



点击蓝字关注哦


欢迎观看视频了解此篇软文
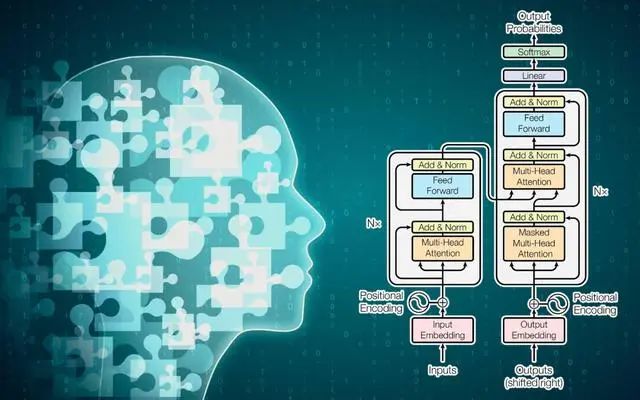
GPT(Generative Pre-trained Transformer)的理论基础和原理主要基于Transformer模型和预训练技术。

1. Transformer 模型: Transformer是一种架构,由Vaswani等人于2017年提出,用于处理序列数据,尤其在自然语言处理任务中表现出色。它使用注意力机制来捕捉输入序列中的长程依赖关系,取代了传统的循环神经网络(RNN)和长短时记忆网络(LSTM)等结构。Transformer包含多头自注意力机制和前馈神经网络,这使得它能够更好地捕捉上下文信息。
2. 预训练技术:GPT采用了预训练的策略。在预训练阶段,模型首先在大规模的文本数据上进行无监督训练。通过学习语言模型,模型能够理解语法、语义和上下文信息。GPT的预训练过程通常涉及对下游任务的目标进行建模,以便在微调阶段更好地适应具体任务。
3. 自回归生成:GPT模型在预训练和微调阶段均采用了自回归生成的方法。在生成文本时,模型根据上下文逐步生成下一个词或标记。每次生成都依赖于前面已生成的内容,这使得模型能够在生成过程中维持上下文的一致性。
4. 多层次表示:GPT的层次化表示允许模型同时捕捉不同层次的语义信息。每个Transformer层都负责不同层次的特征提取,从底层的词级表示到高层的语义表示。
总体而言,GPT的成功建立在Transformer的强大表现和预训练技术的有效性之上,使其成为在自然语言处理任务中取得卓越成果的先进模型。
GPT(Generative Pre-trained Transformer)的功能主要体现在其强大的自然语言处理和生成能力上:

1. 多样的训练方式: GPT在预训练阶段使用了大规模的文本数据,通过学习语言模型来获取广泛的知识。这使得它能够理解语法、语义和上下文信息。不同领域和主题的文本都可以用于预训练,使得模型获得多样的知识。
2. 通用性的问题回答:由于GPT在预训练时并未针对特定任务,而是通过广泛学习语言模型,因此它在回答各种问题方面表现出色。它可以处理不同领域、不同主题的问题,因为它已经学到了各种语言和语境的表示。
3. 上下文敏感:GPT在生成文本时考虑上下文信息,因此能够基于先前的内容生成连贯、上下文一致的回答。这使得模型在处理对话和复杂语境时更为灵活。
总体而言,GPT可以通过预训练学到广泛的语言知识,并能够以通用的方式回答各种问题。其灵活性和多功能性使得它在自然语言处理任务中具有广泛的应用潜力。
GPT的培训分为两个主要阶段:预训练和微调。
1. 预训练阶段:这是GPT获取通用语言知识的阶段。在这个阶段,大规模的文本数据用于训练模型。模型通过学习预测下一个单词的方式,逐渐形成对语法、语义和上下文的理解。OpenAI通常使用互联网上的大量文本数据进行预训练。
2. 微调阶段:预训练后,GPT可以通过在特定任务上进行微调来提高性能。微调的数据集通常是与任务相关的,例如问答、翻译或对话生成。这个阶段的目标是调整模型,使其更适应特定的应用场景。
具体步骤:
- 数据收集:为微调任务收集相关的标注数据,确保数据集具有代表性和多样性。
- 模型微调:使用预训练的GPT模型,在特定任务的数据上进行进一步的训练。通过最小化任务相关的损失函数来微调模型参数。
- 评估和调整: 在开发集或验证集上评估微调后的模型性能。根据性能进行调整,可能需要多次迭代。
- 应用:一旦模型在验证集上表现良好,就可以在实际应用中使用微调后的GPT模型,例如用于自动回答问题、生成文本等任务。
需要注意的是,虽然GPT是通用的,但在特定任务上表现出色的模型通常需要经过精心设计的微调。微调的质量和任务相关的数据集的质量对最终性能至关重要。
要将GPT培养成一个能够执行报关行任务的模型,你可以按照以下步骤进行:
1. 数据收集:收集与报关行相关的大量数据,包括报关单、海关规定、贸易条款等。确保数据集具有多样性,覆盖不同类型的报关情境。
2. 标注数据:对数据进行标注,明确每个文本片段的含义和关联。标注可能包括报关的流程步骤、关键信息提取等。
3. 预处理: 对数据进行预处理,确保输入模型的文本格式符合GPT的要求。这可能涉及到分词、去除噪声、统一格式等操作。
4. 模型微调: 使用预处理后的数据集对GPT进行微调。在微调过程中,模型将逐渐学习报关领域的知识和语境。
5. 评估和优化:在验证集或开发集上评估微调后的模型性能。根据评估结果进行调整,确保模型在报关任务上的准确性和可靠性。
6. 部署:一旦模型表现良好,就可以将其部署到实际应用中。模型可以用于自动处理报关文件、回答相关问题,甚至提供实时的报关建议。
7. 监控和更新:持续监控模型的性能,根据需要进行更新。报关行领域可能会发生法规变化,因此模型需要保持对新信息的适应性。
成功微调的关键在于提供充足而具有代表性的数据,并在微调过程中不断进行评估和调整。此外,保持对法规和业务环境的敏感性也是模型能否成功应用于实际报关任务的关键。
将文本转换为适当的数据格式通常涉及到对文本进行结构化和标记,以便机器学习模型更好地理解。步骤和技术如下:
1. 分段和分句:将文本分成段落或句子,这有助于模型更好地理解文本的组织结构。
2. 分词:将句子拆分为单词或标记的序列。这有助于模型理解语言的基本单元,使其更容易处理。
3. 词嵌入:将单词映射到连续的向量空间中,这有助于保留词汇之间的语义关系。你可以使用预训练的词嵌入模型,如Word2Vec、GloVe或FastText。
4. 实体标记(可选): 如果文本中包含特定实体(如公司名称、日期、金额等),可以对这些实体进行标记,以便模型更好地理解其含义。
5. 建立字典:将文本中的词汇建立成一个字典,每个词对应一个唯一的标识符。这有助于将文本转换为模型可以处理的数字表示。
6. 数值化:使用字典将文本中的单词或标记映像为数字,以便输入到机器学习模型中。
7. 格式规范:确保数据格式符合机器学习模型的输入要求。这可能包括将文本转换为张量或其他适当的数据结构。
具体的实现取决于你使用的机器学习框架和任务。例如,使用Python和深度学习框架(如TensorFlow或PyTorch)时,你可能需要编写脚本或使用库来执行上述任务。数据预处理的确切步骤也取决于文本的性质和目标任务。
将文本输入GPT通常需要将其转换为适当的格式,然后传递给模型。以下是一般的步骤:
1. 文本预处理:对文本进行清洗和预处理,包括去除不需要的字符、分句、分词等。确保文本的格式符合GPT模型的输入要求。
2. Tokenization:将文本分割成标记或单词。GPT使用的是基于子词的标记化方法,将文本划分成子词的序列。
3. 构建输入序列: 将标记转换为模型可以理解的输入序列。通常,你需要在输入文本前后添加特殊标记,以表示序列的开始和结束。
4. 数值化:使用字典将标记映像为数字。每个唯一标记都对应字典中的一个索引。
5. 填充和截断:如果输入序列的长度不符合模型的要求,可能需要进行填充或截断,以确保输入的长度正确。
6. 构建批次:将单个序列或一组序列组成批次,以便同时处理多个样本。
7. **输入到模型:** 将构建好的输入序列传递给GPT模型进行推理或训练。
具体的实现细节取决于你使用的GPT模型和框架。在使用Hugging Face的Transformers库时,你可以使用提供的Tokenizer类来执行标记化和数值化。以下是一个简单的示例使用Transformers库:
```python
from transformers import GPT2Tokenizer
# 初始化 GPT2 Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# 输入文本
text = "你的文本内容"
# Tokenization
tokens = tokenizer.encode(text, return_tensors="pt")
# 输出 token ID
print(tokens)
```
上述示例中,`encode` 函数将文本标记化,并返回包含 token ID 的 PyTorch 张量。这个张量可以作为输入传递给GPT模型。


[文章授权制作]:开胜科技传媒(北京)有限公司

注:本文内容源自网络,版权归原作者所有,如有问题请及时联系我们。
图片使用免责声明:本公众号使用图片均来自搜索引擎,所用图片未标注发布者,使用该图片仅为分享使用,网络平台提供者发现后请联系本站,如果情况属实,我们会第一时间给予删除。



扫码咨询和资深
中美跨国企业家、专家、高端资源对接
我们是:中美跨境商贸一站式服务中心
PEC Global 致力于通过国际化的专业团队为立志进军全球市场,扩大营收的公司提供独特的商业机会和创意的方案
我们核心业务包括跨国企业的建立,经营,并购和重组、跨境商贸咨询、海外品牌建设,海外仓,物流服务,客服中心,线上线下渠道开拓,本土营销,自建站,尾货处理等。
致力于中美跨境商贸一站式解决方案
长按识别二维码关注我们
