


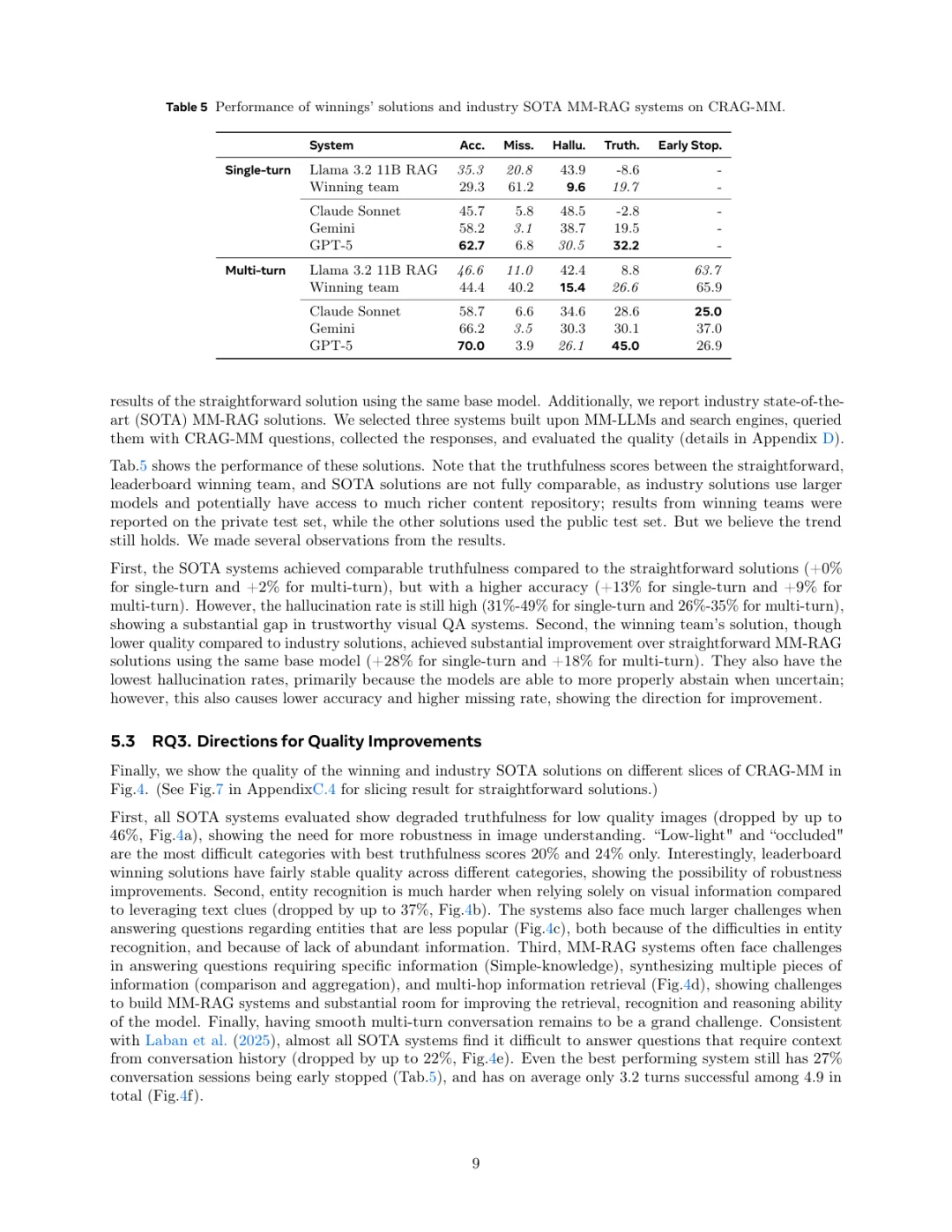


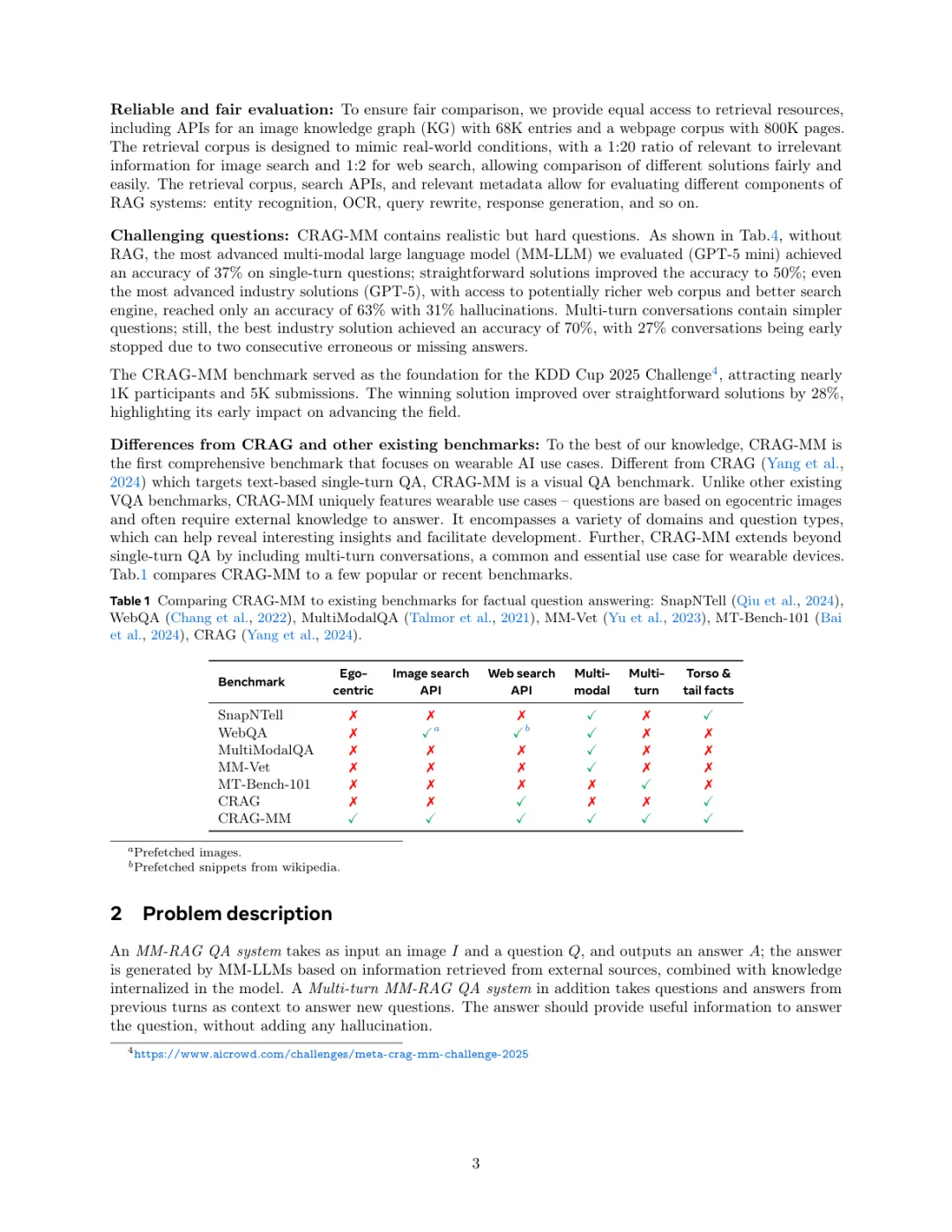


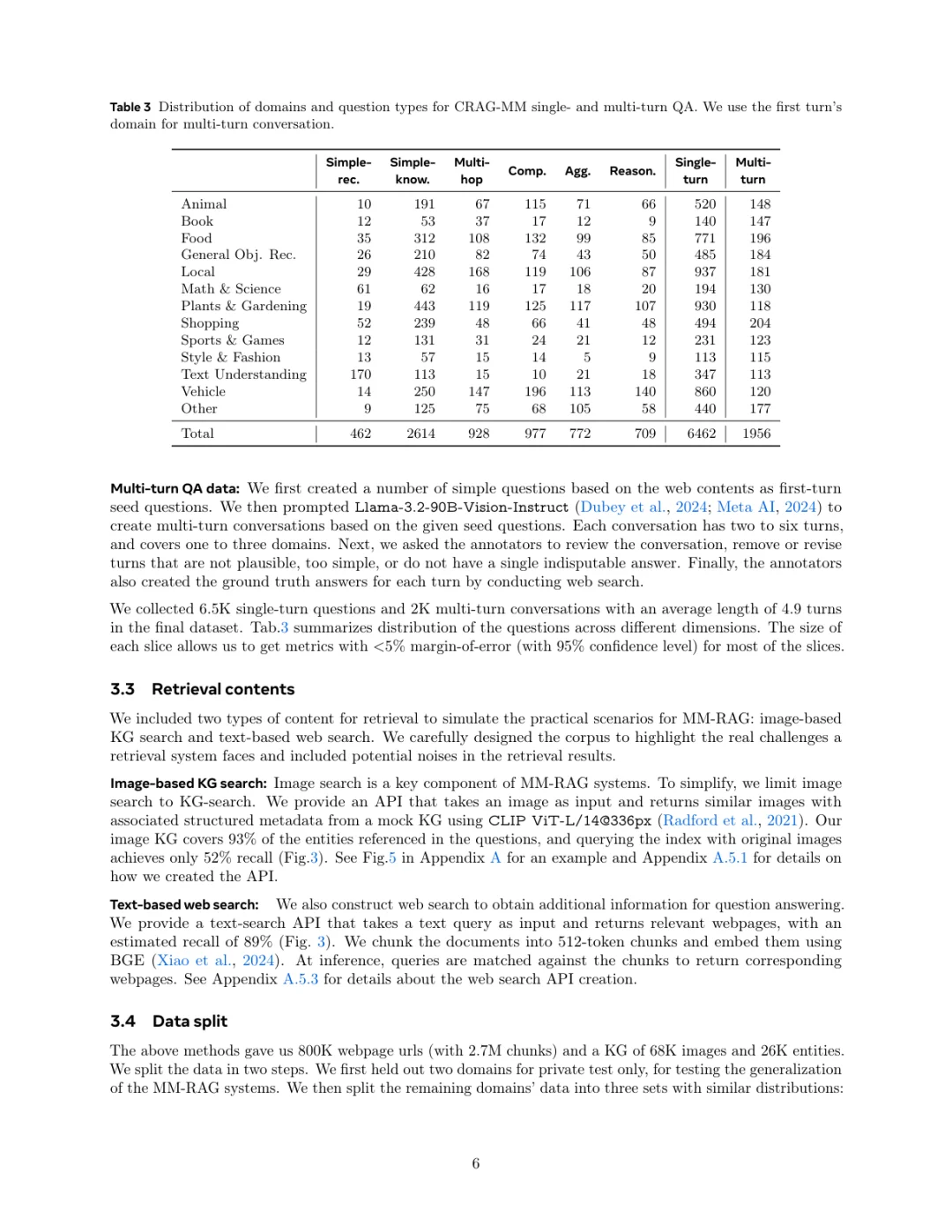
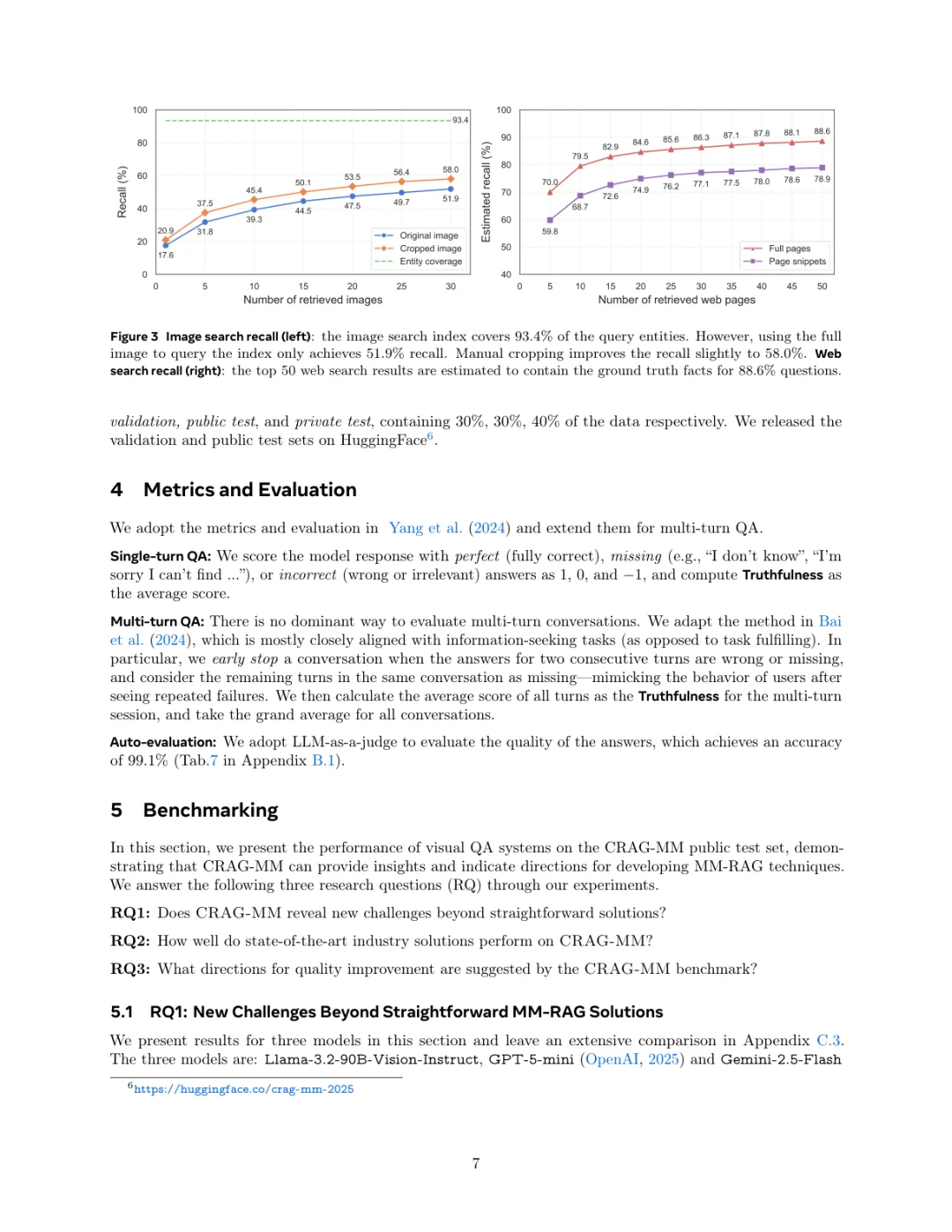
еҲ·еҲ°дёҖзҜҮMetaеӣўйҳҹзҡ„ж–°е·ҘдҪңпјҢе…ідәҺжҖҺд№Ҳз»ҷжҷәиғҪзңјй•ңиҝҷзұ»з©ҝжҲҙи®ҫеӨҮиЈ…дёҠдёҖдёӘжӣҙиҒӘжҳҺзҡ„еӨ§и„‘пјҢиҝҳжҢәжңүж„ҸжҖқзҡ„гҖӮ
зҺ°еңЁеӨ§е®¶йғҪз”ЁжҷәиғҪзңјй•ңзңӢдё–з•ҢпјҢзңӢеҲ°е•Ҙе°ұжғій—®й—®AIгҖӮжҜ”еҰӮвҖңиҝҷж ӢжҘјжңүе•ҘеҺҶеҸІпјҹвҖқ жҲ–иҖ… вҖңиҝҷж¬ҫйӣ¶йЈҹеҗ«зі–еҗ—пјҹвҖқгҖӮиҝҷе°ұйңҖиҰҒз”ЁеҲ°еӨҡжЁЎжҖҒжЈҖзҙўеўһејәз”ҹжҲҗпјҲMM-RAGпјүжҠҖжңҜпјҢи®©AIдёҚд»…иғҪзңӢжҮӮеӣҫзүҮпјҢиҝҳиғҪдёҠзҪ‘жүҫиө„ж–ҷжқҘеӣһзӯ”гҖӮдҪҶзӣ®еүҚиҝҳжІЎжңүдёҖдёӘе…Ёйқўзҡ„вҖңиҖғзәІвҖқжқҘиЎЎйҮҸAIеҲ°еә•еҒҡеҫ—еҘҪдёҚеҘҪпјҢе°Өе…¶жҳҜеңЁжЁЎжӢҹзңҹе®һи§Ҷи§’пјҲ第дёҖдәәз§°гҖҒеӣҫзүҮиҙЁйҮҸе·®пјүзҡ„жғ…еҶөдёӢгҖӮ
жүҖд»ҘMetaеӣўйҳҹжҺЁеҮәдәҶCRAG-MMпјҢдёҖдёӘдё“дёәз©ҝжҲҙи®ҫеӨҮеңәжҷҜи®ҫи®Ўзҡ„еӨҡжЁЎжҖҒгҖҒеӨҡиҪ®еҜ№иҜқRAGеҹәеҮҶгҖӮ他们жһ„е»әдәҶдёҖдёӘеӨ§ж•°жҚ®йӣҶпјҢеҢ…еҗ«дәҶ6500з»„еӣҫж–Үй—®зӯ”еҜ№е’Ң2000з»„еӨҡиҪ®еҜ№иҜқгҖӮиҝҷдәӣж•°жҚ®еҫҲзү№еҲ«пјҢеӨ§йғЁеҲҶйғҪжҳҜжЁЎжӢҹжҷәиғҪзңјй•ңжӢҚеҮәжқҘзҡ„第дёҖи§Ҷи§’з…§зүҮпјҢиҝҳж•…ж„ҸеҠ е…ҘдәҶжЁЎзіҠгҖҒйҒ®жҢЎиҝҷдәӣзңҹе®һдё–з•ҢйҮҢдјҡйҒҮеҲ°зҡ„еӣҫеғҸй—®йўҳгҖӮ
