








文本切片 → Token化
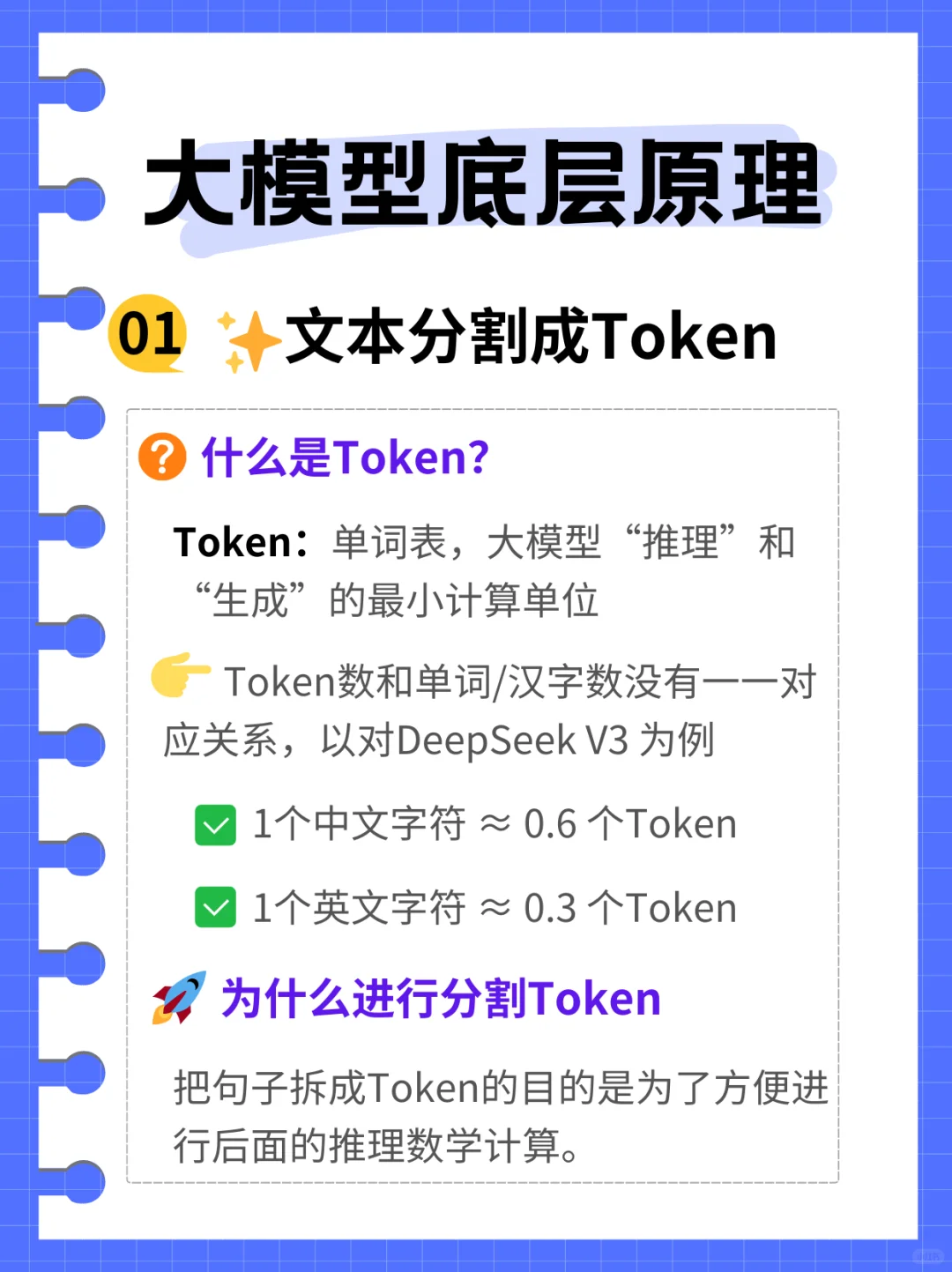
?什么是Token?
? Token = 大模型“吃”文本的最小单位!
→中文1字 ≈ 0.6个Token
→英文1词 ≈ 0.3个Token(按词根拆)
?为什么要切?
✅必须变成数字才能算! 就像做饭前要把食材切块一样?
? 举个栗子:
? 输入:“生成式AI是什么东西?”
