


近期一批国产大模型发布了新版模型,我们进行了跟踪测评,提供了与新旧版本的效果对比。
一、测评结果:
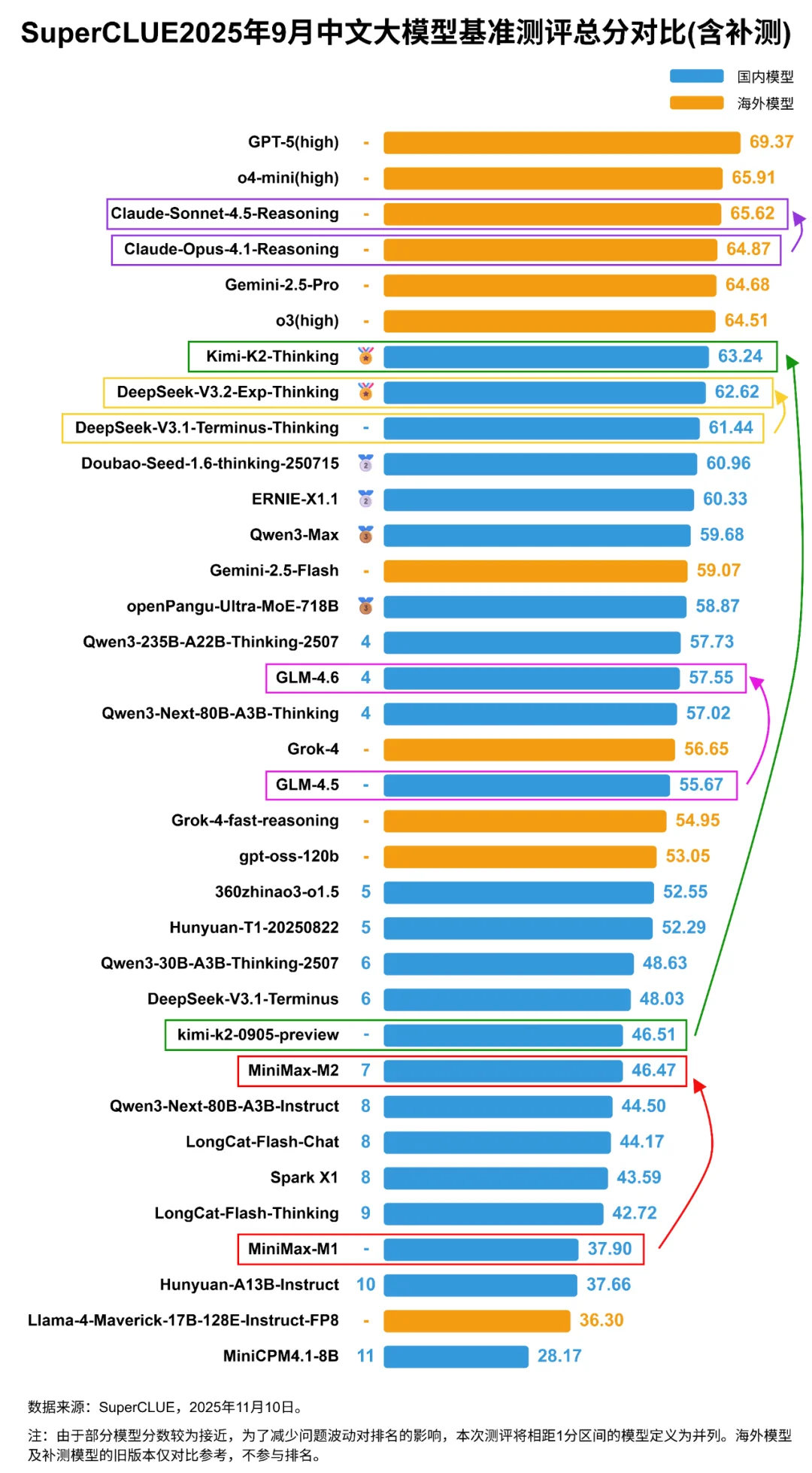
1. 国内的DeepSeek-V3.2-Exp-Thinking、GLM-4.6、MiniMax-M2在上一代的基础上稳步优化,持续进步。
2. Kimi-K2-Thinking相较于kimi-k2-0905-preview的提升幅度最大,从低分段跃升至国内第一梯队,接近海外Claude系列模型。
3. 国内开源模型竞争激烈,相较于海外开源模型优势显著,部分开源模型有媲美国内外顶尖闭源模型的实力。
二、测评任务:
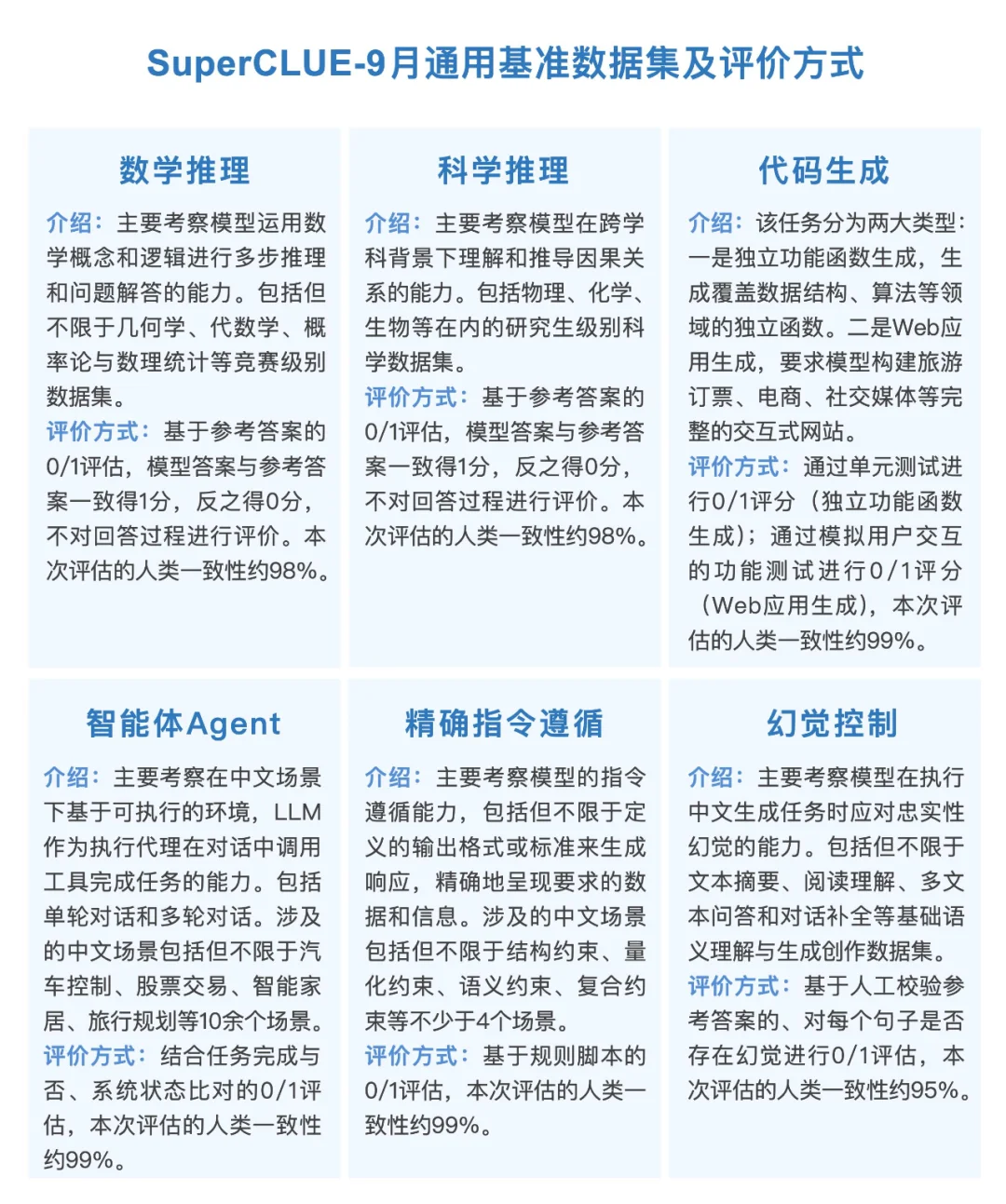
本次测评的数据集包括六大任务:数学推理、科学推理、代码生成(含web开发)、智能体Agent(多轮工具调用)、幻觉控制、精确指令遵循。
三、测评集数量:
题目总量为1260道新题,皆为中文题,最终得分取各任务平均分。
#大模型 #国产大模型 #人工智能 #AI工具 #AI #AI人工智能 #智能体 #测试评分0102 #DeepSeek
一、测评结果:
1. 国内的DeepSeek-V3.2-Exp-Thinking、GLM-4.6、MiniMax-M2在上一代的基础上稳步优化,持续进步。
2. Kimi-K2-Thinking相较于kimi-k2-0905-preview的提升幅度最大,从低分段跃升至国内第一梯队,接近海外Claude系列模型。
3. 国内开源模型竞争激烈,相较于海外开源模型优势显著,部分开源模型有媲美国内外顶尖闭源模型的实力。
二、测评任务:
本次测评的数据集包括六大任务:数学推理、科学推理、代码生成(含web开发)、智能体Agent(多轮工具调用)、幻觉控制、精确指令遵循。
三、测评集数量:
题目总量为1260道新题,皆为中文题,最终得分取各任务平均分。
#大模型 #国产大模型 #人工智能 #AI工具 #AI #AI人工智能 #智能体 #测试评分0102 #DeepSeek