



MetaеңЁе…¶ж–°и®әж–ҮContinual Learning via Sparse Memory Finetuningдёӯеұ•зӨәдәҶеҰӮдҪ•еҜ№и®°еҝҶеұӮиҝӣиЎҢзЁҖз–Ҹеҫ®и°ғпјҢд»ҺиҖҢиғҪеӨҹй’ҲеҜ№дёҚж–ӯеӯҰд№ иҝӣиЎҢжңүй’ҲеҜ№жҖ§зҡ„жӣҙж–°пјҢеҗҢж—¶еҜ№зҺ°жңүзҹҘиҜҶзҡ„еҪұе“ҚжһҒе°ҸгҖӮ
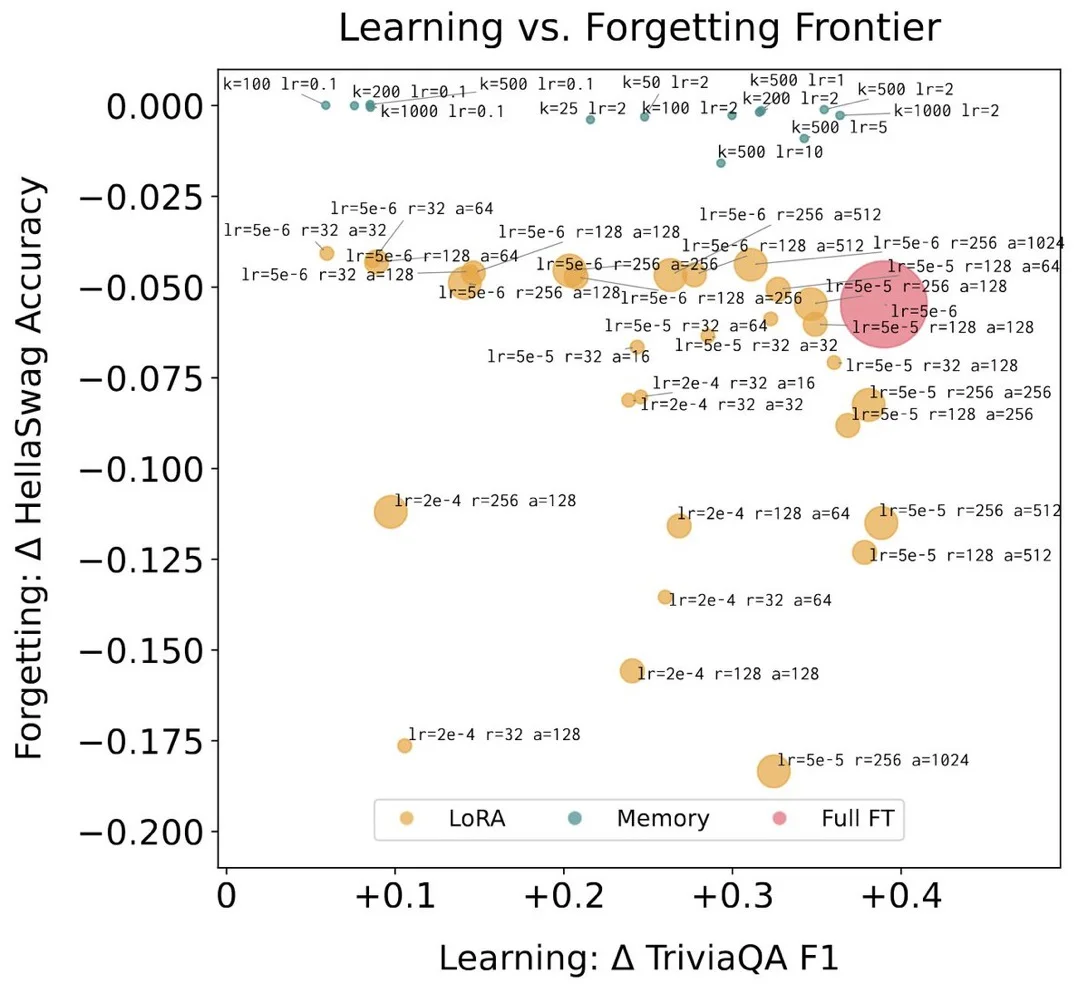
иҷҪ然全йқўеҫ®и°ғе’Ң LoRA еңЁжөӢиҜ•д»»еҠЎдёӯзҡ„иЎЁзҺ°еӨ§е№…дёӢйҷҚпјҲдәӢе®һеӯҰд№ д»»еҠЎж–№йқўпјҡеҫ®и°ғ -89%пјҢLoRA -71%пјүпјҢдҪҶи®°еҝҶеұӮзҡ„еӯҰд№ ж•ҲжһңеҚҙдҝқжҢҒдёҚеҸҳпјҢдё”йҒ—еҝҳзЁӢеәҰеӨ§е№…йҷҚдҪҺпјҲ-11%пјүгҖӮ
з ”з©¶иғҢжҷҜпјҡиҰҒеӯҰд№ ж–°зҹҘиҜҶпјҢжҲ‘д»¬ж— йңҖеҜ№еӨ§еһӢжЁЎеһӢзҡ„жүҖжңүеҸӮж•°иҝӣиЎҢзІҫз»Ҷи°ғж•ҙгҖӮиҝҷдҝғдҪҝеҮәзҺ°дәҶеҸӮж•°ж•ҲзҺҮй«ҳзҡ„жҢҒз»ӯеӯҰд№ /и®°еҝҶж–№жі•пјҢжҜ”еҰӮ LoRA е’Ң CartridgesпјҢе®ғ们дјҡеңЁжЁЎеһӢдёӯж·»еҠ дёҖе°ҸйғЁеҲҶеҸӮж•°гҖӮ然иҖҢпјҢLoRA зҡ„е®№йҮҸеӨ©з”ҹе°ұиҫғе°ҸвҖ”вҖ”дёҖдёӘе°ҸеһӢзҡ„йҖӮй…ҚеҷЁж— жі•йҖӮз”ЁдәҺй•ҝжңҹеӯҰд№ зҡ„йңҖжұӮгҖӮ
