



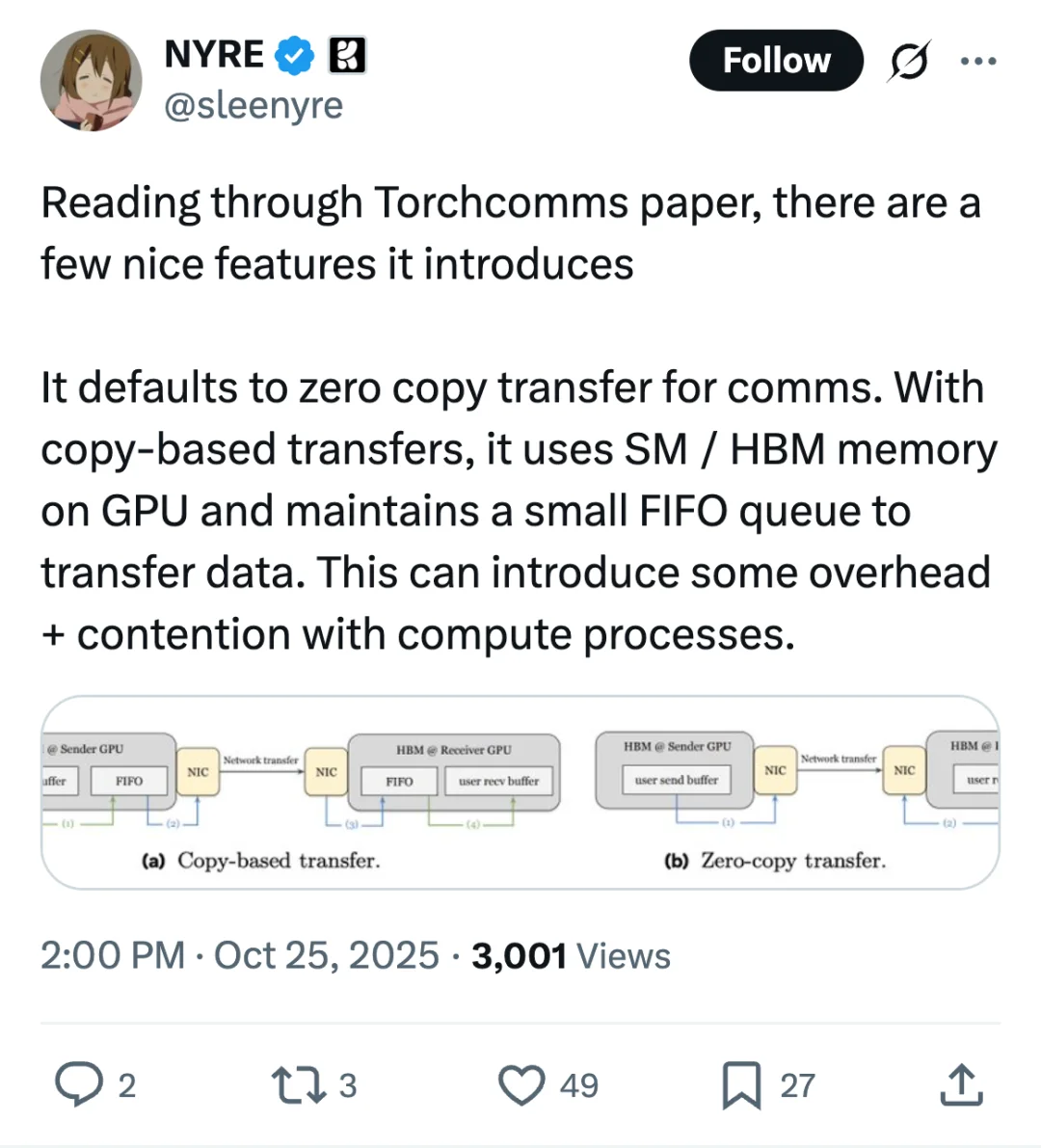
еҲҡзңӢе®ҢTorchcommsи®әж–ҮпјҢеҸ‘зҺ°дәҶдёӘжҢәжңүж„ҸжҖқзҡ„жҖ§иғҪдјҳеҢ–зӮ№гҖӮ
дј з»ҹGPUйҖҡдҝЎз”Ёзҡ„жҳҜеӨҚеҲ¶жЁЎејҸпјҢж•°жҚ®иҰҒе…Ҳз»ҸиҝҮSMжҲ–HBMеҶ…еӯҳпјҢиҝҳеҫ—з»ҙжҠӨFIFOйҳҹеҲ—жҺ’йҳҹпјҢиҝҷе°ұеғҸеҝ«йҖ’з«ҷиҪ¬иҝҗдёҖж ·пјҢеӨҡдәҶдёҖйҒ“жүӢз»ӯиҮӘ然е°ұж…ўдәҶгҖӮиҖҢдё”иҝҷдёӘйҳҹеҲ—иҝҳдјҡе’Ңи®Ўз®—иҝӣзЁӢжҠўиө„жәҗпјҢе®№жҳ“дә§з”ҹжҖ§иғҪ瓶йўҲгҖӮ
TorchcommsзӣҙжҺҘй»ҳи®Өз”Ёйӣ¶жӢ·иҙқдј иҫ“пјҢзӣёеҪ“дәҺж•°жҚ®дёҚз”ЁдёӯиҪ¬зӣҙжҺҘйҖҒиҫҫпјҢзңҒеҺ»дәҶйӮЈеұӮејҖй”Җе’Ңиө„жәҗдәүжҠўгҖӮеҜ№еҒҡеҲҶеёғејҸи®ӯз»ғжҲ–еӨ§и§„жЁЎжҺЁзҗҶзҡ„еҗҢеӯҰжқҘиҜҙпјҢиҝҷдёӘдјҳеҢ–жҖқи·ҜеҖјеҫ—е…іжіЁгҖӮ
и®әж–ҮйҮҢз»ҷзҡ„еҜ№жҜ”еӣҫеҫҲжё…жҘҡпјҢе·Ұиҫ№жҳҜдј з»ҹеӨҚеҲ¶жЁЎејҸзҡ„еӨҡжӯҘйӘӨжөҒзЁӢпјҢеҸіиҫ№жҳҜйӣ¶жӢ·иҙқзҡ„з®ҖеҢ–и·Ҝеҫ„гҖӮеҰӮжһңдҪ зҡ„и®ӯз»ғд»»еҠЎз»ҸеёёеҚЎеңЁйҖҡдҝЎдёҠпјҢеҸҜиғҪе°ұжҳҜиҝҷдёӘеҺҹеӣ гҖӮ
