架构师之道
●AI · LLM · Agents |Enterprise Architecture |Digital Transformation
大数据技术标准推进委员会最近发布了一份技术报告《AI原生数据平台研究报告(2026年)》。

这份报告说白了,就是讲了一个核心故事:以前咱们的数据平台是“伺候人”的(给人看报表),现在得进化成“伺候AI和Agent(智能体)”的了。
没问题,咱们换个姿势。不整那些虚头巴脑的专家视角切分了,我就顺着这份报告本身的逻辑脉络,用大白话给你把它的核心内容从头到尾、详详细细地盘一遍。
这份报告其实就讲了五个大问题:为啥要变?变成啥样?别人咋变的?我该怎么变?未来会咋样?
一、为啥要变?(背景与动因:大模型把数据平台逼上梁山了)
报告开篇就点明了:时代变了,大人。
以前数据平台是干嘛的?主要是“伺候人”的。业务人员提需求,数据工程师写SQL,最后出个BI报表给人看。但现在,大模型和AI Agent(智能体)成了干活的主力。
Agent不看报表,它们需要的是向量、是特征、是上下文记忆。如果还用老一套平台去喂Agent,就像让一个米其林大厨去用柴火灶做分子料理——根本施展不开。
再加上现在算力越来越便宜、大模型越来越通用,“数据”本身成了企业唯一能拉开差距的护城河。所以,数据平台必须从“给人用”彻底转型为“给AI/Agent用”,这就是AI原生数据平台出场的根本原因。
二、变成啥样?(演进脉络与核心架构:数据平台的“四次变身”与“四大内功”)
这部分是报告的技术核心,讲了数据平台是怎么一步步进化到今天的,以及AI原生平台到底长啥样。
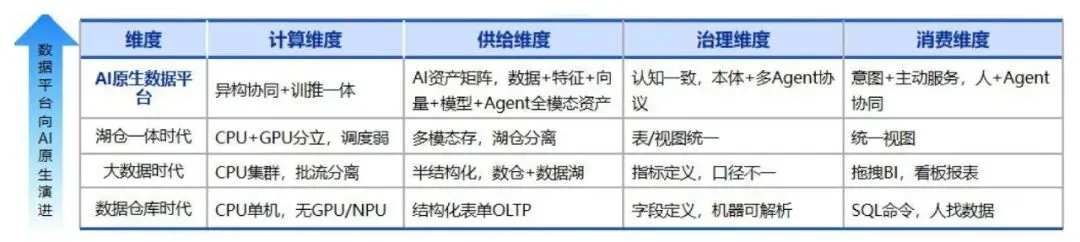
2.1 数据平台的“四次变身”
- 数据仓库时代:
只管结构化表格,单机CPU跑,给人查账用。 - 大数据平台时代:
Hadoop那一套,能存海量数据了,但批处理和实时是割裂的,主要给人做离线分析。 - 湖仓一体时代:
把数据湖和数据仓打通了,能存点非结构化数据了,但底层算力还是各跑各的,算是个过渡期。 - AI原生时代(现在):
彻底为AI量身定制。异构算力(CPU/GPU/NPU)统一调度,啥格式的数据都能存,有统一的业务语义,Agent能直接调用。
2.2 核心架构的“四大内功心法”(四大维度演进)
报告把AI原生平台的升级总结为四个维度的彻底重构:
- 计算维度(算力):
从“CPU单打独斗、静态分配”变成“CPU/GPU/NPU异构池化、智能弹性调度”。训推一体,指哪打哪。 - 供给维度(数据):
从“只存结构化表格”变成“全模态资产大杂烩”。文本、图像、向量、模型、特征全给你管起来,而且是从“被动等人来拿”变成“Agent按需主动来取”。 - 治理维度(规矩):
这是个大升级。从“管字段格式”变成“管业务语义”。给大模型建立统一的“业务字典”和“知识图谱”,防止它胡说八道(幻觉)。同时安全也从“防外贼”变成了“防Agent越权和被Prompt注入”。 - 消费维度(使用):
从“人写SQL查数据”变成“人用大白话下指令,Agent自动去查、去算、去执行”。消费主体从“纯人”变成了“人+Agent”。
2.3 技术架构长啥样?
