


ChatGPT 等系列模型横空出世,以其强大的性能引起了全球的关注,有望改变人与计算机之间的交互方式,应用到千行百业。然而这些大型模型的实际需要极高的内存和计算资源,限制了它们在各种场景中的应用。例如,具有 175B 参数的 GPT-3 在使用 FP32 数据类型存储时需要大约 700GB 内存。尽管 7B 参数模型相对更高效,但其资源需求仍然难以直接部署在手机等边缘设备上。
此外,尽管许多研究已经成功地打造出多个效果很好的大语言模型,但他们往往采用相似的训练策略。一方面,大量工作集中在收集和清理数据上,较少强调研究有效的训练策略。另一方面,大型模型的训练需要极高的计算资源投入,使得探索大量的优化策略并不切实际。

盘古 π 论文链接:https://arxiv.org/pdf/2312.17276.pdf
“小” 模型训练论文链接:https://arxiv.org/pdf/2402.02791.pdf
训练实现链接:https://github.com/YuchuanTian/RethinkTinyLM
在这篇工作中,作者以一个 1B 大小的语言模型作为载体,详细讨论了小的语言模型应该如何炼丹。作者从模型结构、参数初始化、模型优化方法三个角度展开研究:总结出四条提升小语言模型效果的炼丹术:
1、 分词器裁剪(Tokenizer):在小的模型直接继承大模型的 Tokenizer 会引入冗余参数,增加计算开销增加。删除 Tokenizer 中的低频词汇,可以减少 Tokenizer 参数量,为模型主体留足空间。
2、 模型架构调优:模型的深度、宽度对小语言模型效果极大。同参数量下,较深的模型往往效果更好,但推理效率更低。
3、 参数继承:继承大模型参数作为初始值可以提升模型效果并加速收敛。在挑选参数时,首尾层比中间层更重要,每层内的有效参数可以通过可学 mask 得到。
4、 多轮训练:多轮训练被验证对训小模型有效。上一轮训练记录的 loss 值等中间结果可以指导样本的挑选,降低多轮训练的代价。
基于上述策略,作者构建了两个 PanGu-π-1B Pro 和 PanGu-π-1.5B Pro。与类似规模的模型相比,取得了更优的效果。
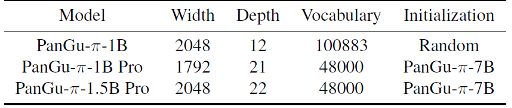
PanGu-π-1B 和 PanGu-π-1.5B 的结构设定
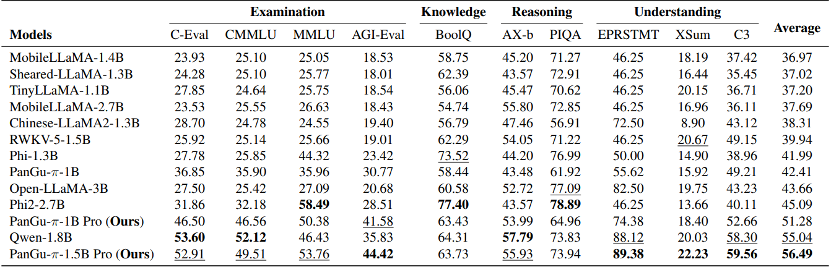
在通用测评集(考试、知识、推理、理解)与相近规模模型的比较。
以下将对四条炼丹术做详细分析。为了控制成本,大多数实验是基于 1B 模型在 50B 条中英文语料上完成的。
分词器裁剪
多语言大模型往往采用一个很大的词表来覆盖各种语料库,但是对于小模型来说,一个大词表就已经占用很多参数了。例如,Qwen-7B、Baichuan2-7B 和 PanGu-π-7B 的词汇量分别为 151936、125696、100883。它们的头部和嵌入层的参数分别占总体参数的 16.12\%、13.72\%、10.91\%。而对于 1B 模型来说模型,使用相同的分词器会占到模型大小的 30% 以上。
实际上,词表中存在大量冗余。通过使用从 PanGu-$\pi$ 模型继承的 100k 词汇表初始化分词器,我们对包含大约 1.6T 分词的庞大语料库进行了频率分析。如下图所示,词表表现出长尾效应,其中前 48k 词汇就占据训练语料库的 97.86%,也就是说超过 50% 的词汇可能是多余的,因为它们只满足不到 3% 的语料库。把低频词表删除,就可以大幅降低词表参数量,把空间留给模型主体,用于提升模型表达能力。
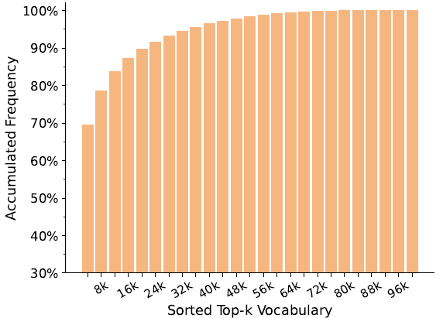
97.86% 的数据可以被 48k 的小词表表示
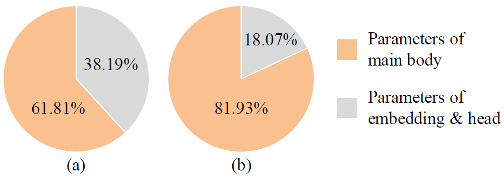
参数量占比:(a)使用直接继承的大词表 (b)使用裁剪后的词表
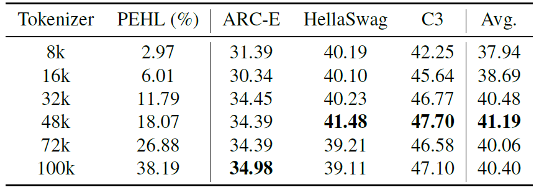
模型效果与词表大小的关系(固定参数量为 1B)
模型架构调优
模型架构的配置,例如宽度、深度和扩展率,对小语言模型的最终性能有相当大的影响。作者做了大量实验进行分析,发现深度影响小语言模型效果最重要的因素。一个更深的模型效果更好,但在 GPU 的推理速度也会低一些,以下是在 50B 数据上具体的实验结果。
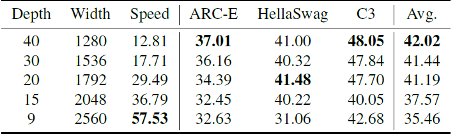
深度、宽度对 1B 模型效果的影响(固定扩张率)
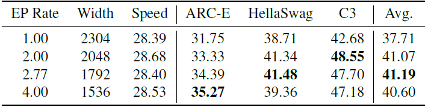
FFN 扩张率对 1B 模型效果的影响(固定深度)
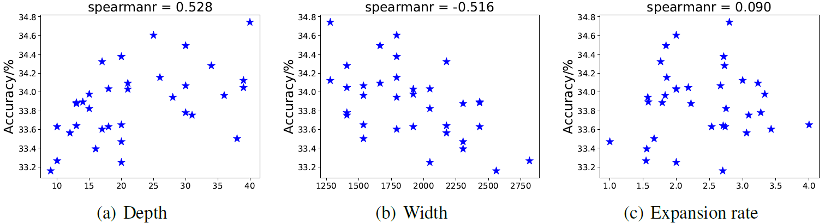
固定模型参数量为 1B 左右,模型效果与深度、宽度、扩张率之间的关系。
参数继承
大模型耗费大量算力在大量数据上进行训练,拥有强大的泛化能力。作者验证了从大模型中继承参数可以从一个较高的起点开始训模型,能够有效提升模型效果。