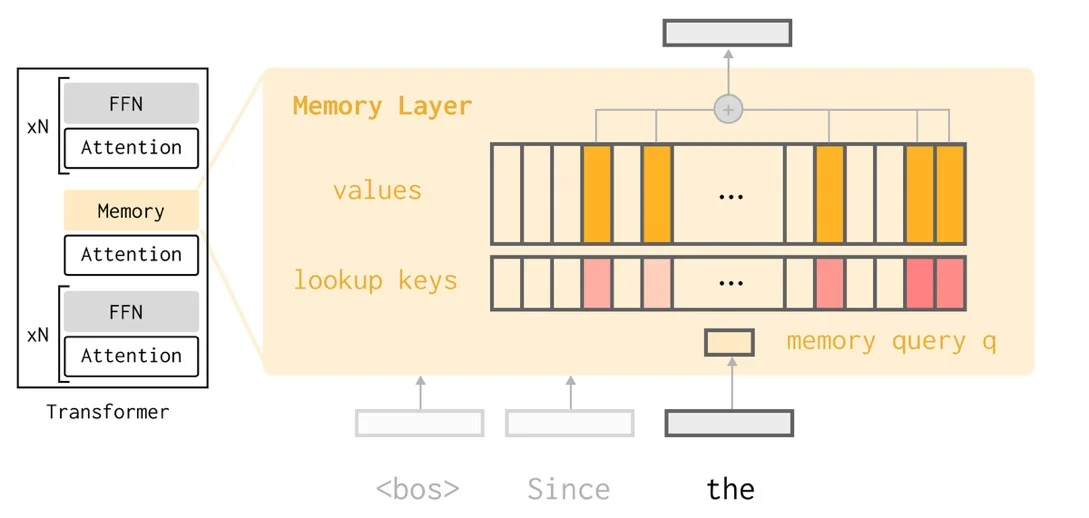
P2пјҡеңЁжң¬ж–ҮдёӯпјҢдҪңиҖ…еұ•зӨәдәҶиҝ‘жңҹжҸҗеҮәзҡ„и®°еҝҶеұӮжһ¶жһ„еҰӮдҪ•жҸҗдҫӣдёҖз§ҚжҪңеңЁзҡ„и§ЈеҶіж–№жЎҲпјҡз”ЁдёҖдёӘзЁҖз–ҸжіЁж„ҸеҠӣжҹҘжүҫжңәеҲ¶жқҘжӣҝд»Је…ЁиҝһжҺҘзҘһз»ҸзҪ‘з»ңпјҲFFNпјүпјҢиҜҘжҹҘжүҫжңәеҲ¶дјҡд»ҺдёҖдёӘеәһеӨ§зҡ„е·ІеӯҰд№ зҡ„и®°еҝҶй”®еҖјжұ дёӯиҝӣиЎҢжҹҘжүҫгҖӮиҝҷдёӘжһ¶жһ„иғҪеӨҹеҜ№жҜҸдёӘиҫ“е…ҘйЎ№жүҖжӣҙж–°зҡ„еҸӮж•°иҝӣиЎҢзІҫз»ҶжҺ§еҲ¶гҖӮ
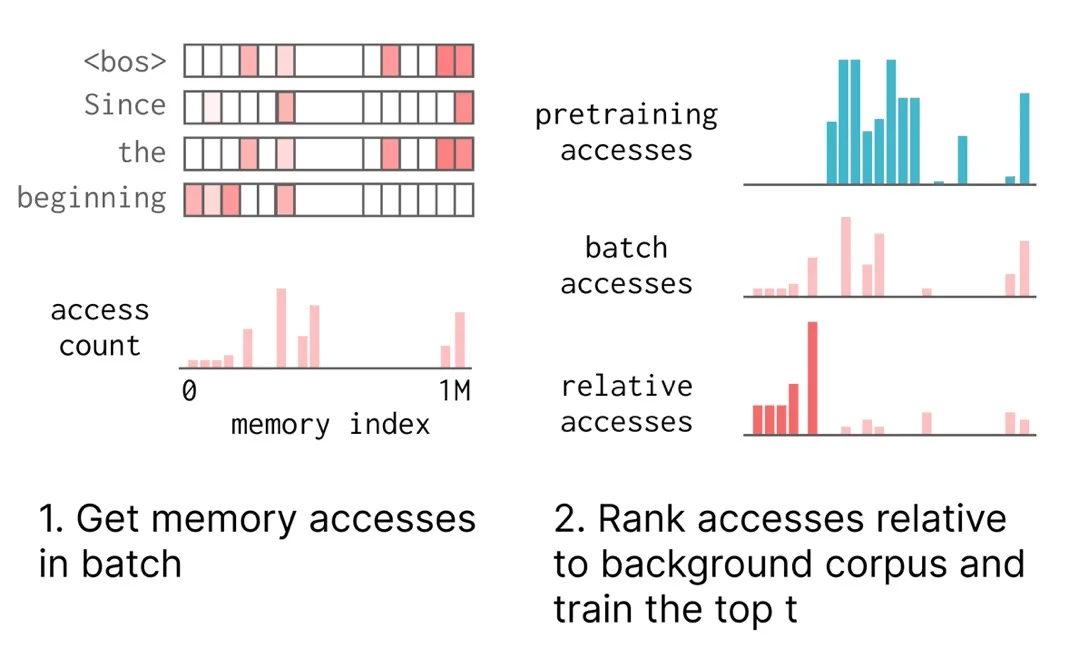
P3: еҲ©з”Ёиҝҷз§ҚзЁҖз–ҸжҖ§пјҢдҪңиҖ…жҸҗи®®д»…жӣҙж–°йӮЈдәӣзү№е®ҡдәҺжҹҗдёҖзү№е®ҡиҫ“е…Ҙзҡ„еҶ…еӯҳж§ҪдҪҚвҖ”вҖ”иҝҷдәӣж§ҪдҪҚеңЁиҜҘиҫ“е…ҘдёҠиў«йў‘з№Ғи®ҝй—®пјҢдҪҶеңЁе…¶д»–ж•°жҚ®пјҲдҫӢеҰӮйў„и®ӯз»ғж•°жҚ®пјүдёҠи®ҝй—®йў‘зҺҮиҫғдҪҺпјҢ并且еҲ©з”Ё