



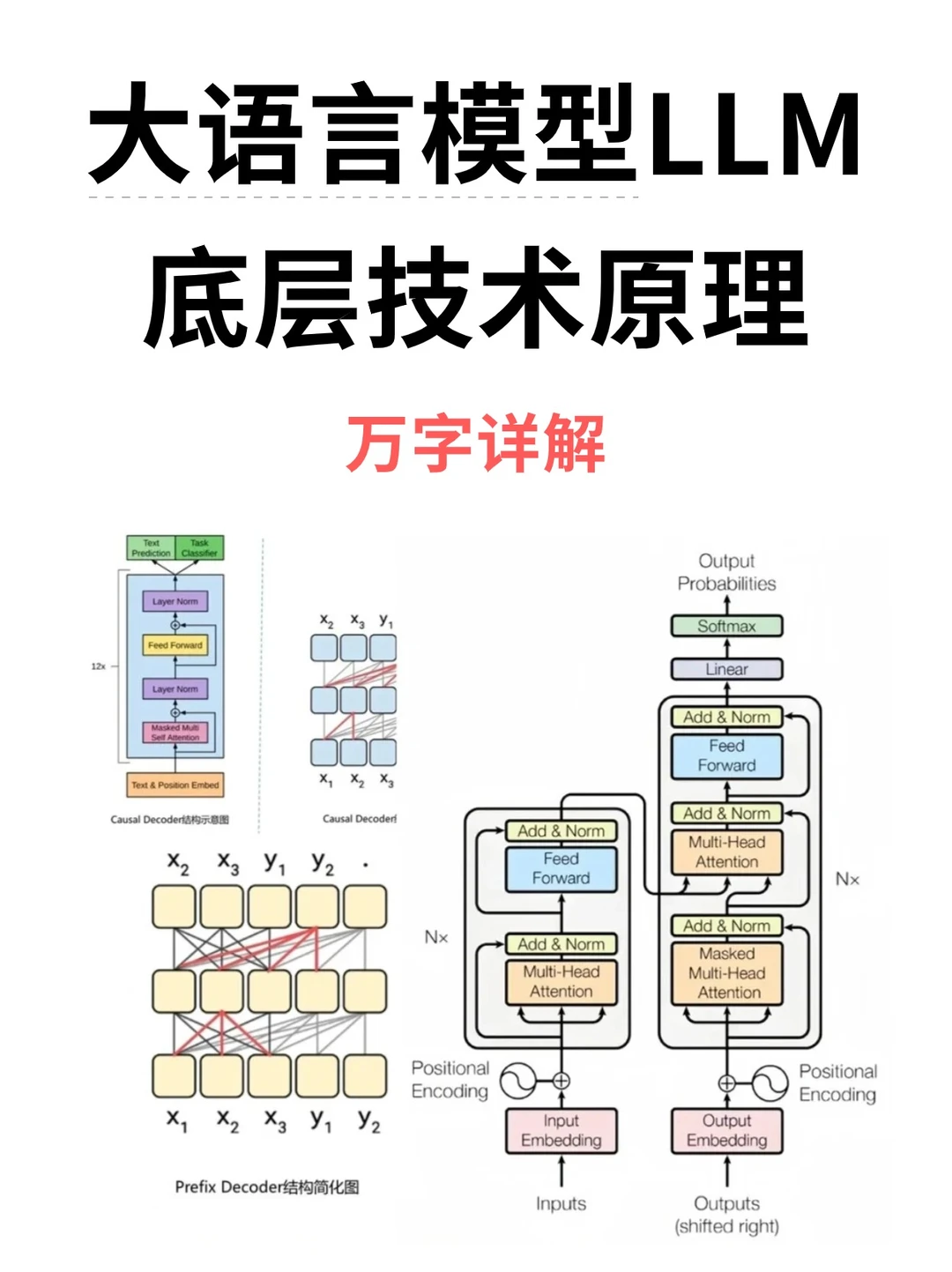




?пјҲLarge Language ModelsпјүжҳҜдёҖз§ҚеҹәдәҺж·ұеәҰеӯҰд№ зҡ„иҮӘ然иҜӯиЁҖеӨ„зҗҶжҠҖжңҜпјҢд»–еҲ©з”ЁеӨ§и§„жЁЎзҡ„ж–Үжң¬и®ӯз»ғпјҢе®һзҺ°ејәеӨ§иҜӯиЁҖжЁЎеһӢзҡ„жһ„е»әгҖӮ
.
