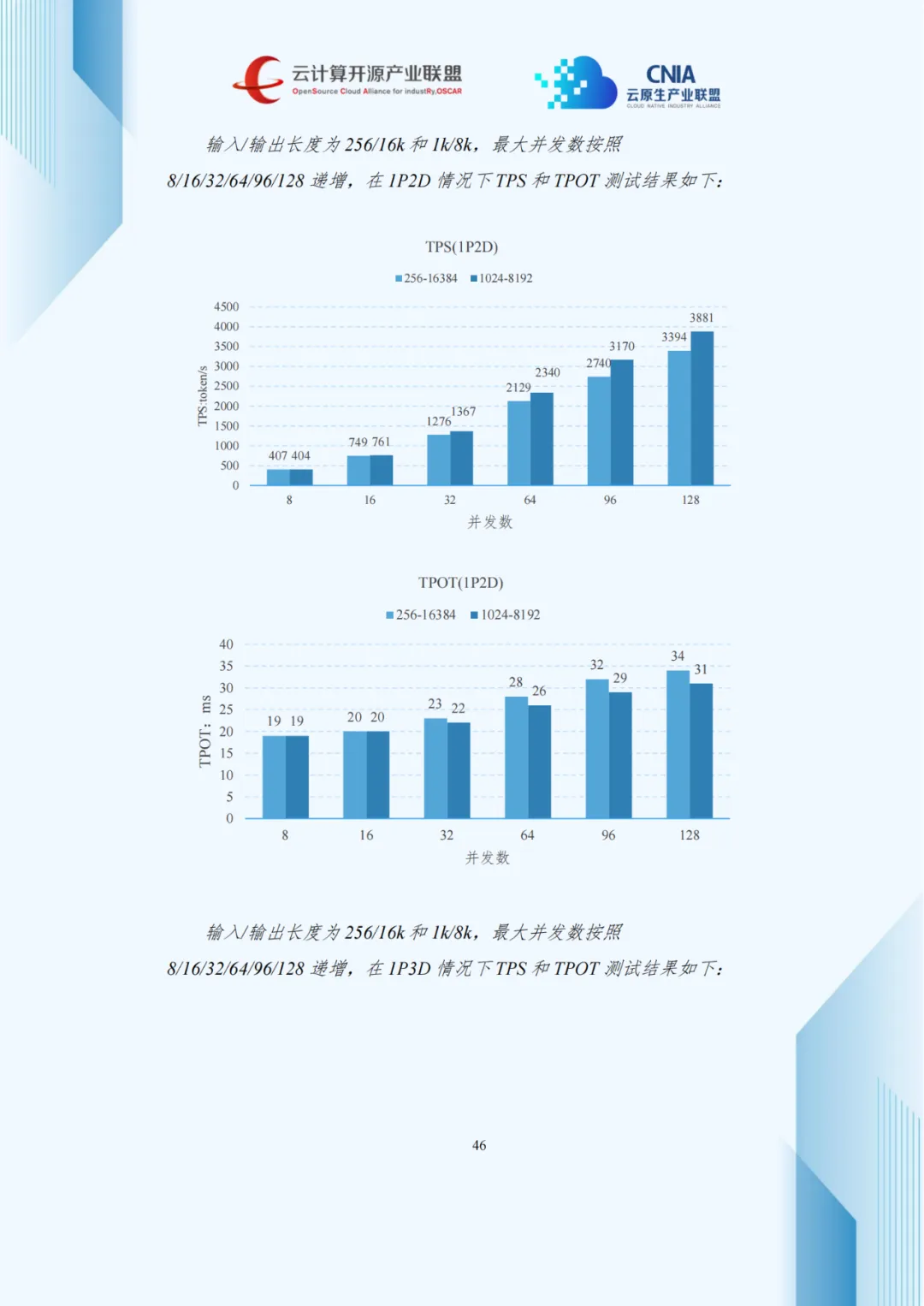
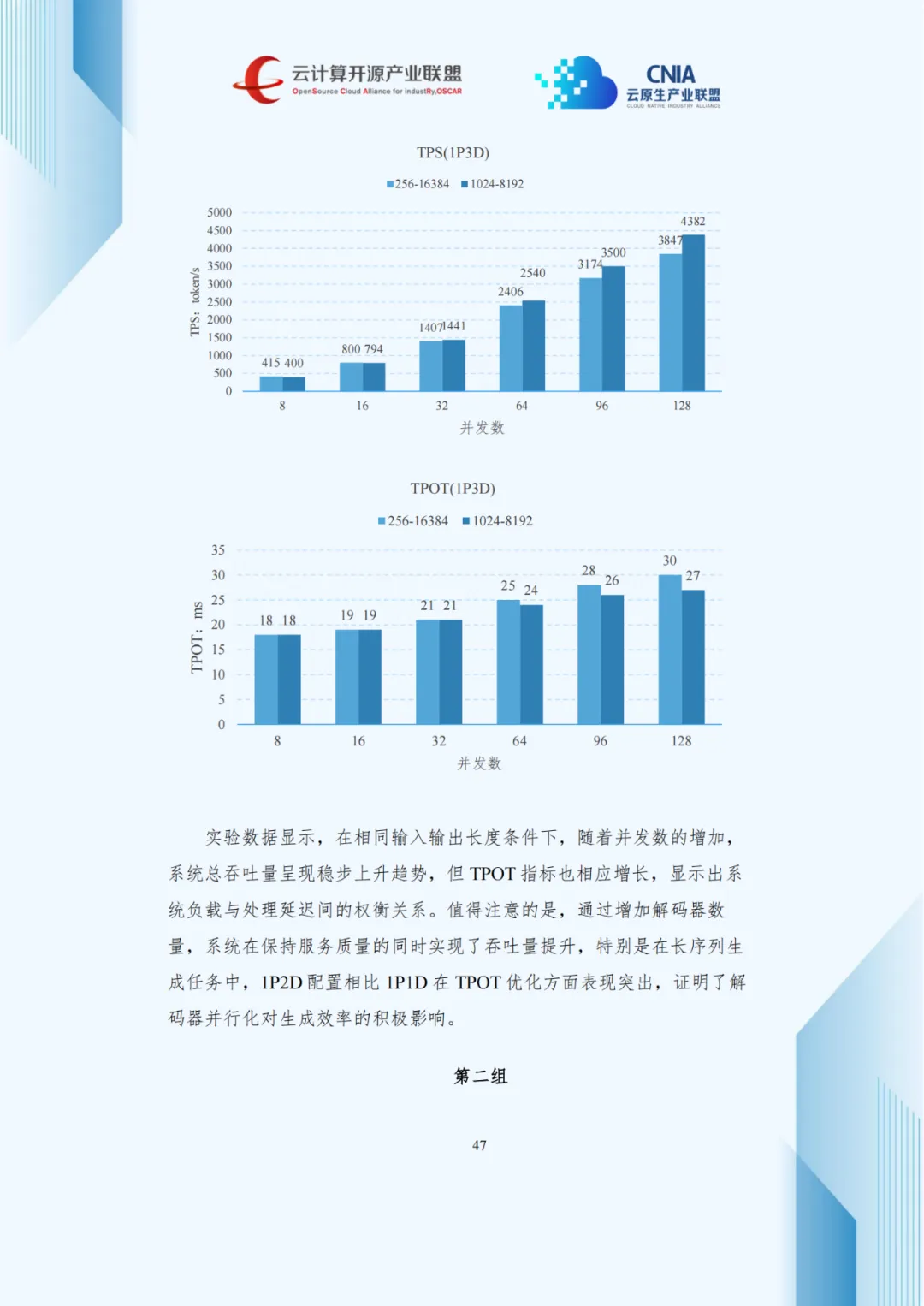
压测数据显示,并发数增加使吞吐量上升但TPOT延长,呈现负载与延迟的权衡关系。1P2D配置在长序列生成任务中优化TPOT效果显著,3P1D配置较1P1D使TTFT降低40%-60%。
五、行业实践案例——从技术突破到业务价值
5.1 科研领域的效能提升
哈佛大学Calmon实验室与IBM合作,构建GPU集群并集成vLLM框架,形成协同优化方案,AI安全检测推理速度超2000词元/秒,较原设施提升近3倍,部署周期从数周缩至数天。
5.2 国产算力的全栈突破
开普云针对国产算力痛点,在芯片适配、框架与模型层深度优化,128K长上下文任务中,吞吐量提升1.5倍以上,延迟降低40%,国产芯片利用率从35%升至72%,达业界先进水平。
5.3 金融行业的智能化转型
中信证券引入硅基流动SiliconLLM引擎,构建三层技术架构,部署19个数字员工应用,累计处理请求超2亿次、Token数千亿规模,显著提升服务效率、降低成本并强化风控。
5.4 制造业的私有化部署创新
