










来自一线的 OpenAI 的 Agent 研究员 yaoshunyu 在个人博客写了一篇文章《The Second Half》,作者提出 AI 发展已进入“下半场”,从专注于模型训练转向定义有意义的问题和评估其现实效用。
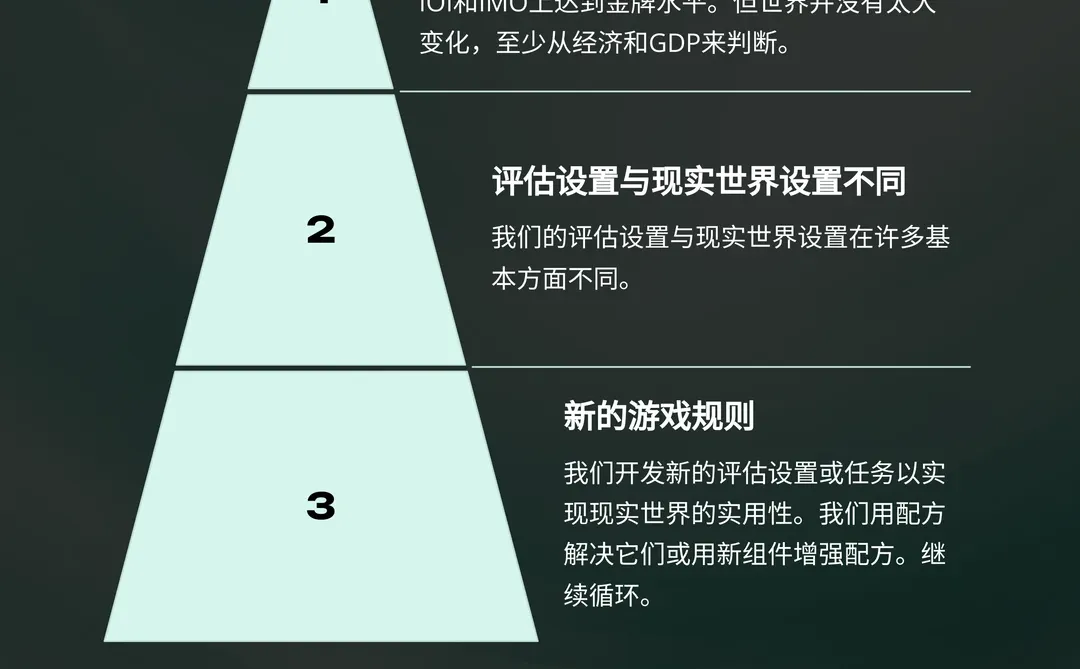
文章指出,AI 在基准测试中表现出色,但在实际经济和社会影响上仍有限,称之为“效用问题”。作者强调,强化学习(RL)现已泛化到多种任务,如软件工程、创意写作和高级数学,标志着 AI 能力的重大飞跃。
然而,当前的评估方法与现实世界需求脱节,需开发新的评估体系,如 Chatbot Arena,以更真实地衡量 AI 表现。
以下是文章的核心观点:
- 从训练到评估的转变:AI 上半场专注于开发新模型和训练方法(如 Transformer、GPT-3),通过基准测试推动进步。而下半场需关注“AI 应该做什么”和“如何衡量真实进展”,这更接近产品管理的思维。
- 强化学习的泛化:强化学习(RL)现可处理多样化任务,包括软件工程、创意写作、国际数学奥林匹克(IMO)级别的数学问题等。其成功依赖于大规模语言预训练、数据/计算规模、推理和行动能力。
- 效用问题:尽管 AI 在棋类、考试等基准测试中超越人类,其对经济(如 GDP)的影响仍有限。这是因为当前评估方法(如独立同分布任务)与现实世界需求(如人机交互、序列任务)存在差距。
- 新评估体系:作者提出需开发更贴近现实的评估方法,如 Chatbot Arena(通过真实用户交互评估聊天机器人)、tau-bench(用户模拟)等,以推动 AI 的实用性。
- 下半场目标:构建具有高经济价值的 AI 产品,创造数十亿甚至万亿美元的公司,同时筛选出真正突破性的研究方法。
也就是说,技术能力已不再是唯一瓶颈,如何让 AI 在现实世界中发挥作用成为核心挑战。
#AI工具 #大模型 #ai工具 #人工智能发展 #深度学习 #AI人工智能 #未来科技趋势 #人工智能就业 #人工智能替代人工
文章指出,AI 在基准测试中表现出色,但在实际经济和社会影响上仍有限,称之为“效用问题”。作者强调,强化学习(RL)现已泛化到多种任务,如软件工程、创意写作和高级数学,标志着 AI 能力的重大飞跃。
然而,当前的评估方法与现实世界需求脱节,需开发新的评估体系,如 Chatbot Arena,以更真实地衡量 AI 表现。
以下是文章的核心观点:
- 从训练到评估的转变:AI 上半场专注于开发新模型和训练方法(如 Transformer、GPT-3),通过基准测试推动进步。而下半场需关注“AI 应该做什么”和“如何衡量真实进展”,这更接近产品管理的思维。
- 强化学习的泛化:强化学习(RL)现可处理多样化任务,包括软件工程、创意写作、国际数学奥林匹克(IMO)级别的数学问题等。其成功依赖于大规模语言预训练、数据/计算规模、推理和行动能力。
- 效用问题:尽管 AI 在棋类、考试等基准测试中超越人类,其对经济(如 GDP)的影响仍有限。这是因为当前评估方法(如独立同分布任务)与现实世界需求(如人机交互、序列任务)存在差距。
- 新评估体系:作者提出需开发更贴近现实的评估方法,如 Chatbot Arena(通过真实用户交互评估聊天机器人)、tau-bench(用户模拟)等,以推动 AI 的实用性。
- 下半场目标:构建具有高经济价值的 AI 产品,创造数十亿甚至万亿美元的公司,同时筛选出真正突破性的研究方法。
也就是说,技术能力已不再是唯一瓶颈,如何让 AI 在现实世界中发挥作用成为核心挑战。
#AI工具 #大模型 #ai工具 #人工智能发展 #深度学习 #AI人工智能 #未来科技趋势 #人工智能就业 #人工智能替代人工