



元启长期关注大算力、大芯片赛道。以 ChatGPT 为里程碑的多模态生成式大模型将原来局限于行业应用的 AI 业务快速扩展至市场规模、用户用量指数级增加的终端消费用户场景。
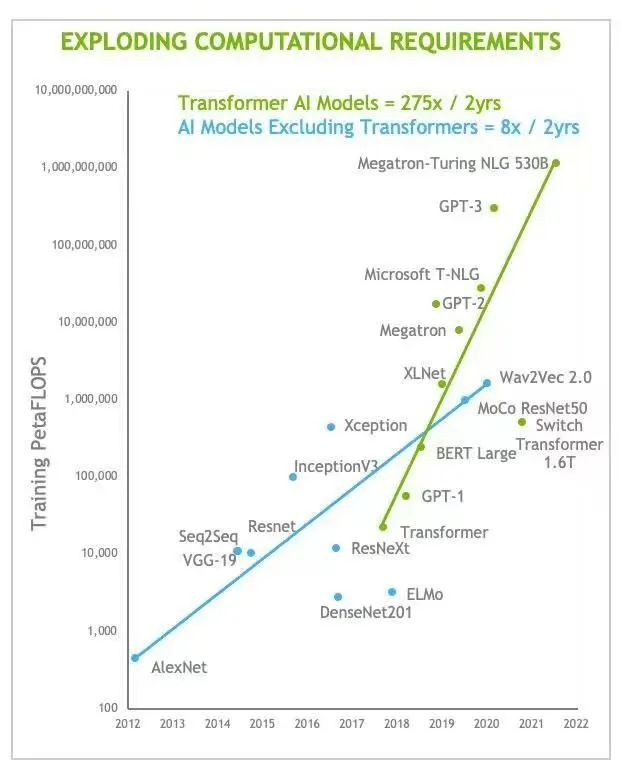
生成式大模型在数据用量及算力用量上都对已有的算力基础设施提出巨大挑战。要加速新 AI 工具在中小企业、个人生产作者的普及,亟须对现有在算力利用率、能效比已达瓶颈的 AI 加速器进行创新。在3月15日 The lnformation 的报道中,微软仅在目前的小范围预览阶段就已经遇到无法解决的 GPU 计算资源短缺问题。
创新的道路是艰难且漫长的,但它是所有创新应用普及的基石。我们希望在这个研究中完整回顾GPU,特别是英伟达的 scalar-based GPU + CUDA 生态如何逐步成长为 AI 行业事实上唯一的基础设施平台,企图找到其中的本质原因,以及未来能够切实看到的创新机会。

为什么研究AI大模型行业?
1、微软 Bing 搜索业务在公布上线整合 ChatGPT 的预览版一个月后快速超过 1 亿 DAU,成为基于 transformer 网络的AI应用向消费终端用户场景的里程碑;
2、覆盖图片、文本及视频的多模态主动生成网络代表 AI 应用由以往代替基础机械式工作/操作向更广泛的生产力辅助工具演变;
3、多模态及主动生成大模型所需的训练数据量,及其所需的后续迭代数据量,相比传统 AI 应用产生多个数量级的提升,在传统 AI 基础设施已在架构上达到能效比瓶颈的环境下产生垂直行业产品需求。
02
基础数据
1、GPT 模型发布于2018 年,参数量1.17 亿预训练数据量5GB;GPT-2 模型发布于2019年,参数量15亿,预训练数据量40GB;GPT-3 模型发布于2020年,参数量1750亿预训练数据量45T;
2、2023年公开预览的 ChatGPT 基于GPT-3.5模型,具体参数量及预训练量未知,已知信息仅有截至发布时使用了2021 年以来国际互联网上大部分公开内容,以文本信息为主;研究撰写于2023年3月,根据新闻报道及行业人士预测,截至发文时已经公布的 GPT-4模型参数量将达100万亿,考虑到下一代 GPT 模型将同时具备图片及视频多模态生成能力,其所需预训练数据量相比 GPT-3/3.5 将有指数级增长;
3、Nvidia 是 OpenAl 训练基础设施里的唯一 AI 加速卡供应商,也是服务器 GPU (主要销售驱动为AI市场)几乎100%份额的供应商,其计算业务 (服务器GPU) 收入由 FY21年的68.41亿元美元,FY22 年的 110.46 美元,快速增长至FY23的 150.68 亿美元,并在FY23 这块业务历史上首次超越英伟达以往的现金牛图形业务。服务器GPU 业务年复合增长率超过 30%,其中中国区销售稳定占全球销售的 1/3。
03
为什么是英伟达?
