


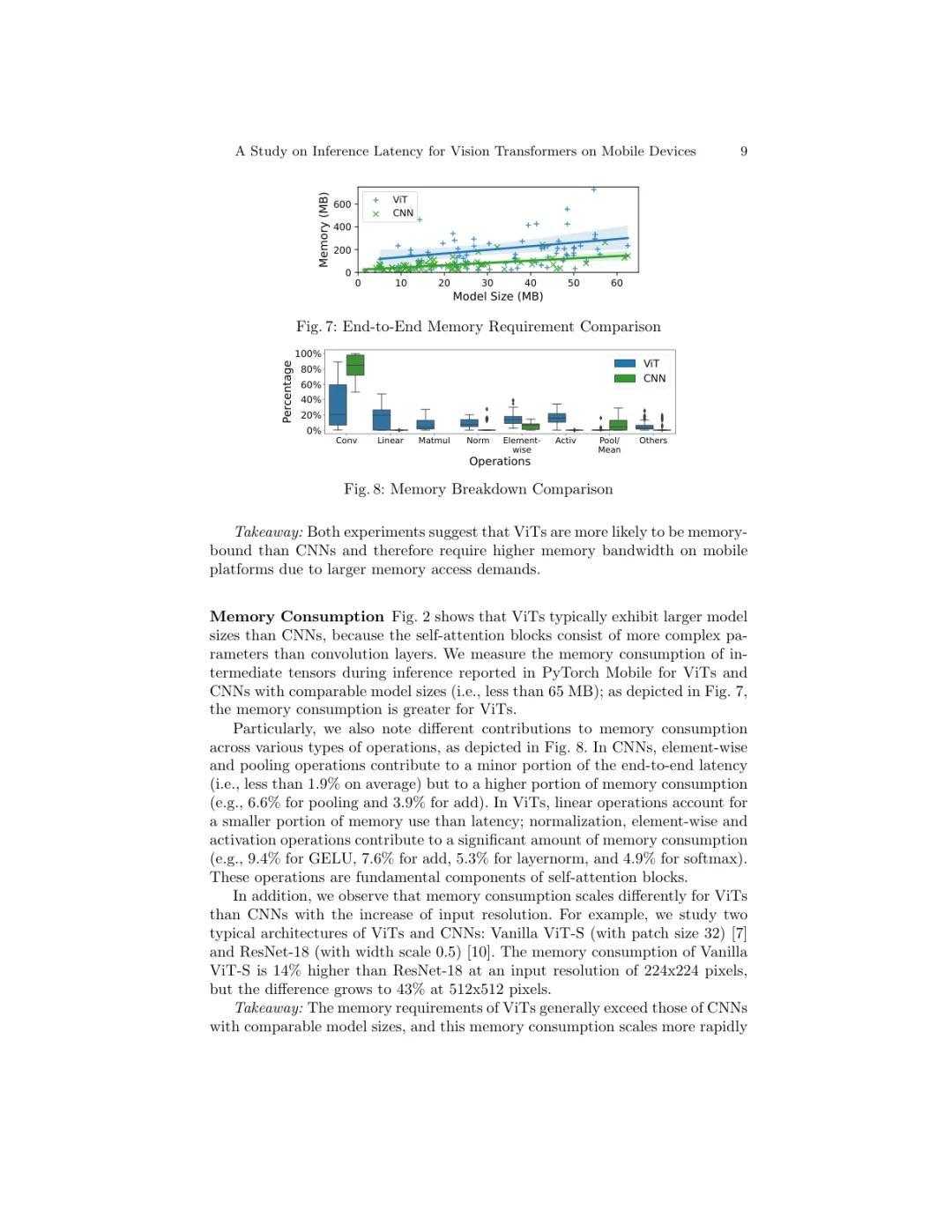





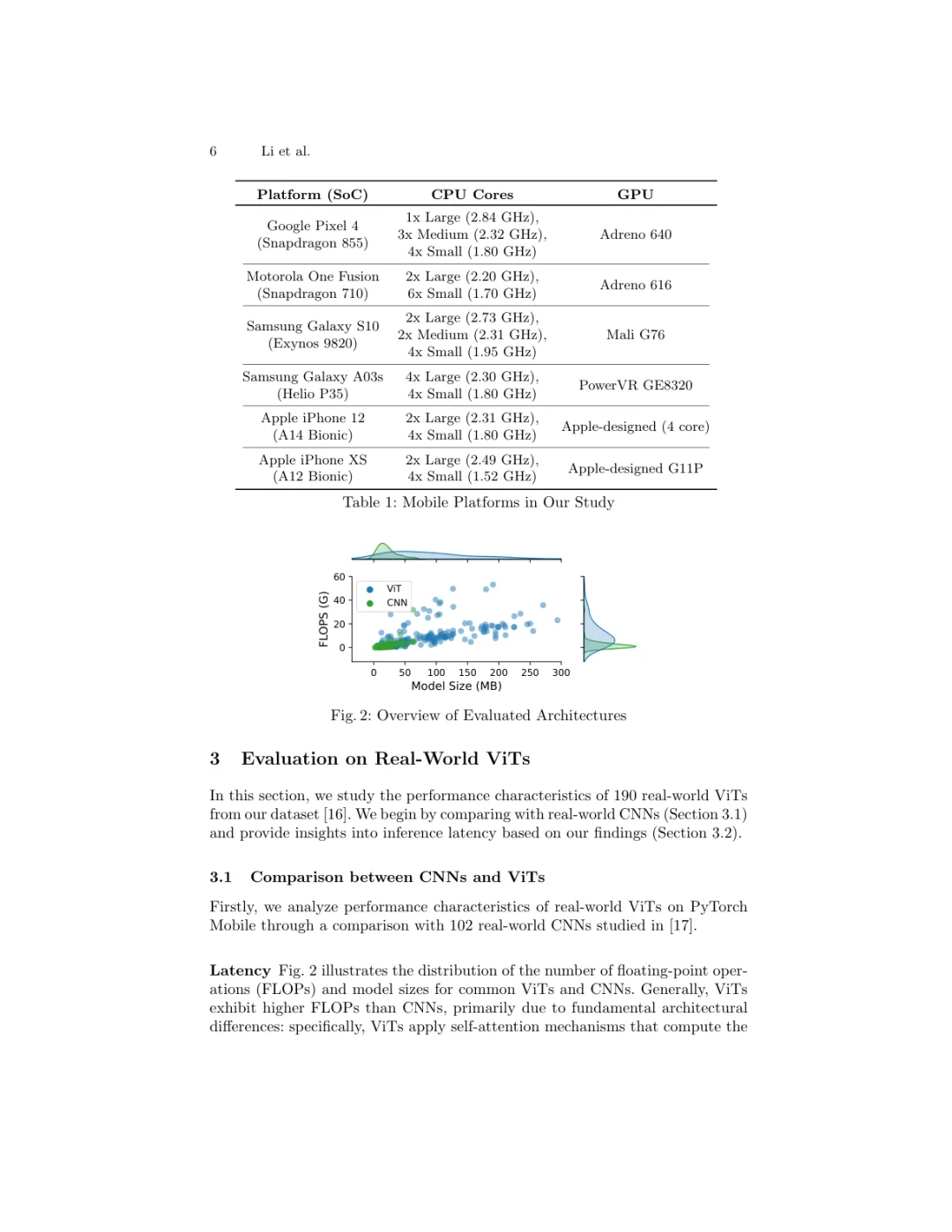
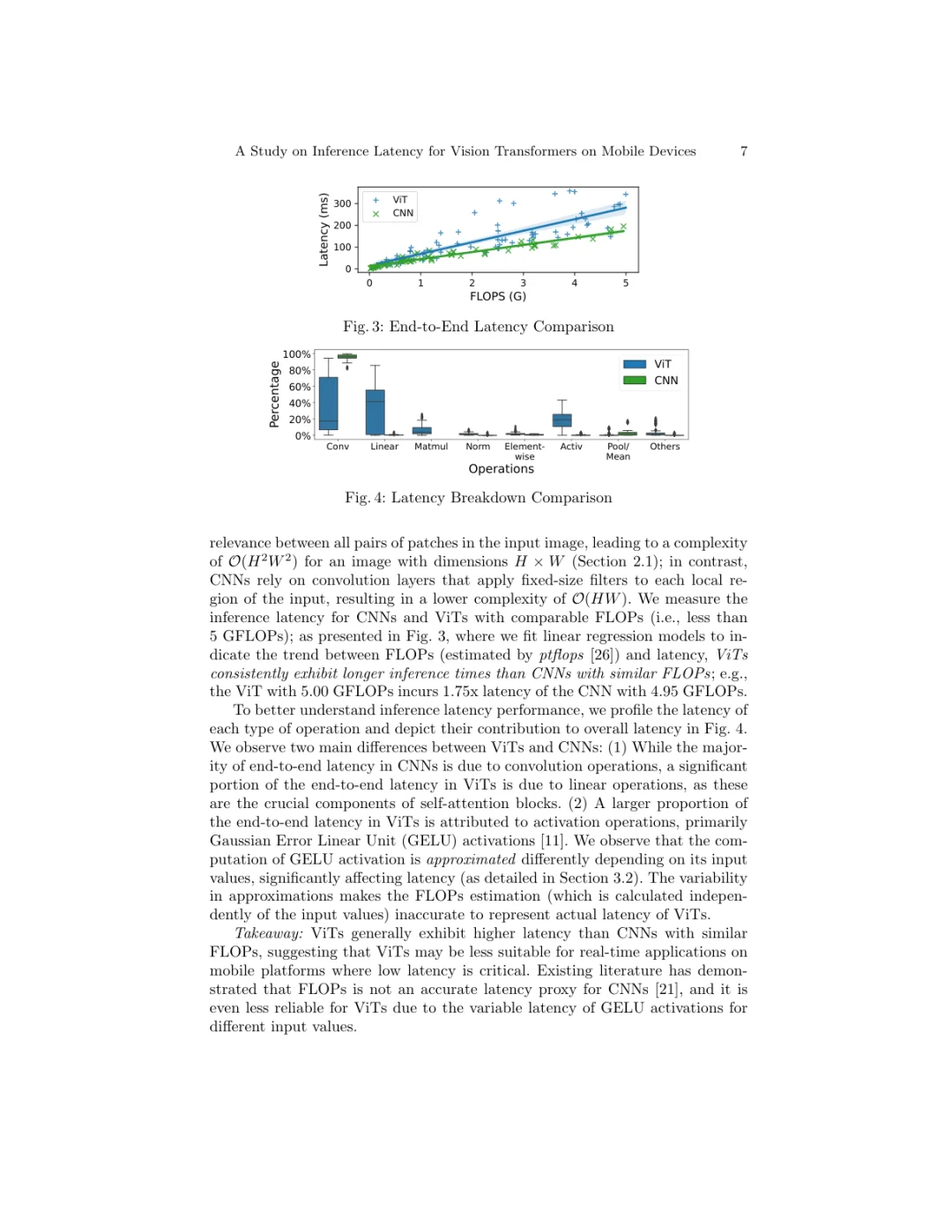
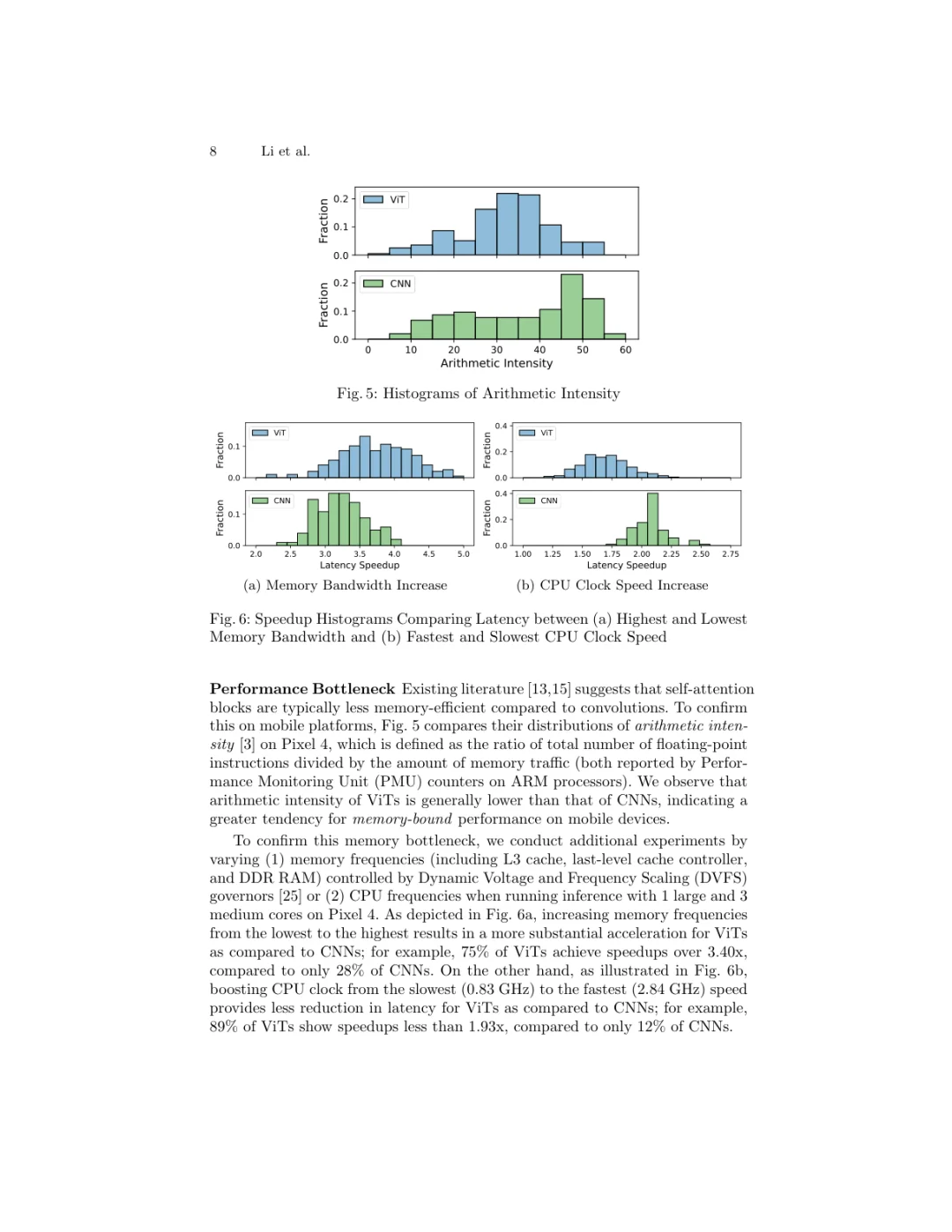
今天刷到一个南加州大学(USC)团队的工作,专门研究了视觉大模型Vision Transformer(ViT)在手机上的推理速度问题。对于想把ViT部署到移动端的同学来说,这篇很有参考价值。
现在ViT在CV领域越来越火,效果也很好,但大家有没有想过,把它放到手机上跑,到底会怎么样?它的性能瓶颈在哪?和传统的CNN比,谁更快?之前很少有工作系统地去研究这个问题,导致大家在做模型选型和优化时有点“摸黑过河”。
这个团队的做法非常扎实。他们先是找了190个真实的ViT模型和102个CNN模型,在6种不同的手机平台(包括苹果和安卓的主流机型)上进行了大规模的性能测试,直接对比ViT和CNN的推理延迟。
这篇工作最大的亮点在于,他们不只是测了一下,还挖得很深。
1. 他们通过对比发现,ViT在手机上通常比同等计算量(FLOPS)的CNN要慢,而且性能瓶颈主要在内存访问上,而不是计算本身。这就解释了为什么有时候模型看着计算量不大,但在手机上就是跑不快。
2. 更酷的是,他们基于这些发现,设计并构建了一个包含1000个合成ViT模型延迟的公开数据集。这些数据覆盖了2种主流推理框架和6个手机平台。这个数据集对于社区来说是个宝贵的资源。
3. 最后,利用这个数据集,他们训练了一个简单的预测器,可以非常准确地预测一个新ViT模型在手机上的推理延迟,而不需要实际部署测试。这对于模型设计(比如神经架构搜索NAS)来说,简直是神器,可以大大节省时间和成本。
实验结果显示,他们的延迟预测器表现很好,在合成ViT上的预测误差率在PyTorch Mobile上是4.4%,在TFLite上只有2.1%。对于真实世界的ViT模型,预测误差也能控制在较低水平,证明了这个方法在实际应用中是完全可行的。
这项研究为在移动设备上部署ViT提供了非常清晰的性能画像和实用的工具。以后开发者在为手机端选择或设计ViT模型时,可以更有依据地评估其性能,甚至提前预测延迟,让AI应用更快地在我们的手机上跑起来。
【论文主题】移动端ViT推理延迟
【论文arxiv链接】https://arxiv.org/abs/2510.25166
【论文发表年月】2025年10月
#AI #ViT #模型部署 #移动端AI #论文解读
现在ViT在CV领域越来越火,效果也很好,但大家有没有想过,把它放到手机上跑,到底会怎么样?它的性能瓶颈在哪?和传统的CNN比,谁更快?之前很少有工作系统地去研究这个问题,导致大家在做模型选型和优化时有点“摸黑过河”。
