






一、训练 vs 推理:内存需求的“冰火两重天”
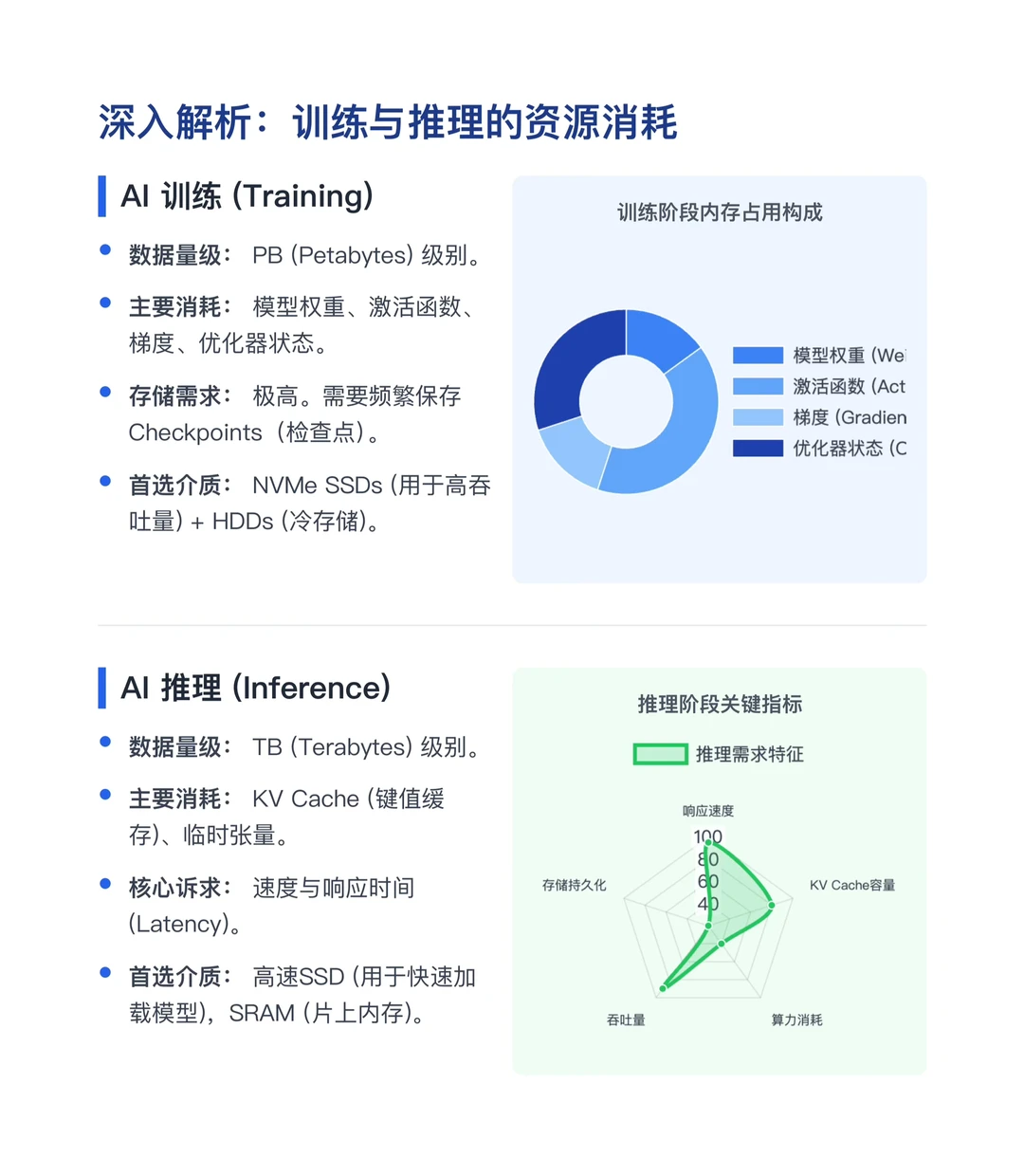
AI对内存的渴望并非一概而论。训练和推理对内存的需求存在巨大鸿沟。
1. 训练是“吞金兽”:训练一个中等规模的模型,仅存储权重、激活函数、梯度和优化器状态,就需要消耗 1TB+ 的组合内存。更不用说PB(Petabytes)级别的训练数据集和频繁的检查点保存。
2. 推理重“速度”:相比之下,推理阶段的内存需求量级较小(TB级),主要用于存储KV Cache和临时张量。推理的核心痛点不是容量,而是低延迟——毕竟没人愿意等ChatGPT五分钟才吐出一个字。
3. 现状:由于AI采用速度远超预期,HBM和DRAM的需求与价格双双飙升,倒逼云厂商签署长期协议锁定产能。
二、反直觉的账本:为何昂贵的SSD正在取代HDD?