1、英伟达是可编程 shader 及 GPU 通用计算产品的绝对先锋:随着计算机游戏及图形应用对顶点及像素的数量及不同绘制方式需求的快速增加,英伟达于 2001 年首次推出在传统固定硬件单元 (fixed-function core)之外加入可编程的标准着色器(shader, 下文中 SM 及 CU泛指同概念)单元,对应产品为 GeForce 3,可编程 shader 自此成为图形 GPU 和游戏/图形行业开发的标配;随着计算机智能应用和互联网数据量的快速增长,研究人员发现用于快速执行简单重复计算的GPU shader 单元是承载AI模型训练及计算的最理想载体,英伟达在这一趋势下快速于 2008 年推出市场上首个着重用于通用计算的 GPU 产品 G80 Tesla,相比传统图形GPU,Tesla 系列弱化了用于图形绘制的固定硬件 fixed-function core,着重对可编程 unified shader(streaming multi-processor,或 computing unit)进行补强;
2、在推出G80的同时,为加速通用计算行业发展,英伟达不断通过吸纳及资助高校研究人员的方式,在行业开放标准 OpenCL 的基础上修改并私有化实现自有的计算标准 CUDA,不断推动 CUDA 成为AI 和科学计算行业的事实标准。这让 CUDA 和英伟达通用计算 GPU(GPGPU)成为 AI行业发展早期至今的唯一事实标准;
3、截至今天,从高校、开源社区、开发工具供应商,到企业研发人员都以英伟达 GPU 及CUDA 编程语言作为 A 应用编写、研发以及创新的基础,所有新出现的主流AI应用及工具都以英伟达 GPU 训练、执行及CUDA 编程后的运行结果作为迭代和评判进步的标准这种行业整体思维的共识在 15 年后的今天已经无法被逆转;
4、对于任何研究、研发人员及企业而言,将 AI 应用迁移至与英伟达 GPU 不同的硬件架构或使用不同于 CUDA 的编程语言,不仅意味着在这个工作中所有已经被编写并验证的 AI 网络及其算子需要按照新的方式实现 (相当于完全重写),更意味着这种繁重并且耗时的工作不产生任何经济效益;
5、因为客户业务的多样性,以及当下大模型的多模态(同时支持文档、语音、图片、视频生0成)强趋势,使仅适用于某一种网络的 ASIC/DSA/DSP/RISC-V 产品呈现出很大的局限性,这也是 Google 在核心搜索业务研发放缓并花了大量资源最终仅部分迁移至 TPU 后在大模型应用上落后的重要原因。
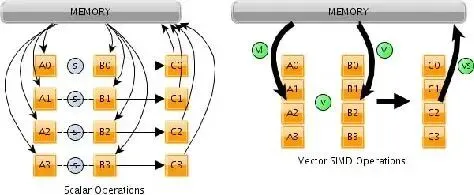
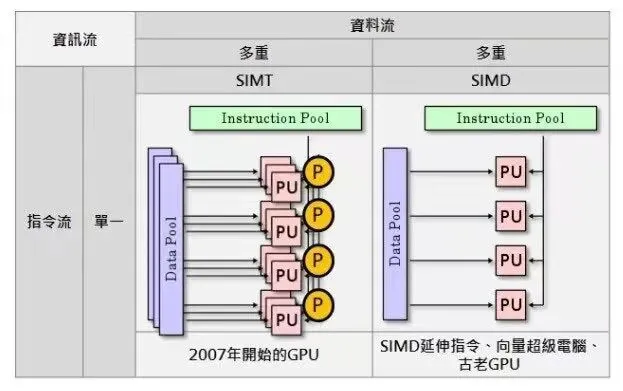
6、很容易被忽略的一个原因。因为英伟达的远见,他至今仍然是主流公司中仅有使用 scalar架构计算单元(shader)的一家,包括 AMD (因为在收购 ATI 后缺乏选代和战略能力)和其它移动简化版GPU在内都还在使用陈旧的 vector shader 计算单元架构,这使得在运行AI和通用计算业务时,后者的性能天然的只能是前者的 1/4,且对软件开发者而言很难做好软件调度。这个后面会展开提到。
04
主流 GPGPU 的瓶颈
1、因为英伟达的发展历程,以及半导体行业的本质规律。GPU 产品的出现由图形应用及游戏主导,到2022年上半年为止,包括英伟达在内的 GPU 企业现金生业务均为图形GPU产品,图形场景成为 GPU 企业和产品设计的基础,用于计算的 GPU 产品线仅在优先迭代的图形产品架构上进行固定功能核心屏蔽,及可编程shader 中用于张量计算的 Tensor Core 补强。以英伟达目前在服务器市场出货量最大的 Turing 架构为例,一个 die 上SM 面积占比在 50%左右,用于辅助 AI 计算的 Tensor Core 面积占比在 10% 左右;

2、这一趋势决定了已有的 GPGPU 产品在 AI 场景下,芯片面积、芯片资源调度及对AI计算有利的内存池配置都非最优;