这个团队的做法非常扎实。他们先是找了190个真实的ViT模型和102个CNN模型,在6种不同的手机平台(包括苹果和安卓的主流机型)上进行了大规模的性能测试,直接对比ViT和CNN的推理延迟。
这篇工作最大的亮点在于,他们不只是测了一下,还挖得很深。
1. 他们通过对比发现,ViT在手机上通常比同等计算量(FLOPS)的CNN要慢,而且性能瓶颈主要在内存访问上,而不是计算本身。这就解释了为什么有时候模型看着计算量不大,但在手机上就是跑不快。
2. 更酷的是,他们基于这些发现,设计并构建了一个包含1000个合成ViT模型延迟的公开数据集。这些数据覆盖了2种主流推理框架和6个手机平台。这个数据集对于社区来说是个宝贵的资源。
3. 最后,利用这个数据集,他们训练了一个简单的预测器,可以非常准确地预测一个新ViT模型在手机上的推理延迟,而不需要实际部署测试。这对于模型设计(比如神经架构搜索NAS)来说,简直是神器,可以大大节省时间和成本。
实验结果显示,他们的延迟预测器表现很好,在合成ViT上的预测误差率在PyTorch Mobile上是4.4%,在TFLite上只有2.1%。对于真实世界的ViT模型,预测误差也能控制在较低水平,证明了这个方法在实际应用中是完全可行的。
这项研究为在移动设备上部署ViT提供了非常清晰的性能画像和实用的工具。以后开发者在为手机端选择或设计ViT模型时,可以更有依据地评估其性能,甚至提前预测延迟,让AI应用更快地在我们的手机上跑起来。
【论文主题】移动端ViT推理延迟
【论文arxiv链接】https://arxiv.org/abs/2510.25166
【论文发表年月】2025年10月
#AI #ViT #模型部署 #移动端AI #论文解读