



DeepMindжңҖж–°з ”з©¶гҖҠDense and Diverse Goal Coverage in Multi Goal Reinforcement LearningгҖӢжҸҗеҮәдёҖз§Қе…Ёж–°з®—жі•вҖ”вҖ”DDGCпјҲDense & Diverse Goal CoverageпјүпјҢзӘҒз ҙдәҶдј з»ҹејәеҢ–еӯҰд№ еңЁеӨҡзӣ®ж ҮеңәжҷҜдёӯвҖңй«ҳеӣһжҠҘдҪҶдҪҺеӨҡж ·жҖ§вҖқзҡ„еұҖйҷҗгҖӮе®ғиғҪеңЁдҝқжҢҒй«ҳ收зӣҠзҡ„еҗҢж—¶пјҢе®һзҺ°еҜ№еӨҡдёӘзӣ®ж ҮзҠ¶жҖҒзҡ„еқҮиЎЎиҰҶзӣ–пјҢжһҒеӨ§жҸҗеҚҮзӯ–з•Ҙзҡ„йІҒжЈ’жҖ§дёҺжіӣеҢ–иғҪеҠӣгҖӮ
ж ёеҝғдә®зӮ№пјҡ
ж–°зӣ®ж ҮеҮҪж•°и®ҫи®Ўпјҡе°ҶвҖңеӣһжҠҘжңҖеӨ§еҢ–вҖқдёҺвҖңзӣ®ж ҮеӨҡж ·жҖ§вҖқз»ҹдёҖдёәдёҖдёӘеҸҜдјҳеҢ–зҡ„зӣ®ж ҮеҮҪж•° Z(ПҖ)=JОі(ПҖ)+IS+(ПҖ)Z(\\pi)=J_\\gamma(\\pi)+I_{S+}(\\pi)Z(ПҖ)=JОівҖӢ(ПҖ)+IS+вҖӢ(ПҖ)пјҢе…јйЎҫеӣһжҠҘдёҺзӣ®ж ҮеҲҶеёғеқҮеҢҖжҖ§гҖӮ
еҹәдәҺFrankвҖ“WolfeжЎҶжһ¶пјҡйҮҮз”ЁеҮёдјҳеҢ–жҖқи·Ҝиҝӯд»Јжӣҙж–°зӯ–з•Ҙж··еҗҲпјҢдҝқиҜҒ算法收ж•ӣжҖ§дёҺеҸҜи§ЈйҮҠжҖ§гҖӮ
иҮӘйҖӮеә”еҘ–еҠұжңәеҲ¶пјҡдёәзЁҖз–Ҹзӣ®ж Үи®ҫи®ЎиҮӘе®ҡд№үеҘ–еҠұ r(s)=1вҲ’d^(s)r(s)=1-dМӮ(s)r(s)=1вҲ’d^(s)пјҢдҪҝз®—жі•дјҳе…ҲжҺўзҙўи®ҝй—®йў‘зҺҮдҪҺзҡ„зӣ®ж ҮгҖӮ
зҰ»зәҝRLеӯҗдҫӢзЁӢйӣҶжҲҗпјҡжҜҸжӯҘйҖҡиҝҮFitted Q IterationпјҲFQIпјүжӣҙж–°зӯ–з•ҘпјҢзҗҶи®әдёҠжҸҗдҫӣ O(1/K)O(1/K)O(1/K) зҡ„收ж•ӣз•ҢгҖӮ
зҗҶи®әдҝқйҡңе®Ңе–„пјҡжҸҗдҫӣдёҘж јжҖ§иғҪдёҠз•ҢдёҺ收ж•ӣжҖ§иҜҒжҳҺпјҢиҜҜе·®жқҘжәҗпјҲиҝ‘дјјиҜҜе·®гҖҒйҮҮж ·иҜҜе·®пјүеқҮиў«еҪўејҸеҢ–йҮҸеҢ–гҖӮ
ж”ҜжҢҒиҝһз»ӯз©әй—ҙжү©еұ•пјҡз»“еҗҲиҝһз»ӯзүҲFQIпјҲFitted Actor-CriticпјүеҸҠзҰ»ж•ЈеҢ–дј°и®ЎпјҢйҖӮз”ЁдәҺеӨҚжқӮжңәеҷЁдәәжҺ§еҲ¶зҺҜеўғгҖӮ