报告画了个典型的分层架构图:底下是算力支撑,往上是存储接入、计算处理、开发层、服务层,最上面是应用层(比如ChatBI、智能客服)。左右两边分别贯穿了“智能治理层”和“安全运营体系”。主打一个“全链路闭环”。

三、别人咋变的?(全球大厂实践:国内外神仙打架与套路拆解)
这部分其实就是各家大厂的“产品宣讲PPT”大赏,报告把他们分门别类地总结了一下。
3.1 海外大厂的三条路
- Databricks(全栈硬核流):
底子厚,直接从底层湖仓(Delta Lake)一路打通到上层的Agent运营平台。主打一个“大而全”,连Agent跑的时候烧多少Token、有没有越权,它都要管(Unity Catalog)。 - Snowflake(云原生轻量流):
主打一个“存算解耦、按需付费”。把各种AI能力(向量检索、模型推理)直接封装成SQL函数,让业务人员写句SQL就能调用AI。Agent也是全托管的,极其轻量。 - Palantir(高安全本体流):
这哥们儿不一样,他不先搞存储,他先搞“业务本体(Ontology)”。先把业务逻辑和实体关系在系统里建好模,再往里填数据。主打一个极度安全、强管控,专门卖给国防、政务这种对安全要求变态的客户。
3.2 国内大厂的“百花齐放”
- 阿里云:
搞了个Agentic Lake,主打全引擎Agent化改造,自然语言直接驱动。 - 腾讯云:
搞了个DIaaS(数据智能即服务),造了一堆带“TC”前缀的名词(TCLake、TCRay等),主打多模态融合和MCP协议开放。 - 华为云:
DataArts平台,核心是“知识湖”,强调数据向知识的转化,很契合政企口味。 - 火山引擎:
直接用Lance格式搞多模态数据湖,主打Agent导向,处理层全自动化。 - 星环科技:
全栈AI Infra,支持11种数据模型,主打一个私有化部署和全栈适配。
报告总结的共性规律:不管国内外怎么吹,底层逻辑就三条:一是必须先搞“统一底座”(别搞一堆烟囱);二是治理和安全必须“内嵌”到全流程里(不能事后打补丁);三是必须“分层分步”落地(别想一口吃成胖子)。
四、我该怎么变?(落地建议:不同体量企业的生存指南)
报告很接地气地给出了三类企业的转型建议,主打一个“看菜下饭”:
4.1 央国企(稳字当头,旁路演进):
- 痛点:
系统老、数据乱、安全要求极高、不敢乱动核心业务。 - 药方:
别去动核心交易系统,搞“旁路抽取”,在旁边建个轻量级AI底座。先搞数据治理,把数据洗干净。初期别碰核心交易,先拿内部知识库、合同审查这种“高容错”场景练手。最后,必须全栈国产化适配。
4.2 中小微企业(穷有穷的玩法,轻量订阅):
- 痛点:
没钱、没技术人才、试错成本极高。 - 药方:
千万别自己建平台!直接买SaaS服务,按量付费。找那种“零代码、大白话交互”的产品,内置好营销、库存等现成模板,开箱即用。重点是把多源数据一键打通,别自己折腾。
3. 大型民企/互联网大厂(全托管云原生,死守开放):
- 痛点:业务迭代快、规模大、怕被云厂商绑架。
- 药方:把底层的Hadoop集群扔了,全面拥抱公有云的全托管“湖仓智一体”服务,省钱省力。开发上搞API优先、低代码编排,让Agent快速上线。最关键的一条:底层存储必须死守Iceberg/Delta Lake等开源开放格式,坚决防范被单一云厂商技术锁定。
五、未来会咋样?(总结与展望:终极形态)
最后,报告画了个饼,说未来3-5年是黄金期:
- 技术上:
统一语义会成熟,数据跟模型彻底融为一体(数据即模型,模型即数据),端边云协同。 - 应用上:
