



我们发表于Nature Communications的工作,突破了医学AI评测的瓶颈——如何显式地评测大模型的“推理过程”,而非仅仅关注答案对错?
? 为什么医学是评测AI推理的完美场景?
(1) 有标准答案:临床指南与病例报告为“正确推理”提供了金标准
(2) 有真实案例:病例报告完整记录了症状、检查、鉴别诊断与治疗规划的逻辑链
(3) 有刚性需求:临床决策容不得幻觉推理,每一步都必须可解释、可验证
? 我们的核心贡献
基于上述洞察,我们构建了:
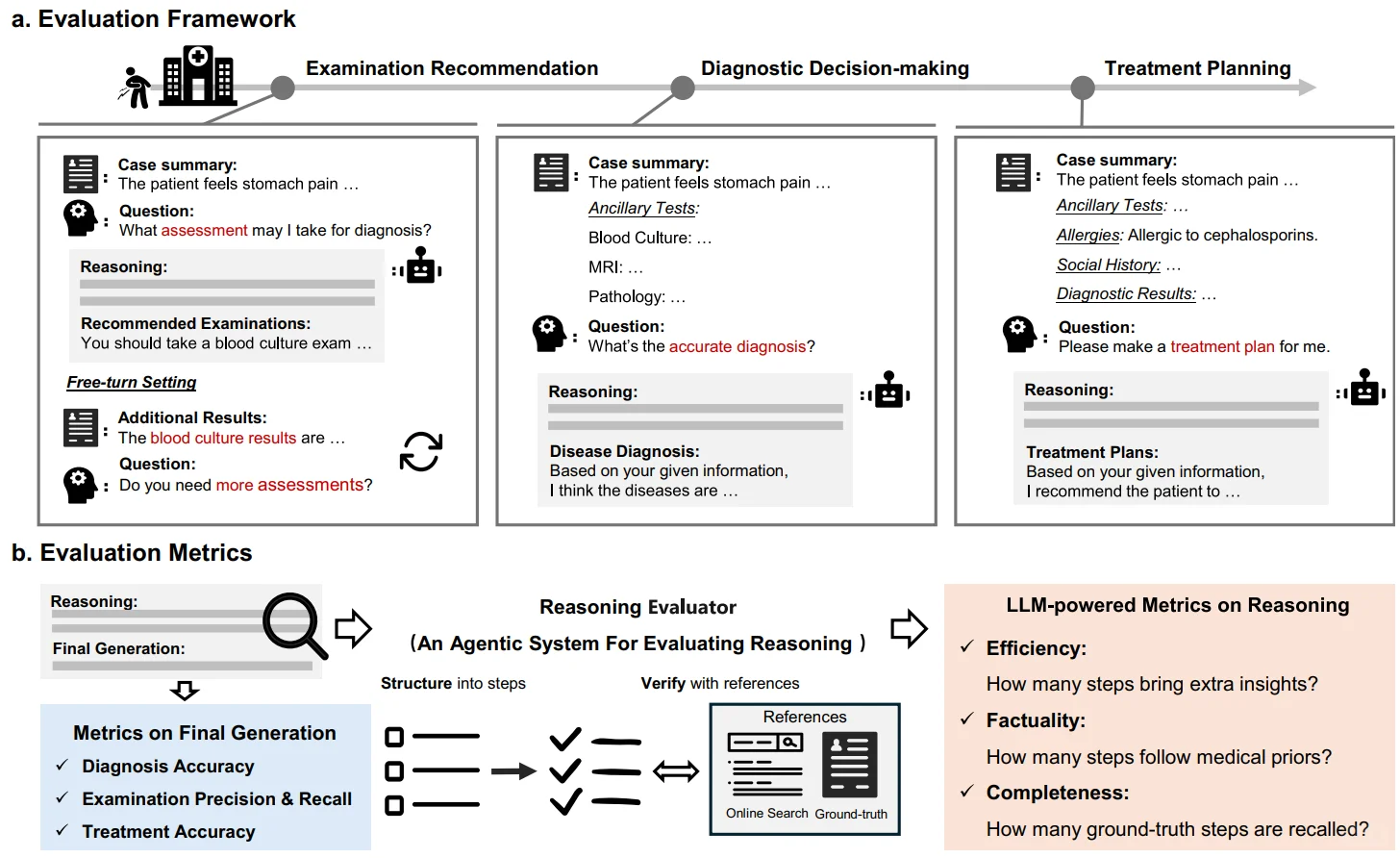
1️⃣ MedRBench 评测基准:从真实病例报告中提炼构建,涵盖1,453个结构化病例,覆盖13个人体系统与10大专科。其核心价值在于,不仅提供问题与答案,更提供了由医生验证过的临床决策推理过程作为评估的黄金标准。
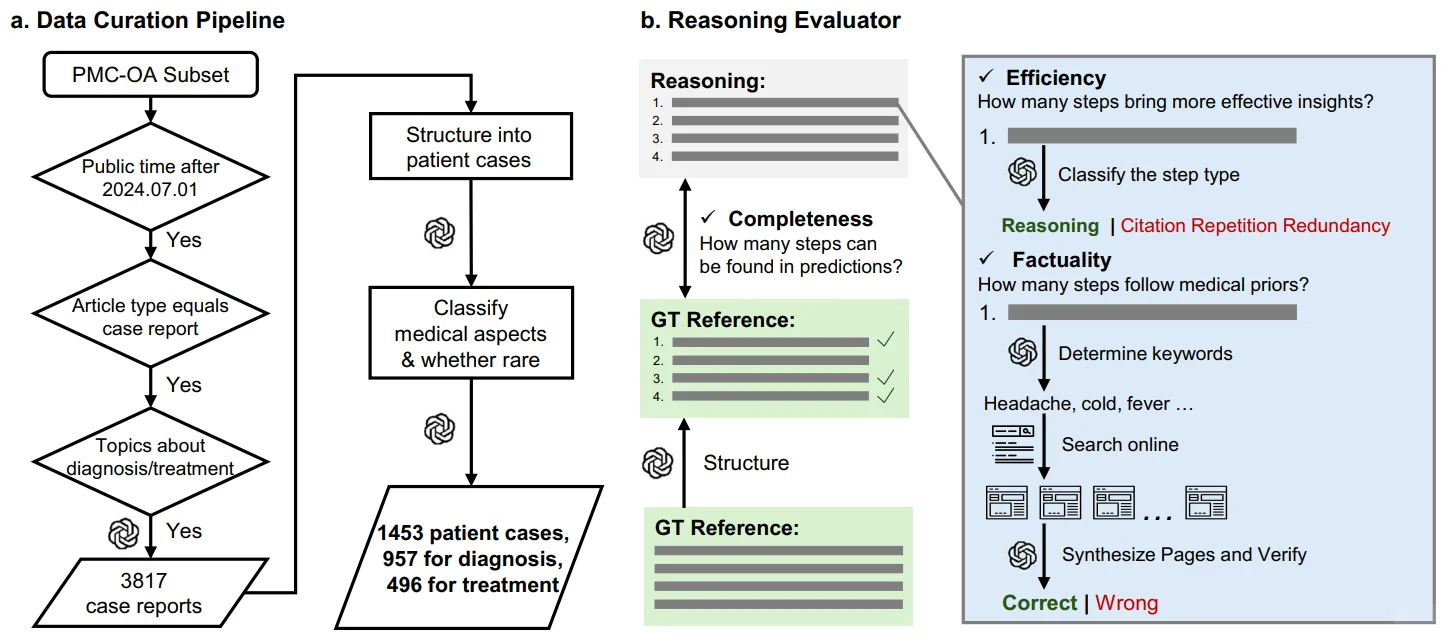
