



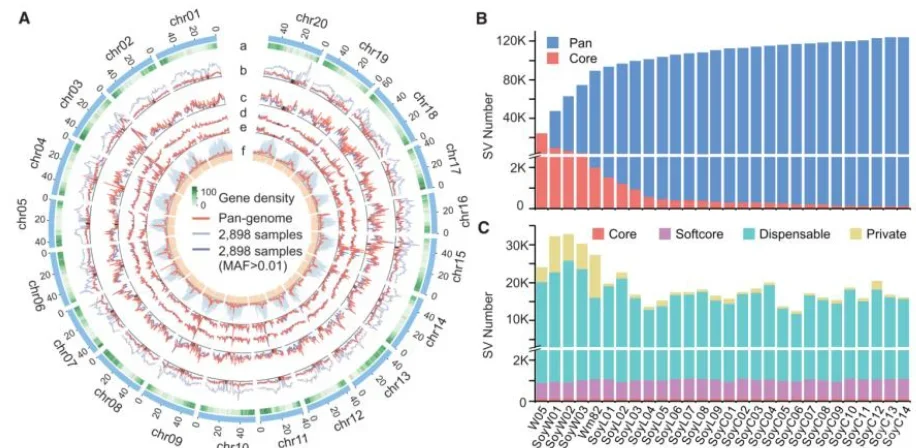
иҝӯд»Је’Ңз»„иЈ…зӯ–з•Ҙ
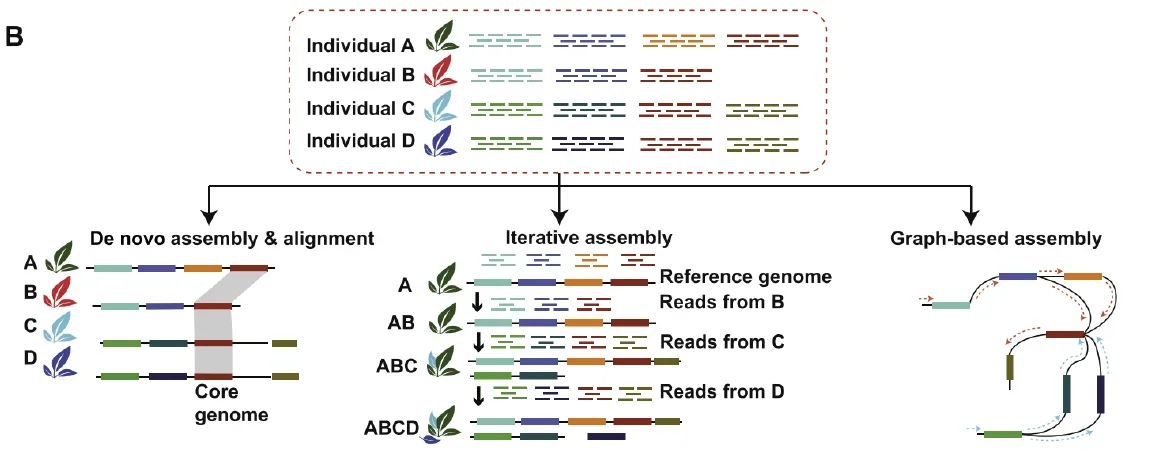
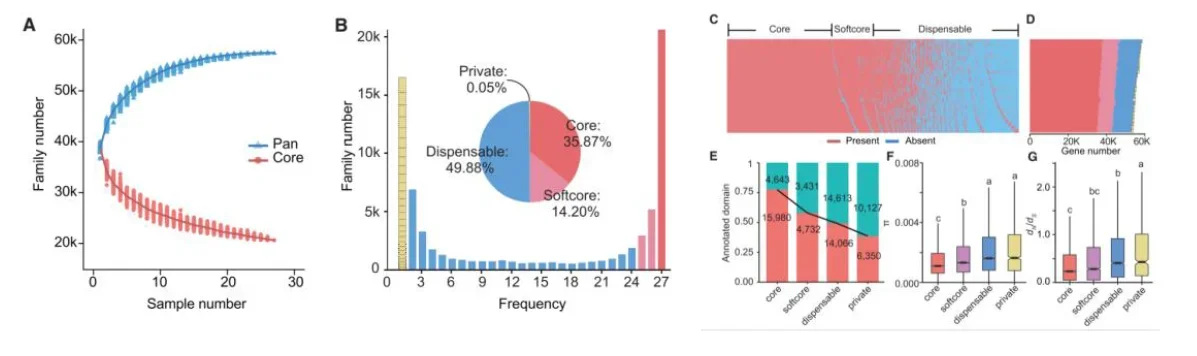
иҝӯд»Јз»„иЈ…жҳҜеҹәдәҺеҸӮиҖғеҹәеӣ з»„зҡ„жіӣеҹәеӣ з»„жһ„е»әж ёеҝғзӯ–з•Ҙд№ӢдёҖпјҢе…¶ж ёеҝғйҖ»иҫ‘жҳҜд»ҺеҲқе§ӢеҸӮиҖғеҹәеӣ з»„еҮәеҸ‘пјҢеҜ№ж ·жң¬иҝӣиЎҢйҖҗдёӘиҝӯд»ЈеӨ„зҗҶпјҡе…Ҳе°ҶеҚ•дёӘж ·жң¬зҡ„жөӢеәҸж•°жҚ®жҜ”еҜ№еҲ°еҪ“еүҚеҸӮиҖғеҹәеӣ з»„пјҢжҸҗеҸ–жңӘжҜ”еҜ№пјҲunmappedпјүзҡ„reads并组装дёәnovelпјҲж–°пјүеәҸеҲ—пјҢеҶҚе°ҶиҝҷдәӣnovelеәҸеҲ—дёҺеҪ“еүҚеҸӮиҖғеҹәеӣ з»„еҗҲ并жӣҙж–°пјҢеҪўжҲҗж–°зҡ„еҸӮиҖғеҹәеӣ з»„пјӣйҡҸеҗҺз”Ёжӣҙж–°еҗҺзҡ„еҸӮиҖғеҹәеӣ з»„еӨ„зҗҶдёӢдёҖдёӘж ·жң¬пјҢйҮҚеӨҚвҖңжҜ”еҜ№вҶ’жҸҗunmapped readsвҶ’з»„иЈ…вҶ’еҗҲ并жӣҙж–°еҸӮиҖғвҖқзҡ„жөҒзЁӢпјҢзӣҙиҮіжүҖжңүж ·жң¬еӨ„зҗҶе®ҢжҜ•пјҢжңҖз»Ҳеҫ—еҲ°еҢ…еҗ«зү©з§ҚжүҖжңүеҸҜеҸҳеәҸеҲ—зҡ„жіӣеҹәеӣ з»„гҖӮ
дјҳеҠҝ 1. йҖҗжӯҘз§ҜзҙҜnovelеәҸеҲ—пјҡжҜҸж¬Ўиҝӯд»Јд»…еӨ„зҗҶеҚ•дёӘж ·жң¬зҡ„unmapped readsпјҢз»„иЈ…йҡҫеәҰдҪҺпјҢnovelеәҸеҲ—зҡ„еҮҶзЎ®жҖ§жӣҙй«ҳгҖӮ 2. еҮҸе°‘еҶ—дҪҷи®Ўз®—пјҡжӣҙж–°еҗҺзҡ„еҸӮиҖғеҹәеӣ з»„еҢ…еҗ«еүҚеәҸж ·жң¬зҡ„зү№ејӮеәҸеҲ—пјҢеҗҺз»ӯж ·жң¬зҡ„жңӘжҜ”еҜ№readsд»…дёәиҮӘиә«зү№жңүеәҸеҲ—пјҢж— йңҖйҮҚеӨҚз»„иЈ…зӣёдјјеәҸеҲ—гҖӮ 3. йҖӮеә”жҖ§ејәпјҡйҖӮз”ЁдәҺеӨҡж ·жң¬гҖҒдёӯзӯүжөӢеәҸж·ұеәҰзҡ„ж•°жҚ®пјҲеҰӮ10-30Г—пјүпјҢе°Өе…¶йҖӮеҗҲзңҹиҸҢгҖҒжӨҚзү©зӯүеҹәеӣ з»„еӨҚжқӮеәҰйҖӮдёӯзҡ„зү©з§ҚпјҲж–ҮжЎЈдёӯд»Ҙй…өжҜҚдёәжөӢиҜ•ж•°жҚ®пјүгҖӮ 4. еҸҜиҝҪиёӘжҖ§пјҡжҜҸдёӘиҝӯд»ЈжӯҘйӘӨзҡ„novelеәҸеҲ—еҸҜйҖҡиҝҮIDж Үи®°пјҲеҰӮвҖңr1.вҖқвҖңr2.вҖқпјүпјҢдҫҝдәҺеҗҺз»ӯиҝҪжәҜеәҸеҲ—жқҘжәҗж ·жң¬гҖӮ
еә”з”Ё
в—Ұ зү©з§Қпјҡеҹәеӣ з»„еӨ§е°ҸйҖӮдёӯпјҲ100Mb-1Gbпјүзҡ„зү©з§ҚгҖӮ
в—Ұ ж•°жҚ®зұ»еһӢпјҡдәҢд»ЈжөӢеәҸпјҲIlluminaпјүзҡ„еҸҢз«ҜreadsпјҢеҚ•ж ·жң¬жөӢеәҸж·ұеәҰвүҘ10Г—пјҲдҝқиҜҒunmapped readsз»„иЈ…зҡ„иҰҶзӣ–еәҰпјүгҖӮ
в—Ұ з ”з©¶зӣ®ж ҮпјҡйңҖжһ„е»әй«ҳе®Ңж•ҙжҖ§жіӣеҹәеӣ з»„пјҢеҗҢж—¶еҢәеҲҶдёҚеҗҢж ·жң¬зү№ејӮеәҸеҲ—зҡ„з ”з©¶пјҲеҰӮз§ҚзҫӨж°ҙе№ізҡ„еҹәеӣ еҸҜеҸҳеҲҶжһҗпјүгҖӮ
#ж•°дҝЎйҷўз”ҹдҝЎжңҚеҠЎеҷЁ #з”ҹдҝЎ #з”ҹзү©дҝЎжҒҜеӯҰ #ж•°жҚ®еҲҶжһҗ #ж·ұеәҰеӯҰд№ #з”ҹзү©еҢ»еӯҰз§‘з ” #з”ҹдҝЎеҲҶжһҗ #з”ҹдҝЎжңҚеҠЎеҷЁ #з”ҹдҝЎе…Ҙй—Ё #еӣҫзүҮжқҘиҮӘдәҺзҪ‘з»ңдҫөжқғеҸҜеҲ
