














摘要
金融行业长期以来面临海量市场数据与信息的处理难题。当前,大语言模型在通用文本理解任务上取得了 显著进展,但在专业性更强的中文金融领域还有较大的提升空间。针对当前大语言模型在处理专业领域文本任务上的不足,提出基于知识增强的继续预训练和监督微调的两阶段训练方法,并改进了训练数据的组织形式和训练范式,从而提升模型在复杂金融场景下的性能。最后,通过实验验证了提出的知识增强方法在大模型训练中的有效性。
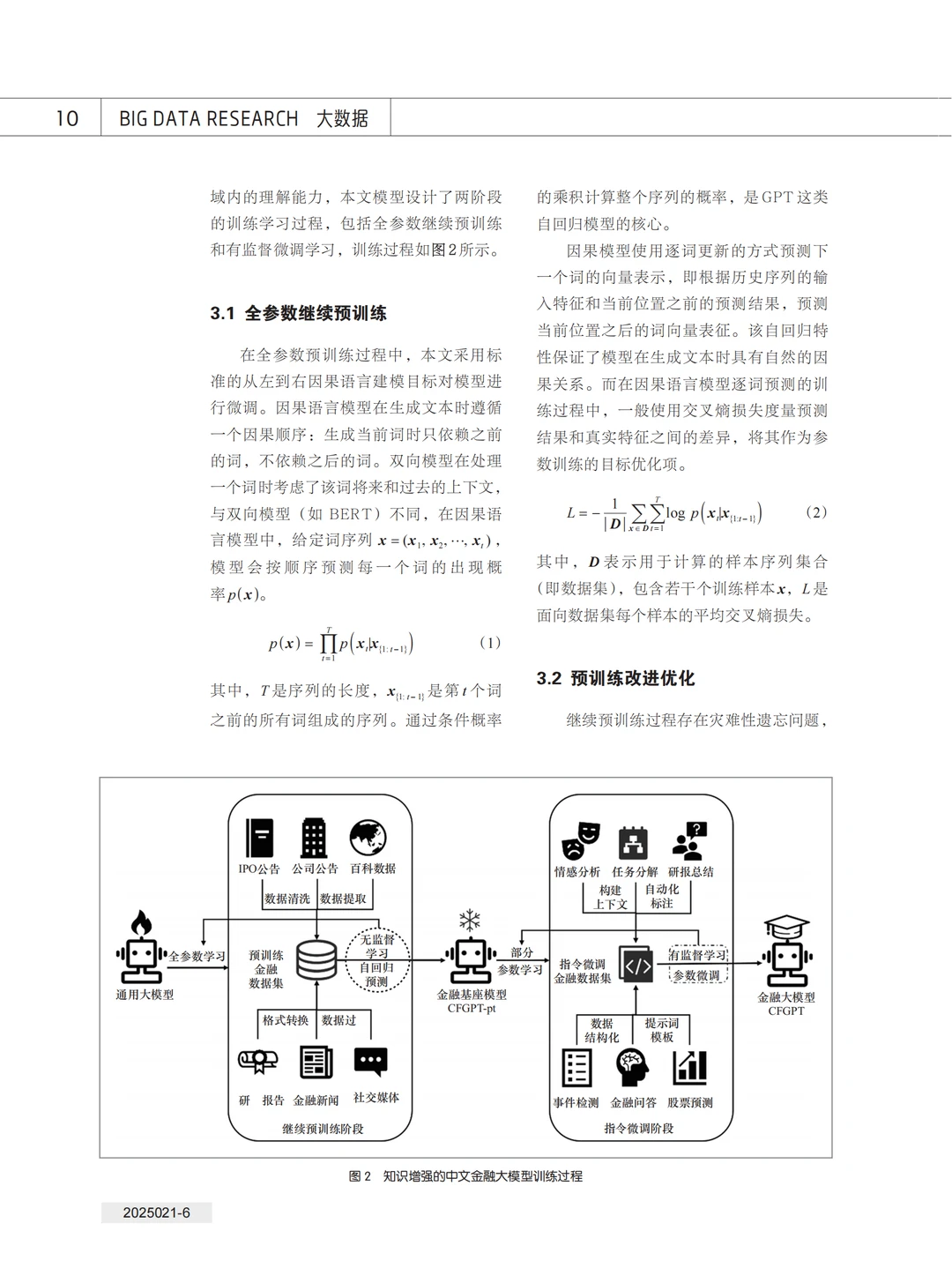
本文提出了一种基于知识增强的中文金融 大 模 型——CFGPT (Chinese financial generative pre-trained model),基 于 高质量中文金融语料,设计了两个步骤的知识增强嵌入学习方法,并通过实验验证了本文方法在金融任务上的有效性。
本文模型在情感分析、金融事件检测、研究报告分析总结、金融问答、金融安全合规以及金融时序预测 6 个任务的相关数据上进行指令微调训练。
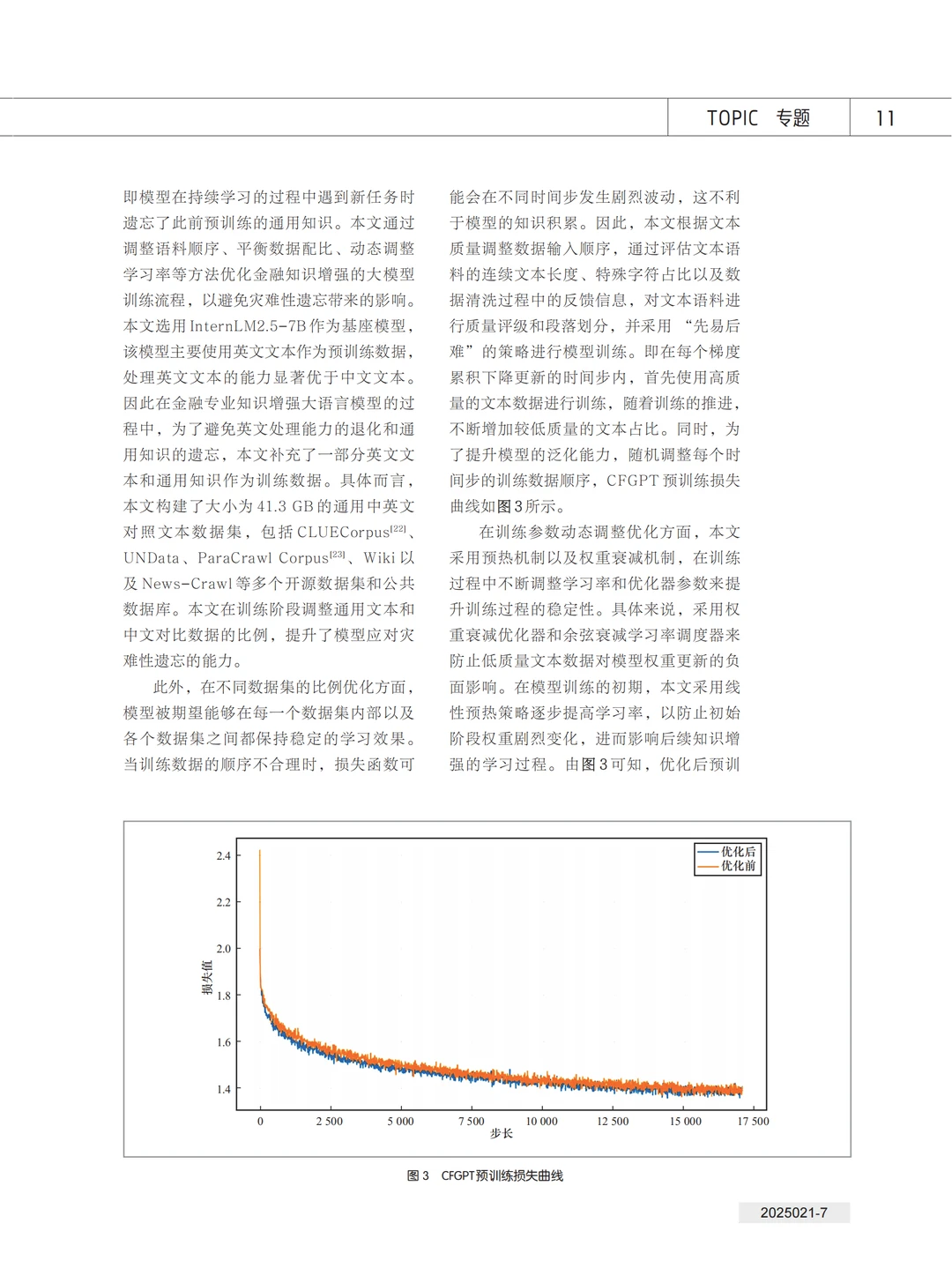
