




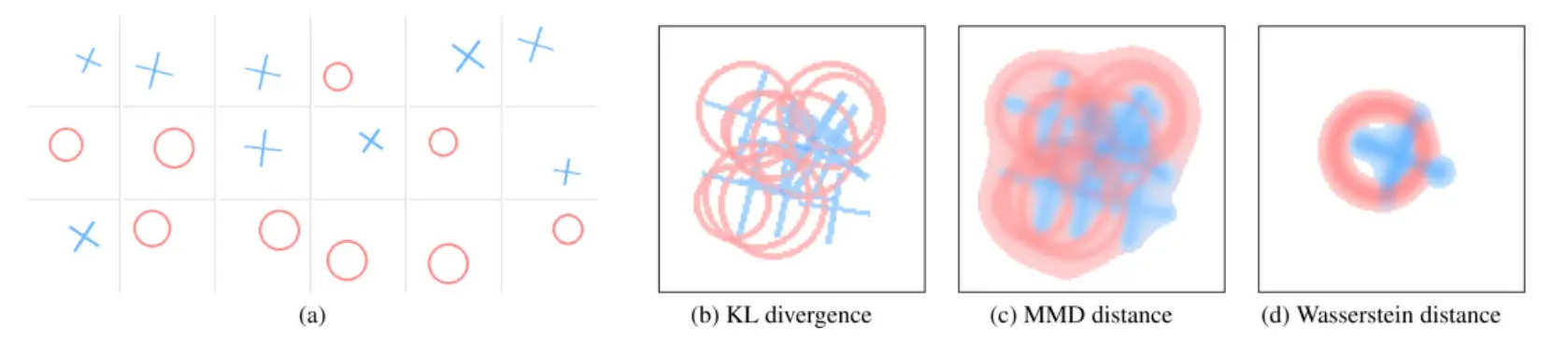
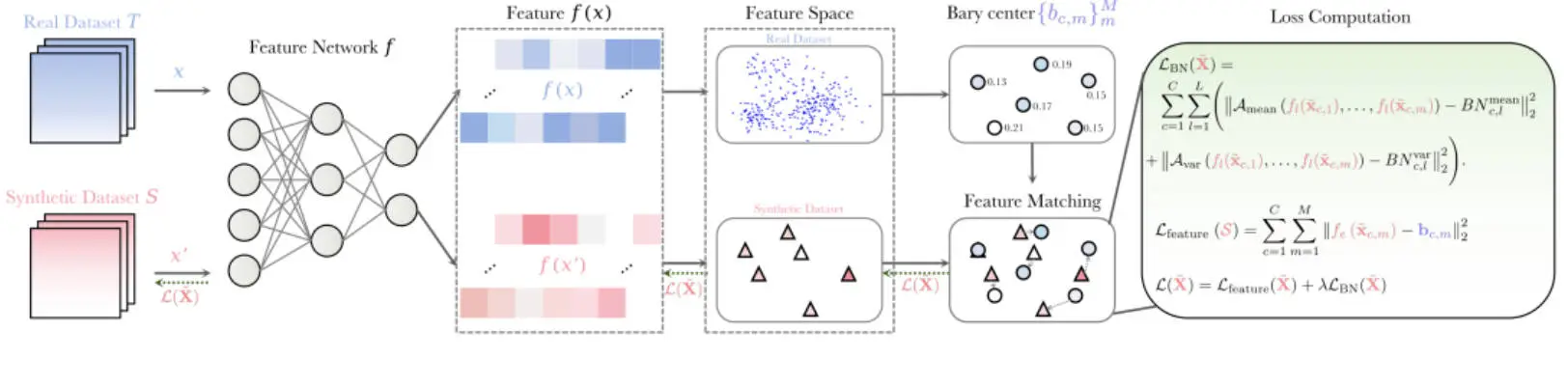
?гҖҗAIзӮјдё№ж–°жҖқи·ҜгҖ‘е‘ҠеҲ«жө·йҮҸж•°жҚ®пјҒWMDDз”ЁеҮ дҪ•еӯҰвҖңи’ёйҰҸвҖқж•°жҚ®йӣҶпјҢе°Ҹж ·жң¬и®ӯеҮәејәжЁЎеһӢпјҒ
? жҠҖжңҜж ёзҲҶзӮ№пјҡ
вң… WMDDпјҡйҰ–еҲӣеҹәдәҺWassersteinеәҰйҮҸзҡ„ж•°жҚ®йӣҶи’ёйҰҸпјҢз”ЁвҖңеҮ дҪ•йҮҚеҝғвҖқзІҫеҮҶдҝқз•ҷеҺҹе§Ӣж•°жҚ®еҲҶеёғзҡ„еҪўзҠ¶е’Ңз»“жһ„гҖӮ
вң… е°‘еҚіжҳҜеӨҡпјҡд»…йңҖжһҒе°‘йҮҸеҗҲжҲҗж ·жң¬пјҲеҰӮжҜҸзұ»10-100еј пјүпјҢеҚіеҸҜи®ӯз»ғеҮәжҖ§иғҪйҖјиҝ‘дҪҝз”Ёе…ЁйҮҸж•°жҚ®зҡ„жЁЎеһӢпјҢе®һзҺ°жһҒиҮҙвҖңйҷҚжң¬еўһж•ҲвҖқгҖӮ
вң… ж•ҲзҺҮдёҺзІҫеәҰе…јеҫ—пјҡеңЁй«ҳеҲҶиҫЁзҺҮеӣҫеғҸж•°жҚ®йӣҶпјҲеҰӮImageNetпјүдёҠе®һзҺ°SOTAжҲ–ејәз«һдәүеҠӣиғҪпјҢеҗҢж—¶и®Ўз®—ејҖй”ҖдёҺдё»жөҒй«ҳж•Ҳж–№жі•зӣёеҪ“гҖӮ
? йқ©е‘ҪжҖ§зӘҒз ҙпјҡ
1пёҸвғЈ еҮ дҪ•дҝқзңҹи’ёйҰҸпјҡйҰ–ж¬Ўе°ҶжңҖдјҳдј иҫ“пјҲOTпјүзҗҶи®әдёӯзҡ„Wassersteinи·қзҰ»еҸҠе…¶йҮҚеҝғжҰӮеҝөеј•е…Ҙж•°жҚ®йӣҶи’ёйҰҸпјҢд»Һж №жң¬дёҠи§ЈеҶідәҶдј з»ҹж–№жі•пјҲеҰӮMMDеқҮеҖјеҢ№й…Қпјүйҡҫд»Ҙдҝқз•ҷж•°жҚ®еҲҶеёғеҮ дҪ•з»“жһ„пјҲеҰӮеҪўзҠ¶гҖҒеӨҡж ·жҖ§пјүзҡ„з—ӣзӮ№пјҢи®©еҗҲжҲҗж•°жҚ®вҖңеҪўзҘһе…јеӨҮвҖқгҖӮ
