


OpenESG NEWS

上周,红衫资本“AI Ascent 2024"大会上其合伙人抛出了一个不算太新的观点:AI 的一大机遇将是软件替代服务。
这个问题如果从AI成为软件行业的增量价值,那么似乎还是没有完全回复。但红衫分享的PPT上看到的软件公司版图上,例如SAP, salesforce, zoom等为代表的公司, 可以说未来任何一家公司都是数据公司,那么问题来了,既然AI会成为增量价值,以数据驱动的软件公司将以什么样的商业模式来转型?

Source:Sequoia Capitals
笔者发现诸多AI需求算法、算力目前来说不是根本性问题,以用户需求为触发的chatbot,缺乏数据产品的灵活商业模式是目前诸多金融科技商业公司存在的难题,也是面对转型的挑战。
AI是对现有软件的增值。务实一点的说,人工智能是SAAS软件基础设施的子集,软件行业因此从人工智能中获得了很多”感觉良好“的价值。
目前国内大模型公司百花齐放,各种场景的AI应用也不断应用而生。但对于天生就有AI基因的数据公司卷各种成本的解决方案,但AI已经越来越成为各大公司的战略,软件公司也面临着转型,但除了C端的应用,B端的生产力有哪些好的应用场景,往往大家首先想到的是我们的大模型能力不够。
但算法和算力并不是真正的门槛,笔者曾于IT解决方案及软件公司一线管理层沟通中获悉,没有应用场景需求,最多就是做汇报,那么算力基础设施就没有用武之地。其实说白了,AI-enabled软件行业还是因为没有更有场景化技术的支撑变得难以落地和泛化。
前几天Databricks是AI应用方面的种子选手,其数据智能产品覆盖了美国70%的企业,在AI转型方面也算是打了个样,开源了为业务而定制的DBRX大模型,不仅以更低成本更高效率,而且其开源的模型对业务层面数据的传递保持透明,是对应用落地场景极大的吸引力。
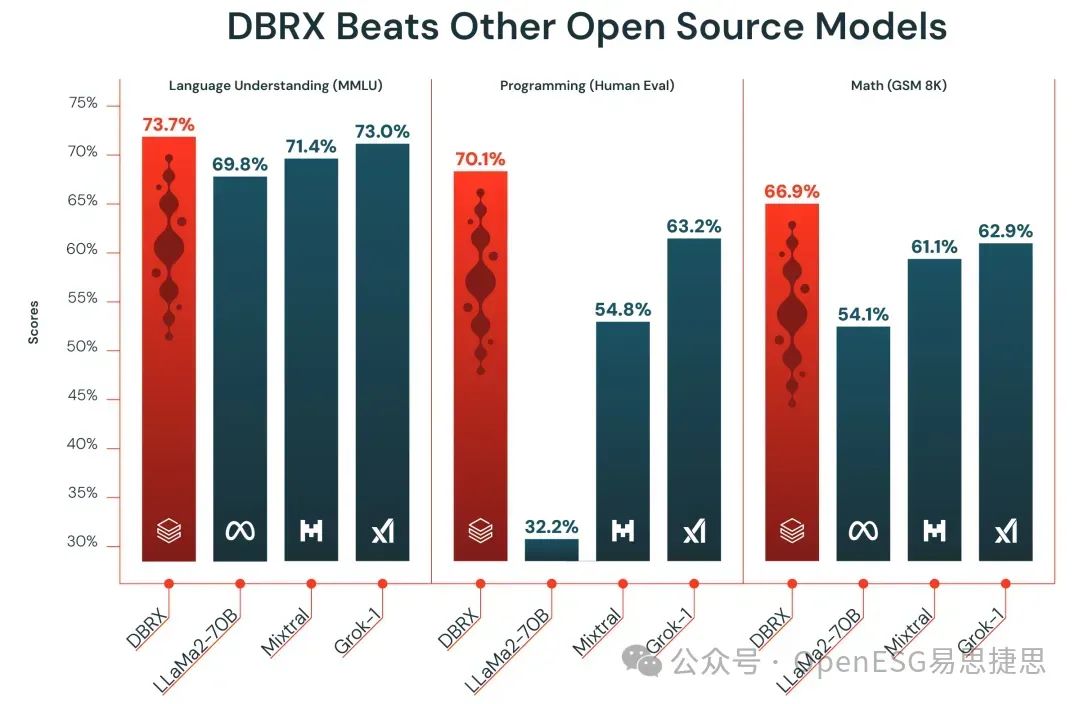
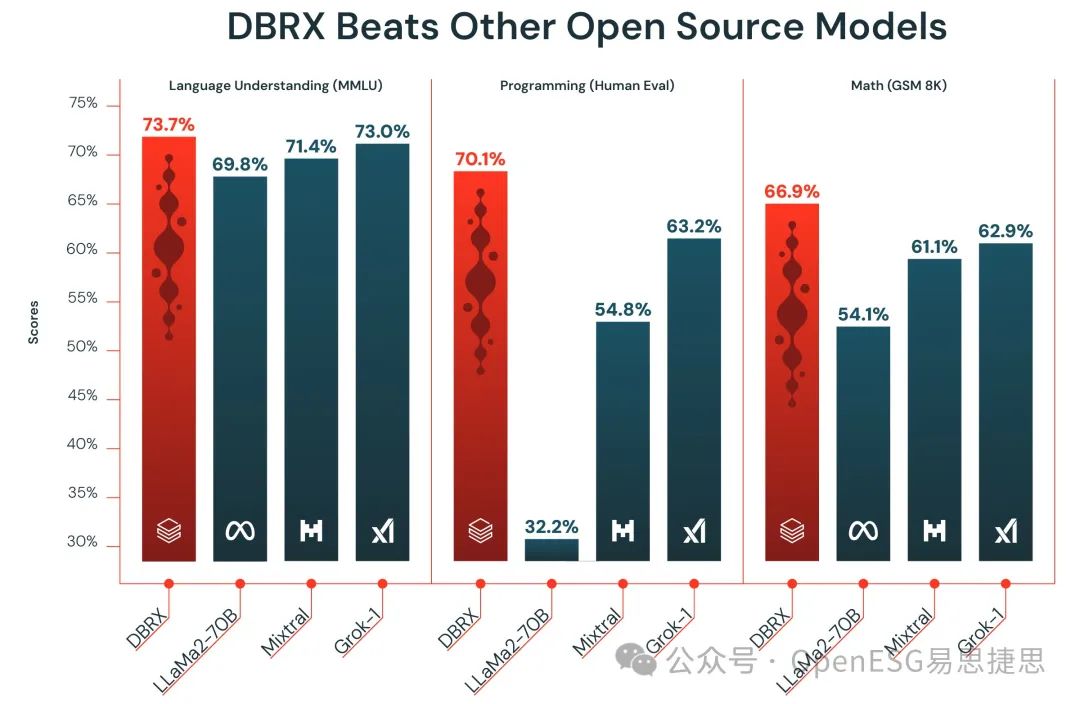
Source: Databricks
