



йҡҸзқҖеӨ§еһӢиҜӯиЁҖжЁЎеһӢпјҲLLMпјүиў«е№ҝжіӣз”ЁдәҺжҷәиғҪдҪ“зі»з»ҹпјҢдёҺеӨ–йғЁзҺҜеўғдәӨдә’еёҰжқҘе·ЁеӨ§йЈҺйҷ©вҖ”вҖ”е°Өе…¶жҳҜвҖңжҸҗзӨәжіЁе…ҘвҖқпјҲPrompt Injectionпјүж”»еҮ»гҖӮCISPAдёҺGoogle DeepMindеӣўйҳҹиҒ”еҗҲжҸҗеҮә SICпјҲSoft Instruction ControlпјүиҪҜжҢҮд»ӨйҳІеҫЎжңәеҲ¶пјҢйҖҡиҝҮеӨҡиҪ®иҝӯд»Јжё…жҙ—дёҺжЈҖжөӢпјҢжңүж•ҲйҷҚдҪҺжЁЎеһӢиў«жҒ¶ж„ҸжҢҮд»Өж“ҚжҺ§зҡ„йЈҺйҷ©гҖӮ
ж ёеҝғдә®зӮ№пјҡ
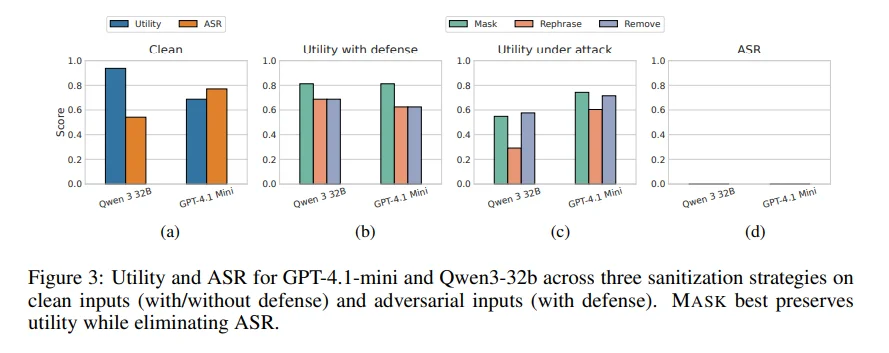
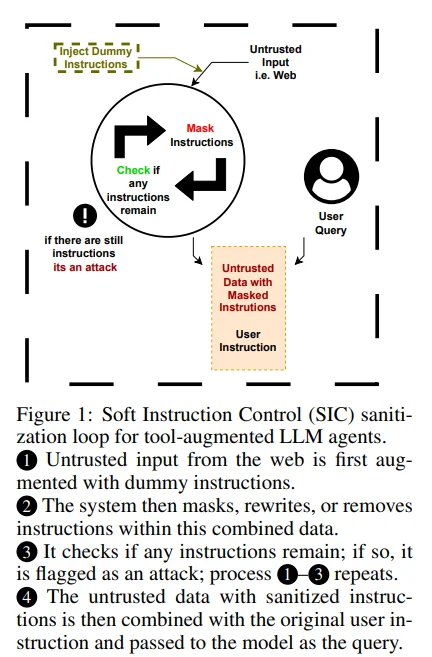
еӨҡиҪ®жҹ”жҖ§жё…жҙ—жңәеҲ¶пјҡеҸҚеӨҚжү«жҸҸгҖҒж”№еҶҷжҲ–еұҸи”Ҫиҫ“е…Ҙж•°жҚ®дёӯзҡ„вҖңжҢҮд»ӨжҖ§иҜӯеҸҘвҖқпјҢзӣҙеҲ°жЈҖжөӢдёҚеҲ°е‘Ҫд»ӨжҖ§еҶ…е®№гҖӮ
еҸҜжҸ’жӢ”йў„еӨ„зҗҶеұӮи®ҫи®ЎпјҡSICдҪңдёәзӢ¬з«ӢжЁЎеқ—иҝҗиЎҢпјҢж— йңҖдҝ®ж”№жЁЎеһӢз»“жһ„жҲ–д»ЈзҗҶйҖ»иҫ‘пјҢйғЁзҪІиҪ»йҮҸгҖҒе…је®№жҖ§ејәгҖӮ
вҖңиҪҜжҺ§еҲ¶вҖқзҗҶеҝөпјҡзӣёиҫғCaMeLзҡ„дёҘж јж•°жҚ®/жҺ§еҲ¶жөҒеҲҶзҰ»пјҢSICйҮҮз”Ёе®ҪжқҫиҜӯд№үиҜҶеҲ«пјҢе…јйЎҫе®үе…ЁдёҺеҸҜз”ЁжҖ§гҖӮ
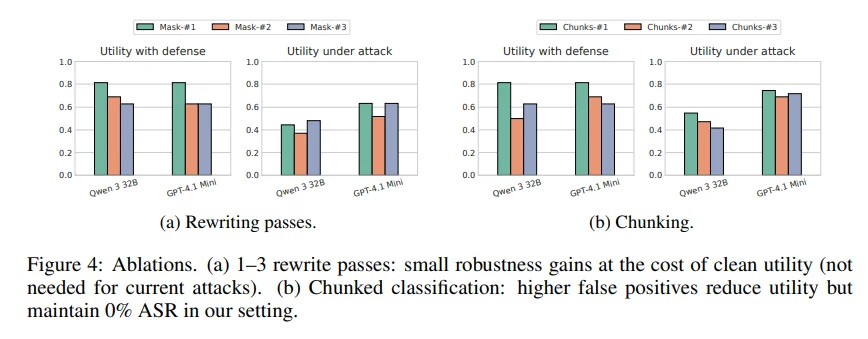