2пёҸвғЈ зү№еҫҒз©әй—ҙзІҫеҮҶеҜ№йҪҗпјҡе·§еҰҷең°еңЁйў„и®ӯз»ғжЁЎеһӢзҡ„ж·ұеұӮзү№еҫҒз©әй—ҙиҝӣиЎҢеҲҶеёғеҜ№йҪҗпјҢиҖҢйқһеҺҹе§ӢеғҸзҙ з©әй—ҙпјҢиғҪжӣҙжңүж•Ҳең°жҚ•жҚүж•°жҚ®зҡ„ж ёеҝғиҜӯд№үиЎЁеҫҒпјҢ并еҖҹеҠ©йў„и®ӯз»ғжЁЎеһӢзҡ„ејәеӨ§е…ҲйӘҢзҹҘиҜҶгҖӮ
3пёҸвғЈ еҲӣж–°PCBNжӯЈеҲҷеҢ–пјҡжҸҗеҮәвҖңжҢүзұ»BatchNormз»ҹи®ЎвҖқпјҲPer-Class BNпјүзәҰжқҹпјҢеңЁдјҳеҢ–ж—¶зӢ¬з«ӢеҜ№йҪҗжҜҸдёӘзұ»еҲ«еңЁзҪ‘з»ңдёӯй—ҙеұӮзҡ„з»ҹи®ЎйҮҸпјҢжңүж•ҲйҒҝе…ҚдәҶдёҚеҗҢзұ»еҲ«й—ҙзҡ„жўҜеәҰе№Іжү°пјҢжӣҙеҘҪең°дҝқжҢҒдәҶзұ»еҶ…з»“жһ„е’ҢеӨҡж ·жҖ§гҖӮ
? е®һжөӢж•°жҚ®зӮёиЈӮпјҡ
жҖ§иғҪйҖјиҝ‘е…ЁйҮҸпјҡеңЁImageNet-1KдёҠпјҢд»…з”Ё100еј /зұ»пјҲIPC=100пјүеҗҲжҲҗеӣҫеғҸи®ӯз»ғResNet-18пјҢTop-1еҮҶзЎ®зҺҮиҫҫ60.7%пјҢе·ІйқһеёёжҺҘиҝ‘дҪҝз”Ё128дёҮеј зңҹе®һеӣҫеғҸи®ӯз»ғзҡ„63.1%гҖӮеңЁTiny-ImageNetзӯүж•°жҚ®йӣҶдёҠиЎЁзҺ°еҗҢж ·дјҳејӮгҖӮ
и·Ёжһ¶жһ„йӘҢиҜҒе®һеҠӣпјҡз”ЁResNet-18и’ёйҰҸзҡ„50 IPCж•°жҚ®пјҢи®ӯз»ғResNet-50/101иғҪжҢҒз»ӯеёҰжқҘжҖ§иғҪеўһзӣҠпјӣиҝҒ移еҲ°ViT-Tiny/Smallжһ¶жһ„дёҠд№ҹжңүеҸҜи§ӮиЎЁзҺ°гҖӮ
