






本地生活场景搜索长期依赖单轮、浅层检索,难以处理真实用户查询中常见的多约束、多场景、多地点链式需求。LocalSearchBench 是首个面向本地生活服务的 多跳推理+智能搜索基准,结合150k 商户数据、300 多跳任务与 LocalPlayground 智能体框架,为评估大型推理模型(LRMs)在真实生活服务里的智能检索能力提供标准化测试平台。
核心亮点
1. 行业内首个本地生活多跳智能检索基准
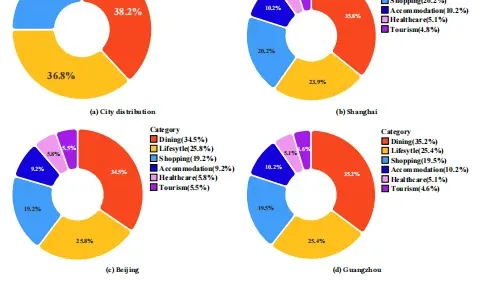
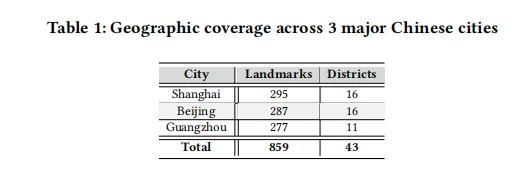
覆盖 餐饮、购物、住宿、生活、医疗、旅游 6 大场景,真实反映用户如“展览结束后去喝咖啡+买零食”等复杂链式需求。基准包括 150,031 条高质量商户数据 + 300 复杂多跳问题。
2. 数据构建系统化、可控、安全
论文提出三阶段流程:
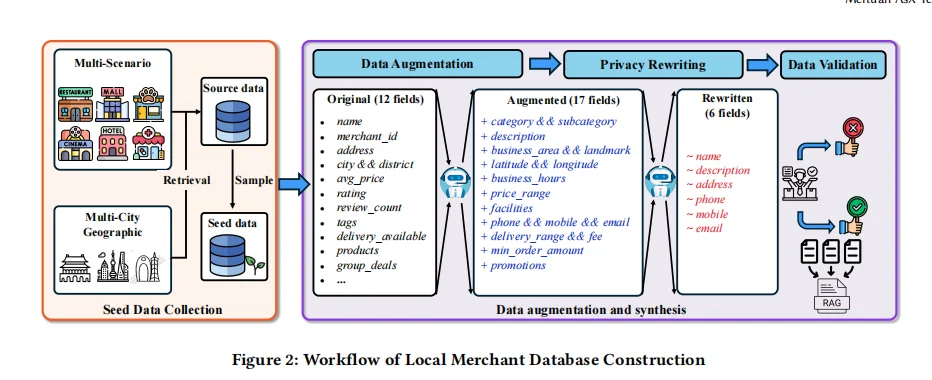
Data Augmentation:将12个字段扩展为29个字段(营业时间、设施、价格区段、地标等)。
Privacy Rewriting:替换真实地址、店名、联系方式确保隐私安全。
LLM-as-a-Judge 多维验证:完整性、逻辑一致性、地理准确性等六大指标。
3. 创建本地生活专用 RAG 工具 LocalRAG
包括向量表示、密集检索、重排序,用于支持智能体跨地点、跨服务的推理搜索。与多跳问题深度结合,模拟真实应用。
4. 300 道真实多跳任务,难度来自真实业务
任务覆盖:
多约束商户组合
多地点链路规划
服务捆绑 + 事件触发式搜索 并按 L3–L4 智能等级设计
5. LocalPlayground:可复现的智能体评测框架
包含 Search Agent(LocalRAG + Web Search) 与 Validation Agent,基于7项指标全方位评估大型模型表现(图10)。
6. 全面评测10大主流模型,结果揭示行业现状
最佳模型(DeepSeek-V3.1)正确率仅 34.34%,说明本地生活多跳推理仍具巨大挑战。引入 Web Search 时:
正确率 +4.37pp
完整性 +3.95pp
忠实度 -3.64pp(噪声干扰)
7. 关键发现:最佳推理轮次为 N = 5
回合数过少 → 信息不足 回合数过多 → 反而降低正确率
arXiv:2512.07436
#AI工具 #智能体 #多跳推理 #本地生活 #RAG #大模型评测 #美团 #搜索增强 #Agent #LLM
核心亮点
1. 行业内首个本地生活多跳智能检索基准
覆盖 餐饮、购物、住宿、生活、医疗、旅游 6 大场景,真实反映用户如“展览结束后去喝咖啡+买零食”等复杂链式需求。基准包括 150,031 条高质量商户数据 + 300 复杂多跳问题。
2. 数据构建系统化、可控、安全
论文提出三阶段流程:
Data Augmentation:将12个字段扩展为29个字段(营业时间、设施、价格区段、地标等)。
Privacy Rewriting:替换真实地址、店名、联系方式确保隐私安全。
LLM-as-a-Judge 多维验证:完整性、逻辑一致性、地理准确性等六大指标。
3. 创建本地生活专用 RAG 工具 LocalRAG
包括向量表示、密集检索、重排序,用于支持智能体跨地点、跨服务的推理搜索。与多跳问题深度结合,模拟真实应用。
4. 300 道真实多跳任务,难度来自真实业务
任务覆盖:
多约束商户组合
多地点链路规划
服务捆绑 + 事件触发式搜索 并按 L3–L4 智能等级设计
5. LocalPlayground:可复现的智能体评测框架
包含 Search Agent(LocalRAG + Web Search) 与 Validation Agent,基于7项指标全方位评估大型模型表现(图10)。
6. 全面评测10大主流模型,结果揭示行业现状
最佳模型(DeepSeek-V3.1)正确率仅 34.34%,说明本地生活多跳推理仍具巨大挑战。引入 Web Search 时:
正确率 +4.37pp
完整性 +3.95pp
忠实度 -3.64pp(噪声干扰)
7. 关键发现:最佳推理轮次为 N = 5
回合数过少 → 信息不足 回合数过多 → 反而降低正确率
arXiv:2512.07436
#AI工具 #智能体 #多跳推理 #本地生活 #RAG #大模型评测 #美团 #搜索增强 #Agent #LLM