#GPUдјҳеҢ– #ж·ұеәҰеӯҰд№ #еҲҶеёғејҸи®ӯз»ғ #жҖ§иғҪи°ғдјҳ #жҠҖжңҜе№Іиҙ§ #AIи®ӯз»ғ #Torchcomms
дј з»ҹGPUйҖҡдҝЎз”Ёзҡ„жҳҜеӨҚеҲ¶жЁЎејҸпјҢж•°жҚ®иҰҒе…Ҳз»ҸиҝҮSMжҲ–HBMеҶ…еӯҳпјҢиҝҳеҫ—з»ҙжҠӨFIFOйҳҹеҲ—жҺ’йҳҹпјҢиҝҷе°ұеғҸеҝ«йҖ’з«ҷиҪ¬иҝҗдёҖж ·пјҢеӨҡдәҶдёҖйҒ“жүӢз»ӯиҮӘ然е°ұж…ўдәҶгҖӮиҖҢдё”иҝҷдёӘйҳҹеҲ—иҝҳдјҡе’Ңи®Ўз®—иҝӣзЁӢжҠўиө„жәҗпјҢе®№жҳ“дә§з”ҹжҖ§иғҪ瓶йўҲгҖӮ
TorchcommsзӣҙжҺҘй»ҳи®Өз”Ёйӣ¶жӢ·иҙқдј иҫ“пјҢзӣёеҪ“дәҺж•°жҚ®дёҚз”ЁдёӯиҪ¬зӣҙжҺҘйҖҒиҫҫпјҢзңҒеҺ»дәҶйӮЈеұӮејҖй”Җе’Ңиө„жәҗдәүжҠўгҖӮеҜ№еҒҡеҲҶеёғејҸи®ӯз»ғжҲ–еӨ§и§„жЁЎжҺЁзҗҶзҡ„еҗҢеӯҰжқҘиҜҙпјҢиҝҷдёӘдјҳеҢ–жҖқи·ҜеҖјеҫ—е…іжіЁгҖӮ
и®әж–ҮйҮҢз»ҷзҡ„еҜ№жҜ”еӣҫеҫҲжё…жҘҡпјҢе·Ұиҫ№жҳҜдј з»ҹеӨҚеҲ¶жЁЎејҸзҡ„еӨҡжӯҘйӘӨжөҒзЁӢпјҢеҸіиҫ№жҳҜйӣ¶жӢ·иҙқзҡ„з®ҖеҢ–и·Ҝеҫ„гҖӮеҰӮжһңдҪ зҡ„и®ӯз»ғд»»еҠЎз»ҸеёёеҚЎеңЁйҖҡдҝЎдёҠпјҢеҸҜиғҪе°ұжҳҜиҝҷдёӘеҺҹеӣ гҖӮ
#GPUдјҳеҢ– #ж·ұеәҰеӯҰд№ #еҲҶеёғејҸи®ӯз»ғ #жҖ§иғҪи°ғдјҳ #жҠҖжңҜе№Іиҙ§ #AIи®ӯз»ғ #Torchcomms