



当前最先进的大模型在关键任务上仍严重“过度自信”,即使明确告知错误会有巨大惩罚,它们仍坚持瞎答,几乎从不说 “I don’t know”。论文提出 Reinforced Hesitation(RH),通过训练让模型真正学会“何时不回答”,从根本解决可信度问题。
核心亮点:
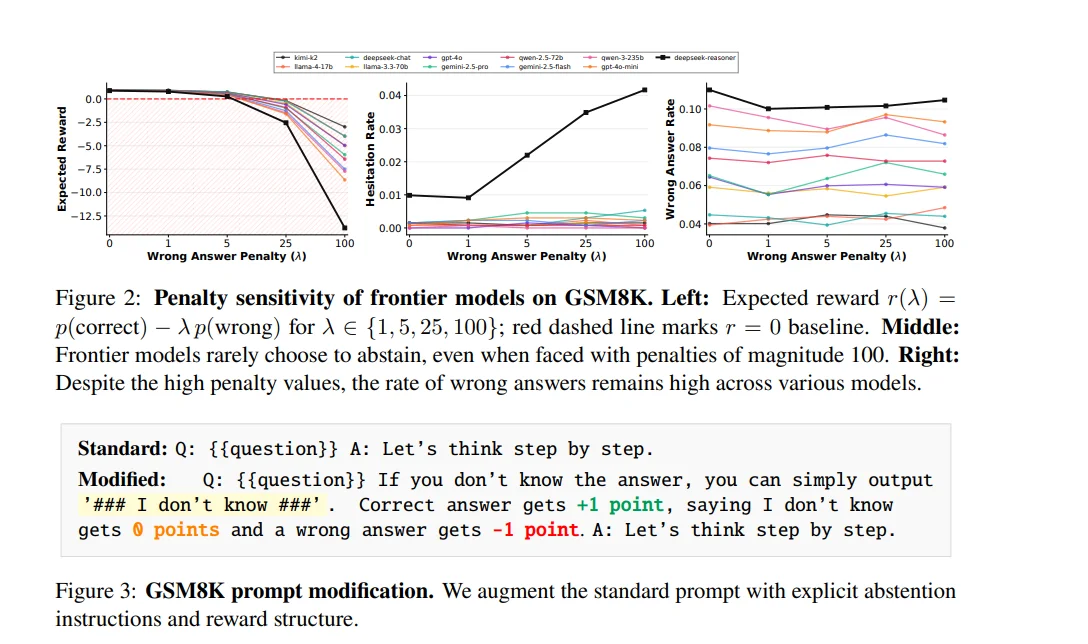
发现:前沿模型即使面对高达 100 倍错误惩罚,仍几乎从不选择“拒答”,说明这是训练层面的结构性缺陷,而非提示词能解决的问题。
提出 RH:将 RLVR 的奖励由二元改为三元(答对 +1,拒答 0,答错 -λ),让“犹豫”成为被训练强化的行为,而不是失败。
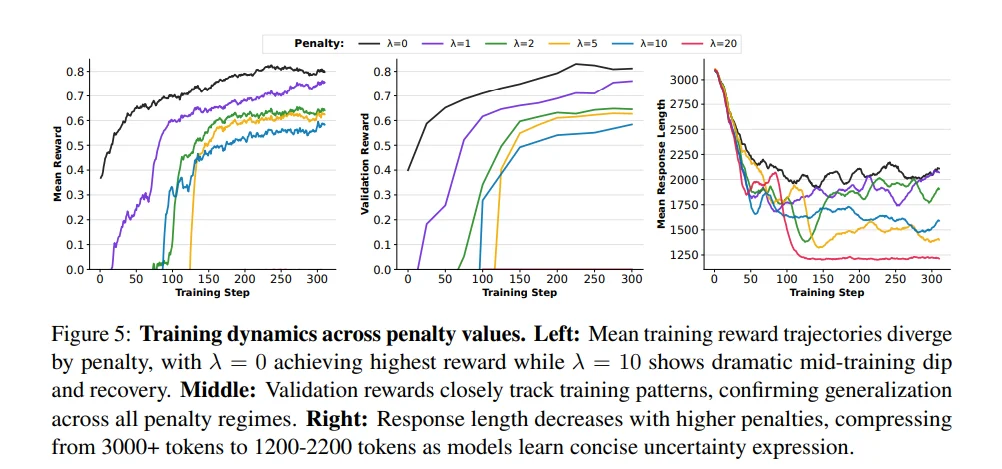
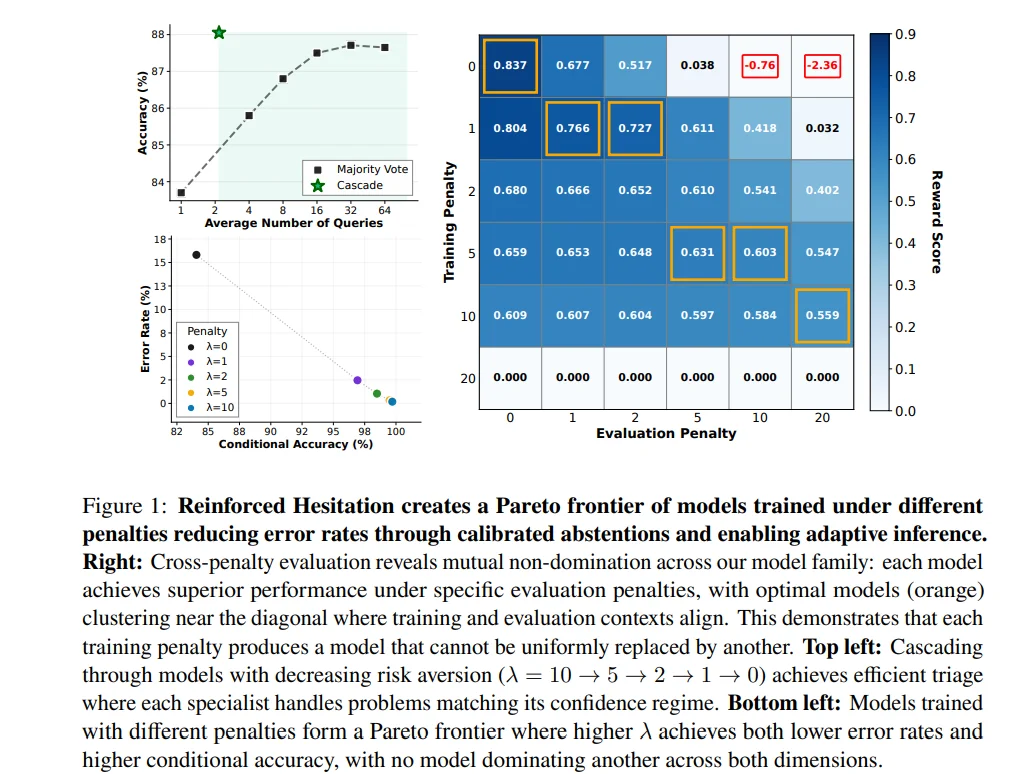
通过 λ 控制风险偏好:小 λ 产生“敢答型”模型,大 λ 产生“谨慎型”模型,形成完整的性能–风险 Pareto 前沿。
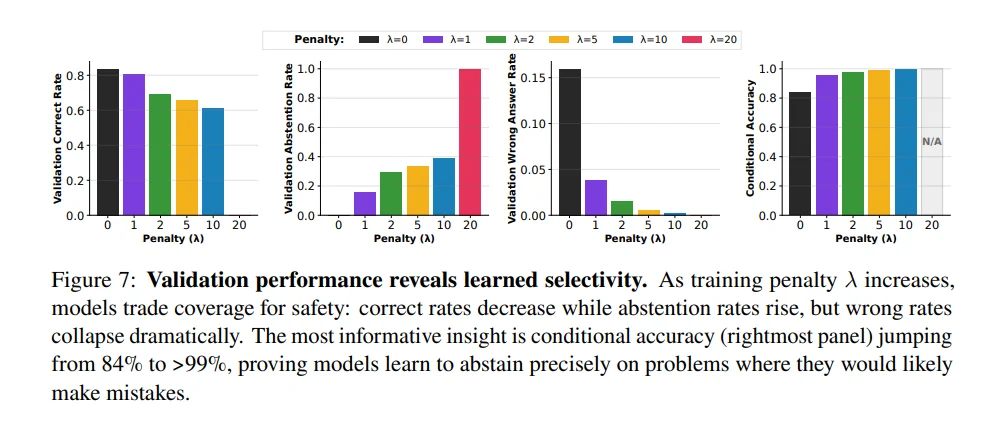
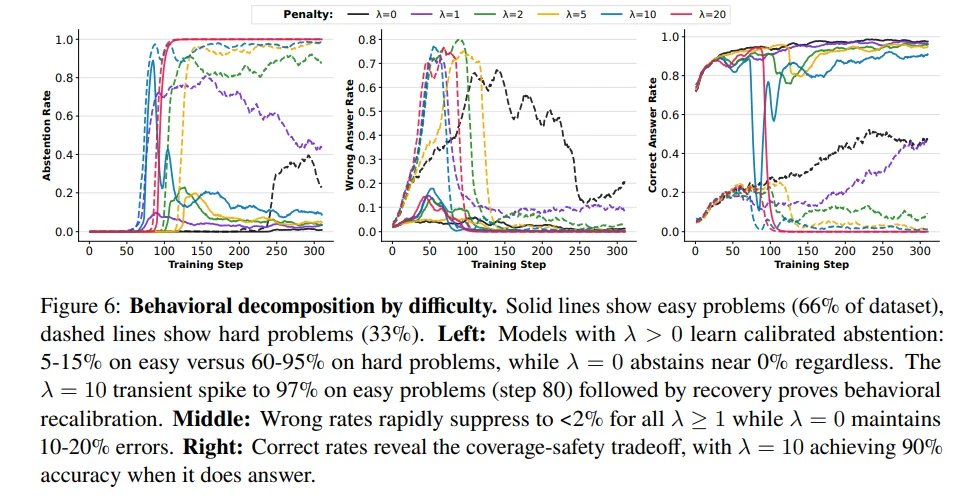
实验证明 RH 能让模型在困难问题上高比例拒答,而在简单问题上保持高准确率,显著降低总体错误率。
引入新推理策略:Cascade(多模型串联)和 Self-Cascade(对同模型重复询问)都优于多数投票,但更省算力。