ж•ҲзҺҮеҸҜи§ӮпјҡеҸ—зӣҠдәҺй«ҳж•Ҳзҡ„жңҖдјҳдј иҫ“жұӮи§Јз®—жі•пјҢе…¶и®ӯз»ғж—¶й—ҙе’ҢжҳҫеӯҳејҖй”ҖдёҺеҪ“еүҚжңҖй«ҳж•Ҳзҡ„еҲҶеёғеҢ№й…Қж–№жі•пјҲеҰӮеҸӘеҢ№й…ҚеқҮеҖјпјүеӨ„дәҺеҗҢдёҖж•°йҮҸзә§пјҢдҪҶжҖ§иғҪйҖҡеёёжӣҙдјҳгҖӮ
ж¶ҲиһҚе®һйӘҢиҜҒе®һпјҡWassersteinйҮҚеҝғеҢ№й…ҚзӣёжҜ”дј з»ҹдәӨеҸүзҶөжҚҹеӨұгҖҒPCBNжӯЈеҲҷзӣёжҜ”е…ЁеұҖBNжӯЈеҲҷпјҢеқҮеёҰжқҘдәҶзЁіе®ҡдё”жҳҫи‘—зҡ„жҖ§иғҪжҸҗеҚҮгҖӮ
и®әж–Үй“ҫжҺҘ: https://arxiv.org/abs/2311.18531
д»Јз Ғй“ҫжҺҘ: https://github.com/Liu-Hy/WMDD
?#ж•°жҚ®йӣҶи’ёйҰҸ #дәәе·ҘжҷәиғҪ #жңәеҷЁеӯҰд№ #ICCV #йҮҸеӯҗжҷәеҝғ
жң¬ж–Үз”ұAIиҫ…еҠ©з”ҹжҲҗ
? жҠҖжңҜж ёзҲҶзӮ№пјҡ
вң… WMDDпјҡйҰ–еҲӣеҹәдәҺWassersteinеәҰйҮҸзҡ„ж•°жҚ®йӣҶи’ёйҰҸпјҢз”ЁвҖңеҮ дҪ•йҮҚеҝғвҖқзІҫеҮҶдҝқз•ҷеҺҹе§Ӣж•°жҚ®еҲҶеёғзҡ„еҪўзҠ¶е’Ңз»“жһ„гҖӮ
вң… е°‘еҚіжҳҜеӨҡпјҡд»…йңҖжһҒе°‘йҮҸеҗҲжҲҗж ·жң¬пјҲеҰӮжҜҸзұ»10-100еј пјүпјҢеҚіеҸҜи®ӯз»ғеҮәжҖ§иғҪйҖјиҝ‘дҪҝз”Ёе…ЁйҮҸж•°жҚ®зҡ„жЁЎеһӢпјҢе®һзҺ°жһҒиҮҙвҖңйҷҚжң¬еўһж•ҲвҖқгҖӮ