3、以 OpenAl 官方博客数据为例,他们计算在实际训练中,GPU 资源的利用率仅为约 33%,存在极大的资源浪费,这一情况在全球AI应用场景中非常普遍;
4、以国内大型互联网企业典型的14KW (电源负荷)机柜为例,一个数十万机柜的常见数据中心场景下,因能耗审批上限及物理空间限制,GPGPU的 Perf/W 及算力有效利用率成为实际应用中最有用的指标。以英伟达主流产品30%的利用率为例,在此基础上存在超过两倍的计算资源利用率提升空间,以及数亿元人民币的电量节省空间。
05
通用 AI GPU/GPGPU 架构创新的关键
1、不存在业务场景仅包含AI 网络的客户场景,客户会用英伟达 GPU 及CUDA 语言编写同时包含常规功能程序及多种不同深度学习网络的综合业务,这决定了任何致力于应用于 AI的通用计算产品都必须在高能效比的前提下兼容真实的桌面架构可编程 shader 及 CUDA API;
2、理论上,任何计算架构芯片都能实现一定程度的 CUDA API 兼容。但要在客户的经济模型和计算效率上实现至少不劣于英伟达产品的性能,只有开发与英伟达相同架构的桌面级可编程shader一个事实上存在的技术路线;
3、实现对于英伟达 CUDA API 的兼容,让行业业务开发者愿意在生产环境中使用新产品,对团队的GPU驱动、编译器、计算库研发经验提出超高要求,行业中经历过商业市场成功验证的团队仅有四个且成员至今分布高度集中 (后面会总结) ;
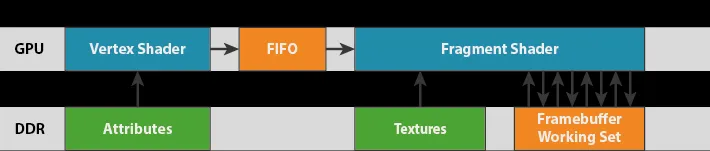
4、桌面 GPU 的架构,与arm Mali,lmagination 及 Qualcomm Adreno 等移动 GPU存在本质的不同。桌面 GPU 架构及编程模型是 immediate-mode rendering,移动简化版 GPU 架构及编程模型是 tile-based rendering。
5、
1)、immediate-mode rendering:
2)、tile-based rendering:
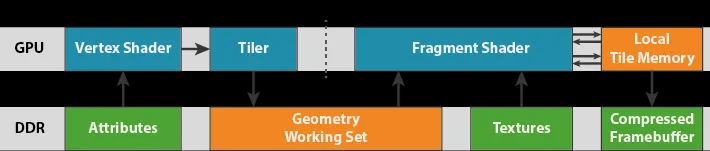
6、简单来说,AI 计算对桌面 GPU 的精确硬件管理并行的工作逻辑存在强依赖并且天然耦合,这类计算应用在移动简化版 GPU 上会因为后者引入的 Tier 会造成不必要的额外内存延迟及计算精度降低,这在以 AI 业务场景下是无法被客户接受的;
7、简化版移动GPU(以Imagination 和芯原全系列产品为代表)因为成本及功耗限制,在计算单元(SM,Streaming Multi-processor) 使用了古老的 VEC4 实现 (即 SM 中ALU 四个一组,因为早期游戏应用在执行过程中可以将颜色:RGB+Alpha (透明度)或坐标:XYZ+W (远近参数)天然合并为一次操作,但随游戏和计算应用的演进,复杂度早已远超这个逻辑),而不是英伟达持续领先市场的 VEC1 (SM 中单个ALU都可以执行不同计算,而不是每四个ALU 单次操作只能做一种计算),导致用户在使用移动简化 GPU 运行计算业务时需要通过软件对数据进行 packaging,但事实上无论是编译器开发者还是终端用户软件工程师都不会把精力花在这件事上,导致 VEC4 设计的 GPU 在运行计算业务时,性能天然的只有 VEC1 GPU 的 1/4。相应的,因为 SM 计算资源无法被合理利用,与SM 实现直接相关的内存资源也会在这一过程中形成浪费。这是一个简单的数学问题,也是一部分新创 GPU 公司在使用比英伟达昂贵得多的 7nm 制程和 HBM2 内存后性能依然不及英伟达产品的本质原因。
8、也有创业公司提到SIMD/MIMD 架构,这里不展开。事实上这是一种早就被GPU行业淘汰的早期图形加速卡设计概念,远在 GPU 用于通用计算之前。当下主流 GPU 有且仅有SMIT 架构。