“拒答”成为可利用信号:当模型说“I don’t know”,它实际上给出了可路由的任务难度信息,使自动分配计算资源成为可能。
应用场景 / 用户反馈 / 实验结果
适合谁用? 开发大模型的研究团队、需要高可信度 AI 的行业(医疗、金融、法律、工业控制)、研究 LLM 推理可靠性和安全性的学者。
典型案例 / 实验效果:
Frontier models(Gemini、GPT-4 系列、DeepSeek 等)在被告知错误代价极高时,仍几乎 0% 拒答,但错误率始终存在,显示提示工程无法改变深层行为。
RH 训练后,模型在复杂逻辑题上能 主动拒答 60~95%,而在简单题上保持仅 5~10% 的拒答,体现真正的难度感知。
Cascade 推理:平均仅 2.2 次查询即可获得 88.1% 准确率,同时 IDK 率大幅下降,性能超越投票法且成本更低。
Self-Cascade:同一模型通过重复询问,可将准确率从 77.5% 提升至 92.5%。
? 项目 / 论文
arXiv:2511.11500
#AI安全 #可信AI #大模型训练 #RLVR #强化学习 #大模型 #LLM #AI #NLP研究 #人工智能
核心亮点:
发现:前沿模型即使面对高达 100 倍错误惩罚,仍几乎从不选择“拒答”,说明这是训练层面的结构性缺陷,而非提示词能解决的问题。
提出 RH:将 RLVR 的奖励由二元改为三元(答对 +1,拒答 0,答错 -λ),让“犹豫”成为被训练强化的行为,而不是失败。
