











Text Generation Inference(TGI)是Hugging Face开发的生产级LLM部署框架,使用Rust和Python编写,专门用于在本地机器上以服务形式运行大型语言模型。
? 核心加速技术
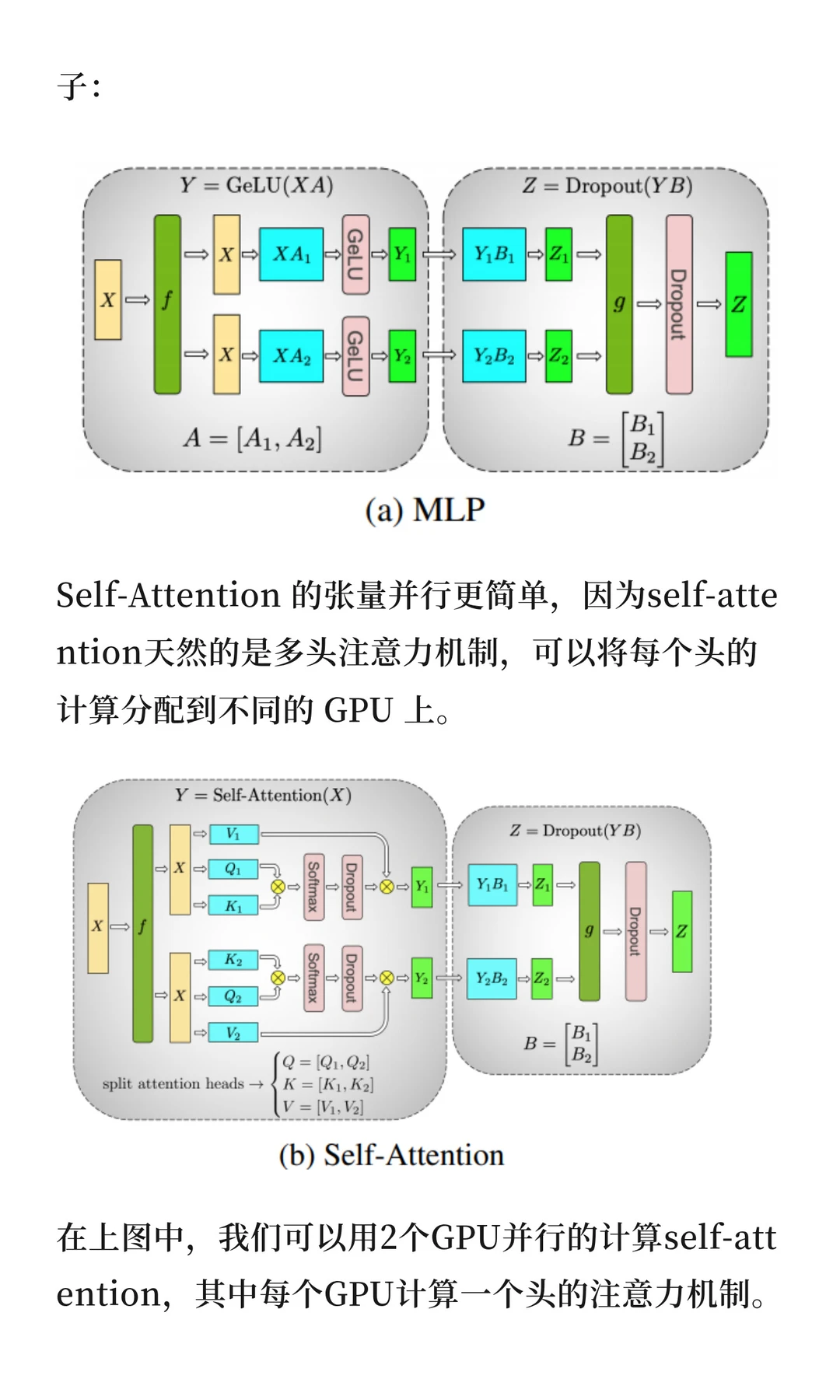
张量并行:将模型参数划分到多个GPU并行计算。在MLP层,按列拆分权重矩阵并行执行矩阵乘法;在Self-Attention层,利用多头机制将每个头分配到不同GPU计算,有几个头就可以用几个GPU。
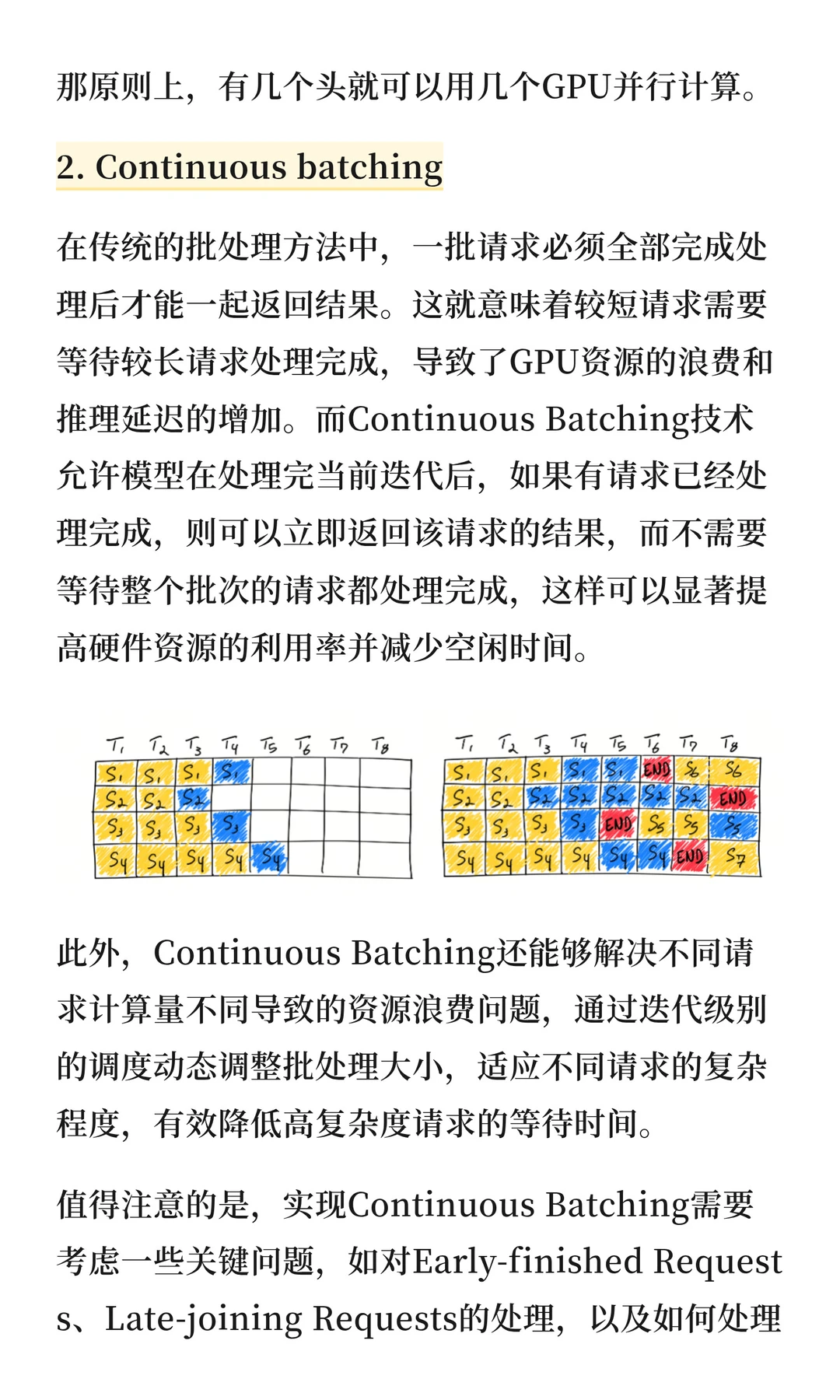
连续批处理:打破传统批处理必须等待所有请求完成的限制。处理完的请求可立即返回,无需等待整个批次,显著提高GPU利用率,减少空闲时间和推理延迟。
Flash Attention:通过分块计算和重计算技术,减少GPU高带宽内存和片上SRAM之间的读写次数,优化内存访问模式,提升长序列处理效率。
PagedAttention:借鉴操作系统虚拟内存思想,在非连续内存空间存储KV缓存,将其划分为块高效管理,降低内存浪费。
✨ 主要特性
简单启动器,快速部署主流LLM
生产就绪,集成分布式追踪和Prometheus监控
支持多种量化方法(bitsandbytes、GPT-Q、AWQ等)
令牌流式传输和推测生成
支持引导/JSON格式化输出
多硬件支持(NVIDIA、AMD、Intel GPU及TPU等)