еӨҡйҮҚжЈҖжөӢеҶ—дҪҷпјҡеј•е…ҘвҖңеҒҮжҢҮд»Ө(canary)вҖқжЈҖжөӢжңәеҲ¶йӘҢиҜҒж”№еҶҷжңүж•ҲжҖ§пјҢ并еҜ№ж•ҙдҪ“дёҺеҲҶеқ—еҶ…е®№еҸҢйҮҚжЈҖжөӢгҖӮ
ж”»еҮ»йҡҫеәҰжҢҮж•°дёҠеҚҮпјҡж”»еҮ»иҖ…йңҖеҗҢж—¶з»•иҝҮйҮҚеҶҷгҖҒжЈҖжөӢдёҺйҮҚжһ„еӨҡдёӘзҺҜиҠӮпјҢжҳҫи‘—жҸҗй«ҳж”»еҮ»жҲҗжң¬гҖӮ
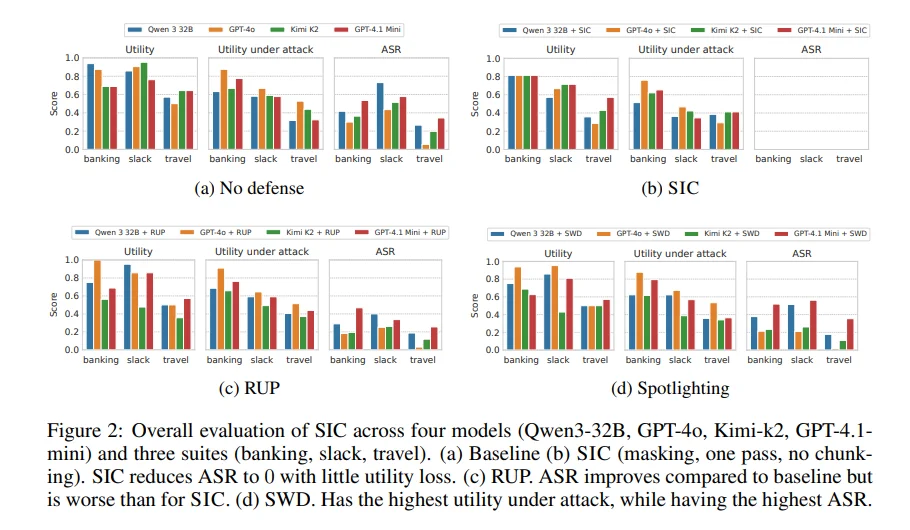
е®һиҜҒжҖ§иғҪејәеҠІпјҡеңЁAgentDojoеҹәеҮҶдёӯпјҢSICеңЁеӨҡжЁЎеһӢпјҲGPT-4oгҖҒQwen3-32BгҖҒKimi-K2зӯүпјүдёҠе®һзҺ° 0%ж”»еҮ»жҲҗеҠҹзҺҮпјҲASRпјүгҖӮ
иҮӘйҖӮеә”ж”»еҮ»дёӢд»ҚдҝқжҢҒйҹ§жҖ§пјҡеҚідҪҝйқўеҜ№NasrзӯүжҸҗеҮәзҡ„йҒ—дј з®—жі•зә§иҮӘйҖӮеә”ж”»еҮ»пјҢASRд»…15%пјҢйўҶе…ҲеҗҢзұ»йҳІеҫЎ3еҖҚд»ҘдёҠгҖӮ
еә”з”ЁеңәжҷҜ / з”ЁжҲ·еҸҚйҰҲ / е®һйӘҢз»“жһңпјҡ SICйҖӮз”ЁдәҺжүҖжңүе…·еӨҮе·Ҙе…·и°ғз”ЁгҖҒеӨ–йғЁж•°жҚ®и®ҝй—®жҲ–иҒ”зҪ‘еҠҹиғҪзҡ„LLMжҷәиғҪдҪ“пјҢе°Өе…¶жҳҜдјҒдёҡе®үе…ЁгҖҒиҮӘеҠЁеҢ–е®ўжңҚгҖҒйҮ‘иһҚдёҺеҠһе…¬еҠ©зҗҶзӯүй«ҳйЈҺйҷ©еңәжҷҜгҖӮ е®һйӘҢжҳҫзӨәпјҡеңЁдёҚзүәзүІеӨӘеӨҡе®һз”ЁжҖ§зҡ„еүҚжҸҗдёӢпјҢSICиғҪжҳҫи‘—йҷҚдҪҺиў«жіЁе…Ҙж”»еҮ»жҲҗеҠҹзҡ„жҰӮзҺҮпјҢдё”и®Ўз®—жҲҗжң¬зәҝжҖ§еҸҜжҺ§гҖӮеҜ№жҠ—е®һйӘҢйӘҢиҜҒе…¶еңЁй“¶иЎҢгҖҒSlackдёҺж—…иЎҢдёүеӨ§д»»еҠЎдёӯзЁіе®ҡйҳІеҫЎж•ҲжһңгҖӮ
