






标题
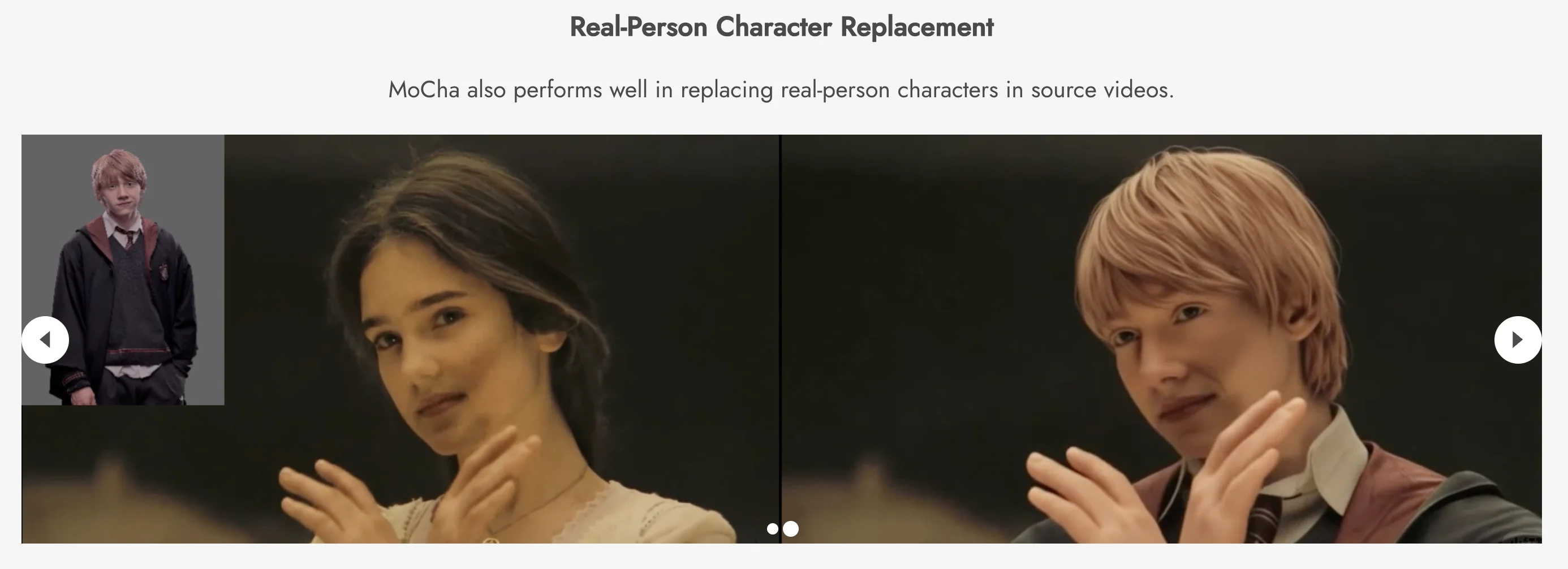
由于缺乏合格的配对视频数据,使用用户提供的视频角色进行可控替换仍然是一个难题。先前的研究主要采用基于重建的范式,依赖于每帧掩码和明确的结构引导(例如,姿势、深度)。然而,这种依赖性使得它们在遮挡、罕见姿势、角色-物体交互或复杂光照等复杂场景下显得脆弱,常常导致视觉伪影和时间不连续性。本文提出了一个突破这些限制的全新框架 MoCha,它只需要一个首帧掩码,并通过将不同条件统一到单个标记流中来重新渲染角色。此外,MoCha 采用条件感知的 RoPE 来支持多参考图像和可变长度视频生成。为了克服数据瓶颈,我们构建了一个全面的数据合成流程来收集合格的配对训练视频。大量实验表明,我们的方法显著优于现有的最佳方法。
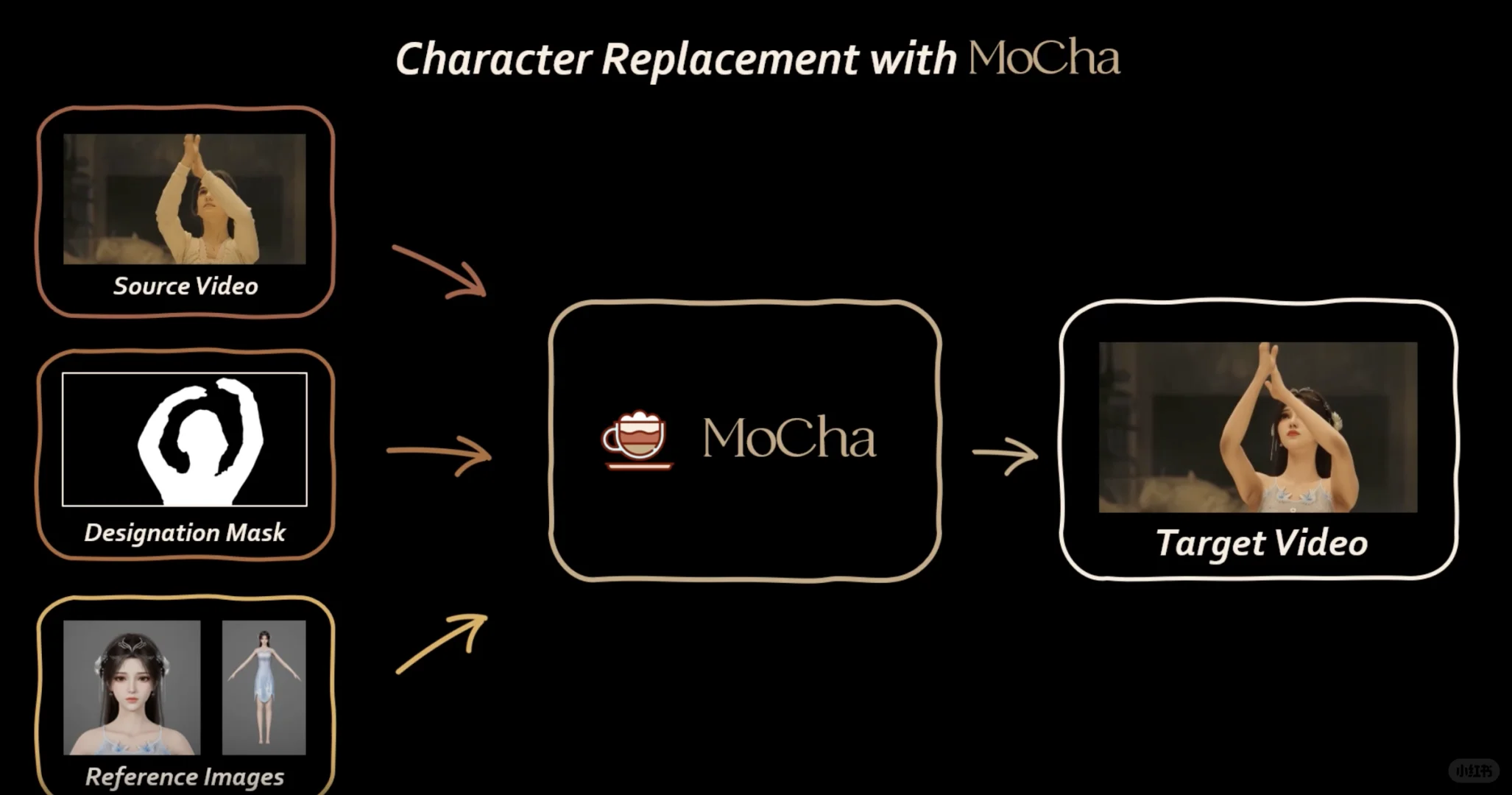
要使用 MoCha 开始您自己的角色替换,需要以下三个输入:
· 源视频:包含待替换角色的原始视频。
· 首帧指定蒙版:在源视频首帧中标记待替换源角色的蒙版。
· 参考图像:用于替换的新角色的参考图像,背景清晰。我们建议您上传至少一张高质量的正面面部特写照片。
代码已经开源在Orange-3DV-Team/MoCha
由于缺乏合格的配对视频数据,使用用户提供的视频角色进行可控替换仍然是一个难题。先前的研究主要采用基于重建的范式,依赖于每帧掩码和明确的结构引导(例如,姿势、深度)。然而,这种依赖性使得它们在遮挡、罕见姿势、角色-物体交互或复杂光照等复杂场景下显得脆弱,常常导致视觉伪影和时间不连续性。本文提出了一个突破这些限制的全新框架 MoCha,它只需要一个首帧掩码,并通过将不同条件统一到单个标记流中来重新渲染角色。此外,MoCha 采用条件感知的 RoPE 来支持多参考图像和可变长度视频生成。为了克服数据瓶颈,我们构建了一个全面的数据合成流程来收集合格的配对训练视频。大量实验表明,我们的方法显著优于现有的最佳方法。
要使用 MoCha 开始您自己的角色替换,需要以下三个输入:
· 源视频:包含待替换角色的原始视频。
· 首帧指定蒙版:在源视频首帧中标记待替换源角色的蒙版。
· 参考图像:用于替换的新角色的参考图像,背景清晰。我们建议您上传至少一张高质量的正面面部特写照片。
代码已经开源在Orange-3DV-Team/MoCha