







2025 年也被叫做 Agent 元年,眼看年末将至,Agent 在实际生产环境中的真实落地的怎么样了?伯克利,IBM和斯坦福联手做了一份研究报告,基于 306 名一线从业者的调研数据与 20 个深度企业案例分析,不仅回答了这个核心问题,也着力缩小学术研究和实际部署之间的差距;
? 研究首先回答了几个问题:
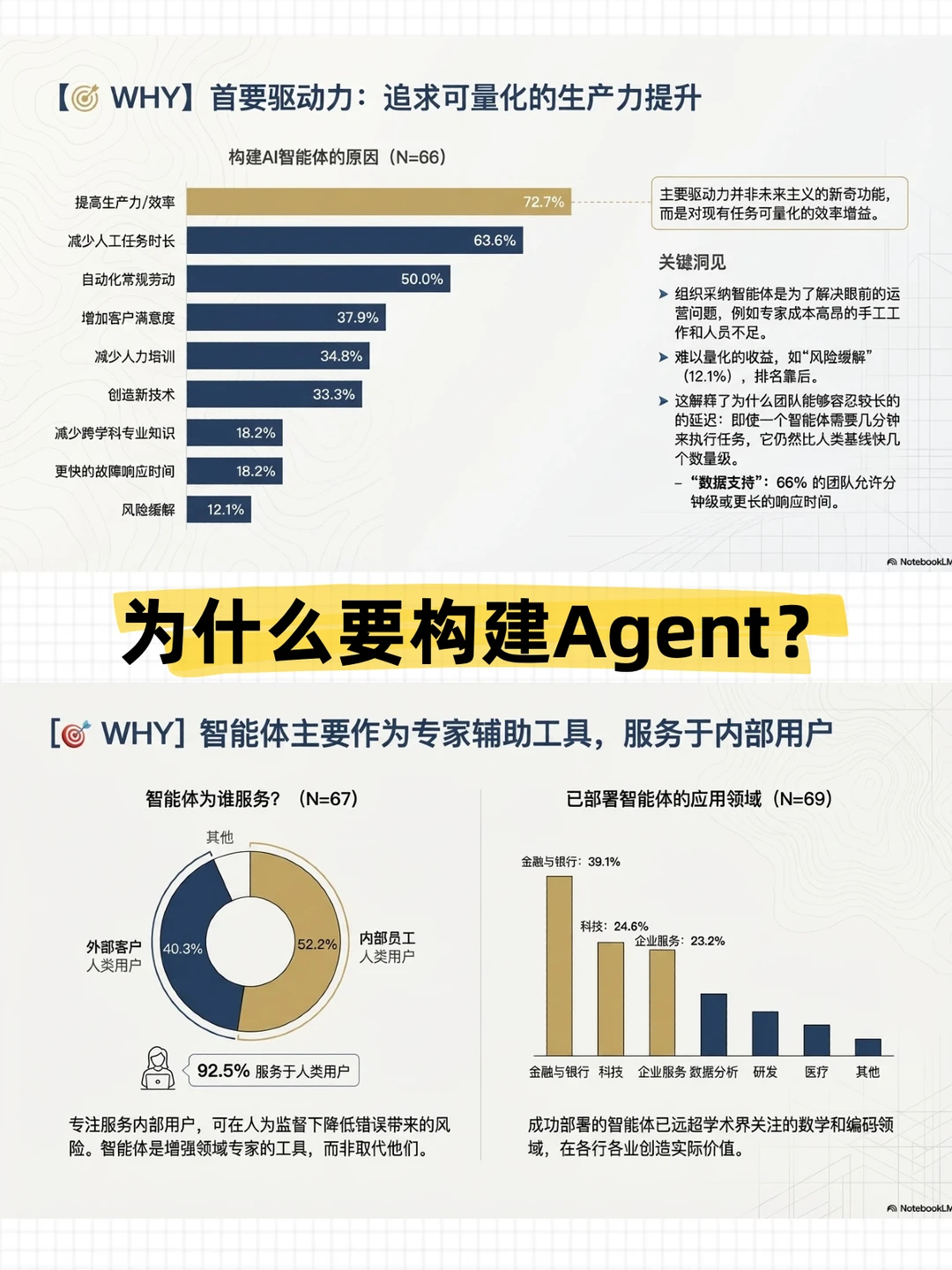
- 使用Agent的动机是什么?