2️⃣ Reasoning Evaluator 智能评测系统:该系统能自动搜索网络医学资源,从效率、事实准确性与完整性三个维度,将模型的“推理过程”与专业的“金标准”进行比对量化,实现可靠、可扩展的自动评估。
? 主要发现:
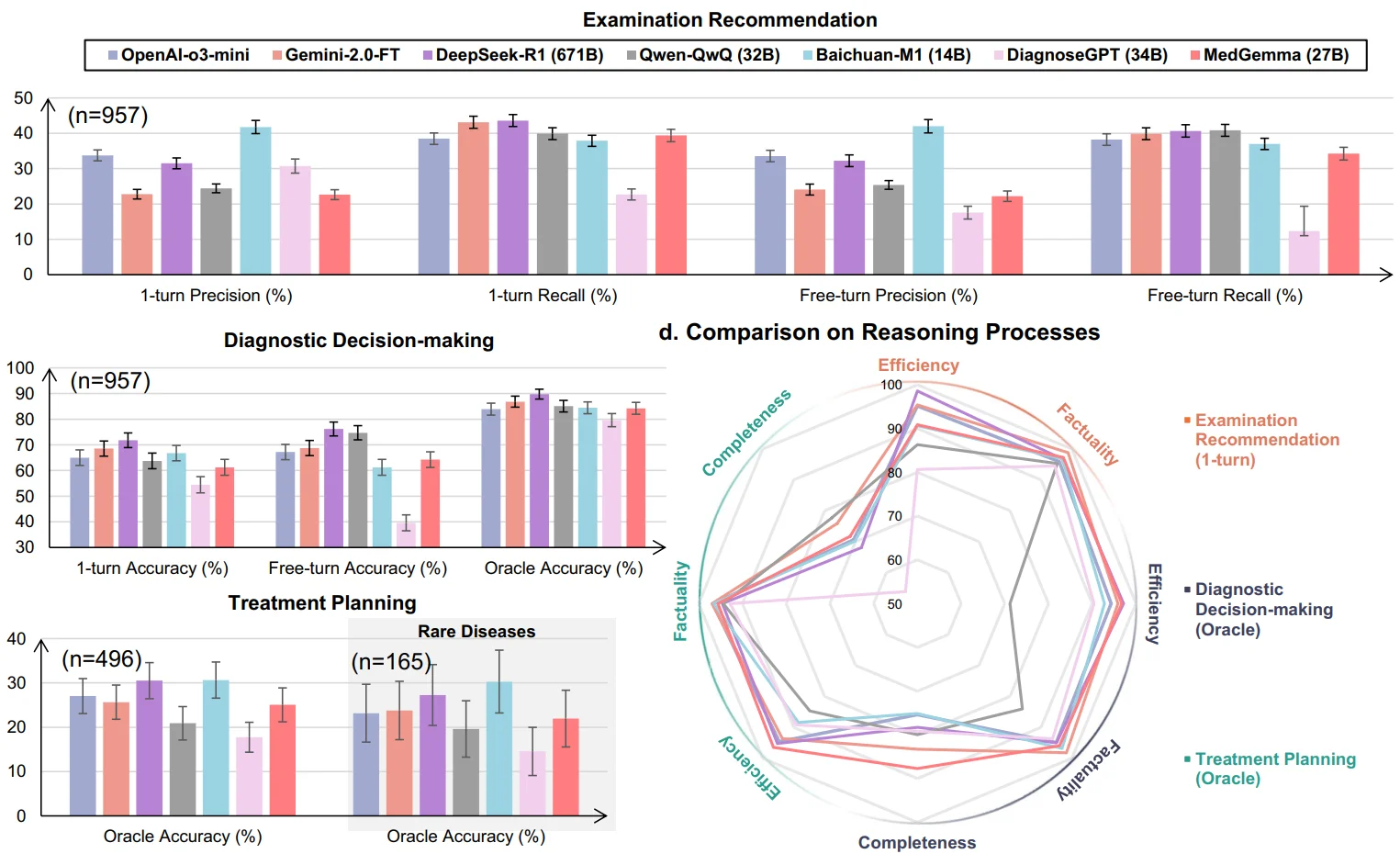
诊断能力:信息充足时准确率>85%,信息有限时骤降至65-75%
推理质量:事实准确性>90%,但完整性仅70-80%,关键步骤大量缺失
治疗规划:准确率仅约30%,远未达到临床可用标准
? 相关资源:
GitHub项目:https://github.com/MAGIC-AI4Med/MedRBench/tree/main
Paper:https://www.nature.com/articles/s41467-025-64769-1
P1:临床评估框架 | 模拟从检查推荐到治疗规划的完整诊疗路径及量化指标
P2:模型性能对比 | 七大主流LLM在诊断、检查、治疗三大任务中的评测结果
P3:推理评估机制 | Reasoning Evaluator系统数据构建和多维度量化评估流程