иҝҷдёӘе·ҘдҪңзҡ„еҲӣж–°зӮ№жҲ‘и§үеҫ—еҫҲе®һеңЁгҖӮйҰ–е…ҲпјҢе®ғйқһеёёиҙҙиҝ‘зңҹе®һеңәжҷҜпјҢдё“й—Ёй’ҲеҜ№з¬¬дёҖдәәз§°и§Ҷи§’е’Ңеҗ„з§ҚдҪҺиҙЁйҮҸеӣҫеғҸпјҢиҝҷжҳҜд»ҘеүҚзҡ„еҹәеҮҶеҫҲе°‘иҰҶзӣ–зҡ„гҖӮе…¶ж¬ЎпјҢе®ғдёҚеҸӘжҳҜдёҖдёӘж•°жҚ®йӣҶпјҢиҝҳи®ҫи®ЎдәҶдёүдёӘе…·дҪ“зҡ„иҜ„жөӢд»»еҠЎпјҡеҚ•жәҗжЈҖзҙўгҖҒеӨҡжәҗжЈҖзҙўгҖҒеӨҡиҪ®еҜ№иҜқпјҢ并且жҸҗдҫӣдәҶй…ҚеҘ—зҡ„зҹҘиҜҶеә“е’ҢзҪ‘йЎөжЈҖзҙўAPIпјҢзӣёеҪ“дәҺжҗӯе»әдәҶдёҖж•ҙдёӘиҖғеңәгҖӮжӣҙеҺүе®ізҡ„жҳҜпјҢе®ғе·Із»Ҹиў«з”ЁдҪңKDD Cup 2025зҡ„иөӣйўҳпјҢеҗёеј•дәҶдёҠеҚғдәәеҸӮдёҺпјҢиҜҙжҳҺиҝҷдёӘеҹәеҮҶзҡ„д»·еҖје·Із»Ҹеҫ—еҲ°дәҶдёҡз•Ңзҡ„и®ӨеҸҜгҖӮ
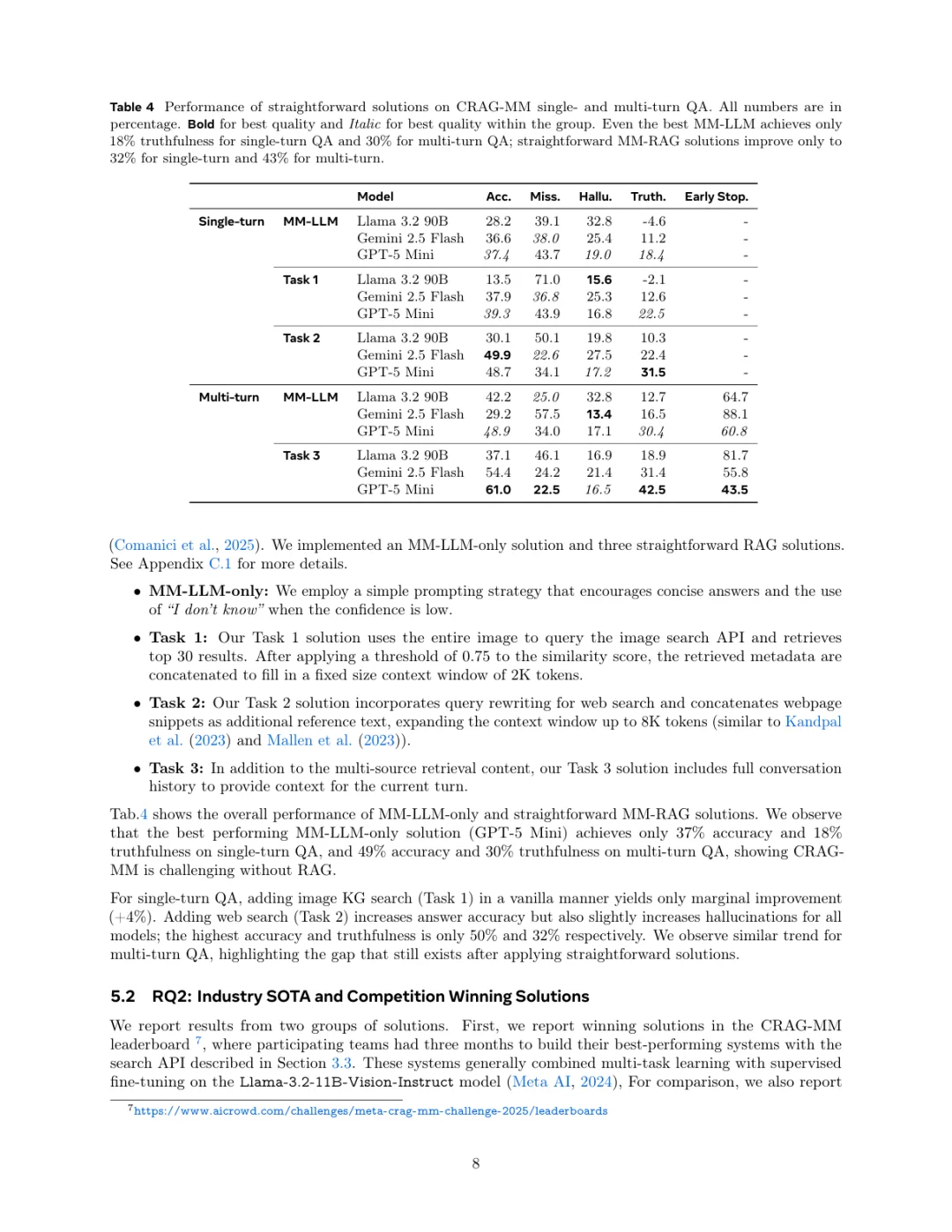
йӮЈзҺ°еңЁзҡ„жЁЎеһӢиЎЁзҺ°еҰӮдҪ•е‘ўпјҹз»“жһңжңүзӮ№жүҺеҝғгҖӮ他们жөӢиҜ•еҸ‘зҺ°пјҢеҚідҫҝжҳҜеҪ“еүҚжңҖејәзҡ„жЁЎеһӢпјҢеңЁеҚ•иҪ®е’ҢеӨҡиҪ®й—®зӯ”дёҠзҡ„еӣһзӯ”зңҹе®һжҖ§д№ҹеҸӘжңү32%е’Ң45%е·ҰеҸігҖӮиҝҷиҜҙжҳҺпјҢи®©AIжҲҙдёҠзңјй•ңзңӢжҮӮдё–з•ҢпјҢ并且еҮҶзЎ®еӣһзӯ”й—®йўҳпјҢиҝҳжңүеҫҲй•ҝзҡ„и·ҜиҰҒиө°гҖӮдёҚиҝҮеҘҪж¶ҲжҒҜжҳҜпјҢKDD CupдёҠзҡ„дјҳиғңж–№жЎҲе·Із»ҸжҠҠеҹәзәҝжҖ§иғҪжҸҗеҚҮдәҶ28%пјҢиҜҙжҳҺиҝҷдёӘйўҶеҹҹеңЁеҝ«йҖҹиҝӣжӯҘгҖӮ
CRAG-MMиҝҷдёӘе·ҘдҪңдёҚд»…жҢҮеҮәдәҶеҪ“еүҚMM-RAGжҠҖжңҜеңЁе®һйҷ…еә”з”Ёдёӯзҡ„зҹӯжқҝпјҢд№ҹдёәжңӘжқҘзҡ„з ”з©¶жҢҮжҳҺдәҶж–№еҗ‘пјҢжҸҗдҫӣдәҶдёҖдёӘйқһеёёеҘҪзҡ„е·Ҙе…·е’Ңе№іеҸ°гҖӮжңҹеҫ…еҗҺз»ӯиғҪзңӢеҲ°жӣҙеӨҡеҹәдәҺиҝҷдёӘеҹәеҮҶзҡ„зӘҒз ҙжҖ§иҝӣеұ•гҖӮ
гҖҗи®әж–Үдё»йўҳгҖ‘Multi-modal RAG, Benchmark, Wearable AI
