


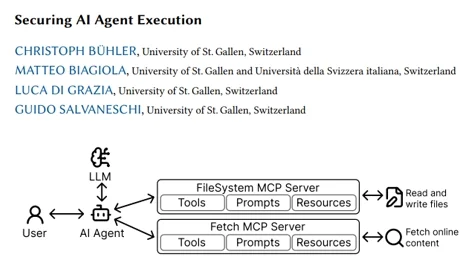
иҜҘи®әж–Үй’ҲеҜ№еҪ“еүҚ AI д»ЈзҗҶпјҲд»Ҙ LLM дёәжҺЁзҗҶж ёеҝғпјүйҖҡиҝҮ Model Context ProtocolпјҲMCPпјүи°ғз”ЁеӨ–йғЁе·Ҙе…·ж—¶еҮәзҺ°зҡ„вҖңй»ҳи®Өе®Ңе…ЁдҝЎд»»вҖқе®үе…ЁзјәеҸЈпјҡ
зҺ°жңү MCP жңҚеҠЎеҷЁеңЁдё»жңәдҫ§йҖҡеёёд»ҘеҺҹз”ҹиҝӣзЁӢиә«д»ҪиҝҗиЎҢпјҢ继жүҝз”ЁжҲ·зә§жқғйҷҗпјҢзјәд№Ҹйҡ”зҰ»дёҺжңҖе°ҸжқғйҷҗжңәеҲ¶пјӣ
ж”»еҮ»иҖ…еҸҜйҖҡиҝҮе·Ҙе…·жҠ•жҜ’гҖҒеӮҖе„Ўж”»еҮ»гҖҒжӢүжҜҜж”»еҮ»жҲ–жҒ¶ж„ҸеӨ–йғЁиө„жәҗж”»еҮ»пјҢеңЁжіЁеҶҢгҖҒиҝҗиЎҢжҲ–жӣҙж–°йҳ¶ж®өзӘғеҸ–ж•°жҚ®гҖҒжү§иЎҢе‘Ҫд»ӨжҲ–жЁӘеҗ‘移еҠЁпјӣ
йқҷжҖҒжү«жҸҸдёҺиҝҗиЎҢж—¶зӣ‘жҺ§зұ»ж–№жЎҲеҸӘиғҪвҖңжЈҖжөӢвҖқиҖҢйқһвҖңйҳ»жӯўвҖқи¶ҠжқғиЎҢдёәпјҢдё”з”ҹжҖҒзўҺзүҮеҢ–гҖҒеӨҚз”ЁжҖ§е·®гҖӮ
дёәжӯӨпјҢдҪңиҖ…жҸҗеҮә AgentBoundвҖ”вҖ”йҰ–дёӘйқўеҗ‘ MCP зҡ„еҸҜејәеҲ¶жү§иЎҢзҡ„и®ҝй—®жҺ§еҲ¶жЎҶжһ¶пјҢдҪҝжңҚеҠЎеҷЁеҝ…йЎ»еЈ°жҳҺжүҖйңҖжқғйҷҗпјҲAgentManifestпјүпјҢ并еңЁжІҷз®ұпјҲAgentBoxпјүдёӯжҢүеЈ°жҳҺзІҫзЎ®йҷҗеҲ¶ж–Ү件系з»ҹгҖҒзҪ‘з»ңгҖҒеӨ–и®ҫзӯүи®ҝй—®пјҢд»ҺиҖҢжҠҠвҖңдҝЎд»»дҪҶйӘҢиҜҒвҖқиҪ¬дёәвҖңйӘҢиҜҒдё”йҡ”зҰ»вҖқпјҢеңЁж— йңҖж”№еҠЁзҺ°жңүжңҚеҠЎеҷЁд»Јз Ғзҡ„еүҚжҸҗдёӢйҳ»ж–ӯз»қеӨ§еӨҡж•°й’ҲеҜ№зҺҜеўғзҡ„жҒ¶ж„ҸиЎҢдёәгҖӮ
зҺ°жңү MCP жңҚеҠЎеҷЁеңЁдё»жңәдҫ§йҖҡеёёд»ҘеҺҹз”ҹиҝӣзЁӢиә«д»ҪиҝҗиЎҢпјҢ继жүҝз”ЁжҲ·зә§жқғйҷҗпјҢзјәд№Ҹйҡ”зҰ»дёҺжңҖе°ҸжқғйҷҗжңәеҲ¶пјӣ
ж”»еҮ»иҖ…еҸҜйҖҡиҝҮе·Ҙе…·жҠ•жҜ’гҖҒеӮҖе„Ўж”»еҮ»гҖҒжӢүжҜҜж”»еҮ»жҲ–жҒ¶ж„ҸеӨ–йғЁиө„жәҗж”»еҮ»пјҢеңЁжіЁеҶҢгҖҒиҝҗиЎҢжҲ–жӣҙж–°йҳ¶ж®өзӘғеҸ–ж•°жҚ®гҖҒжү§иЎҢе‘Ҫд»ӨжҲ–жЁӘеҗ‘移еҠЁпјӣ
йқҷжҖҒжү«жҸҸдёҺиҝҗиЎҢж—¶зӣ‘жҺ§зұ»ж–№жЎҲеҸӘиғҪвҖңжЈҖжөӢвҖқиҖҢйқһвҖңйҳ»жӯўвҖқи¶ҠжқғиЎҢдёәпјҢдё”з”ҹжҖҒзўҺзүҮеҢ–гҖҒеӨҚз”ЁжҖ§е·®гҖӮ
дёәжӯӨпјҢдҪңиҖ…жҸҗеҮә AgentBoundвҖ”вҖ”йҰ–дёӘйқўеҗ‘ MCP зҡ„еҸҜејәеҲ¶жү§иЎҢзҡ„и®ҝй—®жҺ§еҲ¶жЎҶжһ¶пјҢдҪҝжңҚеҠЎеҷЁеҝ…йЎ»еЈ°жҳҺжүҖйңҖжқғйҷҗпјҲAgentManifestпјүпјҢ并еңЁжІҷз®ұпјҲAgentBoxпјүдёӯжҢүеЈ°жҳҺзІҫзЎ®йҷҗеҲ¶ж–Ү件系з»ҹгҖҒзҪ‘з»ңгҖҒеӨ–и®ҫзӯүи®ҝй—®пјҢд»ҺиҖҢжҠҠвҖңдҝЎд»»дҪҶйӘҢиҜҒвҖқиҪ¬дёәвҖңйӘҢиҜҒдё”йҡ”зҰ»вҖқпјҢеңЁж— йңҖж”№еҠЁзҺ°жңүжңҚеҠЎеҷЁд»Јз Ғзҡ„еүҚжҸҗдёӢйҳ»ж–ӯз»қеӨ§еӨҡж•°й’ҲеҜ№зҺҜеўғзҡ„жҒ¶ж„ҸиЎҢдёәгҖӮ