? 被切成:生成|式|AI|是什么|东西|? ✅ 共6个Token → 进入下一流水线!
Embedding:嵌入层 → 向量化
▪️每个Token都被“翻译”成一串数字向量,这步叫:Embedding(嵌入)
▪️目的:让AI能“理解”语义 → 把文字变成数学空间中的点!
▪️比如:“猫”和“狗”的向量会靠得很近?? 而“猫”和“火箭”就离得远?
多层推理 → 自注意力机制
?这才是AI的“大脑运转”??
? 核心机制:Self-Attention(自注意力) 让每个Token“回头看”整句话:
→它在句子里的位置?
→和前后词有什么关系?
→是重点?还是陪衬?
? 每一层都在调整Token的“隐藏状态”
⚠️ 注意:不是改Embedding!是改它“当前的理解状态”!
? 类比: 向量夹角越小 → 语义越相似 AI就是靠这个判断“意思是不是一样”!
向量计算 → 预测下一个词!
▪️经过N层“脑内推理”后,AI得出: ➡️ 下一个最可能的词是谁?
▪️模型输出的是“概率分布”: 比如输入“今天天气真__” AI说:
“好” → 78% ✅(选它!)
“差” → 15%
“香” → 0.01% ?
? 然后把“好”加回去,变成新输入: “今天天气真好__” → 继续预测下一个… 直到生成完整回答!
✨ 最终流程图一总结?
?? 人类提问 → ➡️ 切成Token → ➡️ 转为向量 → ➡️ 多层推理 → ➡️ 预测+生成 → ✅ 输出答案!
伙伴们,今天的内容到这里分享结束了,如果能帮到大家的话,那就真的是太棒了!之后会持续更新一些大模型方面内容,包括理论和实践,那我们下次见
? 下期预告: 《AI的8种应用模式》
#AI #干货分享 #大模型 #人工智能 #AI工具 #求职 #新人博主 #搭建个人知识体系 #人工智能就业 #产品经理
?什么是Token?
? Token = 大模型“吃”文本的最小单位!
→中文1字 ≈ 0.6个Token
→英文1词 ≈ 0.3个Token(按词根拆)
?为什么要切?
✅必须变成数字才能算! 就像做饭前要把食材切块一样?
? 举个栗子:
? 输入:“生成式AI是什么东西?”
? 被切成:生成|式|AI|是什么|东西|? ✅ 共6个Token → 进入下一流水线!
Embedding:嵌入层 → 向量化
▪️每个Token都被“翻译”成一串数字向量,这步叫:Embedding(嵌入)
▪️目的:让AI能“理解”语义 → 把文字变成数学空间中的点!
▪️比如:“猫”和“狗”的向量会靠得很近?? 而“猫”和“火箭”就离得远?
多层推理 → 自注意力机制
?这才是AI的“大脑运转”??
? 核心机制:Self-Attention(自注意力) 让每个Token“回头看”整句话:
→它在句子里的位置?
→和前后词有什么关系?
→是重点?还是陪衬?
? 每一层都在调整Token的“隐藏状态”
⚠️ 注意:不是改Embedding!是改它“当前的理解状态”!
? 类比: 向量夹角越小 → 语义越相似 AI就是靠这个判断“意思是不是一样”!
向量计算 → 预测下一个词!
▪️经过N层“脑内推理”后,AI得出: ➡️ 下一个最可能的词是谁?
▪️模型输出的是“概率分布”: 比如输入“今天天气真__” AI说:
“好” → 78% ✅(选它!)
“差” → 15%
“香” → 0.01% ?
? 然后把“好”加回去,变成新输入: “今天天气真好__” → 继续预测下一个… 直到生成完整回答!
✨ 最终流程图一总结?
?? 人类提问 → ➡️ 切成Token → ➡️ 转为向量 → ➡️ 多层推理 → ➡️ 预测+生成 → ✅ 输出答案!
伙伴们,今天的内容到这里分享结束了,如果能帮到大家的话,那就真的是太棒了!之后会持续更新一些大模型方面内容,包括理论和实践,那我们下次见
? 下期预告: 《AI的8种应用模式》
#AI #干货分享 #大模型 #人工智能 #AI工具 #求职 #新人博主 #搭建个人知识体系 #人工智能就业 #产品经理