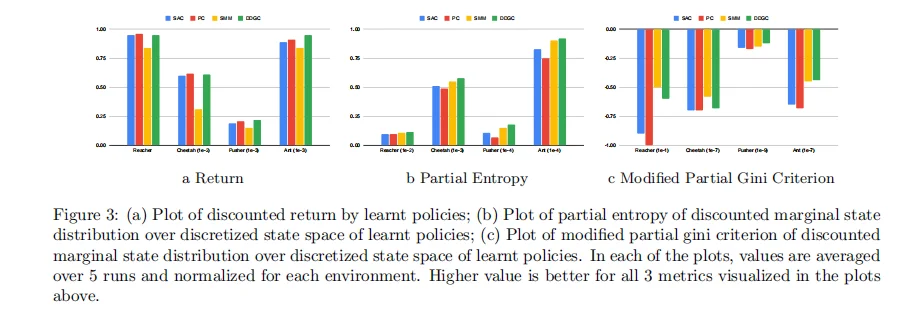
з»ҸйӘҢйӘҢиҜҒдјҳи¶ҠпјҡеңЁReacherгҖҒPusherгҖҒAntгҖҒHalfCheetahзӯүж ҮеҮҶзҺҜеўғдёӯпјҢDDGCеңЁвҖңеӣһжҠҘвҖқдёҺвҖңзӣ®ж ҮеӨҡж ·жҖ§вҖқдёӨйЎ№жҢҮж ҮдёҠеқҮдјҳдәҺSACгҖҒSMMзӯүеҹәзәҝгҖӮ
еә”з”ЁеңәжҷҜ / з”ЁжҲ·еҸҚйҰҲ / е®һйӘҢз»“жһңпјҡ йҖӮз”ЁдәҺеӨҡзӣ®ж ҮејәеҢ–еӯҰд№ гҖҒжңәеҷЁдәәжҺ§еҲ¶гҖҒиҮӘеҠЁжҺўзҙўгҖҒеҲҶеӯҗз»“жһ„еҸ‘зҺ°зӯүйңҖиҰҒеӨҡж ·зӣ®ж ҮиҰҶзӣ–зҡ„еңәжҷҜгҖӮ е®һйӘҢиЎЁжҳҺпјҡ
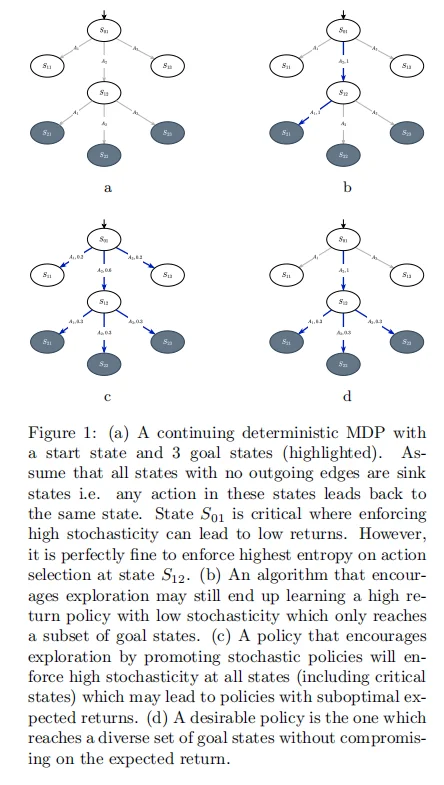
еңЁеҗҲжҲҗMDPдёӯпјҢDDGCиғҪеңЁеӨҡдёӘзӣ®ж ҮзҠ¶жҖҒдёҠе®һзҺ°иҝ‘д№ҺеқҮеҢҖеҲҶеёғпјӣ
еңЁBraxеӨҡзӣ®ж ҮеҹәеҮҶдёӯпјҢDDGCеңЁдҝқжҢҒй«ҳеӣһжҠҘзҡ„еҗҢж—¶е®һзҺ°жңҖй«ҳвҖңйғЁеҲҶзҶөвҖқе’ҢвҖңGiniеӨҡж ·жҖ§вҖқеҲҶж•°пјӣ
зӣёжҜ”SACд»…иҒҡз„ҰеҚ•дёҖи·Ҝеҫ„пјҢDDGCжҳҫи‘—жҸҗеҚҮзӯ–з•ҘзЁіеҒҘжҖ§дёҺжіӣеҢ–иғҪеҠӣгҖӮ
? и®әж–ҮпјҡarXiv:2510.25311v1
#ејәеҢ–еӯҰд№ #DeepMind #еӨҡзӣ®ж ҮдјҳеҢ– #жҺўзҙўз®—жі• #жңәеҷЁдәәжҺ§еҲ¶ #AIз ”з©¶ #еҲҶеёғејҸ #зҰ»зәҝеӯҰд№ #жңәеҷЁжҷәиғҪ #и°·жӯҢ
ж ёеҝғдә®зӮ№пјҡ
ж–°зӣ®ж ҮеҮҪж•°и®ҫи®Ўпјҡе°ҶвҖңеӣһжҠҘжңҖеӨ§еҢ–вҖқдёҺвҖңзӣ®ж ҮеӨҡж ·жҖ§вҖқз»ҹдёҖдёәдёҖдёӘеҸҜдјҳеҢ–зҡ„зӣ®ж ҮеҮҪж•° Z(ПҖ)=JОі(ПҖ)+IS+(ПҖ)Z(\\pi)=J_\\gamma(\\pi)+I_{S+}(\\pi)Z(ПҖ)=JОівҖӢ(ПҖ)+IS+вҖӢ(ПҖ)пјҢе…јйЎҫеӣһжҠҘдёҺзӣ®ж ҮеҲҶеёғеқҮеҢҖжҖ§гҖӮ
еҹәдәҺFrankвҖ“WolfeжЎҶжһ¶пјҡйҮҮз”ЁеҮёдјҳеҢ–жҖқи·Ҝиҝӯд»Јжӣҙж–°зӯ–з•Ҙж··еҗҲпјҢдҝқиҜҒ算法收ж•ӣжҖ§дёҺеҸҜи§ЈйҮҠжҖ§гҖӮ