9、OpenAl 震惊行业的 ChatGPT/GPT-3.5 模型由包含 10000 张英伟达 V100 计算卡的基础设施训练完成,英伟达 V100 仅使用已经成熟的台积电 12nm 制程,及性价比极高的消费级内存 LPDDR。在英伟达官方博客中,对其产品设计中内存产品的选用逻辑做出明确说明:

10、英伟达博客中明确指出,HBM 内存不仅昂贵(价格是LPDDR 产品的三倍以上,且良率极低),带来的价格/带宽比也及不理想,并不是计算产品的理性选择。同样逻辑下,行业目前应用效果最优、规模最大的网络由英伟达基于台积电成熟工艺 12nm 制程制造,一个竞争产品如果使用更先进工艺(并且未能在最终能效比下)与之竞争,在成本、售价模型和企业经营模型上都不成立;
11、【稀疏】: 稀疏化(Sparse)并不是一个新概念,伴随计算机图形学的开始,行业就在尝试稀疏化,数十年过去,这些问题在逻辑上并没有得到实质解决:稀疏化一定带来精度损失,并且因为无论是图形计算(framebffer 及 texture)还是AI计算都涉及多次累加计算(目前讨论更多的大模型尤甚),结果中精度损失会被放大并且无法回溯。这一问题导致工业界至今没有接受稀疏化应用,一方面供应商无法解释在客户部署现场出现的结果不理想,另一方面出现的错误结果无法被及时重现修复。英伟达在硬件及编译器中也仅保守地提供4*4知阵的(近)无损稀疏,在用户进行稀疏裁剪后重新通过增量训练(lncrementalLearning)直到结果接近原精度,本质上最后得到的是一个新模型。英伟达已经是AI行业的事实标准,这个做法交给任何一个其它厂商来做都很难被客户接受。
12、世界历史上,基于immediate-mode rendering 架构自研 GPU 产品并在商业上成功的团队仅有四个,其中 AMD 和英伟达在中国都不设有研发中心:
1)、S3,成立于 1996年,2000 年被VIA 收购,核心团队成员在收购前几乎全都流往下述公司及高通;
2)、3Dfx成立于1996年,2000 年被英伟达收购;
3)、ATl,成立于1985年,2006 年被AMD 收购;
4)、Vivante,成立于 2004 年,2015 年被芯原收购。
06
总结
1、全球 AI GPU 市场在过往保持 30% 的年复合增长率情况下,受多模态 AIGC 应用的爆发影响即将迎来数百倍增量;
2、英伟达产品目前几乎代表AI 计算行业的 100% 市场规模,最新财年销售规模超过 150 亿美元,中国市场持续占据销售的 1/3。任何一家企业能从中争取 10% 的市场份额,都能形成很可观的销售,但需要团队、产品定义、软件能力高度契合;
3、在大量综合应用及多模态生成式网络的趋势下,对于行业客户的心智和经济模型而言,任何使用于这一市场的产品仅可能使用immediate-mode rendering 桌面 GPU 架构,并且在此基础上兼容(而不是通过转换代码实现) CUDAAPI;
4、由于功耗和体积的限制,GPU 在 AI 场景下最重要的指标是 Perf/W,但达成这个目的的前提是采用真实的 VEC1 桌面 GPU shader 实现,而不是用简化版的移动 GPU 或 DSP 拼凑。对于已有的基于图形GPU的AI 计算卡而言,计算效率及能效比依然存在至少两倍的架构提升空间,但对团队的产品定义及自研架构、软件执行经验提出巨大挑战;
5、世界历史上,在商业市场成功证明自己的 immediate-mode rendering GPU 设计团队仅有四个;
6、市场上一代产品回片的创业公司已经超过五家,因为芯片行业天然的长验证、流片、封装、测试周期,目前还未完成一代芯片流片及客户验证的团队事实上已经完全错失机会窗口。

元启资本长期关注人工智能赛道,拥有出色的价值发现和深入的科学研究能力,具有一站式、全天候、全周期综合金融服务能力,已经在大数据、智能中台、企业服务、先进制造等领域均有丰富的行业积淀和布局,已经与多家业内领先企业展开深度合作,助力企业握行业内关键时点和关键变化,完善价值链创造效率,促进产业转型升级。
