随着自动驾驶技术进入城市场景,面临的挑战确实变得更加复杂和困难。传统的小模型在处理大规模数据、感知复杂环境和解决长尾问题方面存在局限性。因此,引入大模型技术已成为业界的一个趋势,以满足高级别自动驾驶的要求,增强泛化能力具有重要作用。它能够帮助自动驾驶汽车更好地理解和应对复杂的城市环境,实现更安全、高效的出行体验。值得注意的是,有监督的标注数据是大模型应用成功的关键之一。
有监督的标注数据用于训练大型深度学习模型。通过将输入数据与其对应的标签进行配对,模型可以从中学习到输入与输出之间的关联性。这使得模型能够逐渐优化权重和参数,提高对数据的预测和决策能力。
有监督的标注数据提供了多样性和广泛性的训练样本,对模型的泛化能力具有关键影响。通过在标注数据上进行训练,模型能够学习到不同场景下的特征和模式,并推广到未见过的数据中。这使得模型能够在现实世界中适应各种复杂情况,并做出准确的预测和决策。
有监督的标注数据也用于评估大型模型的性能和准确性。通过将已知标签的测试数据输入到模型中,可以计算模型的预测输出与真实标签的差异。这有助于评估模型的性能并确定是否需要进一步优化或调整。
中汽智联基于已有基础对深度学习算法在自动驾驶数据标注方面进行了优化,围绕主动学习、弱监督学习、外部知识的融入、多模态标注以及迁移学习和远程监督等方向进行。