иҮӘйҖӮеә”еҘ–еҠұжңәеҲ¶пјҡдёәзЁҖз–Ҹзӣ®ж Үи®ҫи®ЎиҮӘе®ҡд№үеҘ–еҠұ r(s)=1вҲ’d^(s)r(s)=1-dМӮ(s)r(s)=1вҲ’d^(s)пјҢдҪҝз®—жі•дјҳе…ҲжҺўзҙўи®ҝй—®йў‘зҺҮдҪҺзҡ„зӣ®ж ҮгҖӮ
зҰ»зәҝRLеӯҗдҫӢзЁӢйӣҶжҲҗпјҡжҜҸжӯҘйҖҡиҝҮFitted Q IterationпјҲFQIпјүжӣҙж–°зӯ–з•ҘпјҢзҗҶи®әдёҠжҸҗдҫӣ O(1/K)O(1/K)O(1/K) зҡ„收ж•ӣз•ҢгҖӮ
зҗҶи®әдҝқйҡңе®Ңе–„пјҡжҸҗдҫӣдёҘж јжҖ§иғҪдёҠз•ҢдёҺ收ж•ӣжҖ§иҜҒжҳҺпјҢиҜҜе·®жқҘжәҗпјҲиҝ‘дјјиҜҜе·®гҖҒйҮҮж ·иҜҜе·®пјүеқҮиў«еҪўејҸеҢ–йҮҸеҢ–гҖӮ
ж”ҜжҢҒиҝһз»ӯз©әй—ҙжү©еұ•пјҡз»“еҗҲиҝһз»ӯзүҲFQIпјҲFitted Actor-CriticпјүеҸҠзҰ»ж•ЈеҢ–дј°и®ЎпјҢйҖӮз”ЁдәҺеӨҚжқӮжңәеҷЁдәәжҺ§еҲ¶зҺҜеўғгҖӮ
з»ҸйӘҢйӘҢиҜҒдјҳи¶ҠпјҡеңЁReacherгҖҒPusherгҖҒAntгҖҒHalfCheetahзӯүж ҮеҮҶзҺҜеўғдёӯпјҢDDGCеңЁвҖңеӣһжҠҘвҖқдёҺвҖңзӣ®ж ҮеӨҡж ·жҖ§вҖқдёӨйЎ№жҢҮж ҮдёҠеқҮдјҳдәҺSACгҖҒSMMзӯүеҹәзәҝгҖӮ
еә”з”ЁеңәжҷҜ / з”ЁжҲ·еҸҚйҰҲ / е®һйӘҢз»“жһңпјҡ йҖӮз”ЁдәҺеӨҡзӣ®ж ҮејәеҢ–еӯҰд№ гҖҒжңәеҷЁдәәжҺ§еҲ¶гҖҒиҮӘеҠЁжҺўзҙўгҖҒеҲҶеӯҗз»“жһ„еҸ‘зҺ°зӯүйңҖиҰҒеӨҡж ·зӣ®ж ҮиҰҶзӣ–зҡ„еңәжҷҜгҖӮ е®һйӘҢиЎЁжҳҺпјҡ
еңЁеҗҲжҲҗMDPдёӯпјҢDDGCиғҪеңЁеӨҡдёӘзӣ®ж ҮзҠ¶жҖҒдёҠе®һзҺ°иҝ‘д№ҺеқҮеҢҖеҲҶеёғпјӣ
еңЁBraxеӨҡзӣ®ж ҮеҹәеҮҶдёӯпјҢDDGCеңЁдҝқжҢҒй«ҳеӣһжҠҘзҡ„еҗҢж—¶е®һзҺ°жңҖй«ҳвҖңйғЁеҲҶзҶөвҖқе’ҢвҖңGiniеӨҡж ·жҖ§вҖқеҲҶж•°пјӣ
зӣёжҜ”SACд»…иҒҡз„ҰеҚ•дёҖи·Ҝеҫ„пјҢDDGCжҳҫи‘—жҸҗеҚҮзӯ–з•ҘзЁіеҒҘжҖ§дёҺжіӣеҢ–иғҪеҠӣгҖӮ
? и®әж–ҮпјҡarXiv:2510.25311v1
#ејәеҢ–еӯҰд№ #DeepMind #еӨҡзӣ®ж ҮдјҳеҢ– #жҺўзҙўз®—жі• #жңәеҷЁдәәжҺ§еҲ¶ #AIз ”з©¶ #еҲҶеёғејҸ #зҰ»зәҝеӯҰд№ #жңәеҷЁжҷәиғҪ #и°·жӯҢ