作者首先验证了模型各个层的重要性。对于 LLaMA2-7B、LLaMA2-13B、InternLM-7B 和 PanGu-π-7B 等多个大模型,作者跳过了一些层,来观察跳过后模型效果的变化。不同模型都展现出类似的规律:越靠近模型两端的层对模型效果的影响最大,删除一些中间层对模型效果影响较小。因此参数继承时,可以删除大模型部分中间层,来对齐大小模型的深度。
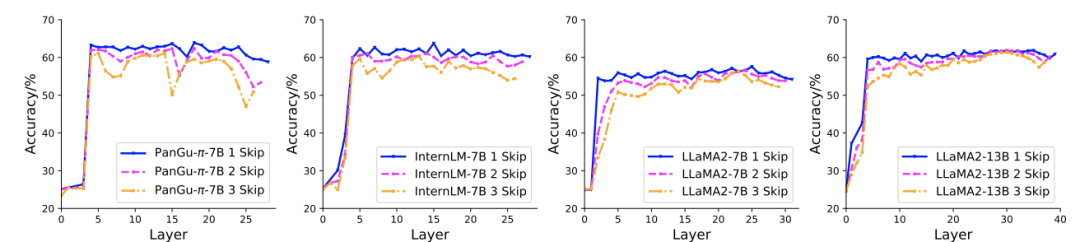
删除大模型中的多个层来验证层的重要性。不同大模型上的实验结果表明,靠近首尾的层中间层更重要。
在每个层内部,可以用各种度量函数来评估参数的重要性,包括权重的范数、泰勒展开式、数据驱动可学的度量等。下图比较了使用不同度量选择参数后模型训练效果和收敛速度。使用数据驱动学习的度量是最有效的,可以从较好的起点开始,以更快的速度收敛到更低的 loss 值。
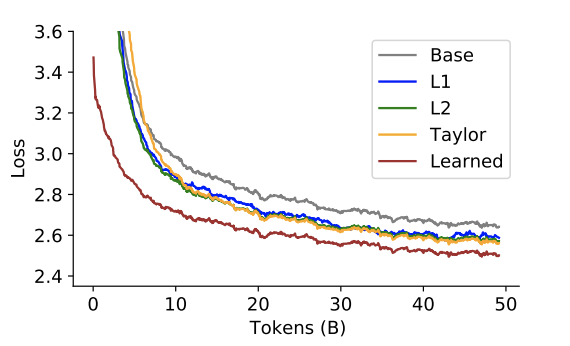
不同参数选择方法效果的比较
多轮训练
现在大多数大模型通常只训练一轮语言模型,即所有的数据只用一次来更新模型,模型的参数实际上并未充分收敛。同时,小语言模型容量较小,也使得模型的遗忘问题更加严重。作者提出应当对模型进行多轮训练,来减轻遗忘问题。
为了降低多轮训练的成本,可以使用第一轮的训练 loss 来做数据筛选和精炼,优先选择 loss 大的数据送入第二轮。用 r 表示第 2 轮训练时样本的采样率,可以发现当采样率超过 50% 时,模型效果的提升比较小。
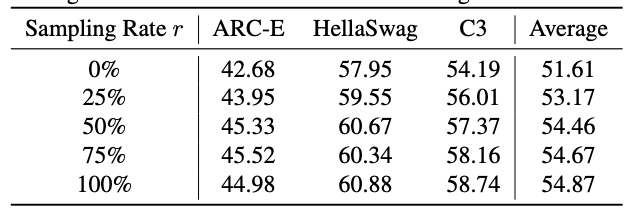
第二轮训练时数据采样率的影响
以下是模型在全量数据(1.6T token)上的训练曲线,可以发现第二轮训练时,模型效果依然有非常明显的提升。
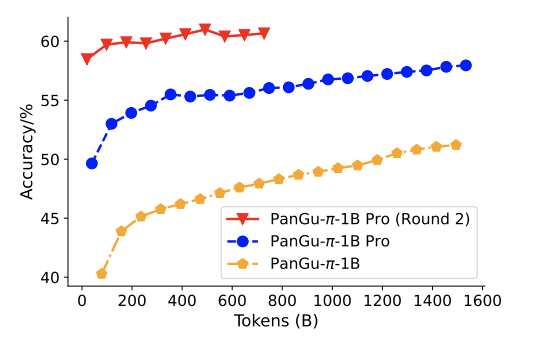
训练过程中,PanGu-π-1B 和 PanGu-π-1B Pro 模型在 HellaSwag 数据集上的效果
特别说明:本文仅用于学术交流,如有侵权请后台联系小编删除。
- END -
转载来源:机器之心
转载编辑:朱文贤
审核:李丹 赵恩婷 黄莉云 韩梅


资讯推荐

▶ 技术与工具
▶ 国际语言服务动态
| 翻译公司篇 | “收购狂魔”Keywords Studios
| 行业机构篇 | 加拿大联邦翻译局 Canada's Translation Bureau
▶ 专访
▶ 行业洞察
▶ 教育创新