вң… ж•ҲзҺҮдёҺзІҫеәҰе…јеҫ—пјҡеңЁй«ҳеҲҶиҫЁзҺҮеӣҫеғҸж•°жҚ®йӣҶпјҲеҰӮImageNetпјүдёҠе®һзҺ°SOTAжҲ–ејәз«һдәүеҠӣиғҪпјҢеҗҢж—¶и®Ўз®—ејҖй”ҖдёҺдё»жөҒй«ҳж•Ҳж–№жі•зӣёеҪ“гҖӮ
? йқ©е‘ҪжҖ§зӘҒз ҙпјҡ
1пёҸвғЈ еҮ дҪ•дҝқзңҹи’ёйҰҸпјҡйҰ–ж¬Ўе°ҶжңҖдјҳдј иҫ“пјҲOTпјүзҗҶи®әдёӯзҡ„Wassersteinи·қзҰ»еҸҠе…¶йҮҚеҝғжҰӮеҝөеј•е…Ҙж•°жҚ®йӣҶи’ёйҰҸпјҢд»Һж №жң¬дёҠи§ЈеҶідәҶдј з»ҹж–№жі•пјҲеҰӮMMDеқҮеҖјеҢ№й…Қпјүйҡҫд»Ҙдҝқз•ҷж•°жҚ®еҲҶеёғеҮ дҪ•з»“жһ„пјҲеҰӮеҪўзҠ¶гҖҒеӨҡж ·жҖ§пјүзҡ„з—ӣзӮ№пјҢи®©еҗҲжҲҗж•°жҚ®вҖңеҪўзҘһе…јеӨҮвҖқгҖӮ
2пёҸвғЈ зү№еҫҒз©әй—ҙзІҫеҮҶеҜ№йҪҗпјҡе·§еҰҷең°еңЁйў„и®ӯз»ғжЁЎеһӢзҡ„ж·ұеұӮзү№еҫҒз©әй—ҙиҝӣиЎҢеҲҶеёғеҜ№йҪҗпјҢиҖҢйқһеҺҹе§ӢеғҸзҙ з©әй—ҙпјҢиғҪжӣҙжңүж•Ҳең°жҚ•жҚүж•°жҚ®зҡ„ж ёеҝғиҜӯд№үиЎЁеҫҒпјҢ并еҖҹеҠ©йў„и®ӯз»ғжЁЎеһӢзҡ„ејәеӨ§е…ҲйӘҢзҹҘиҜҶгҖӮ
3пёҸвғЈ еҲӣж–°PCBNжӯЈеҲҷеҢ–пјҡжҸҗеҮәвҖңжҢүзұ»BatchNormз»ҹи®ЎвҖқпјҲPer-Class BNпјүзәҰжқҹпјҢеңЁдјҳеҢ–ж—¶зӢ¬з«ӢеҜ№йҪҗжҜҸдёӘзұ»еҲ«еңЁзҪ‘з»ңдёӯй—ҙеұӮзҡ„з»ҹи®ЎйҮҸпјҢжңүж•ҲйҒҝе…ҚдәҶдёҚеҗҢзұ»еҲ«й—ҙзҡ„жўҜеәҰе№Іжү°пјҢжӣҙеҘҪең°дҝқжҢҒдәҶзұ»еҶ…з»“жһ„е’ҢеӨҡж ·жҖ§гҖӮ
? е®һжөӢж•°жҚ®зӮёиЈӮпјҡ
