










✨ MeasureBench是什么?
MeasureBench是一个全面的基准测试,旨在评估视觉语言模型(VLMs)在读取测量仪器方面的性能。该基准测试包括2,442个图像-问题对,其中1,272个来自真实世界,1,170个来自合成数据。这些数据覆盖了26种不同类型的测量仪器,包括模拟表盘、数字显示、线性刻度和复合读数设计。通过这些多样化的数据,MeasureBench能够全面评估VLMs在细粒度视觉理解方面的表现。
?️MeasureBench的数据合成框架如何工作?
MeasureBench的数据合成框架能够生成多样化的测量仪器图像,包括2D程序化渲染和3D物理渲染两种路径。2D渲染路径使用代码模板生成图像,适用于大规模实验;3D渲染路径则使用Blender生成逼真的图像,减少模拟与真实世界的差距。该框架能够随机化刻度、单位、指针角度、材料、光照、背景和相机姿态,生成39种不同外观的17种仪器类型,每种外观生成30张图像,总计1,170张合成图像。
? MeasureBench的评估结果如何?
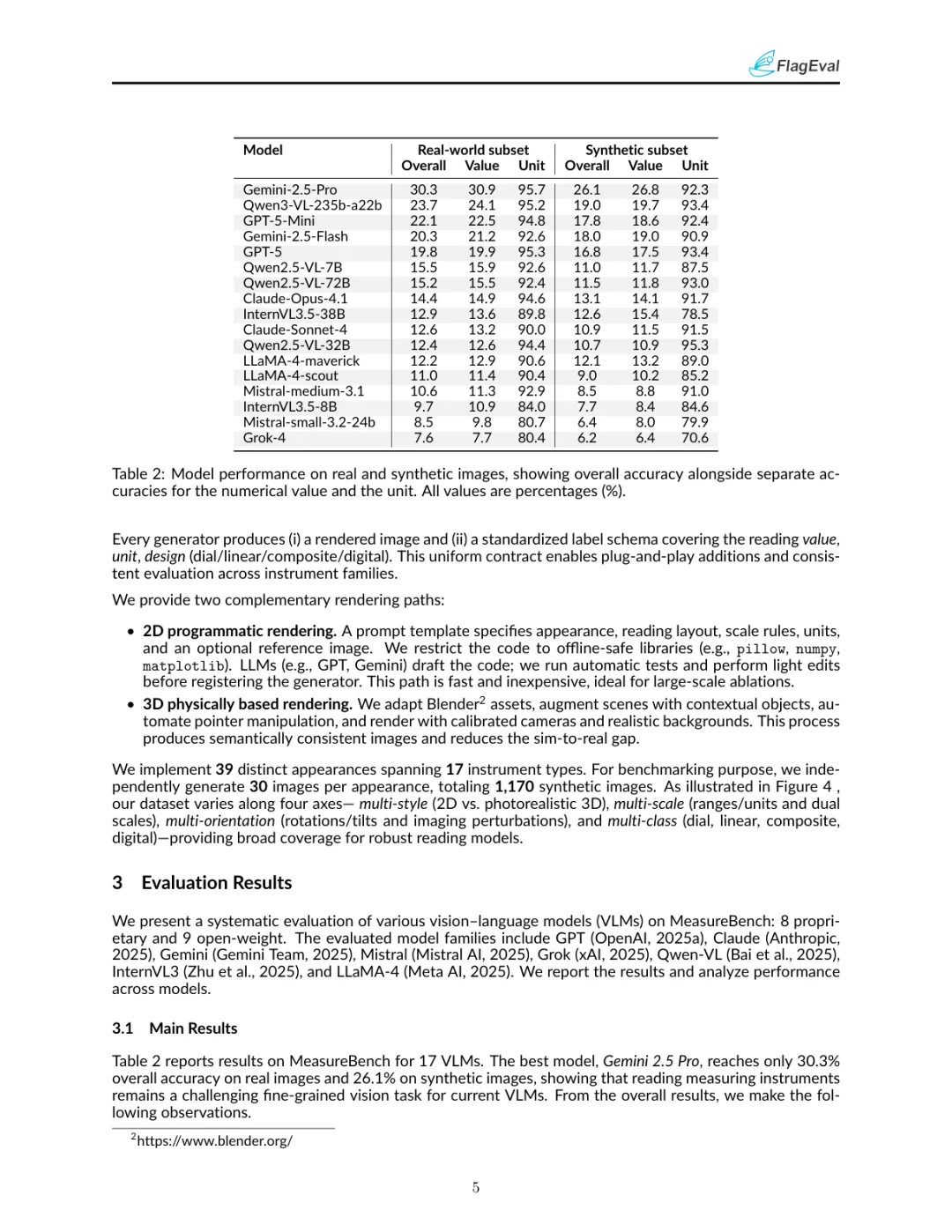
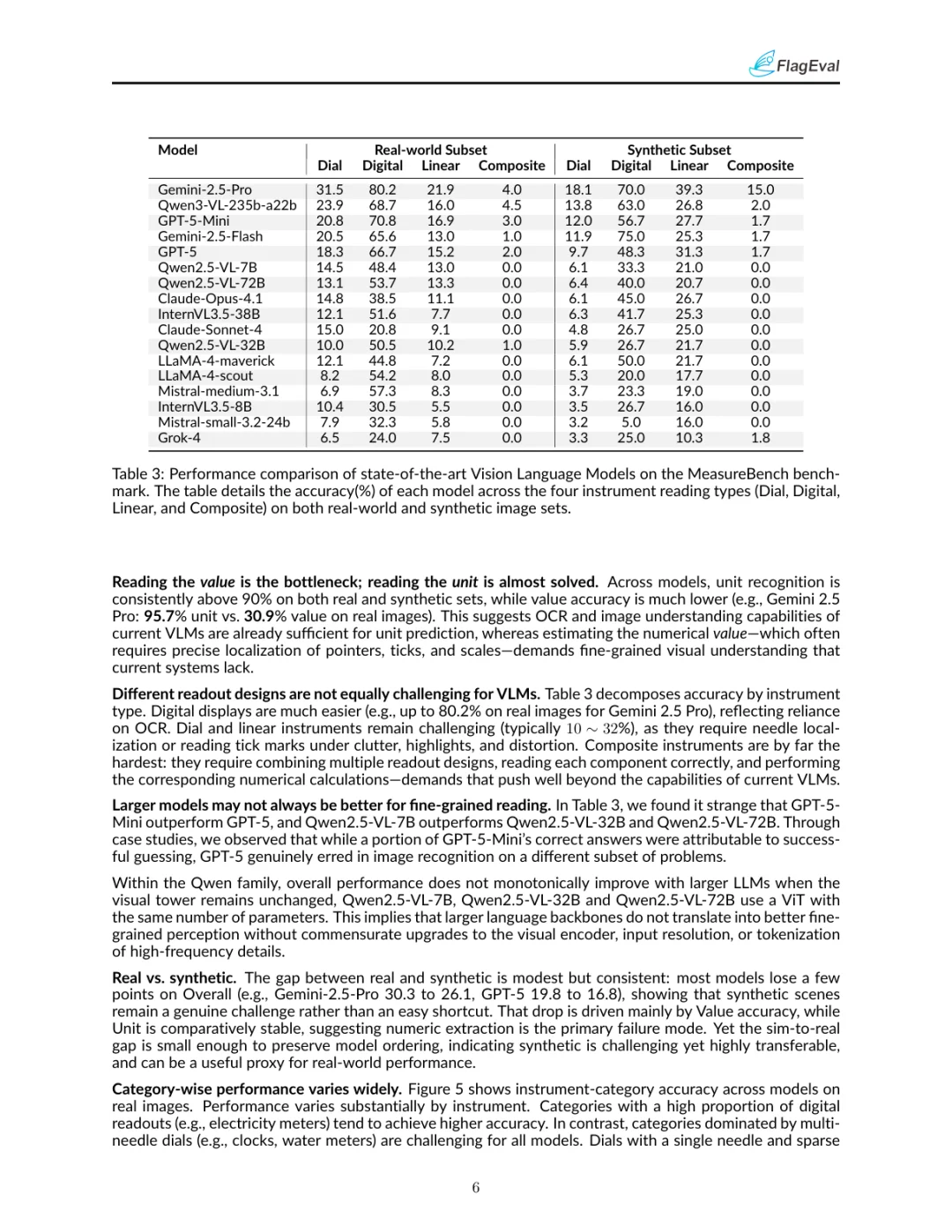
评估结果显示,即使是当前最先进的VLMs在读取测量仪器方面仍然面临巨大挑战。例如,Gemini 2.5 Pro在真实图像上的准确率为30.3%,在合成图像上的准确率为26.1%。尽管这些模型在识别单位方面表现良好(准确率超过90%),但在读取数值时却经常出错,尤其是在指针定位和刻度读取方面。不同类型的读数设计对VLMs的挑战也不同,数字显示相对容易,而模拟表盘和线性刻度则更为困难。
? MeasureBench的强化学习实验结果如何?
使用合成数据进行强化学习的初步实验显示,模型在合成数据集上的性能显著提升,从11.0%提高到35.2%。然而,这种提升在真实世界图像上的效果较为有限,准确率从15.5%提高到20.1%。这表明合成数据虽然有助于模型学习,但仍然存在从模拟到真实世界的迁移问题。#测量读取 #计算机视觉 #数据集 #多模态人工智能 #大模型