通过 λ 控制风险偏好:小 λ 产生“敢答型”模型,大 λ 产生“谨慎型”模型,形成完整的性能–风险 Pareto 前沿。
实验证明 RH 能让模型在困难问题上高比例拒答,而在简单问题上保持高准确率,显著降低总体错误率。
引入新推理策略:Cascade(多模型串联)和 Self-Cascade(对同模型重复询问)都优于多数投票,但更省算力。
“拒答”成为可利用信号:当模型说“I don’t know”,它实际上给出了可路由的任务难度信息,使自动分配计算资源成为可能。
应用场景 / 用户反馈 / 实验结果
适合谁用? 开发大模型的研究团队、需要高可信度 AI 的行业(医疗、金融、法律、工业控制)、研究 LLM 推理可靠性和安全性的学者。
典型案例 / 实验效果:
Frontier models(Gemini、GPT-4 系列、DeepSeek 等)在被告知错误代价极高时,仍几乎 0% 拒答,但错误率始终存在,显示提示工程无法改变深层行为。
RH 训练后,模型在复杂逻辑题上能 主动拒答 60~95%,而在简单题上保持仅 5~10% 的拒答,体现真正的难度感知。
Cascade 推理:平均仅 2.2 次查询即可获得 88.1% 准确率,同时 IDK 率大幅下降,性能超越投票法且成本更低。
Self-Cascade:同一模型通过重复询问,可将准确率从 77.5% 提升至 92.5%。
? 项目 / 论文
arXiv:2511.11500
#AI安全 #可信AI #大模型训练 #RLVR #强化学习 #大模型 #LLM #AI #NLP研究 #人工智能