?зӣ®еүҚдё»жөҒзҡ„LLMеҹәеә§йғҪйҮҮз”ЁTransformerжһ¶жһ„пјҢе®ғз”ұеӨҡеұӮиҮӘжіЁж„ҸеҠӣжңәеҲ¶е’ҢеүҚйҰҲзҘһз»ҸзҪ‘з»ңз»„жҲҗпјҢж—ЁеңЁе®һзҺ°иҫғй•ҝиҫ“е…ҘеәҸеҲ—зҡ„并иЎҢеӨ„зҗҶгҖӮ
.
вҸіLLMзҡ„е…ій”®жҠҖжңҜ:
вҳ‘пёҸScalingпјҡжӣҙеӨҡзҡ„жЁЎеһӢеҸӮж•°гҖҒж•°жҚ®йҮҸе’Ңи®ӯз»ғи®Ўз®—пјҢеҸҜд»Ҙжңүж•ҲжҸҗеҚҮжЁЎеһӢж•ҲжһңгҖӮ
вҳ‘пёҸTrainingпјҡеҲҶеёғејҸи®ӯз»ғзӯ–з•ҘеҸҠдёҖдәӣжҸҗеҚҮи®ӯз»ғзЁіе®ҡжҖ§е’Ңж•Ҳжһңзҡ„дјҳеҢ–trickгҖӮеҸҰеӨ–иҝҳжңүGPT-4д№ҹжҸҗеҮәеҺ»е»әз«ӢдёҖдәӣзү№ж®Ҡзҡ„е·ҘзЁӢи®ҫж–ҪйҖҡиҝҮе°ҸжЁЎеһӢзҡ„иЎЁзҺ°еҺ»йў„жөӢеӨ§жЁЎеһӢзҡ„иЎЁзҺ°пјҲpredictable scalingпјүгҖӮ
вҳ‘пёҸAbility elicitingпјҡиғҪеҠӣеј•еҜјгҖӮи®ҫи®ЎеҗҲйҖӮзҡ„д»»еҠЎжҢҮд»ӨжҲ–е…·дҪ“зҡ„дёҠдёӢж–ҮеӯҰд№ зӯ–з•ҘеҸҜд»ҘжҝҖеҸ‘LLMеңЁеәһеӨ§йў„ж–ҷдёҠеӯҰд№ еҲ°зҡ„иғҪеҠӣгҖӮ
вҳ‘пёҸAlignment tuningпјҡеҜ№йҪҗеҫ®и°ғгҖӮдёәдәҶйҒҝе…ҚжЁЎеһӢиҫ“еҮәдёҖдәӣдёҚе®үе…ЁжҲ–иҖ…дёҚз¬ҰеҗҲдәәзұ»жӯЈеҗ‘д»·еҖји§Ӯзҡ„еӣһеӨҚпјҢInstructGPTеҲ©з”ЁRLHFпјҲreinforcement learning with human feedbackпјүжҠҖжңҜе®һзҺ°иҝҷдёҖзӣ®зҡ„гҖӮ
вҳ‘пёҸTools manipulationпјҡе·Ҙе…·ж“ҚдҪңгҖӮдёәдәҶејҘиЎҘжЁЎеһӢдёҚж“…й•ҝйқһж–Үжң¬иҫ“еҮәд»»еҠЎе’Ңе®һж—¶дҝЎжҒҜзјәеӨұзҡ„й—®йўҳпјҢи®©жЁЎеһӢеҸҜд»ҘдҪҝз”Ёи®Ўз®—еҷЁгҖҒжҗңзҙўеј•ж“ҺжҲ–иҖ…з»ҷжЁЎеһӢе®үиЈ…жҸ’件зӯүе·Ҙе…·
.