某头部机器人厂商采用天翼云CCE One平台构建私有化集群,实现数据全程内网流转,交付周期缩至6个工作日(缩短80%),响应时间从800ms降至520ms(提升35%),可支撑500+并发请求。
六、未来挑战与发展建议
6.1 产业面临的系统性挑战
大模型推理规模化部署仍面临多重挑战:成本压力制约普及,标准化缺失阻碍协同,人才短缺、生态碎片化加剧集成难度,安全合规提出更高要求。
6.2 构建“五位一体”发展体系
针对上述挑战,报告提出“技术标准—创新生态—人才培养—政策环境—商业模式”五位一体发展建议:加快制定推理性能测试标准;构建产学研用协同创新机制;培养算法、系统、硬件复合型人才;加大基础软硬件研发支持;探索效果分成等新型商业模式,降低企业使用门槛。
结语:推理优化——AI规模落地的“最后一公里”
《大模型推理优化与部署实践产业洞察研究报告》清晰勾勒出产业现状与趋势。随着开源普及、算力降价、技术迭代,大模型正从专属工具升级为千行百业基础设施。
推理优化与高效部署是连接技术与价值的核心纽带,唯有打通这“最后一公里”,才能充分释放大模型的商业与社会价值,赋能实体经济,为数字经济与新质生产力发展提供坚实支撑。

















































AI科普馆:打开AI世界之窗