иҝӯд»Јз»„иЈ…жҳҜеҹәдәҺеҸӮиҖғеҹәеӣ з»„зҡ„жіӣеҹәеӣ з»„жһ„е»әж ёеҝғзӯ–з•Ҙд№ӢдёҖпјҢе…¶ж ёеҝғйҖ»иҫ‘жҳҜд»ҺеҲқе§ӢеҸӮиҖғеҹәеӣ з»„еҮәеҸ‘пјҢеҜ№ж ·жң¬иҝӣиЎҢйҖҗдёӘиҝӯд»ЈеӨ„зҗҶпјҡе…Ҳе°ҶеҚ•дёӘж ·жң¬зҡ„жөӢеәҸж•°жҚ®жҜ”еҜ№еҲ°еҪ“еүҚеҸӮиҖғеҹәеӣ з»„пјҢжҸҗеҸ–жңӘжҜ”еҜ№пјҲunmappedпјүзҡ„reads并组装дёәnovelпјҲж–°пјүеәҸеҲ—пјҢеҶҚе°ҶиҝҷдәӣnovelеәҸеҲ—дёҺеҪ“еүҚеҸӮиҖғеҹәеӣ з»„еҗҲ并жӣҙж–°пјҢеҪўжҲҗж–°зҡ„еҸӮиҖғеҹәеӣ з»„пјӣйҡҸеҗҺз”Ёжӣҙж–°еҗҺзҡ„еҸӮиҖғеҹәеӣ з»„еӨ„зҗҶдёӢдёҖдёӘж ·жң¬пјҢйҮҚеӨҚвҖңжҜ”еҜ№вҶ’жҸҗunmapped readsвҶ’з»„иЈ…вҶ’еҗҲ并жӣҙж–°еҸӮиҖғвҖқзҡ„жөҒзЁӢпјҢзӣҙиҮіжүҖжңүж ·жң¬еӨ„зҗҶе®ҢжҜ•пјҢжңҖз»Ҳеҫ—еҲ°еҢ…еҗ«зү©з§ҚжүҖжңүеҸҜеҸҳеәҸеҲ—зҡ„жіӣеҹәеӣ з»„гҖӮ
дјҳеҠҝ 1. йҖҗжӯҘз§ҜзҙҜnovelеәҸеҲ—пјҡжҜҸж¬Ўиҝӯд»Јд»…еӨ„зҗҶеҚ•дёӘж ·жң¬зҡ„unmapped readsпјҢз»„иЈ…йҡҫеәҰдҪҺпјҢnovelеәҸеҲ—зҡ„еҮҶзЎ®жҖ§жӣҙй«ҳгҖӮ 2. еҮҸе°‘еҶ—дҪҷи®Ўз®—пјҡжӣҙж–°еҗҺзҡ„еҸӮиҖғеҹәеӣ з»„еҢ…еҗ«еүҚеәҸж ·жң¬зҡ„зү№ејӮеәҸеҲ—пјҢеҗҺз»ӯж ·жң¬зҡ„жңӘжҜ”еҜ№readsд»…дёәиҮӘиә«зү№жңүеәҸеҲ—пјҢж— йңҖйҮҚеӨҚз»„иЈ…зӣёдјјеәҸеҲ—гҖӮ 3. йҖӮеә”жҖ§ејәпјҡйҖӮз”ЁдәҺеӨҡж ·жң¬гҖҒдёӯзӯүжөӢеәҸж·ұеәҰзҡ„ж•°жҚ®пјҲеҰӮ10-30Г—пјүпјҢе°Өе…¶йҖӮеҗҲзңҹиҸҢгҖҒжӨҚзү©зӯүеҹәеӣ з»„еӨҚжқӮеәҰйҖӮдёӯзҡ„зү©з§ҚпјҲж–ҮжЎЈдёӯд»Ҙй…өжҜҚдёәжөӢиҜ•ж•°жҚ®пјүгҖӮ 4. еҸҜиҝҪиёӘжҖ§пјҡжҜҸдёӘиҝӯд»ЈжӯҘйӘӨзҡ„novelеәҸеҲ—еҸҜйҖҡиҝҮIDж Үи®°пјҲеҰӮвҖңr1.вҖқвҖңr2.вҖқпјүпјҢдҫҝдәҺеҗҺз»ӯиҝҪжәҜеәҸеҲ—жқҘжәҗж ·жң¬гҖӮ
еә”з”Ё
в—Ұ зү©з§Қпјҡеҹәеӣ з»„еӨ§е°ҸйҖӮдёӯпјҲ100Mb-1Gbпјүзҡ„зү©з§ҚгҖӮ
в—Ұ ж•°жҚ®зұ»еһӢпјҡдәҢд»ЈжөӢеәҸпјҲIlluminaпјүзҡ„еҸҢз«ҜreadsпјҢеҚ•ж ·жң¬жөӢеәҸж·ұеәҰвүҘ10Г—пјҲдҝқиҜҒunmapped readsз»„иЈ…зҡ„иҰҶзӣ–еәҰпјүгҖӮ
в—Ұ з ”з©¶зӣ®ж ҮпјҡйңҖжһ„е»әй«ҳе®Ңж•ҙжҖ§жіӣеҹәеӣ з»„пјҢеҗҢж—¶еҢәеҲҶдёҚеҗҢж ·жң¬зү№ејӮеәҸеҲ—зҡ„з ”з©¶пјҲеҰӮз§ҚзҫӨж°ҙе№ізҡ„еҹәеӣ еҸҜеҸҳеҲҶжһҗпјүгҖӮ
#ж•°дҝЎйҷўз”ҹдҝЎжңҚеҠЎеҷЁ #з”ҹдҝЎ #з”ҹзү©дҝЎжҒҜеӯҰ #ж•°жҚ®еҲҶжһҗ #ж·ұеәҰеӯҰд№ #з”ҹзү©еҢ»еӯҰз§‘з ” #з”ҹдҝЎеҲҶжһҗ #з”ҹдҝЎжңҚеҠЎеҷЁ #з”ҹдҝЎе…Ҙй—Ё #еӣҫзүҮжқҘиҮӘдәҺзҪ‘з»ңдҫөжқғеҸҜеҲ