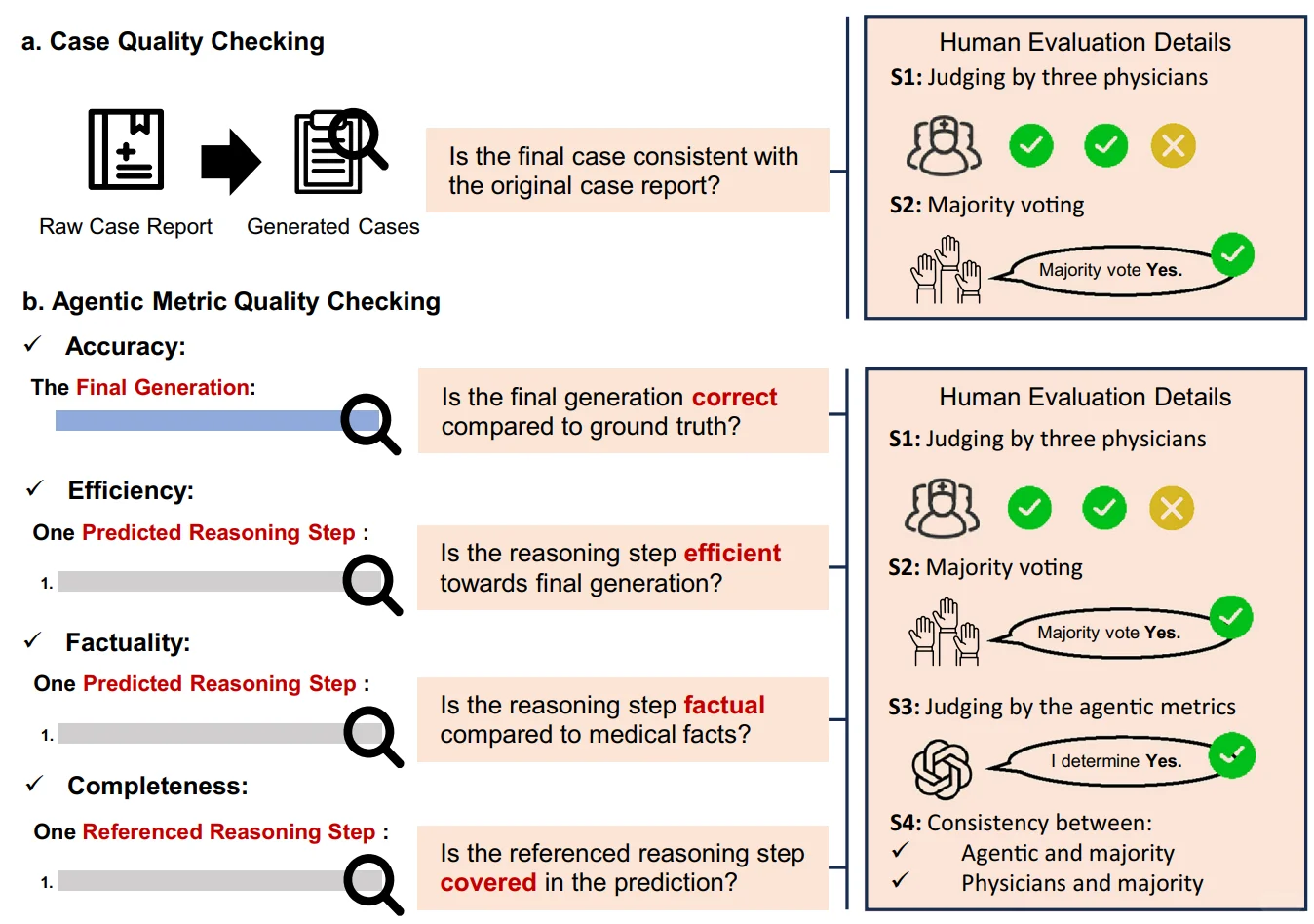
P4:人工验证机制 | 医学专家多轮标注验证评测数据质量与Reasoning Evaluator临床一致性
#人工智能 #医疗健康 #科研突破 #大语言模型 #临床决策 #Nature 子刊
? 为什么医学是评测AI推理的完美场景?
(1) 有标准答案:临床指南与病例报告为“正确推理”提供了金标准
(2) 有真实案例:病例报告完整记录了症状、检查、鉴别诊断与治疗规划的逻辑链
(3) 有刚性需求:临床决策容不得幻觉推理,每一步都必须可解释、可验证
? 我们的核心贡献
基于上述洞察,我们构建了:
1️⃣ MedRBench 评测基准:从真实病例报告中提炼构建,涵盖1,453个结构化病例,覆盖13个人体系统与10大专科。其核心价值在于,不仅提供问题与答案,更提供了由医生验证过的临床决策推理过程作为评估的黄金标准。
2️⃣ Reasoning Evaluator 智能评测系统:该系统能自动搜索网络医学资源,从效率、事实准确性与完整性三个维度,将模型的“推理过程”与专业的“金标准”进行比对量化,实现可靠、可扩展的自动评估。
? 主要发现:
诊断能力:信息充足时准确率>85%,信息有限时骤降至65-75%
推理质量:事实准确性>90%,但完整性仅70-80%,关键步骤大量缺失
治疗规划:准确率仅约30%,远未达到临床可用标准
? 相关资源:
GitHub项目:https://github.com/MAGIC-AI4Med/MedRBench/tree/main
Paper:https://www.nature.com/articles/s41467-025-64769-1
P1:临床评估框架 | 模拟从检查推荐到治疗规划的完整诊疗路径及量化指标
P2:模型性能对比 | 七大主流LLM在诊断、检查、治疗三大任务中的评测结果
P3:推理评估机制 | Reasoning Evaluator系统数据构建和多维度量化评估流程
P4:人工验证机制 | 医学专家多轮标注验证评测数据质量与Reasoning Evaluator临床一致性
#人工智能 #医疗健康 #科研突破 #大语言模型 #临床决策 #Nature 子刊