MeasureBench是一个全面的基准测试,旨在评估视觉语言模型(VLMs)在读取测量仪器方面的性能。该基准测试包括2,442个图像-问题对,其中1,272个来自真实世界,1,170个来自合成数据。这些数据覆盖了26种不同类型的测量仪器,包括模拟表盘、数字显示、线性刻度和复合读数设计。通过这些多样化的数据,MeasureBench能够全面评估VLMs在细粒度视觉理解方面的表现。
?️MeasureBench的数据合成框架如何工作?
MeasureBench的数据合成框架能够生成多样化的测量仪器图像,包括2D程序化渲染和3D物理渲染两种路径。2D渲染路径使用代码模板生成图像,适用于大规模实验;3D渲染路径则使用Blender生成逼真的图像,减少模拟与真实世界的差距。该框架能够随机化刻度、单位、指针角度、材料、光照、背景和相机姿态,生成39种不同外观的17种仪器类型,每种外观生成30张图像,总计1,170张合成图像。
? MeasureBench的评估结果如何?
评估结果显示,即使是当前最先进的VLMs在读取测量仪器方面仍然面临巨大挑战。例如,Gemini 2.5 Pro在真实图像上的准确率为30.3%,在合成图像上的准确率为26.1%。尽管这些模型在识别单位方面表现良好(准确率超过90%),但在读取数值时却经常出错,尤其是在指针定位和刻度读取方面。不同类型的读数设计对VLMs的挑战也不同,数字显示相对容易,而模拟表盘和线性刻度则更为困难。
? MeasureBench的强化学习实验结果如何?
使用合成数据进行强化学习的初步实验显示,模型在合成数据集上的性能显著提升,从11.0%提高到35.2%。然而,这种提升在真实世界图像上的效果较为有限,准确率从15.5%提高到20.1%。这表明合成数据虽然有助于模型学习,但仍然存在从模拟到真实世界的迁移问题。#测量读取 #计算机视觉 #数据集 #多模态人工智能 #大模型