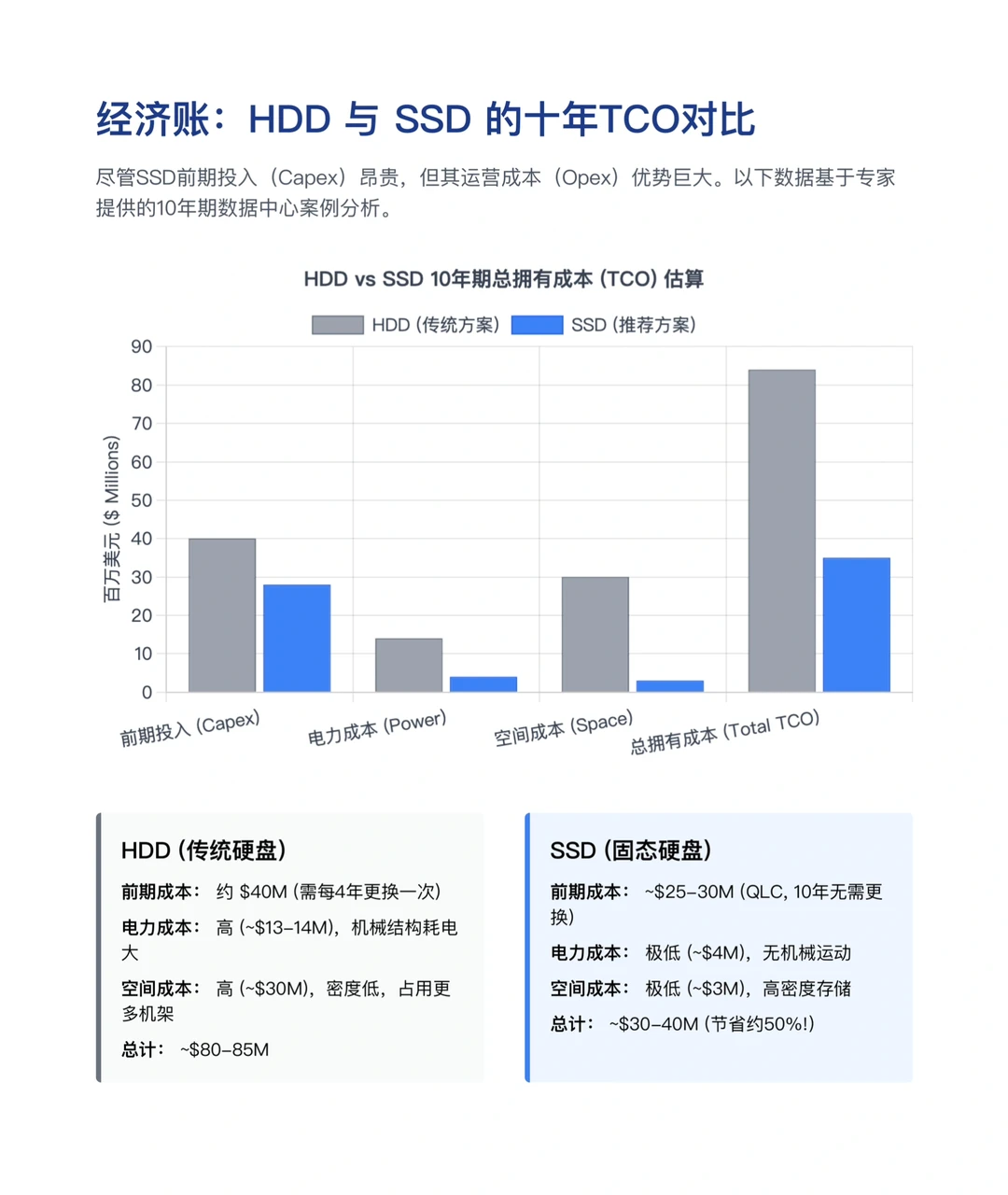
传统观点认为,机械硬盘便宜量大,是海量数据的归宿。但目前由于HDD短缺,许多云厂商正被迫转向固态硬盘。
问题来了:SSD的单价是HDD的5到10倍,巨头们疯了吗?