гҖҗи®әж–Үarxivй“ҫжҺҘгҖ‘https://arxiv.org/abs/2510.26160
гҖҗи®әж–ҮеҸ‘иЎЁе№ҙжңҲгҖ‘2025е№ҙ10жңҲ
#AI #RAG #еӨҡжЁЎжҖҒ #Benchmark #Meta #дәәе·ҘжҷәиғҪ #и®әж–Үи§ЈиҜ» #еүҚжІҝ科жҠҖ
зҺ°еңЁеӨ§е®¶йғҪз”ЁжҷәиғҪзңјй•ңзңӢдё–з•ҢпјҢзңӢеҲ°е•Ҙе°ұжғій—®й—®AIгҖӮжҜ”еҰӮвҖңиҝҷж ӢжҘјжңүе•ҘеҺҶеҸІпјҹвҖқ жҲ–иҖ… вҖңиҝҷж¬ҫйӣ¶йЈҹеҗ«зі–еҗ—пјҹвҖқгҖӮиҝҷе°ұйңҖиҰҒз”ЁеҲ°еӨҡжЁЎжҖҒжЈҖзҙўеўһејәз”ҹжҲҗпјҲMM-RAGпјүжҠҖжңҜпјҢи®©AIдёҚд»…иғҪзңӢжҮӮеӣҫзүҮпјҢиҝҳиғҪдёҠзҪ‘жүҫиө„ж–ҷжқҘеӣһзӯ”гҖӮдҪҶзӣ®еүҚиҝҳжІЎжңүдёҖдёӘе…Ёйқўзҡ„вҖңиҖғзәІвҖқжқҘиЎЎйҮҸAIеҲ°еә•еҒҡеҫ—еҘҪдёҚеҘҪпјҢе°Өе…¶жҳҜеңЁжЁЎжӢҹзңҹе®һи§Ҷи§’пјҲ第дёҖдәәз§°гҖҒеӣҫзүҮиҙЁйҮҸе·®пјүзҡ„жғ…еҶөдёӢгҖӮ