ж„Ҹд№үпјҡ SICд»ЈиЎЁд»ҺвҖңзЎ¬йҳІеҫЎвҖқеҗ‘вҖңиҪҜйҳІеҫЎвҖқзҡ„йҮҚиҰҒиҪ¬жҠҳгҖӮе®ғдёҚжҳҜиҝҪжұӮзҗҶи®әе®ҢзҫҺпјҢиҖҢжҳҜзҺ°е®һеҸҜиЎҢгҖҒе®һз”Ёй«ҳж•Ҳзҡ„вҖңжҸҗй«ҳж”»еҮ»й—Ёж§ӣвҖқж–№жЎҲгҖӮи®әж–ҮжҢҮеҮәпјҢжңӘжқҘз ”з©¶еҸҜеңЁз»“жһ„еҢ–ж•°жҚ®пјҲеҰӮJSONгҖҒдјӘд»Јз ҒеөҢе…ҘпјүиҜҶеҲ«дёҺи·ЁеҸҘжҺЁзҗҶйҳІеҫЎж–№еҗ‘иҝӣдёҖжӯҘејәеҢ–гҖӮ еҜ№дәҺAIе®үе…Ёз ”з©¶иҖ…дёҺжҷәиғҪдҪ“зі»з»ҹејҖеҸ‘иҖ…иҖҢиЁҖпјҢSICжҸҗдҫӣдәҶдёҖдёӘе…је…·йҖҸжҳҺжҖ§дёҺиҪ»йҮҸжҖ§зҡ„йҳІеҫЎжЁЎжқҝпјҢдёәжһ„е»әеҸҜдҝЎгҖҒе®үе…Ёзҡ„AIд»ЈзҗҶзі»з»ҹеҘ е®ҡж–°еҹәзҹігҖӮ
? и®әж–Ү arXiv:2510.21057
#AIе®үе…Ё #prompt #llm #жҷәиғҪдҪ“е®үе…Ё #deepmind #CISPA #е®үе…Ёз ”з©¶ #з”ҹжҲҗејҸAI #Agentе®үе…Ё #е®үе…Ёжһ¶жһ„
ж ёеҝғдә®зӮ№пјҡ
еӨҡиҪ®жҹ”жҖ§жё…жҙ—жңәеҲ¶пјҡеҸҚеӨҚжү«жҸҸгҖҒж”№еҶҷжҲ–еұҸи”Ҫиҫ“е…Ҙж•°жҚ®дёӯзҡ„вҖңжҢҮд»ӨжҖ§иҜӯеҸҘвҖқпјҢзӣҙеҲ°жЈҖжөӢдёҚеҲ°е‘Ҫд»ӨжҖ§еҶ…е®№гҖӮ