为解决点云数据标注成本高昂的问题,自主研发了面向无标签点云数据的自动化主动学习深度学习算法,通过迭代地选择最有信息价值的数据样本,并将其标注为训练数据,从而不断提高算法的性能和准确性;
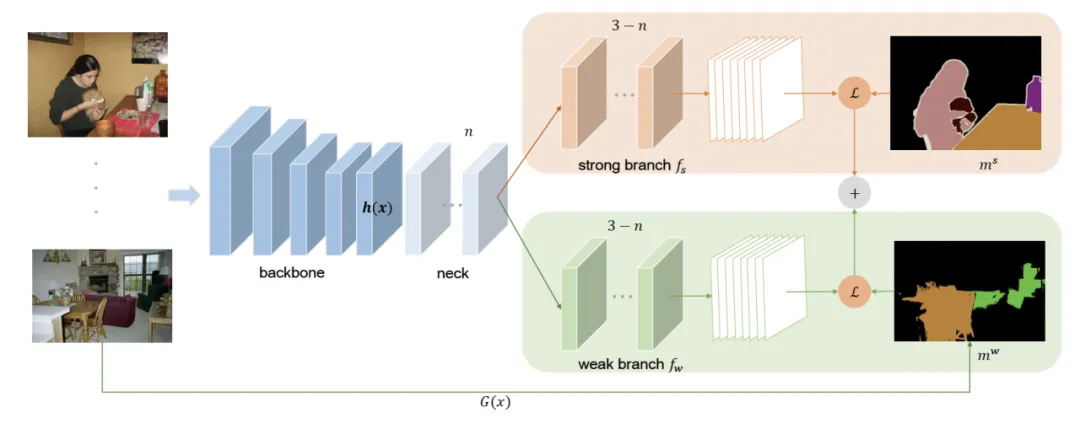
强弱双分支网络网络模型
为有效解决人工标注精确率低的问题,自主研发了面向错误标注数据集的PU弱监督自动化深度学习算法,结合了PU学习和弱监督学习的思想,能够利用正例样本和未标注样本进行模型训练,从而提高深度学习算法在错误标注数据上的性能和鲁棒性;
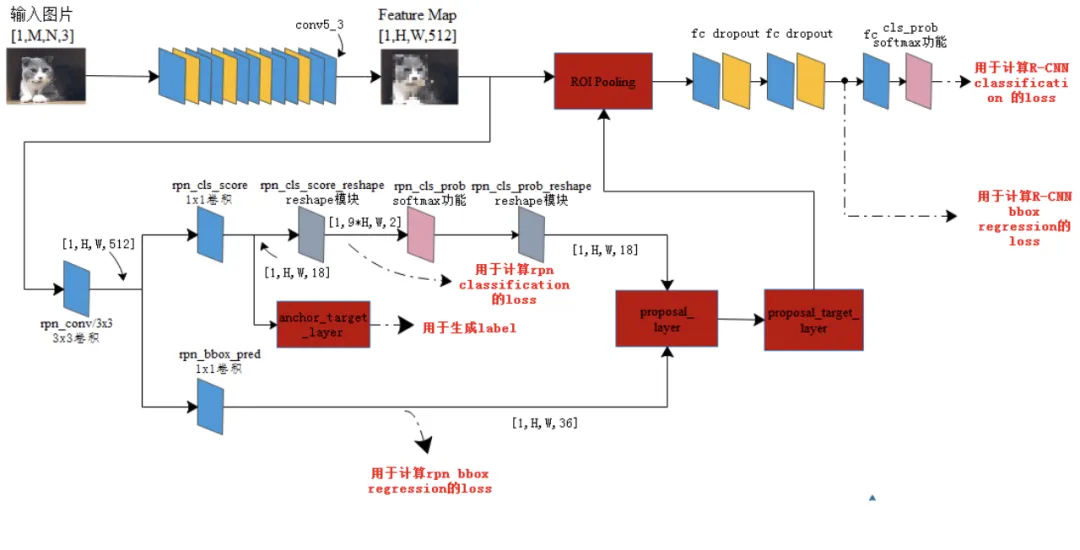
面向视频级解析的主动学习和模型增强技术
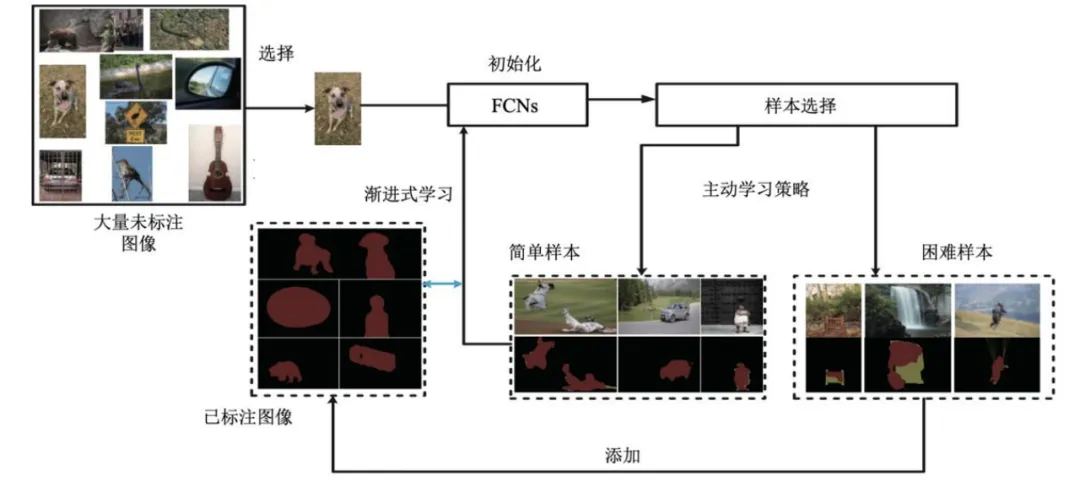
面向像素级解析的增量式人机协同学习模型
为解决千万级别原始图像数据的标注问题,自主研发了面向半标注数据集的半监督自动化深度学习技术,利用有标签数据的标签信息和未标签数据的无标签信息,通过自动化的方式提高深度学习算法在半标注数据上的性能和泛化能力;