жүҖд»ҘMetaеӣўйҳҹжҺЁеҮәдәҶCRAG-MMпјҢдёҖдёӘдё“дёәз©ҝжҲҙи®ҫеӨҮеңәжҷҜи®ҫи®Ўзҡ„еӨҡжЁЎжҖҒгҖҒеӨҡиҪ®еҜ№иҜқRAGеҹәеҮҶгҖӮ他们жһ„е»әдәҶдёҖдёӘеӨ§ж•°жҚ®йӣҶпјҢеҢ…еҗ«дәҶ6500з»„еӣҫж–Үй—®зӯ”еҜ№е’Ң2000з»„еӨҡиҪ®еҜ№иҜқгҖӮиҝҷдәӣж•°жҚ®еҫҲзү№еҲ«пјҢеӨ§йғЁеҲҶйғҪжҳҜжЁЎжӢҹжҷәиғҪзңјй•ңжӢҚеҮәжқҘзҡ„第дёҖи§Ҷи§’з…§зүҮпјҢиҝҳж•…ж„ҸеҠ е…ҘдәҶжЁЎзіҠгҖҒйҒ®жҢЎиҝҷдәӣзңҹе®һдё–з•ҢйҮҢдјҡйҒҮеҲ°зҡ„еӣҫеғҸй—®йўҳгҖӮ
иҝҷдёӘе·ҘдҪңзҡ„еҲӣж–°зӮ№жҲ‘и§үеҫ—еҫҲе®һеңЁгҖӮйҰ–е…ҲпјҢе®ғйқһеёёиҙҙиҝ‘зңҹе®һеңәжҷҜпјҢдё“й—Ёй’ҲеҜ№з¬¬дёҖдәәз§°и§Ҷи§’е’Ңеҗ„з§ҚдҪҺиҙЁйҮҸеӣҫеғҸпјҢиҝҷжҳҜд»ҘеүҚзҡ„еҹәеҮҶеҫҲе°‘иҰҶзӣ–зҡ„гҖӮе…¶ж¬ЎпјҢе®ғдёҚеҸӘжҳҜдёҖдёӘж