еҸҜжҸ’жӢ”йў„еӨ„зҗҶеұӮи®ҫи®ЎпјҡSICдҪңдёәзӢ¬з«ӢжЁЎеқ—иҝҗиЎҢпјҢж— йңҖдҝ®ж”№жЁЎеһӢз»“жһ„жҲ–д»ЈзҗҶйҖ»иҫ‘пјҢйғЁзҪІиҪ»йҮҸгҖҒе…је®№жҖ§ејәгҖӮ
вҖңиҪҜжҺ§еҲ¶вҖқзҗҶеҝөпјҡзӣёиҫғCaMeLзҡ„дёҘж јж•°жҚ®/жҺ§еҲ¶жөҒеҲҶзҰ»пјҢSICйҮҮз”Ёе®ҪжқҫиҜӯд№үиҜҶеҲ«пјҢе…јйЎҫе®үе…ЁдёҺеҸҜз”ЁжҖ§гҖӮ
еӨҡйҮҚжЈҖжөӢеҶ—дҪҷпјҡеј•е…ҘвҖңеҒҮжҢҮд»Ө(canary)вҖқжЈҖжөӢжңәеҲ¶йӘҢиҜҒж”№еҶҷжңүж•ҲжҖ§пјҢ并еҜ№ж•ҙдҪ“дёҺеҲҶеқ—еҶ…е®№еҸҢйҮҚжЈҖжөӢгҖӮ
ж”»еҮ»йҡҫеәҰжҢҮж•°дёҠеҚҮпјҡж”»еҮ»иҖ…йңҖеҗҢж—¶з»•иҝҮйҮҚеҶҷгҖҒжЈҖжөӢдёҺйҮҚжһ„еӨҡдёӘзҺҜиҠӮпјҢжҳҫи‘—жҸҗй«ҳж”»еҮ»жҲҗжң¬гҖӮ
е®һиҜҒжҖ§иғҪејәеҠІпјҡеңЁAgentDojoеҹәеҮҶдёӯпјҢSICеңЁеӨҡжЁЎеһӢпјҲGPT-4oгҖҒQwen3-32BгҖҒKimi-K2зӯүпјүдёҠе®һзҺ° 0%ж”»еҮ»жҲҗеҠҹзҺҮпјҲASRпјүгҖӮ
иҮӘйҖӮеә”ж”»еҮ»дёӢд»ҚдҝқжҢҒйҹ§жҖ§пјҡеҚідҪҝйқўеҜ№NasrзӯүжҸҗеҮәзҡ„йҒ—дј з®—жі•зә§иҮӘйҖӮеә”ж”»еҮ»пјҢASRд»…15%пјҢйўҶе…ҲеҗҢзұ»йҳІеҫЎ3еҖҚд»ҘдёҠгҖӮ
еә”з”ЁеңәжҷҜ / з”ЁжҲ·еҸҚйҰҲ / е®һйӘҢз»“жһңпјҡ SICйҖӮз”ЁдәҺжүҖжңүе…·еӨҮе·Ҙе…·и°ғз”ЁгҖҒеӨ–йғЁж•°жҚ®и®ҝй—®жҲ–иҒ”зҪ‘еҠҹиғҪзҡ„LLMжҷәиғҪдҪ“пјҢе°Өе…¶жҳҜдјҒдёҡе®үе…ЁгҖҒиҮӘеҠЁеҢ–е®ўжңҚгҖҒйҮ‘иһҚдёҺеҠһе…¬еҠ©зҗҶзӯүй«ҳйЈҺйҷ©еңәжҷҜгҖӮ е®һйӘҢжҳҫзӨәпјҡеңЁдёҚзүәзүІеӨӘеӨҡе®һз”ЁжҖ§зҡ„еүҚжҸҗдёӢпјҢSICиғҪжҳҫи‘—йҷҚдҪҺиў«жіЁе…Ҙж”»еҮ»жҲҗеҠҹзҡ„жҰӮзҺҮпјҢдё”и®Ўз®—жҲҗжң¬зәҝжҖ§еҸҜжҺ§гҖӮеҜ№жҠ—е®һйӘҢйӘҢиҜҒе…¶еңЁй“¶иЎҢгҖҒSlackдёҺж—…иЎҢдёүеӨ§д»»еҠЎдёӯзЁіе®ҡйҳІеҫЎж•ҲжһңгҖӮ
ж„Ҹд№үпјҡ SICд»ЈиЎЁд»ҺвҖңзЎ¬йҳІеҫЎвҖқеҗ‘вҖңиҪҜйҳІеҫЎвҖқзҡ„йҮҚиҰҒиҪ¬жҠҳгҖӮе®ғдёҚжҳҜиҝҪжұӮзҗҶи®әе®ҢзҫҺпјҢиҖҢжҳҜзҺ°е®һеҸҜиЎҢгҖҒе®һз”Ёй«ҳж•Ҳзҡ„вҖңжҸҗй«ҳж”»еҮ»й—Ёж§ӣвҖқж–№жЎҲгҖӮи®әж–ҮжҢҮеҮәпјҢжңӘжқҘз ”з©¶еҸҜеңЁз»“жһ„еҢ–ж•°жҚ®пјҲеҰӮJSONгҖҒдјӘд»Јз ҒеөҢе…ҘпјүиҜҶеҲ«дёҺи·ЁеҸҘжҺЁзҗҶйҳІеҫЎж–№еҗ‘иҝӣдёҖжӯҘејәеҢ–гҖӮ еҜ№дәҺAIе®үе…Ёз ”з©¶иҖ…дёҺжҷәиғҪдҪ“зі»з»ҹејҖеҸ‘иҖ…иҖҢиЁҖпјҢSICжҸҗдҫӣдәҶдёҖдёӘе…је…·йҖҸжҳҺжҖ§дёҺиҪ»йҮҸжҖ§зҡ„йҳІеҫЎжЁЎжқҝпјҢдёәжһ„е»әеҸҜдҝЎгҖҒе®үе…Ёзҡ„AIд»ЈзҗҶзі»з»ҹеҘ е®ҡж–°еҹәзҹігҖӮ
? и®әж–Ү arXiv:2510.21057
#AIе®үе…Ё #prompt #llm #жҷәиғҪдҪ“е®үе…Ё #deepmind #CISPA #е®үе…Ёз ”з©¶ #з”ҹжҲҗејҸAI #Agentе®үе…Ё #е®үе…Ёжһ¶жһ„