Databricks推出的DBRX 模型称为“专家混合”的架构,其中只有模型的某些部分激活以响应查询,具体取决于其内容。这产生了一个训练和操作效率更高的模型。DBRX 拥有大约 1360 亿个参数,或者模型中在训练期间更新的值。Llama 2 有 700 亿个参数,Mixtral 有 450 亿个参数,Grok 有 3140 亿个参数。但 DBRX 平均只激活约 360 亿个来处理典型的查询。
Source: Databricks
DBRX 由 其收购的Mosaic AI 开发,在 NVIDIA DGX Cloud 上进行训练,并通过 MegaBlocks 架构针对效率进行了优化。它在 GitHub、Hugging Face 和 Databricks Platform 上可用,允许企业与 DBRX 交互并基于其独特数据构建自定义模型。此外,DBRX 预计将通过 NVIDIA API 目录提供,并在 NVIDIA NIM 推理微服务上提供支持。
此外回到本文的核心大模型的能力,Databricks CEO Ali 认为模型质量好坏最重要的一部分是模型的数据。数据质量,数据清理,数据过滤以及数据准备都非常重要。
但笔者并不认为,应当说AI应用场景的落地能力强弱取决于数据的好坏。
在中国来说,独立的行业数据企业生态并未成型,不像美国出现的3大云巨头+2大数据智能公司包括Snowflake 以及 Data Bricks。企业级的大数据+大模型,我们看到有不少公司尝试起了AI一体机的生意,解决了算力租用,定制化算法以及专有数据的一体化体验。当然这也潜藏了一个难题就是成本昂贵,如何拥抱大模型以轻量化的姿态,Databricks的崛起之路及商业模式转型值得参考。
人工智能是一个巨大的长期机会,这将改变一切,每个人都会利用人工智能,通过API调用变得人人可用。 在不久的未来,每个领域的赢家都是那些可以最有效利用数据和 AI 的。
在数据领域,未来的大数据架构将是一个高度集成、智能化和自动化的系统,它能够有效地处理和分析大量数据,同时简化数据管理和 AI 应用的开发过程,为企业提供竞争优势,Databricks 工程总监李潇表示。