一笔10年总拥有成本的账:
1.HDD方案:虽然初次购买便宜,但每4年需更换一次,且机械结构耗电巨大、发热严重。10年总成本约 8000万-8500万美元。
2.SSD方案:虽然前期投入高,但10年无需更换,且无机械运动,电力和冷却成本极低,空间占用更少。10年总成本仅 3000万-4000万美元。
尽管是被迫转型,但从长期运营看,SSD不仅性能吊打HDD,反而能帮数据中心省下约50%的钱。
三、硬件博弈:TPU与未来的存储
在芯片端,Google的TPU与NVIDIA的GPU之争仍在继续。
1. TPU: 专为深度学习设计,TCO更低,扩展性强,是Google内部Gemini模型的基石。
2. GPU: 赢在生态(CUDA),通用性强,是OpenAI等大多数公司的首选。
此外,为了解决LLM模型太大装不进内存的尴尬,High Bandwidth Flash技术正在崛起。这是一种介于DRAM和SSD之间的新层级,旨在为边缘AI提供TB级的高速非易失性存储。
AI的竞争,归根结底是能源与效率的竞争。当模型参数迈向万亿级别,不仅是算力,存储系统的每一次读写、每一瓦散热,都决定了谁能在这场长跑中活得更久。
#行业报告#伯恩斯坦#ai#数据中心#内存#存储#股票#财报
AI对内存的渴望并非一概而论。训练和推理对内存的需求存在巨大鸿沟。
1. 训练是“吞金兽”:训练一个中等规模的模型,仅存储权重、激活函数、梯度和优化器状态,就需要消耗 1TB+ 的组合内存。更不用说PB(Petabytes)级别的训练数据集和频繁的检查点保存。
2. 推理重“速度”:相比之下,推理阶段的内存需求量级较小(TB级),主要用于存储KV Cache和临时张量。推理的核心痛点不是容量,而是低延迟——毕竟没人愿意等ChatGPT五分钟才吐出一个字。
3. 现状:由于AI采用速度远超预期,HBM和DRAM的需求与价格双双飙升,倒逼云厂商签署长期协议锁定产能。
二、反直觉的账本:为何昂贵的SSD正在取代HDD?
传统观点认为,机械硬盘便宜量大,是海量数据的归宿。但目前由于HDD短缺,许多云厂商正被迫转向固态硬盘。
问题来了:SSD的单价是HDD的5到10倍,巨头们疯了吗?
一笔10年总拥有成本的账:
1.HDD方案:虽然初次购买便宜,但每4年需更换一次,且机械结构耗电巨大、发热严重。10年总成本约 8000万-8500万美元。
2.SSD方案:虽然前期投入高,但10年无需更换,且无机械运动,电力和冷却成本极低,空间占用更少。10年总成本仅 3000万-4000万美元。
尽管是被迫转型,但从长期运营看,SSD不仅性能吊打HDD,反而能帮数据中心省下约50%的钱。
三、硬件博弈:TPU与未来的存储
在芯片端,Google的TPU与NVIDIA的GPU之争仍在继续。
1. TPU: 专为深度学习设计,TCO更低,扩展性强,是Google内部Gemini模型的基石。
2. GPU: 赢在生态(CUDA),通用性强,是OpenAI等大多数公司的首选。
此外,为了解决LLM模型太大装不进内存的尴尬,High Bandwidth Flash技术正在崛起。这是一种介于DRAM和SSD之间的新层级,旨在为边缘AI提供TB级的高速非易失性存储。
AI的竞争,归根结底是能源与效率的竞争。当模型参数迈向万亿级别,不仅是算力,存储系统的每一次读写、每一瓦散热,都决定了谁能在这场长跑中活得更久。
#行业报告#伯恩斯坦#ai#数据中心#内存#存储#股票#财报