先搞定报表、问答这些通用场景,然后深扎金融、能源、制造等核心业务,Agent会成为标配。 - 格局上:
市场大洗牌,有模型、有平台、有行业经验的“全能巨头”和“垂直专精”玩家会活下来,开源和闭源一起发力。
虽然还有数据质量差、语义标准化慢、Agent不够可靠等坑要填,但AI原生数据平台成为企业智能化的“核心基础设施”已经是板上钉钉的事了。
六、我的一些看法
6.1 “AI原生”是个过渡词,未来是“Agent 即应用”
报告里还在强调“数据平台”这个实体。但我认为,未来 3-5 年,“数据平台”这个概念会隐形。它不会再是一个你需要单独登录、单独管理的庞大系统。它会变成 Agent 的“潜意识”和“消化道”。用户根本不需要关心底层是湖仓还是向量库,他们只关心 Agent 能不能把活干好。数据平台将彻底“基础设施化”和“无感化”。
6.2 得“上下文”者得天下
报告里提到了“上下文信息管理”,但这其实是未来最核心的壁垒。大模型本身大家都能调(API 越来越便宜),算力也能租。真正的护城河,是谁能最高效、最准确地把企业私域的“动态上下文”喂给 Agent。谁能把企业的隐性知识、实时业务状态瞬间转化为 Agent 能懂的结构化记忆,谁就能赢。
6.3 从“DataOps”走向“AgentOps”
软件工程的重心正在转移。以前我们折腾 CI/CD、折腾 DataOps(数据运维),未来企业的核心工程团队将全面转向 AgentOps(智能体运维)。怎么监控 Agent 的行为轨迹?怎么评估 Agent 的决策质量?怎么给 Agent 做灰度发布?这将是未来软件工程最赚钱、也最缺人的领域。
6.4 别把“语义治理”当成了治幻觉的万能药
从“管字段”到“管语义”,这是报告里我觉得写得最透彻的部分。以前的数据治理是“格式治理”——这字段是整数还是字符串?现在不行了,现在得搞 “语义治理”。
大模型最容易犯“幻觉”,为啥?因为它不懂你们公司的“业务黑话”。所以现在的治理,得把业务指标、口径变成大模型能懂的“本体(Ontology)”和“知识图谱”。另外,安全也变了,以前防黑客,现在得防Agent“越权”或者被“Prompt注入”骗了。
但是报告还说,搞了“统一语义”、“知识图谱”,就能规避 AI 幻觉。呵呵!在目前的工程实践里,RAG(检索增强生成)的召回率、Chunking(分块)策略、多模态对齐依然是个玄学。语义治理能缓解幻觉,但绝对不可能“消除”幻觉。报告把技术理想化了。
6.5 忽略了最厚的墙:“部门墙”与“组织变革”
在给央国企的建议里,报告大谈“旁路演进”、“数据治理先行”。但现实中,央国企搞 AI 数据平台,最大的阻力根本不是技术,而是业务部门不愿意共享数据,是部门利益割裂。没有“一把手”工程和组织架构的强力变革,你底层技术再“原生”,上面跑的业务数据也进不来。报告对“人”和“组织”的因素考虑得太少。
七、总结一下
这份报告的核心内容,其实就是给整个数据行业下达了一道 “改旗易帜”的动员令。它告诉你,旧的数据平台时代结束了,新的AI原生时代来了;它给你看了国内外大厂是怎么搭台子的,也教你不同体量的公司该怎么唱戏。虽然里面夹杂着不少厂商的私货和软广,但整体的技术演进方向和落地逻辑,是符合当前行业真实发展趋势的。
有任何不同的看法,评论区我们可以继续聊~ ?
https://pan.baidu.com/s/1uM50v80YJeGypo2t0OdJyQ?pwd=2v1c
提醒一句:以上资料请仅用于个人学习和研究之用,勿用于任何商业目的,切记!!!
架构师之道
架构之道,在于化繁为简,以设计思维驱动技术决策
> 关注作者并添加星标,与‘架构师之道’同行