•°жҚ®йӣҶпјҢиҝҳи®ҫи®ЎдәҶдёүдёӘе…·дҪ“зҡ„иҜ„жөӢд»»еҠЎпјҡеҚ•жәҗжЈҖзҙўгҖҒеӨҡжәҗжЈҖзҙўгҖҒеӨҡиҪ®еҜ№иҜқпјҢ并且жҸҗдҫӣдәҶй…ҚеҘ—зҡ„зҹҘиҜҶеә“е’ҢзҪ‘йЎөжЈҖзҙўAPIпјҢзӣёеҪ“дәҺжҗӯе»әдәҶдёҖж•ҙдёӘиҖғеңәгҖӮжӣҙеҺүе®ізҡ„жҳҜпјҢе®ғе·Із»Ҹиў«з”ЁдҪңKDD Cup 2025зҡ„иөӣйўҳпјҢеҗёеј•дәҶдёҠеҚғдәәеҸӮдёҺпјҢиҜҙжҳҺиҝҷдёӘеҹәеҮҶзҡ„д»·еҖје·Із»Ҹеҫ—еҲ°дәҶдёҡз•Ңзҡ„и®ӨеҸҜгҖӮ
йӮЈзҺ°еңЁзҡ„жЁЎеһӢиЎЁзҺ°еҰӮдҪ•е‘ўпјҹз»“жһңжңүзӮ№жүҺеҝғгҖӮ他们жөӢиҜ•еҸ‘зҺ°пјҢеҚідҫҝжҳҜеҪ“еүҚжңҖејәзҡ„жЁЎеһӢпјҢеңЁеҚ•иҪ®е’ҢеӨҡиҪ®й—®зӯ”дёҠзҡ„еӣһзӯ”зңҹе®һжҖ§д№ҹеҸӘжңү32%е’Ң45%е·ҰеҸігҖӮиҝҷиҜҙжҳҺпјҢи®©AIжҲҙдёҠзңјй•ңзңӢжҮӮдё–з•ҢпјҢ并且еҮҶзЎ®еӣһзӯ”й—®йўҳпјҢиҝҳжңүеҫҲй•ҝзҡ„и·ҜиҰҒиө°гҖӮдёҚиҝҮеҘҪж¶ҲжҒҜжҳҜпјҢKDD