TGI为大模型生产部署提供了完整高效的解决方案。
#动手学大模型 #大模型面试 #LLM #大模型 #TGI #大模型推理加速 #大模型推理框架 #AiChannel #flashattention
? 核心加速技术
张量并行:将模型参数划分到多个GPU并行计算。在MLP层,按列拆分权重矩阵并行执行矩阵乘法;在Self-Attention层,利用多头机制将每个头分配到不同GPU计算,有几个头就可以用几个GPU。
连续批处理:打破传统批处理必须等待所有请求完成的限制。处理完的请求可立即返回,无需等待整个批次,显著提高GPU利用率,减少空闲时间和推理延迟。
Flash Attention:通过分块计算和重计算技术,减少GPU高带宽内存和片上SRAM之间的读写次数,优化内存访问模式,提升长序列处理效率。
PagedAttention:借鉴操作系统虚拟内存思想,在非连续内存空间存储KV缓存,将其划分为块高效管理,降低内存浪费。
✨ 主要特性
简单启动器,快速部署主流LLM
生产就绪,集成分布式追踪和Prometheus监控
支持多种量化方法(bitsandbytes、GPT-Q、AWQ等)
令牌流式传输和推测生成
支持引导/JSON格式化输出
多硬件支持(NVIDIA、AMD、Intel GPU及TPU等)
TGI为大模型生产部署提供了完整高效的解决方案。
#动手学大模型 #大模型面试 #LLM #大模型 #TGI #大模型推理加速 #大模型推理框架 #AiChannel #flashattention