TFIDF еҜ№иҝҷдәӣж§ҪдҪҚиҝӣиЎҢжҺ’еәҸгҖӮиҝҷе®һзҺ°дәҶи®°еҝҶзҡ„йҖүжӢ©жҖ§гҖӮеҪ“дәҶи§ЈеҲ°жңүе…іиҙқжӢүе…ӢВ·еҘҘе·ҙ马зҡ„ж–°дҝЎжҒҜж—¶пјҢжҲ‘们еҸӘйңҖиҰҒеҫ®и°ғйӮЈдәӣвҖңеӯҳеӮЁвҖқиҜҘдҝЎжҒҜзҡ„ж§ҪдҪҚпјҢиҖҢж— йңҖи§ҰеҸҠйӮЈдәӣиҙҹиҙЈдҫӢеҰӮдәҶи§ЈеҰӮдҪ•зј–зЁӢзӯүеҠҹиғҪзҡ„еҸӮж•°гҖӮ
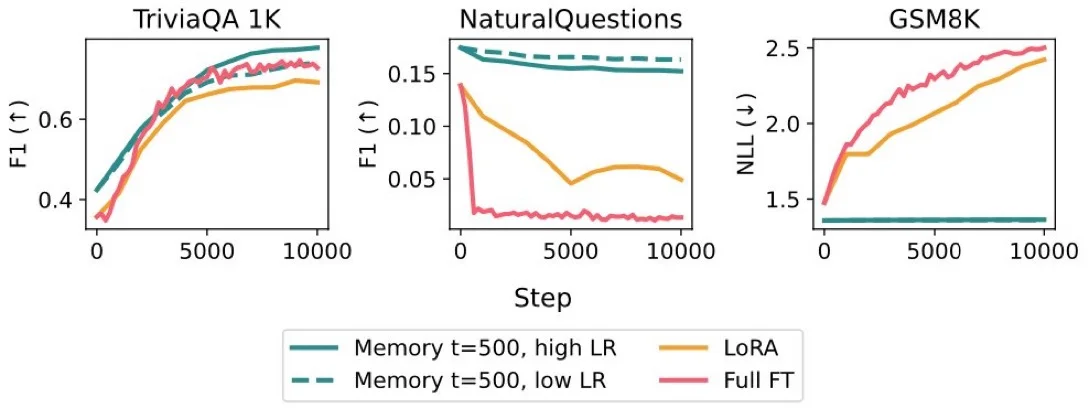
P4пјҡдҪңиҖ…й’ҲеҜ№дёӨдёӘжҢҒз»ӯжҖ§зҡ„дәӢе®һеӯҰд№ д»»еҠЎиҝӣиЎҢдәҶиҜ„дј°пјҡд»ҺдёҖзі»еҲ—вҖңTriviaQAвҖқдәӢе®һж•°жҚ®дёӯиҝӣиЎҢеӯҰд№ пјҢд»ҘеҸҠд»ҺвҖңSimpleQAвҖқдёӯзҡ„дёҖзі»еҲ—з»ҙеҹәзҷҫ科ж–ҮжЎЈдёӯиҝӣиЎҢеӯҰд№ гҖӮзЁҖз–Ҹи®°еҝҶеҫ®и°ғзҡ„ж•ҲжһңдёҺе®Ңе…Ёеҫ®и°ғе’Ң LoRA дёҖж ·еҘҪпјҢдҪҶеңЁжңӘжөӢиҜ•д»»еҠЎдёӯзҡ„иЎЁзҺ°еҚҙиҰҒеҘҪеҫ—еӨҡпјҢиҖҢдё”иҝҳиғҪе®һзҺ°жңүйҖүжӢ©жҖ§зҡ„жӣҙж–°пјҢд»ҺиҖҢеҮҸе°‘дәҶжҖ§иғҪзҡ„дёӢйҷҚгҖӮ