?еӨ§жЁЎеһӢеҸ‘еұ•
еҲҶдёәеӣӣдёӘжӯҘйӘӨпјҡйў„и®ӯз»ғгҖҒзӣ‘зқЈејҸеҫ®и°ғгҖҒеҘ–еҠұе»әжЁЎе’ҢејәеҢ–еӯҰд№
вҳ‘пёҸйў„и®ӯз»ғйҳ¶ж®өйңҖиҰҒеӨ§йҮҸз®—еҠӣпјҢдҪҶеҸҜд»ҘиҠӮзәҰжҲҗжң¬гҖӮ
вҳ‘пёҸеҗҺйқўдёүдёӘйҳ¶ж®өйңҖиҰҒдәәе·ҘеҸӮдёҺпјҢ并且жүҖйңҖзҡ„ж•°жҚ®е’Ңиө„жәҗеәһеӨ§гҖӮ
вҳ‘пёҸLLAMAжҳҜе…¶дёӯзҡ„е…ёеһӢпјҢйҖҡиҝҮж”№иҝӣи§Јз ҒеҷЁжһ¶жһ„е’ҢдҪҝз”Ёзү№е®ҡзҡ„жҝҖжҙ»еҮҪж•°жҸҗеҚҮдәҶи®ӯз»ғзЁіе®ҡжҖ§е’ҢйқһзәҝжҖ§иЎЁеҫҒиғҪеҠӣгҖӮ
вҳ‘пёҸејәеҢ–еӯҰд№ жҳҜжңҖеҗҺдёҖжӯҘпјҢйҖҡиҝҮи®ӯз»ғдәҢе…ғеҲҶзұ»еҷЁе’ҢејәеҢ–еӯҰд№ з®—жі•пјҢиҝӣдёҖжӯҘеҫ®и°ғжЁЎеһӢгҖӮ
#AIдә§е“Ғз»ҸзҗҶ #aiдә§е“Ғз»ҸзҗҶ #еӨ§жЁЎеһӢ #еӨ§иҜӯиЁҖжЁЎеһӢ #llm #LLM #дә§е“Ғз»ҸзҗҶ #з®—жі• #transformer #иҒҢеңә #е№Іиҙ§еҲҶдә«
.
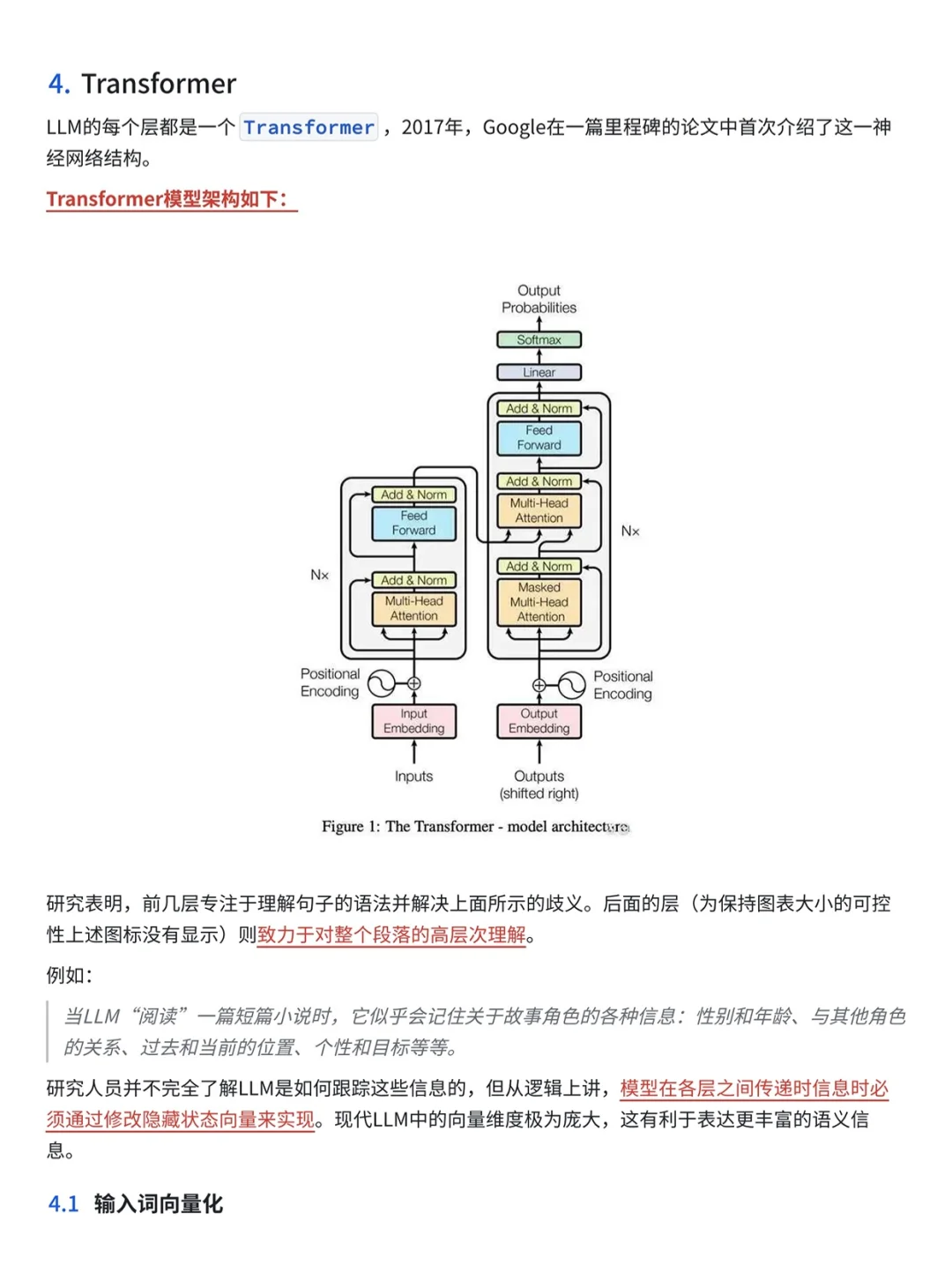
?зӣ®еүҚдё»жөҒзҡ„LLMеҹәеә§йғҪйҮҮз”ЁTransformerжһ¶жһ„пјҢе®ғз”ұеӨҡеұӮиҮӘжіЁж„ҸеҠӣжңәеҲ¶е’ҢеүҚйҰҲзҘһз»ҸзҪ‘з»ңз»„жҲҗпјҢж—ЁеңЁе®һзҺ°иҫғй•ҝиҫ“е…ҘеәҸеҲ—зҡ„并иЎҢеӨ„зҗҶгҖӮ