жҖ§иғҪйҖјиҝ‘е…ЁйҮҸпјҡеңЁImageNet-1KдёҠпјҢд»…з”Ё100еј /зұ»пјҲIPC=100пјүеҗҲжҲҗеӣҫеғҸи®ӯз»ғResNet-18пјҢTop-1еҮҶзЎ®зҺҮиҫҫ60.7%пјҢе·ІйқһеёёжҺҘиҝ‘дҪҝз”Ё128дёҮеј зңҹе®һеӣҫеғҸи®ӯз»ғзҡ„63.1%гҖӮеңЁTiny-ImageNetзӯүж•°жҚ®йӣҶдёҠиЎЁзҺ°еҗҢж ·дјҳејӮгҖӮ
и·Ёжһ¶жһ„йӘҢиҜҒе®һеҠӣпјҡз”ЁResNet-18и’ёйҰҸзҡ„50 IPCж•°жҚ®пјҢи®ӯз»ғResNet-50/101иғҪжҢҒз»ӯеёҰжқҘжҖ§иғҪеўһзӣҠпјӣиҝҒ移еҲ°ViT-Tiny/Smallжһ¶жһ„дёҠд№ҹжңүеҸҜи§ӮиЎЁзҺ°гҖӮ
ж•ҲзҺҮеҸҜи§ӮпјҡеҸ—зӣҠдәҺй«ҳж•Ҳзҡ„жңҖдјҳдј иҫ“жұӮи§Јз®—жі•пјҢе…¶и®ӯз»ғж—¶й—ҙе’ҢжҳҫеӯҳејҖй”ҖдёҺеҪ“еүҚжңҖй«ҳж•Ҳзҡ„еҲҶеёғеҢ№й…Қж–№жі•пјҲеҰӮеҸӘеҢ№й…ҚеқҮеҖјпјүеӨ„дәҺеҗҢдёҖж•°йҮҸзә§пјҢдҪҶжҖ§иғҪйҖҡеёёжӣҙдјҳгҖӮ
ж¶ҲиһҚе®һйӘҢиҜҒе®һпјҡWassersteinйҮҚеҝғеҢ№й…ҚзӣёжҜ”дј з»ҹдәӨеҸүзҶөжҚҹеӨұгҖҒPCBNжӯЈеҲҷзӣёжҜ”е…ЁеұҖBNжӯЈеҲҷпјҢеқҮеёҰжқҘдәҶзЁіе®ҡдё”жҳҫи‘—зҡ„жҖ§иғҪжҸҗеҚҮгҖӮ
и®әж–Үй“ҫжҺҘ: https://arxiv.org/abs/2311.18531
д»Јз Ғй“ҫжҺҘ: https://github.com/Liu-Hy/WMDD
?#ж•°жҚ®йӣҶи’ёйҰҸ #дәәе·ҘжҷәиғҪ #жңәеҷЁеӯҰд№ #ICCV #йҮҸеӯҗжҷәеҝғ
жң¬ж–Үз”ұAIиҫ…еҠ©з”ҹжҲҗ