?Paper: arxiv.org/abs/2510.15103
Blogпјҡhttps://jessylin.com/2025/10/20/continual-learning/
#еҚҡеЈ«з”ҹ #еӨ§жЁЎеһӢ #gpt #жҢҒз»ӯеӯҰд№ #и®әж–ҮеҲҶдә« #meta #lora #еӨҡжЁЎжҖҒдәәе·ҘжҷәиғҪ #ai
иҷҪ然全йқўеҫ®и°ғе’Ң LoRA еңЁжөӢиҜ•д»»еҠЎдёӯзҡ„иЎЁзҺ°еӨ§е№…дёӢйҷҚпјҲдәӢе®һеӯҰд№ д»»еҠЎж–№йқўпјҡеҫ®и°ғ -89%пјҢLoRA -71%пјүпјҢдҪҶи®°еҝҶеұӮзҡ„еӯҰд№ ж•ҲжһңеҚҙдҝқжҢҒдёҚеҸҳпјҢдё”йҒ—еҝҳзЁӢеәҰеӨ§е№…йҷҚдҪҺпјҲ-11%пјүгҖӮ
з ”з©¶иғҢжҷҜпјҡиҰҒеӯҰд№ ж–°зҹҘиҜҶпјҢжҲ‘д»¬ж— йңҖеҜ№еӨ§еһӢжЁЎеһӢзҡ„жүҖжңүеҸӮж•°иҝӣиЎҢзІҫз»Ҷи°ғж•ҙгҖӮиҝҷдҝғдҪҝеҮәзҺ°дәҶеҸӮж•°ж•ҲзҺҮй«ҳзҡ„жҢҒз»ӯеӯҰд№ /и®°еҝҶж–№жі•пјҢжҜ”еҰӮ LoRA е’Ң CartridgesпјҢе®ғ们дјҡеңЁжЁЎеһӢдёӯж·»еҠ дёҖе°ҸйғЁеҲҶеҸӮж•°гҖӮ然иҖҢпјҢLoRA зҡ„е®№йҮҸеӨ©з”ҹе°ұиҫғе°ҸвҖ”вҖ”дёҖдёӘе°ҸеһӢзҡ„йҖӮй…ҚеҷЁж— жі•йҖӮз”ЁдәҺй•ҝжңҹеӯҰд№ зҡ„йңҖжұӮгҖӮ