提高生产力和效率是 Agent 被采用的主要驱动力(72.7%),其次是减少人工任务工时(63.6%)和自动化常规任务(50.0%)
- 应用Agent的行业领域有哪些?
和学术研究中最高频提到的编程不同,实际部署最多的领域分别是金融与银行:39.1%,技术:24.6%,企业服务:23.2%,数据分析:13.0%
- Agent的最终用户是谁?
绝大多数部署的Agent是服务于人类用户(92.5%),其中内部员工占52.2%,C端用户占40.3%,企业部署倾向于内部部署,这样容错率较高,调整起来也比较灵活;
?关于Agent的实际部署,我总结了以下几点启示:
- 可靠性大于一切,需要有意识的限制Agent自主性:
实际部署过程更偏爱预定义的、结构化的静态工作流,而不是让模型动态自主规划;同时,大多数系统(68%)将Agent自主执行的步骤限制在10步以内;
- Prompt工程仍是主流,优先选择闭源模型:
与学术研究青睐开源模型 + SFT/RL训练不同,多数Agent部署依赖于闭源的前沿模型,,将重点放在提示工程,没有进行额外的权重调整;85% 团队选择从头构建定制的 Agent 应用,而不是使用第三方Agent框架;
- 评估体系仍是硬伤,人类评估不可或缺:
由于缺少具备行业特征的测试集,74.2% 的已部署的Agent仍然依赖于人工评估。就算有一半以上的团队用了 LLM-as-a-judge,最后也会用人工评估来兜底;
- 相比起系统延迟,更注重输出质量;
可能更多服务的是企业内部用户,所以,相比起延迟,大部分团队更看重输出的质量和实际能力,超过 60% 的系统都能接受分钟级的响应时间;
?在Agent未来发展上,有这么几点:
- 提升自主性和可靠性;
- 故障检测和观测机制;
- 样本效率更高的后训练方法;
- 更好的架构框架;支持多模态;
- 用于潜力更大的软件操作应用场景;
#chatgpt应用领域 #AI人工智能 #ai研究 #prompt #大模型
? 研究首先回答了几个问题:
- 使用Agent的动机是什么?
提高生产力和效率是 Agent 被采用的主要驱动力(72.7%),其次是减少人工任务工时(63.6%)和自动化常规任务(50.0%)
- 应用Agent的行业领域有哪些?
和学术研究中最高频提到的编程不同,实际部署最多的领域分别是金融与银行:39.1%,技术:24.6%,企业服务:23.2%,数据分析:13.0%
- Agent的最终用户是谁?
绝大多数部署的Agent是服务于人类用户(92.5%),其中内部员工占52.2%,C端用户占40.3%,企业部署倾向于内部部署,这样容错率较高,调整起来也比较灵活;
?关于Agent的实际部署,我总结了以下几点启示:
- 可靠性大于一切,需要有意识的限制Agent自主性:
实际部署过程更偏爱预定义的、结构化的静态工作流,而不是让模型动态自主规划;同时,大多数系统(68%)将Agent自主执行的步骤限制在10步以内;
- Prompt工程仍是主流,优先选择闭源模型:
与学术研究青睐开源模型 + SFT/RL训练不同,多数Agent部署依赖于闭源的前沿模型,,将重点放在提示工程,没有进行额外的权重调整;85% 团队选择从头构建定制的 Agent 应用,而不是使用第三方Agent框架;
- 评估体系仍是硬伤,人类评估不可或缺:
由于缺少具备行业特征的测试集,74.2% 的已部署的Agent仍然依赖于人工评估。就算有一半以上的团队用了 LLM-as-a-judge,最后也会用人工评估来兜底;
- 相比起系统延迟,更注重输出质量;
可能更多服务的是企业内部用户,所以,相比起延迟,大部分团队更看重输出的质量和实际能力,超过 60% 的系统都能接受分钟级的响应时间;
?在Agent未来发展上,有这么几点:
- 提升自主性和可靠性;
- 故障检测和观测机制;
- 样本效率更高的后训练方法;
- 更好的架构框架;支持多模态;
- 用于潜力更大的软件操作应用场景;
#chatgpt应用领域 #AI人工智能 #ai研究 #prompt #大模型