.
вҸіLLMзҡ„е…ій”®жҠҖжңҜ:
вҳ‘пёҸScalingпјҡжӣҙеӨҡзҡ„жЁЎеһӢеҸӮж•°гҖҒж•°жҚ®йҮҸе’Ңи®ӯз»ғи®Ўз®—пјҢеҸҜд»Ҙжңүж•ҲжҸҗеҚҮжЁЎеһӢж•ҲжһңгҖӮ
вҳ‘пёҸTrainingпјҡеҲҶеёғејҸи®ӯз»ғзӯ–з•ҘеҸҠдёҖдәӣжҸҗеҚҮи®ӯз»ғзЁіе®ҡжҖ§е’Ңж•Ҳжһңзҡ„дјҳеҢ–trickгҖӮеҸҰеӨ–иҝҳжңүGPT-4д№ҹжҸҗеҮәеҺ»е»әз«ӢдёҖдәӣзү№ж®Ҡзҡ„е·ҘзЁӢи®ҫж–ҪйҖҡиҝҮе°ҸжЁЎеһӢзҡ„иЎЁзҺ°еҺ»йў„жөӢеӨ§жЁЎеһӢзҡ„иЎЁзҺ°пјҲpredictable scalingпјүгҖӮ
вҳ‘пёҸAbility elicitingпјҡиғҪеҠӣеј•еҜјгҖӮи®ҫи®ЎеҗҲйҖӮзҡ„д»»еҠЎжҢҮд»ӨжҲ–е…·дҪ“зҡ„дёҠдёӢж–ҮеӯҰд№ зӯ–з•ҘеҸҜд»ҘжҝҖеҸ‘LLMеңЁеәһеӨ§йў„ж–ҷдёҠеӯҰд№ еҲ°зҡ„иғҪеҠӣгҖӮ
вҳ‘пёҸAlignment tuningпјҡеҜ№йҪҗеҫ®и°ғгҖӮдёәдәҶйҒҝе…ҚжЁЎеһӢиҫ“еҮәдёҖдәӣдёҚе®үе…ЁжҲ–иҖ…дёҚз¬ҰеҗҲдәәзұ»жӯЈеҗ‘д»·еҖји§Ӯзҡ„еӣһеӨҚпјҢInstructGPTеҲ©з”ЁRLHFпјҲreinforcement learning with human feedbackпјүжҠҖжңҜе®һзҺ°иҝҷдёҖзӣ®зҡ„гҖӮ