P2пјҡеңЁжң¬ж–ҮдёӯпјҢдҪңиҖ…еұ•зӨәдәҶиҝ‘жңҹжҸҗеҮәзҡ„и®°еҝҶеұӮжһ¶жһ„еҰӮдҪ•жҸҗдҫӣдёҖз§ҚжҪңеңЁзҡ„и§ЈеҶіж–№жЎҲпјҡз”ЁдёҖдёӘзЁҖз–ҸжіЁж„ҸеҠӣжҹҘжүҫжңәеҲ¶жқҘжӣҝд»Је…ЁиҝһжҺҘзҘһз»ҸзҪ‘з»ңпјҲFFNпјүпјҢиҜҘжҹҘжүҫжңәеҲ¶дјҡд»ҺдёҖдёӘеәһеӨ§зҡ„е·ІеӯҰд№ зҡ„и®°еҝҶй”®еҖјжұ дёӯиҝӣиЎҢжҹҘжүҫгҖӮиҝҷдёӘжһ¶жһ„иғҪеӨҹеҜ№жҜҸдёӘиҫ“е…ҘйЎ№жүҖжӣҙж–°зҡ„еҸӮж•°иҝӣиЎҢзІҫз»ҶжҺ§еҲ¶гҖӮ
P3: еҲ©з”Ёиҝҷз§ҚзЁҖз–ҸжҖ§пјҢдҪңиҖ…жҸҗи®®д»…жӣҙж–°йӮЈдәӣзү№е®ҡдәҺжҹҗдёҖзү№е®ҡиҫ“е…Ҙзҡ„еҶ…еӯҳж§ҪдҪҚвҖ”вҖ”иҝҷдәӣж§ҪдҪҚеңЁиҜҘиҫ“е…ҘдёҠиў«йў‘з№Ғи®ҝй—®пјҢдҪҶеңЁе…¶д»–ж•°жҚ®пјҲдҫӢеҰӮйў„и®ӯз»ғж•°жҚ®пјүдёҠи®ҝй—®йў‘зҺҮиҫғдҪҺпјҢ并且еҲ©з”Ё TFIDF еҜ№иҝҷдәӣж§ҪдҪҚиҝӣиЎҢжҺ’еәҸгҖӮиҝҷе®һзҺ°дәҶи®°еҝҶзҡ„йҖүжӢ©жҖ§гҖӮеҪ“дәҶи§ЈеҲ°жңүе…іиҙқжӢүе…ӢВ·еҘҘе·ҙ马зҡ„ж–°дҝЎжҒҜж—¶пјҢжҲ‘们еҸӘйңҖиҰҒеҫ®и°ғйӮЈдәӣвҖңеӯҳеӮЁвҖқиҜҘдҝЎжҒҜзҡ„ж§ҪдҪҚпјҢиҖҢж— йңҖи§ҰеҸҠйӮЈдәӣиҙҹиҙЈдҫӢеҰӮдәҶи§ЈеҰӮдҪ•зј–зЁӢзӯүеҠҹиғҪзҡ„еҸӮж•°гҖӮ
P4пјҡдҪңиҖ…й’ҲеҜ№дёӨдёӘжҢҒз»ӯжҖ§зҡ„дәӢе®һеӯҰд№ д»»еҠЎиҝӣиЎҢдәҶиҜ„дј°пјҡд»ҺдёҖзі»еҲ—вҖңTriviaQAвҖқдәӢе®һж•°жҚ®дёӯиҝӣиЎҢеӯҰд№ пјҢд»ҘеҸҠд»ҺвҖңSimpleQAвҖқдёӯзҡ„дёҖзі»еҲ—з»ҙеҹәзҷҫ科ж–ҮжЎЈдёӯиҝӣиЎҢеӯҰд№ гҖӮзЁҖз–Ҹи®°еҝҶеҫ®и°ғзҡ„ж•ҲжһңдёҺе®Ңе…Ёеҫ®и°ғе’Ң LoRA дёҖж ·еҘҪпјҢдҪҶеңЁжңӘжөӢиҜ•д»»еҠЎдёӯзҡ„иЎЁзҺ°еҚҙиҰҒеҘҪеҫ—еӨҡпјҢиҖҢдё”иҝҳиғҪе®һзҺ°жңүйҖүжӢ©жҖ§зҡ„жӣҙж–°пјҢд»ҺиҖҢеҮҸе°‘дәҶжҖ§иғҪзҡ„дёӢйҷҚгҖӮ
?Paper: arxiv.org/abs/2510.15103
Blogпјҡhttps://jessylin.com/2025/10/20/continual-learning/
#еҚҡеЈ«з”ҹ #еӨ§жЁЎеһӢ #gpt #жҢҒз»ӯеӯҰд№ #и®әж–ҮеҲҶдә« #meta #lora #еӨҡжЁЎжҖҒдәәе·ҘжҷәиғҪ #ai