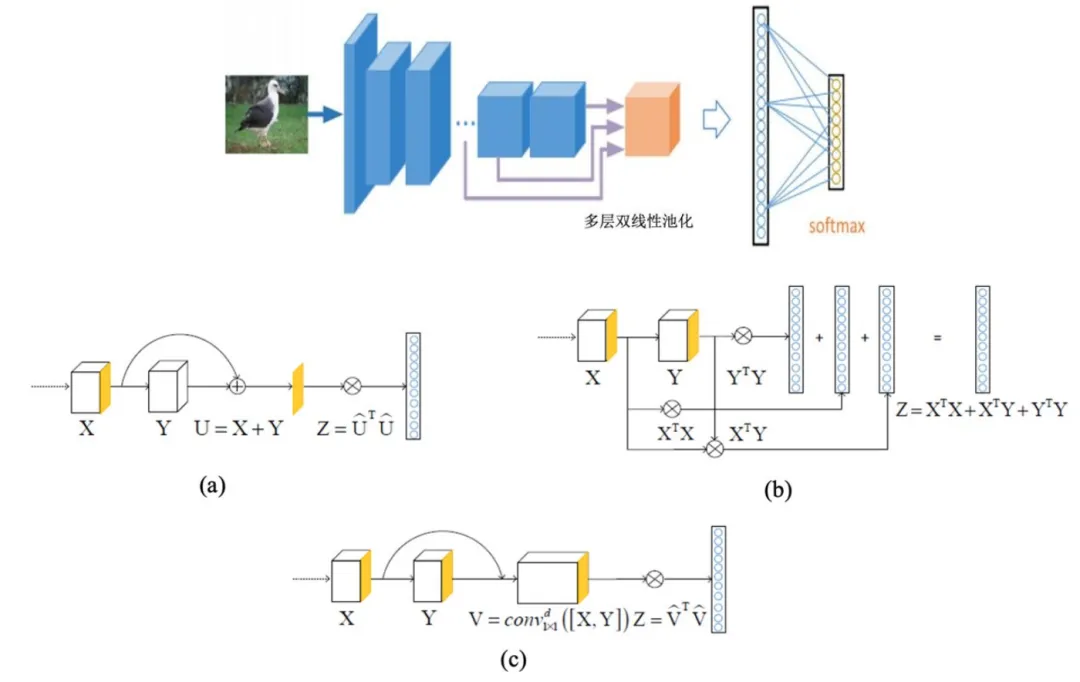
多层融合二阶统计卷积神经网络模型(HLBP)
为解决人工标注工具链不成熟的行业问题,自主研发了面向偏标注数据集的自动化的符合实例学习的弱监督深度学习技术,自动修正偏标注数据中的错误或不完整标签,并利用相似样本之间的关系进行学习,从而充分利用偏标注数据的信息。
特征级堆叠后降维的双线性网络模型
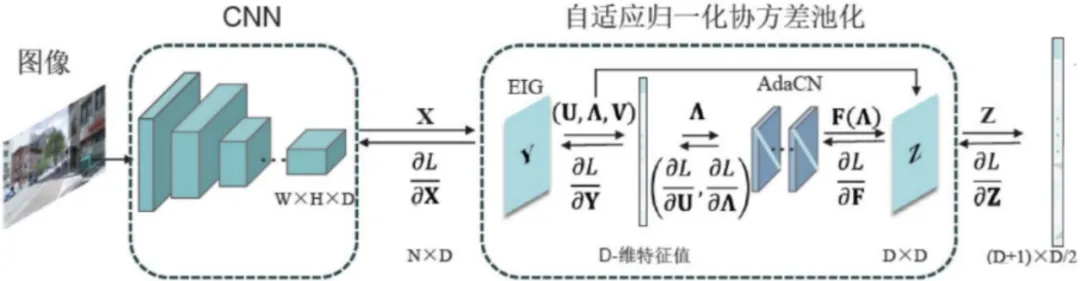
基于自适应归一化协方差池化的深层神经网络模型
未来中汽智联自动驾驶数据标注的业务方向将聚焦于高精度标注、多模态标注、场景与语义标注、异常和边界条件标注,同时提升实时和迭代标注的能力,为自动驾驶技术的进一步发展提供更准确、全面和适应性强的训练数据。
联系人
李子焱
袁悦

中汽数据有限公司
面向3060双碳、数字化转型、“新四化”等产业发展趋势和创新发展需求,中汽数据有限公司以“一基两翼”为发展框架,深入开展节能低碳、绿色生态、市场研究、司法鉴定等工作,精准布局智能网联、智能座舱、工业互联网(工业软件)等创新领域,形成以“国家级汽车产业数据中心、国家级汽车产业链决策支撑机构、国家级泛汽车产业数字化支撑机构”为核心的业务定位。