CupдёҠзҡ„дјҳиғңж–№жЎҲе·Із»ҸжҠҠеҹәзәҝжҖ§иғҪжҸҗеҚҮдәҶ28%пјҢиҜҙжҳҺиҝҷдёӘйўҶеҹҹеңЁеҝ«йҖҹиҝӣжӯҘгҖӮ
CRAG-MMиҝҷдёӘе·ҘдҪңдёҚд»…жҢҮеҮәдәҶеҪ“еүҚMM-RAGжҠҖжңҜеңЁе®һйҷ…еә”з”Ёдёӯзҡ„зҹӯжқҝпјҢд№ҹдёәжңӘжқҘзҡ„з ”з©¶жҢҮжҳҺдәҶж–№еҗ‘пјҢжҸҗдҫӣдәҶдёҖдёӘйқһеёёеҘҪзҡ„е·Ҙе…·е’Ңе№іеҸ°гҖӮжңҹеҫ…еҗҺз»ӯиғҪзңӢеҲ°жӣҙеӨҡеҹәдәҺиҝҷдёӘеҹәеҮҶзҡ„зӘҒз ҙжҖ§иҝӣеұ•гҖӮ
гҖҗи®әж–Үдё»йўҳгҖ‘Multi-modal RAG, Benchmark, Wearable AI
гҖҗи®әж–Үarxivй“ҫжҺҘгҖ‘https://arxiv.org/abs/2510.26160
гҖҗи®әж–ҮеҸ‘иЎЁе№ҙжңҲгҖ‘2025е№ҙ10жңҲ
#AI #RAG #еӨҡжЁЎжҖҒ #Benchmark #Meta #дәәе·ҘжҷәиғҪ #и®әж–Үи§ЈиҜ» #еүҚжІҝ科жҠҖ