вҳ‘пёҸTools manipulationпјҡе·Ҙе…·ж“ҚдҪңгҖӮдёәдәҶејҘиЎҘжЁЎеһӢдёҚж“…й•ҝйқһж–Үжң¬иҫ“еҮәд»»еҠЎе’Ңе®һж—¶дҝЎжҒҜзјәеӨұзҡ„й—®йўҳпјҢи®©жЁЎеһӢеҸҜд»ҘдҪҝз”Ёи®Ўз®—еҷЁгҖҒжҗңзҙўеј•ж“ҺжҲ–иҖ…з»ҷжЁЎеһӢе®үиЈ…жҸ’件зӯүе·Ҙе…·
.
?еӨ§жЁЎеһӢеҸ‘еұ•
еҲҶдёәеӣӣдёӘжӯҘйӘӨпјҡйў„и®ӯз»ғгҖҒзӣ‘зқЈејҸеҫ®и°ғгҖҒеҘ–еҠұе»әжЁЎе’ҢејәеҢ–еӯҰд№
вҳ‘пёҸйў„и®ӯз»ғйҳ¶ж®өйңҖиҰҒеӨ§йҮҸз®—еҠӣпјҢдҪҶеҸҜд»ҘиҠӮзәҰжҲҗжң¬гҖӮ
вҳ‘пёҸеҗҺйқўдёүдёӘйҳ¶ж®өйңҖиҰҒдәәе·ҘеҸӮдёҺпјҢ并且жүҖйңҖзҡ„ж•°жҚ®е’Ңиө„жәҗеәһеӨ§гҖӮ
вҳ‘пёҸLLAMAжҳҜе…¶дёӯзҡ„е…ёеһӢпјҢйҖҡиҝҮж”№иҝӣи§Јз ҒеҷЁжһ¶жһ„е’ҢдҪҝз”Ёзү№е®ҡзҡ„жҝҖжҙ»еҮҪж•°жҸҗеҚҮдәҶи®ӯз»ғзЁіе®ҡжҖ§е’ҢйқһзәҝжҖ§иЎЁеҫҒиғҪеҠӣгҖӮ
вҳ‘пёҸејәеҢ–еӯҰд№ жҳҜжңҖеҗҺдёҖжӯҘпјҢйҖҡиҝҮи®ӯз»ғдәҢе…ғеҲҶзұ»еҷЁе’ҢејәеҢ–еӯҰд№ з®—жі•пјҢиҝӣдёҖжӯҘеҫ®и°ғжЁЎеһӢгҖӮ
#AIдә§е“Ғз»ҸзҗҶ #aiдә§е“Ғз»ҸзҗҶ #еӨ§жЁЎеһӢ #еӨ§иҜӯиЁҖжЁЎеһӢ #llm #LLM #дә§е“Ғз»ҸзҗҶ #з®—жі• #transformer #иҒҢеңә #е№Іиҙ§еҲҶдә«