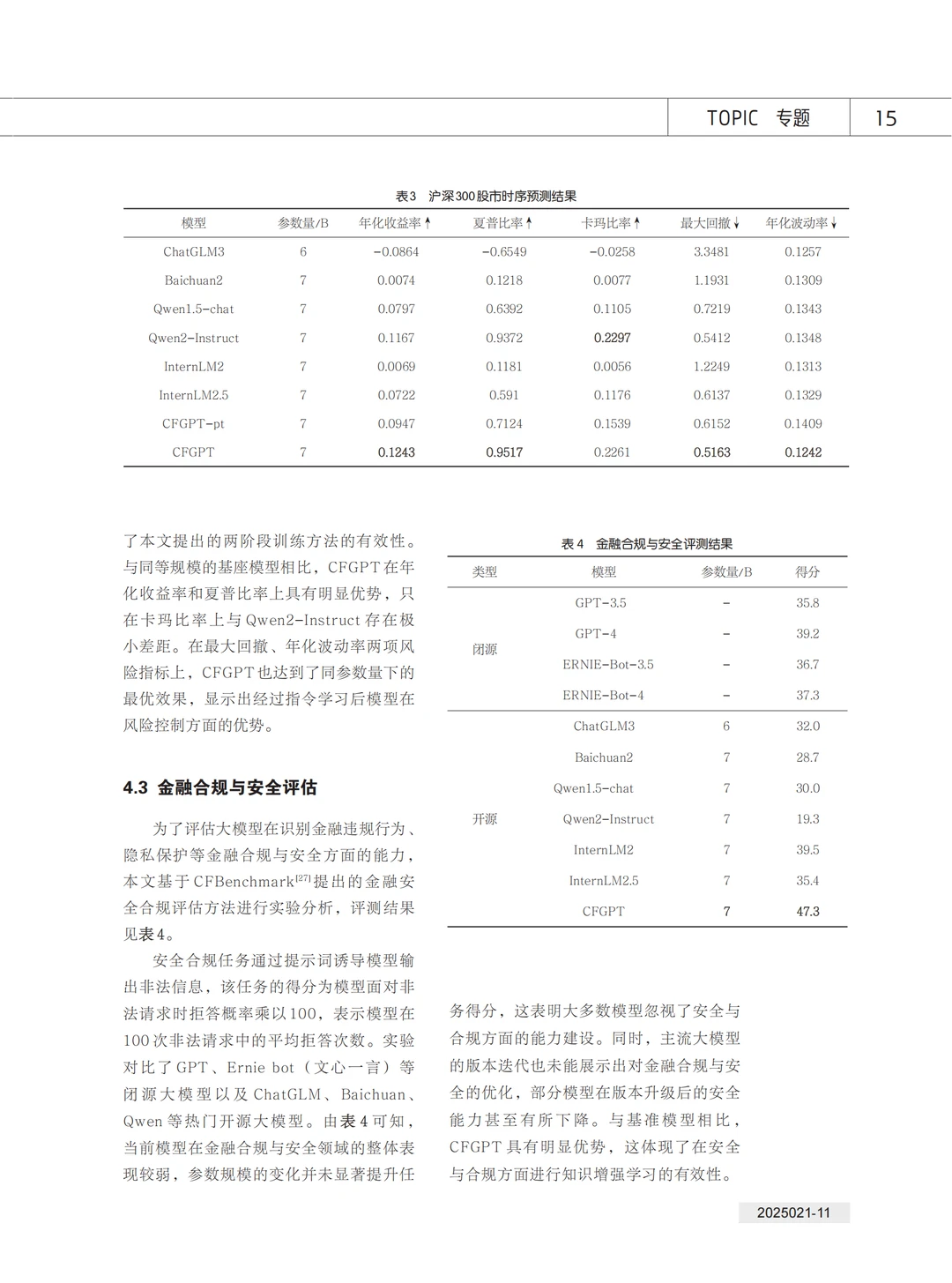
本文开展了知识增强的中文金融大模型研究,提出了全参数继续预训练和金融场景任务指令微调的两阶段训练方法,显著提升了大模型在金融垂直领域的应用能力。本文详细介绍了高质量金融数据集的构建与处理方法、全参数预训练过程及其优化方法,以及面向 6 个真实金融场景的任务监督微调数据集的构建、处理和模型训练优化过程;最后,通过金融专业知识评估、时序预测、合规与安全评估实验验证了本文方法的有效性。本文提出的数据组织形式和模型训练范式为金融行业提供了更精准、高效的智能化解决方案,同时为其他垂直领域的大模型研究提供了参考。
金融行业长期以来面临海量市场数据与信息的处理难题。当前,大语言模型在通用文本理解任务上取得了 显著进展,但在专业性更强的中文金融领域还有较大的提升空间。针对当前大语言模型在处理专业领域文本任务上的不足,提出基于知识增强的继续预训练和监督微调的两阶段训练方法,并改进了训练数据的组织形式和训练范式,从而提升模型在复杂金融场景下的性能。最后,通过实验验证了提出的知识增强方法在大模型训练中的有效性。
本文提出了一种基于知识增强的中文金融 大 模 型——CFGPT (Chinese financial generative pre-trained model),基 于 高质量中文金融语料,设计了两个步骤的知识增强嵌入学习方法,并通过实验验证了本文方法在金融任务上的有效性。
本文模型在情感分析、金融事件检测、研究报告分析总结、金融问答、金融安全合规以及金融时序预测 6 个任务的相关数据上进行指令微调训练。
本文开展了知识增强的中文金融大模型研究,提出了全参数继续预训练和金融场景任务指令微调的两阶段训练方法,显著提升了大模型在金融垂直领域的应用能力。本文详细介绍了高质量金融数据集的构建与处理方法、全参数预训练过程及其优化方法,以及面向 6 个真实金融场景的任务监督微调数据集的构建、处理和模型训练优化过程;最后,通过金融专业知识评估、时序预测、合规与安全评估实验验证了本文方法的有效性。本文提出的数据组织形式和模型训练范式为金融行业提供了更精准、高效的智能化解决方案,同时为其他垂直领域的大模型研究提供了参考。